tensorflow02
线性回归
连续值得预测
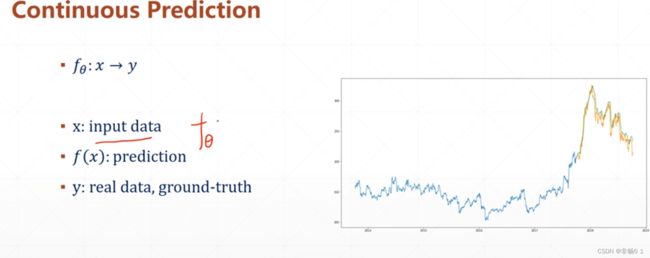
图中黄线越贴合蓝线,说明模型f越好,预测越准
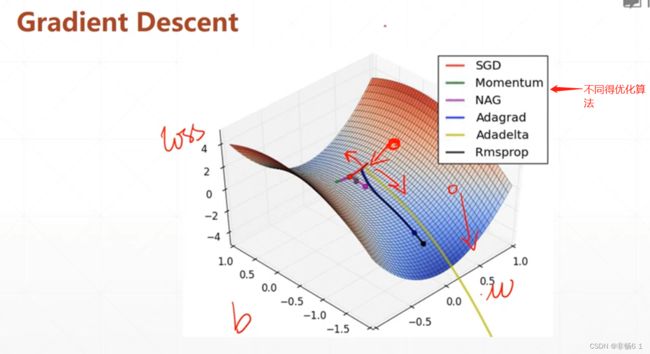
找w和b,转换找loss极小值


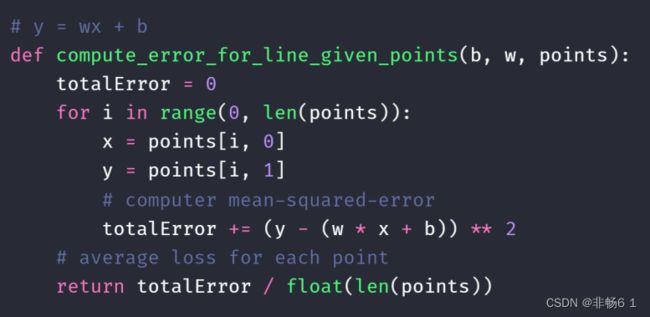
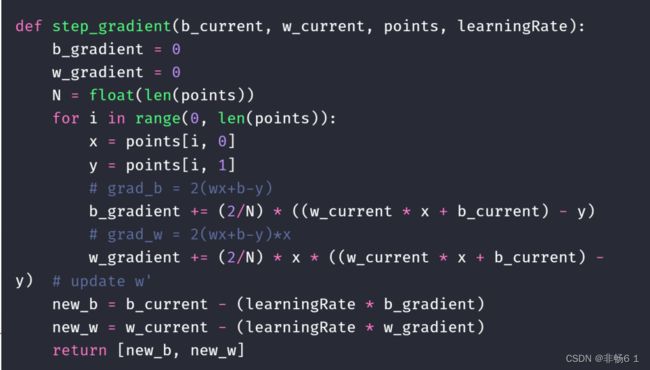
回归问题实战

手写数字问题


import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
(x, y), (x_val, y_val) = datasets.mnist.load_data()
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
print(x.shape, y.shape)
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
train_dataset = train_dataset.batch(200)
model = keras.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(10)])
optimizer = optimizers.SGD(learning_rate=0.001)
def train_epoch(epoch):
# Step4.loop
for step, (x, y) in enumerate(train_dataset):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# Step1. compute output
# [b, 784] => [b, 10]
out = model(x)
# Step2. compute loss
loss = tf.reduce_sum(tf.square(out - y)) / x.shape[0]
# Step3. optimize and update w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)
# w' = w - lr * grad
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'loss:', loss.numpy())
def train():
for epoch in range(30):
train_epoch(epoch)
if __name__ == '__main__':
train() 

