基于pytorch的深度学习模型构建案例
文章目录
-
- 深度学习理论流程
- 数据准备与处理
-
-
- Tensor
- Dataset
- Dataloader
- IterableDataset
-
- 模型设计与构建
-
-
- 神经网络组成
- 线性层Linear
- 构建方法1
- 构建方法2:ModuleList
- 构建方法3:Sequential
- 构建方法4:ModuleDict
-
- 模型训练
-
-
- 训练理论过程
- 自动梯度
- 损失函数
- 优化算法
- 训练过程实现
-
- 模型测试
- 模型保存和加载
-
-
- 保存和加载模型权重
- 保存和加载模型整体
-
- 完整案例
- 数据和代码我上传一份在这里
深度学习理论流程
关于pytorch的一些简介就不废话了,只说一句:pytorch是深度学习框架中的一种。既然我们要用pytorch来完成我们的深度学习的工作,那么首先最需要知道的就是,完成一个深度学习案例都有哪些工作需要准备。惯例先甩一个图:
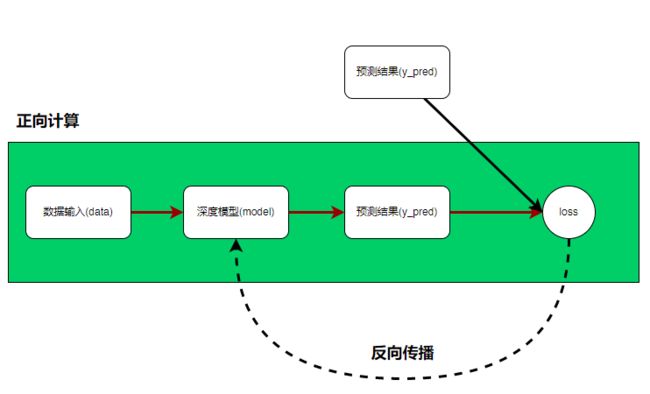
这个图就是一个深度学习的大致流程,大致由正向计算过程和反向传播过程组成。
在正向计算过程中,需要准备数据,然后将数据输入到模型当中得到预测结果;
在反向传播过程中,需要将预测结果与真实结果进行比较计算loss,然后反向求梯度,更新深度模型里的参数,使得模型预测结果与真实值之间的差距(loss)越来越小。所以总结下来,一个深度模型需要的工作有:
- 数据的准备与处理
- 模型的构建
- loss的求解
- 梯度的求解
- 参数更新(模型优化)
下面会更具这五点一一展开
数据准备与处理
在pytorch中,任何数据都是以tensor的形式进行编码的,也就是说数据要想在pytorch平台下运行,必须转化为Tensor的形式,那下面就看看什么是tensor?
Tensor
`torch.tensor(data, *, dtype=None, device=None, requires_grad=False, pin_memory=False)`
data : 初始化tensor的数据,可以是列表(list)、元组(tuple)、numpy的数组ndarray、数字标量和其他类型等。
dtype :指定tensor的数据类型,通常数据类型又如下几种
| dtype | 数据类型描述 |
|---|---|
| torch.float16 or torch.half | 16位浮点型 |
| torch.float32 or torch.float | 32位浮点型 |
| torch.float64 or torch.double | 64位浮点型 |
| torch.uint8 | 8位无符号整型 |
| torch.int8 | 8位有符号整型 |
| torch.int16 or torch.short | 16位有符号整型 |
| torch.int32 or torch.int | 32位有符号整型 |
| torch.int64 or torch.long | 64位有符号整型 |
| torch.bool | bool类型 |
| torch.complex64 or torch.cfloat | 64位复数 |
以上是常用的一些数据类型,如果没有指定这个参数,那么torch会根据data自动推断数据类型,所以如果data里面的数据类型是统一的,就可以,那么大可忽略dtype,让它自动推断。
例子:
- list初始化tensor
data_list = [[1,2,3],[2,3,4],[4,5,6]]
list_tensor = torch.tensor(data_list)
print('数据类型dtype:{}'.format(list_tensor.dtype))
print('数据为:\n{}'.format(list_tensor))
输出
数据类型dtype:torch.int64
数据为:
tensor([[1, 2, 3],
[2, 3, 4],
[4, 5, 6]])
初始化过程中,并没有指定数据类型,所以系统会根据数据自己推测出是torch.int64,但是推测的前提是:给出的数据类型一定要统一(int就是全部int,不能多个数据类型混杂)
- tuple初始化tensor
data_tuple = ((1,2,3),(3,4,5))
tuple_tensor = torch.tensor(data_tuple,dtype = torch.float32)
print('数据类型dtype:{}'.format(tuple_tensor.dtype))
print('数据为:\n{}'.format(tuple_tensor))
输出
数据类型dtype:torch.float32
数据为:
tensor([[1., 2., 3.],
[3., 4., 5.]])
