opencv 入门笔记四 ROI(Range Of Interest),部分区域截取
预备知识:
opencv读取彩色图像格式为bgr,并非rgb.
OpenCV使用BGR而非RGB格式 - pluviophile - 博客园
OpenCV与Python之图像的读入与显示以及利用Numpy的图像转换 - Dean-Feng - 博客园
1.截取三通道彩色图像的部分区域复制到其他区域:
(前两天看了一篇文章是关于小目标检测的,文中提到,神经网络进行小目标检测的一大挑战是图片中小目标的数量太少,而训练是基于大量的样本数据的,所以训练效果不好。为了增加小目标的数量,经常手工在图片中增加小目标的数量,对图片进行预处理。ROI截取部分区域,可以很好的做到这一点)
(当然了,如果不想手工增加,可以先用已有的比较成熟的目标检测算法得到目标的预测框,根据bounding box进行ROI区域截取,复制到当前图片中,增加目标数量,保存新的图片,从中选择合适的图片作为训练数据集,这种方法也称之为半手工标注)
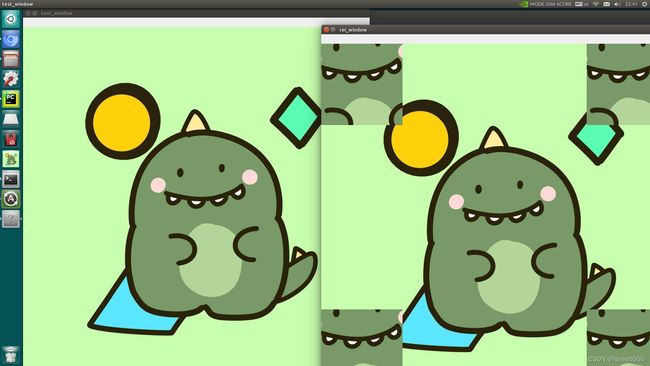
1.1代码:
#!/usr/bin/python3
import cv2 as cv
# 读取图片文件
img = cv.imread("/home/newj/my_sh/.png")
cv.imwrite("original_pic.png",img)
# 显示图片尺寸
print(img.shape)
# 显示图片
cv.imshow("test_window", img)
# 截取像素420-660的位置
roi = img[420:660, 420:660]
# 截取的部分复制给原图像的四个角
img[0:240, 0:240] = roi
img[784:1024, 784:1024] = roi
img[0:240, 784:1024] = roi
img[784:1024, 0:240] = roi
# 显示处理后的图像
cv.imshow("roi_window", img)
# 保存处理后的图像
cv.imwrite("roi_copy.png", img)
# 阻塞等待键盘响应
key = cv.waitKey(0)
# 输入q退出
if key == ord('q'):
cv.destroyAllWindows()
2.截取三通道彩色图像的某一通道:
(在一些特殊的场景下,我们在神经网络处理过程中或许只需要一个颜色通道的图像数据,降低对硬件cpu或者显存的要求,就能达到我们想要的训练效果,这个时候我们可以截取单通道数据进行处理和训练,当然了也可以进行灰度图转换,根据具体情况而定)

2.1代码:
#!/usr/bin/python3
import cv2 as cv
# 读取图片文件
img = cv.imread("/home/newj/my_sh/.png")
cv.imwrite("original_pic.png", img)
# 显示图片尺寸
print(img.shape)
# 显示图片
cv.imshow("test_window", img)
######以下参数0,1,2,固定,因为opencv读入颜色通道按照bgr格式#######
# 截取蓝色通道
roi_b = img[:, :, 0]
# 截取绿色通道
roi_g = img[:, :, 1]
# 截取红色通道
roi_r = img[:, :, 2]
# 显示处理后的图像
cv.imshow("roi_b", roi_b)
# 显示处理后的图像
cv.imshow("roi_g", roi_g)
# 显示处理后的图像
cv.imshow("roi_r", roi_r)
# 保存处理后的图像
cv.imwrite("roi_b.png", roi_b)
# 保存处理后的图像q
cv.imwrite("roi_g.png", roi_g)
# 保存处理后的图像
cv.imwrite("roi_r.png", roi_r)
# 阻塞等待键盘响应
key = cv.waitKey(0)
# 输入q退出
if key == ord('q'):
cv.destroyAllWindows()
3.三通道彩色图像通道的截取和合并:
b,g,r = cv2.split(img) #截取三个通道,但这样做比较耗时
img = cv2.merge((b,g,r))4.最后,一起进步!