指定了数据类型是torch.float32,所以最开始的整型变成了float32形
- ndarray初始化tensor
data_list = [[1,2,3],[2,3,4],[4,5,6]]
data_tuple = ((1,2,3),(3,4,5))
tuple_tensor = torch.tensor(data_tuple,dtype = torch.float32)
print('数据类型dtype:{}'.format(tuple_tensor.dtype))
print('数据为:\n{}'.format(tuple_tensor))
输出
数据类型dtype:torch.float64
数据为:
tensor([[1., 2., 3.],
[2., 3., 4.],
[4., 5., 6.]], dtype=torch.float64)
- 标量初始化tensor
test = torch.tensor(3)
print('数据类型dtype:{}'.format(test.dtype))
print('数据为:\n{}'.format(test))
输出
数据类型dtype:torch.int64
数据为:3
&emsp: 初始化tensor之后,其实tensor的操作和array有些类似,但是tensor和ndarray等其他数据类型差别在于什么?在于tensor可以搬运到gpu上去运行,那如何搬运?就是第三个参数:device
device:指定数据在什么地方运行,要么是cpu要么是gpu
| 指定运行设备 | 关键字 |
|---|---|
| cpu | ‘cpu’ |
| gpu | ‘cuda:index’ |
如果你的电脑上有多个gpu,那么就可以通过index指定,当然你也可以直接写一个cuda
示例1:
data = [[1,2],[3,4]]
gpu_device = torch.device('cuda')
#指定用第一个gpu
#gpu_device = torch.device('cuda:0')
tensor_data = torch.tensor(data,device=gpu_device )
示例2:
data = [[1,2],[3,4]]
tensor_data = torch.tensor(data,device='cuda:0')
注:目前这三个参数已经足以,还有几个参数,后面在深度学习进行反向梯度的时候,会用到,到时候再说。
在训练模型过程中,如果是利用一条一条的数据进行训练的话,收敛速度太慢,所以通常是小批量数据送入模型,然后反向梯度训练模型,那么要达到此效果,就必须利用pytorch提供的Dataloaders数据加载器不断的小批量输出数据给模型,而Dataloader加载器中有一个参数是Dataset,所以必须先初始化Dataset,然后利用Dataset初始化Dataloader。
Dataset
在实际业务中,我们都是利用我们自己的数据来训练模型,所以我们就需要定义自己的数据类,这个自定义数据类必须继承Dataset,然后实现三个函数:
__init__:函数在实例化 Dataset 对象时运行一次
__len__:函数返回我们数据集中的样本数。
__getitem__:函数从给定索引处的数据集中加载并返回一个样本idx
下面就从csv文件中来初始化我们自定义的一个数据集,数据集是cretio,会在附件中提供
import pandas as pd
from torch.utils.data import DataLoader,Dataset
class Mydata(Dataset):
def __init__(self,path):
self.df = pd.read_csv(path).values
def __getitem__(self,idx):
features = self.df[idx,:-1]
label = self.df[idx,-1]
return features,label
def __len__(self):
data_lens = self.df.shape[0]
return data_lens
path = './train_set.csv'
train_data = Mydata(path)
test = iter(train_data)
next(test)
输出:
(array([9.47368421e-02, 3.81388253e-04, 8.27716684e-04, 8.04597701e-02,
1.21156602e-04, 1.50927124e-03, 5.42822678e-03, 9.14076782e-03,
1.24179528e-03, 2.50000000e-01, 2.70270270e-02, 0.00000000e+00,
9.09090909e-03, 2.60000000e+01, 1.20000000e+01, 7.50000000e+01,
3.93000000e+02, 1.00000000e+00, 0.00000000e+00, 9.69000000e+02,
2.70000000e+01, 1.00000000e+00, 8.55000000e+02, 3.32000000e+02,
6.59000000e+02, 5.09000000e+02, 1.30000000e+01, 2.73000000e+02,
2.65000000e+02, 8.00000000e+00, 1.88000000e+02, 2.30000000e+01,
2.00000000e+00, 1.03300000e+03, 0.00000000e+00, 0.00000000e+00,
6.70000000e+01, 2.70000000e+01, 4.25000000e+02]),
0.0)
细节说明:
- 调用Mydata时,__init__哈数只会运行一次,里面一般是用于初始化读取数据之类的工作,而在里面有一个细节,那就是pandas读出来的数据取了values,为什么呢?下一个接口Dataloader讲解时解答。
2.__getitem__函数有个参数是idx,这个索引就好比是一个行索引,读入的数据可以根据索引取得一行数据,你要返回什么类型的自己可以diy,但是通常都是返回features和label值。
3.__len__返回的是整体数据的的大小,可以理解为是有多少条数据。
但是最后还有一个问题,那就是之前讲过以pytorch为基础的深度学习计算中,必须以torch为基础进行编码,但是这里丝毫没有torch的影子,这就得看下一个接口了Dataloader,比较并不是直接让Dataset入模计算的。
Dataloader
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
这个类的参数比较多,这里只讲解用得比较多的几个:
dataset:上一节初始化的dataset数据;
batch_size:表示一批次往深度模型中出多少数据;
shuffle:打乱数据往外出,而不是顺序往外出;
num_workers:线程数
drop_last:
示例:
import pandas as pd
from torch.utils.data import DataLoader,Dataset
class Mydata(Dataset):
def __init__(self,path):
self.df = pd.read_csv(path).values
def __getitem__(self,idx):
features = self.df[idx,:-1]
label = self.df[idx,-1]
return features,label
def __len__(self):
data_lens = self.df.shape[0]
return data_lens
#测试
path = './train_set.csv'
dataset1 = Mydata(path)
train_data_1 = DataLoader(dataset1,batch_size = 2,shuffle = True)
for x,y in train_data_1:
print('特征数据为:\n{}'.format(x))
print('隔离线'.center(100,'*'))
print('label为:\n{}'.format(y))
break
输出:
特征数据为:
tensor([[0.0000e+00, 1.0933e-02, 3.5474e-04, 3.4483e-02, 2.0030e-02, 2.4148e-02,
9.0470e-03, 9.1408e-03, 1.9159e-02, 0.0000e+00, 2.7027e-02, 0.0000e+00,
3.8961e-03, 5.6000e+01, 5.1000e+01, 0.0000e+00, 0.0000e+00, 1.0000e+00,
0.0000e+00, 7.0700e+02, 2.0000e+01, 1.0000e+00, 2.7000e+02, 2.0900e+02,
0.0000e+00, 6.4900e+02, 2.0000e+00, 3.5800e+02, 0.0000e+00, 8.0000e+00,
1.9400e+02, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00],
[1.0526e-02, 1.2713e-04, 3.9021e-03, 6.8966e-02, 4.9251e-06, 1.2937e-03,
1.8094e-03, 9.1408e-03, 1.5966e-03, 2.5000e-01, 5.4054e-02, 0.0000e+00,
7.7922e-03, 0.0000e+00, 1.5000e+02, 5.4700e+02, 1.6400e+02, 1.0000e+00,
3.0000e+00, 3.3500e+02, 1.7000e+01, 1.0000e+00, 1.9400e+02, 6.0900e+02,
1.0980e+03, 3.0400e+02, 2.0000e+00, 2.6100e+02, 3.1400e+02, 3.0000e+00,
2.5100e+02, 2.3000e+01, 2.0000e+00, 5.9700e+02, 0.0000e+00, 0.0000e+00,
3.0200e+02, 4.0000e+00, 2.2400e+02]], dtype=torch.float64)
************************************************隔离线*************************************************
label为:
tensor([0., 1.], dtype=torch.float64)
细节说明:
- 从中可以看出,设置batch_size = 2之后,一次输出为2条数据;
2.设置shuffle = True之后,出的数据是随机的;
重要说明:
从输出可以看出,我们整个过程并没有设置类型转化为tensor,但是输出结果确实是tensor类型的,所以你可以认为数据并不需要可以转化为tensor,只需要将Dataset经过Dataloader之后,就转为tensor了,前面说了初始化tensor可以使用list,tuple,ndarray等,所以前面Dataset初始化时,将Dataframe转为了array直接喂给Dataset就行了,这个数据会在这一节的Dataloader中直接自动转为tensor,所以不需要自己手动转为tensor,只需要喂给他ndarray、list、或者tuple就行了。
所以说如果你要自己手动转化为tensor?其实就是要在上一步的Dataset转了。
IterableDataset
前面利用Dataset配合Dataloader的方式,是一次性在Dataset中把所有的数据都加载进内存的,但是如果遇到数据特别庞大,无法加载进内存该怎么办?那就是要利用IterableDataset配合流式数据进行数据的读入了,而继承这个类的,需要重写__init__和__iter__函数
__init_: 函数在实例化 Dataset 对象时运行一次;
__iter_: 定义一个迭代器,一次返回一条数据;
示例:
from torch.utils.data import DataLoader,IterableDataset
import torch
class MyIterableDataset(IterableDataset):
def __init__(self, file_path):
self.file_path = file_path
def __iter__(self):
with open(self.file_path, 'r') as file_obj:
for line in file_obj: # 更多操作在这里完成
/*这里用了map和list转数据,是因为流式读入数据,数据是一个list,list里面都是字符串型
*所以经过map和list转化之后,变成了一个浮点型的list,但是和前面的不同,这里的list必须转为tensor
*/
line_data = torch.tensor(list(map(float,line.strip('\n').split(','))))
yield line_data[:-1],line_data[-1]
path = './train_set1.csv'
dataset2 = MyIterableDataset(path)
train_data_2 = DataLoader(dataset2,batch_size = 2,drop_last = True)
for feature,label in train_data_2:
print(feature)
print('分隔线'.center(100,'*'))
print(label)
break
输出:
tensor([[9.4737e-02, 3.8139e-04, 8.2772e-04, 8.0460e-02, 1.2116e-04, 1.5093e-03,
5.4282e-03, 9.1408e-03, 1.2418e-03, 2.5000e-01, 2.7027e-02, 0.0000e+00,
9.0909e-03, 2.6000e+01, 1.2000e+01, 7.5000e+01, 3.9300e+02, 1.0000e+00,
0.0000e+00, 9.6900e+02, 2.7000e+01, 1.0000e+00, 8.5500e+02, 3.3200e+02,
6.5900e+02, 5.0900e+02, 1.3000e+01, 2.7300e+02, 2.6500e+02, 8.0000e+00,
1.8800e+02, 2.3000e+01, 2.0000e+00, 1.0330e+03, 0.0000e+00, 0.0000e+00,
6.7000e+01, 2.7000e+01, 4.2500e+02],
[0.0000e+00, 2.5426e-04, 7.0947e-04, 4.5977e-02, 7.0901e-03, 1.9836e-02,
3.0157e-03, 7.3126e-03, 5.3752e-02, 0.0000e+00, 2.7027e-02, 0.0000e+00,
5.1948e-03, 0.0000e+00, 3.7000e+01, 7.4400e+02, 9.6200e+02, 6.0000e+00,
4.0000e+00, 1.3200e+02, 1.7000e+01, 1.0000e+00, 5.5000e+01, 8.8100e+02,
1.4500e+02, 1.5900e+02, 2.0000e+00, 4.8000e+01, 3.4800e+02, 8.0000e+00,
2.8500e+02, 6.5000e+01, 2.0000e+00, 2.9400e+02, 0.0000e+00, 0.0000e+00,
1.7500e+02, 2.1000e+01, 1.5000e+02]])
************************************************分隔线*************************************************
tensor([0., 0.])
细节说明:
1.在__init__中就初始化了一个数据路径
2.__item__才开始流式的读入数据,返回的数据用了yield而不是return,这是因为是流式读入,数据并不是一次读完。
3.Dataloader中多了一个参数drop_last = True,这表示,如果最后的数据不够一个批次batch_size的化,选择丢弃。
重要说明:
因为数据是流式读入,所以数据样本中只能有纯数据,不能有列名。

模型设计与构建
神经网络组成
数据准备好之后,就要开始构建网络了,既然是要构建神经网络,那首先就得知道神经网络是由什么组成的?下面是最常见的神经网络图
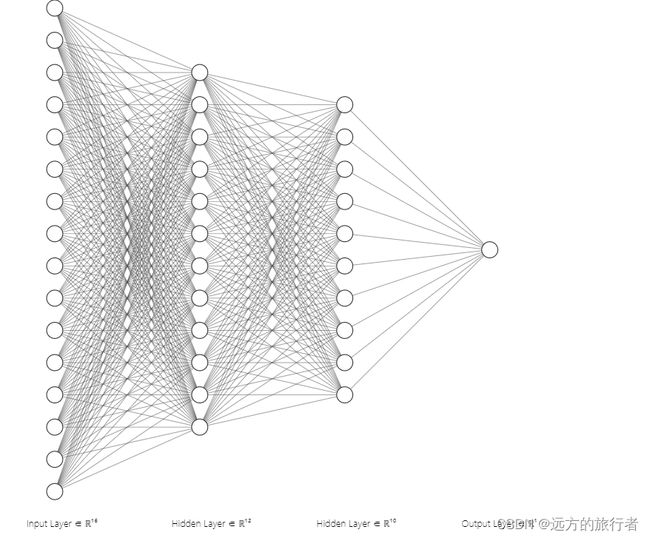
从图中可以看出神经元组成组要有:
神经元
神经网络最主要的是有神经元构成,图中的圆圈就是神经元
神经网络层
多个神经元组成神经网络层,而神经网络层又有多种,诸如卷积层、线性层等。
激活层
还有一些隐藏的组成,比如每个神经元要被激活,是需要一个激活函数的,所以每一个神经网络层的每一个神经元的激活函数就组成了激活层。
最后神经网络层之间连接起来就组成了整个神经网络。所以我们在构建神经网络的时候,就挨个实现就行了,然后连接起来。
本文就来构建一个3层线性神经网络:
第一层:39个神经元
第二层:24个神经元
第三层:12个神经元
线性层Linear
接口为:
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数说明:
in_features: 指定输入数据尺寸
out_features:指定输出数据尺寸
bias:指定是否使用偏置,一般是建议使用,默认是True,使用偏置
device:指定设备,cpu还是gpu
dtype:指定输入数据类型
在前面构建自定义数据集的时候,都是需要继承一个基类的(Dataset),然后重写里面的几个方法。同样的,构建神经网络模型也类似,需要继承nn.Module,然后重写__init__和forward,在__init__中定义我们所需要的神经网络层,然后在forward中将这些网络层连接起来。
构建方法1
import torch
from torch import nn
def __init__(self):
super(NeuralNetwork, self).__init__()
self.input_layer1 = nn.Linear(39,24)
self.input_layer2 = nn.Linear(24,12)
self.output_layer = nn.Linear(12,1)
self.activate1 = nn.ReLU()
self.activate2 = nn.Sigmoid()
def forward(self, x):
x = self.input_layer1(x)
x = self.activate1(x)
x = self.input_layer2(x)
x = self.activate1(x)
x = self.output_layer(x)
output = self.activate2(x)
return output
细节说明:
- 在上图中在__init__构建了三个线性层,两个激活层,他的激活函数是ReLU和Sigmoid;
2.在forward中将上面的网络层挨个组了起来;
3.除了__init__和forward之外,还有一个super,这是初始化父类,这是必须的,不能忘记。
为了直观的查看网络结构,利用tensorboard查看网络结构,代码如下:
from torch.utils.tensorboard import SummaryWriter
model = NeuralNetwork()
writer = SummaryWriter('run1/fashion_mnist_experiment_1')
test = torch.ones(1,39)
writer.add_graph(model, test)
writer.close()
运行之后,可以看到本地文件下出现了run1文件夹
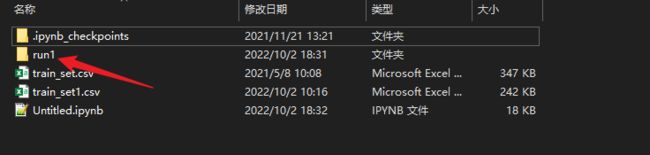
然后在终端运行命令:tensorboard --logdir=run1

然后本地打开http://localhost:6006/
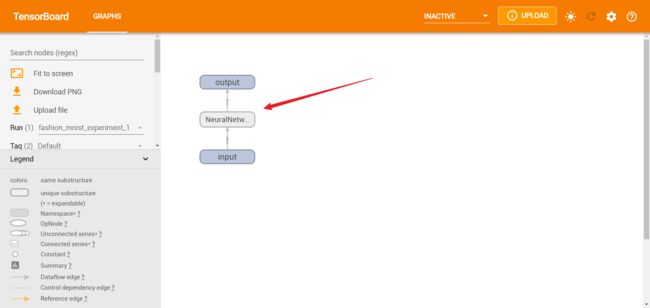
点开箭头处,看看模型详细结构。
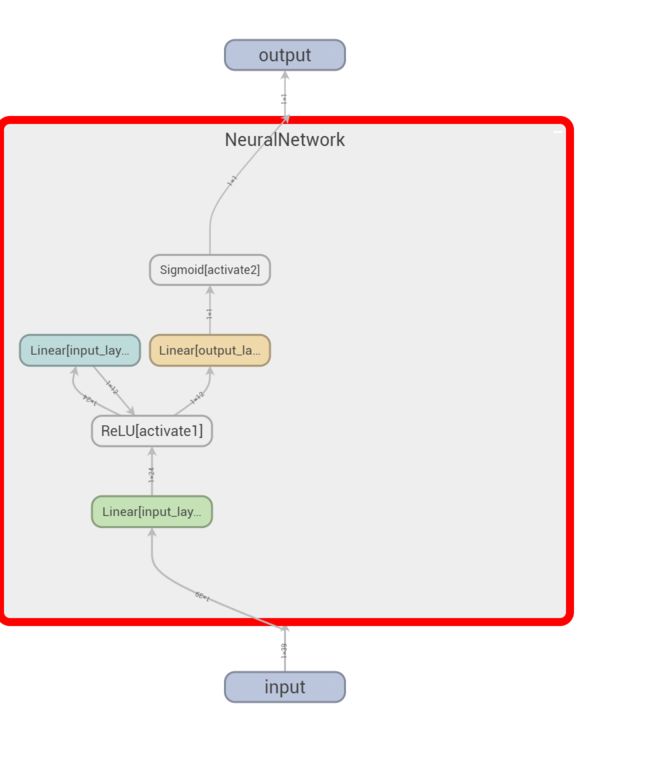
可以看得出,确实构建了一个三层神经网络。
构建方法2:ModuleList
在第一个方法中,有没有可以简化一点呢?可以的,那我们就从forward中简化。
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.layer = nn.ModuleList([
nn.Linear(39,24),
nn.ReLU(),
nn.Linear(24,12),
nn.ReLU(),
nn.Linear(12,1),
nn.Sigmoid()
])
def forward(self, x):
for item_layer in self.layer:
x = item_layer(x)
return x
model = NeuralNetwork()
# 可视化
writer = SummaryWriter('run2/fashion_mnist_experiment_1')
test = torch.ones(1,39)
writer.add_graph(model, test)
writer.close()
细节说明:
- 从中可以看出,ModuleList就和python的list是一样的,本质就是一个list,只是它是在pytorch下是list,操作和python下是list是大致一样的。
- 在使用了ModuleList之后,我们的forward就可以简化了,一个for循环就搞定了。
可视化

构建方法3:Sequential
Sequential是一个序贯模型,可以事先把所有的网络层按照实际的构建顺序排列好,而Sequential内部就已经有了一个forward,所以我们在forward中就不需要那么复杂的进行构建了。
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.layer = nn.Sequential(
nn.Linear(39,24),
nn.ReLU(),
nn.Linear(24,12),
nn.ReLU(),
nn.Linear(12,1),
nn.Sigmoid()
)
def forward(self, x):
output = self.layer(x)
return output
model = NeuralNetwork()
# 可视化
writer = SummaryWriter('run3/fashion_mnist_experiment_1')
test = torch.ones(1,39)
writer.add_graph(model, test)
writer.close()
细节说明:
- 利用Sequential时,所有的网络层必须按照我们想要构建的顺序罗列,不能顺序错乱。
2.利用Sequential之后,forward就不用那么复杂的构建了,直接把数据x输入就行了。
可视化:
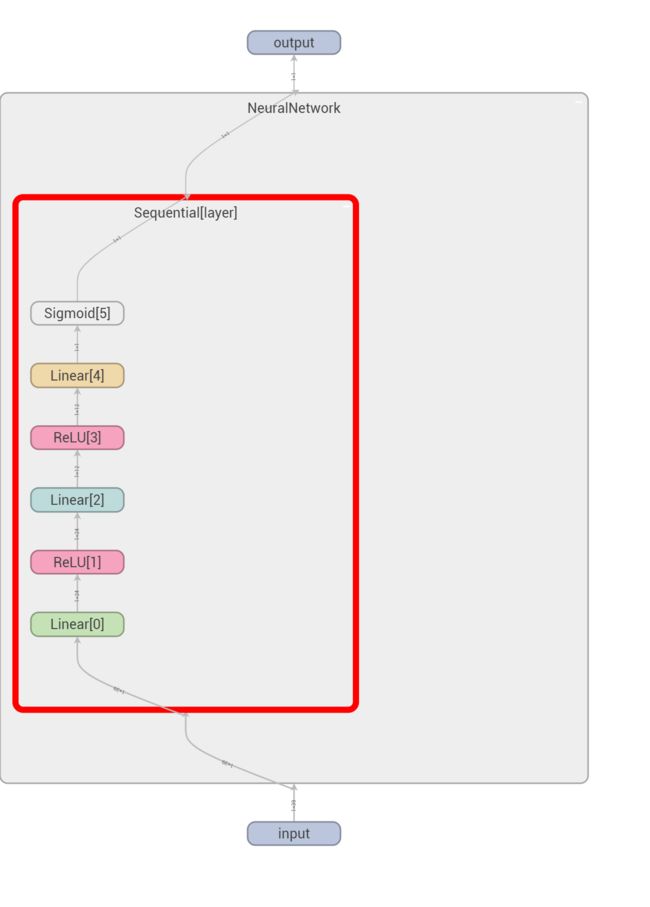
但是缺点在于,一旦构建好了,就不能再改变了,不够灵活
构建方法4:ModuleDict
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.layers = nn.ModuleDict({
'layer1': nn.Linear(39,24),
'layer2':nn.Linear(24,12),
'layer3':nn.Linear(12,1)
})
self.activates = nn.ModuleDict({
'relu':nn.ReLU(),
'sigmoid':nn.Sigmoid()
})
def forward(self, x):
x = self.layers['layer1'](x)
x = self.activates['relu'](x)
x = self.layers['layer2'](x)
x = self.activates['relu'](x)
x = self.layers['layer3'](x)
x = self.activates['sigmoid'](x)
return x
model = NeuralNetwork()
# 可视化
writer = SummaryWriter('run4/fashion_mnist_experiment_1')
test = torch.ones(1,39)
writer.add_graph(model, test)
writer.close()
细节注意:
- 从中可以看出ModuleDict和python中的dict一样,就是一个字典,给每一个层赋予一个名字,其他的操作和python中的dict是一样的,每一个层就可以通过名字来获取
- 在forward中,虽然比之前的复杂了很多,但是灵活度很高,每一个层都可以复用,这在构建模块化的一些诸如mlp或者是残差块的时候,优势很明显。
可视化:
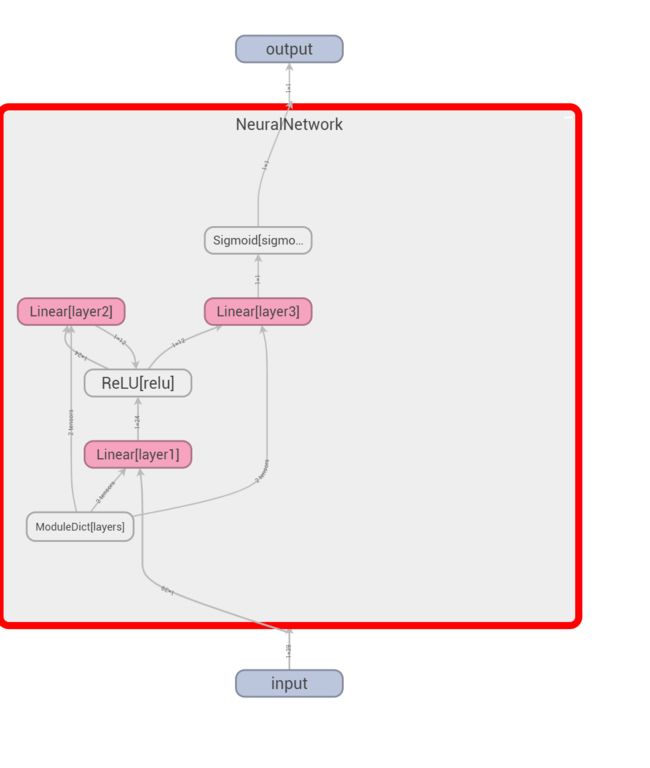
模型训练
训练理论过程
构建好了数据和模型,就要开始训练了,通常训练的过程中,最常用的算法是 反向传播,具体效果如下:
- 数据输入模型,得到预测结果y_pred;
- 计算预测值与真实值之间的差距,也就是损失函数loss;
- 计算loss关于参数w和b的梯度值,也就是倒数;
- 利用优化函数优化模型参数w和b;
- 重复1-5步骤,知道模型效果达到预期。
自动梯度
pytorch中是可以求梯度值的,而且是自动求梯度,只要设置requires_grad=True就行了,在神经网络中,训练更新的是w和b参数,如果你不进行初始化,那么requires_grad默认就是True,如果你是要手动初始化w和b,那么你就需要手动设置这个requires_grad,还记得在最开始将Tenser的时候吗?那里有一个参数就是requires_grad,就是在那里设置的。
损失函数
罗列部分损失函数
| nn.MSELoss | 均方差损失函数,用于回归 |
|---|---|
| nn.CrossEntropyLoss | 用于分类 |
| nn.NLLLoss | 负对数损失函数 |
| nn.GaussianNLLLoss | 高斯负对数损失函数 |
| nn.BCELoss | 二值交叉熵损失函数 |
优化算法
部分优化算法
| SGD | 随机梯度下降 |
|---|---|
| RMSprop | |
| RAdam | |
| Adam | |
| Adagrad |
训练过程实现
#模型训练过程
def train_loop(dataloader,model,loss_fn,optimizer,t):
size = len(dataloader.dataset)
for batch,(x,y) in enumerate(dataloader):
pred = model(x)
loss = loss_fn(pred.squeeze(),y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 30 == 0:
loss, current = loss.item(), batch * len(x)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# writer.add_scalar('training loss',loss / 100, t*len(x)+batch//100)
# 3.模型训练
# 3.1超参设置
learning_rate = 1e-3
epochs = 3
# 3.2.设置损失函数和优化函数
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 3.3.开始训练
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loop(train_data_1, model, loss_fn, optimizer,t)
# test_loop(test_dataloader, model, loss_fn)
print("Done!")
细节说明:
- pred = model(x) :预测结果;
2.loss = loss_fn(pred.squeeze(),y) : 利用损失函数计算得到损失;
3.optimizer.zero_grad() : 清空上一步的梯度值,避免梯度累积;
4.loss.backward(): 求得本次的梯度值;- optimizer.step() :利用优化器根据梯度值更新模型参数。
重要说明
喂给模型的数据一定要是torch.float32,如果不是,则一定要转。
模型测试
模型测试的时候,并不需要根据梯度来更新参数,所以自动求梯度需要禁止,其中禁止的方法有:
- torch.no_grad()
- detach()
代码示例
# 模型测试过程
def test_loop(dataloader,model,loss_fn):
size = len(dataloader.dataset)
num_batchs = len(dataloader)
test_loss,correct = 0,0
with torch.no_grad():
for x,y in dataloader:
pred = model(x)
test_loss = loss_fn(pred.squeeze(),y).item()
correct += pred.argmax(1).sum().item()
test_loss /= num_batchs
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
test_loop(train_data_1, model, loss_fn)
print("Done!")
模型保存和加载
模型的保存有两种方法,一种方法是保存模型权重,另一种是保存整个模型
保存和加载模型权重
权重保存
# 权重保存
torch.save(model.state_dict(), 'model_weights.pth')
权重加载
#权重加载
model_teset = NeuralNetwork()
model_teset.load_state_dict(torch.load('./model_weights.pth'))
保存和加载模型整体
模型保存
torch.save(model, 'model.pth')
模型加载
model = torch.load('model.pth')
细节说明:
1.保存权重的方法比保存模型占用的存储要小,因为不需要保存模型形状等等;
2.保存权重的办法中,如果要加载的化,要事先建立模型形状,然后再加载权重
完整案例
import pandas as pd
from torch.utils.data import DataLoader,Dataset,IterableDataset
import os
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
# 自定义数据集
class Mydata(Dataset):
def __init__(self,path):
self.df = pd.read_csv(path).values
def __getitem__(self,idx):
features = torch.tensor(self.df[idx,:-1],dtype=torch.float32)
label = torch.tensor(self.df[idx,-1],dtype = torch.float32)
return features,label
def __len__(self):
data_lens = self.df.shape[0]
return data_lens
# 自定义神经网络
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.input_layer1 = nn.Linear(39,24)
self.input_layer2 = nn.Linear(24,12)
self.output_layer = nn.Linear(12,1)
self.activate1 = nn.ReLU()
self.activate2 = nn.Sigmoid()
def forward(self, x):
x = self.input_layer1(x)
x = self.activate1(x)
x = self.input_layer2(x)
x = self.activate1(x)
x = self.output_layer(x)
output = self.activate2(x)
return output
#模型训练过程
def train_loop(dataloader,model,loss_fn,optimizer,t):
size = len(dataloader.dataset)
for batch,(x,y) in enumerate(dataloader):
pred = model(x)
loss = loss_fn(pred.squeeze(),y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 30 == 0:
loss, current = loss.item(), batch * len(x)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# writer.add_scalar('training loss',loss / 100, t*len(x)+batch//100)
# 模型测试过程
def test_loop(dataloader,model,loss_fn):
size = len(dataloader.dataset)
num_batchs = len(dataloader)
test_loss,correct = 0,0
with torch.no_grad():
for x,y in dataloader:
pred = model(x)
test_loss = loss_fn(pred.squeeze(),y).item()
correct += pred.argmax(1).sum().item()
test_loss /= num_batchs
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
if __name__ == '__main__':
#1.数据读取
train_path = './train_set.csv'
dataset1 = Mydata(train_path)
train_data_1 = DataLoader(dataset1,batch_size = 2,shuffle = True,drop_last = True)
val_path = './val_set.csv'
dataset2 = Mydata(val_path)
val_data_1 = DataLoader(dataset2,batch_size = 2,shuffle = True,drop_last = True)
model = NeuralNetwork()
# 模型形状保存(这一步不是必须的)
writer = SummaryWriter('run1/fashion_mnist_experiment_1')
test = torch.ones(1,39)
writer.add_graph(model, test)
writer.close()
# 3.模型训练
# 3.1超参设置
learning_rate = 1e-3
epochs = 3
# 3.2.设置损失函数和优化函数
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 3.3.开始训练
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train_loop(train_data_1, model, loss_fn, optimizer,t)
test_loop(val_data_1, model, loss_fn)
#模型保存
torch.save(model, 'model.pth')
print("Done!")