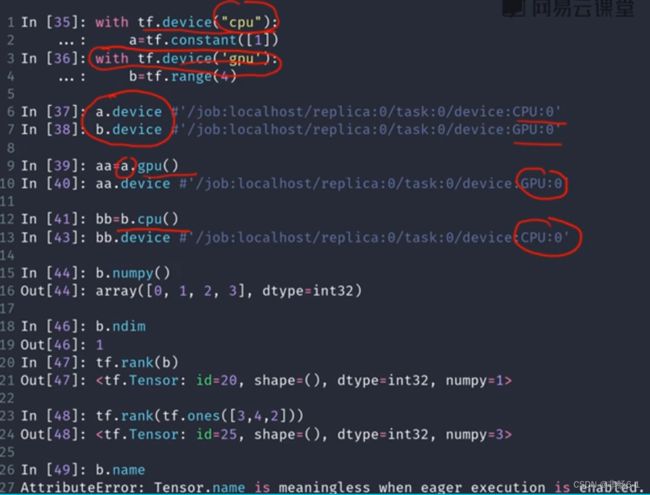
数据类型

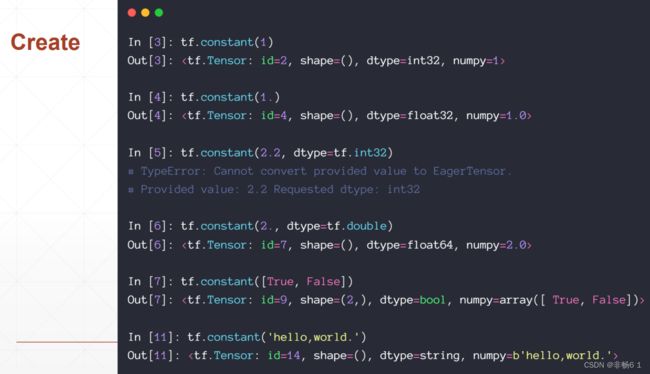

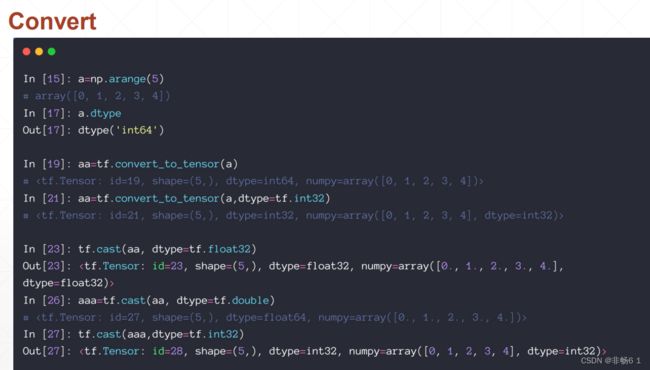
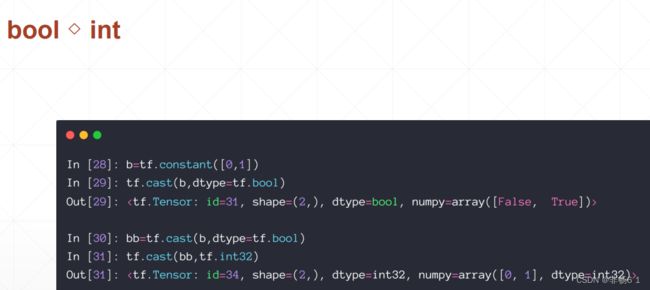
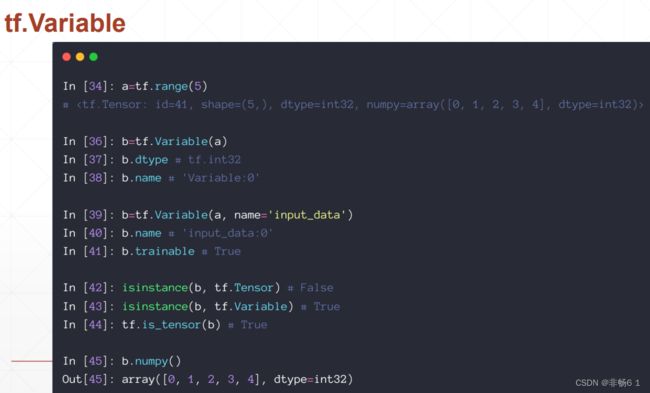
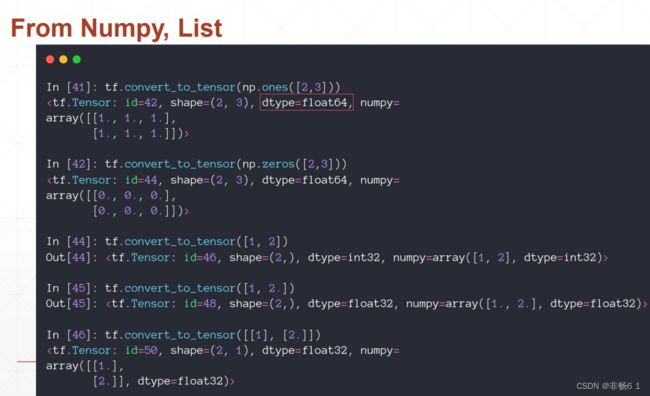
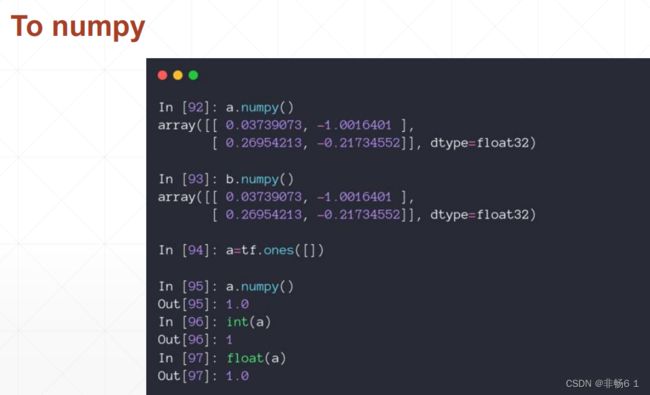 创建Tensor
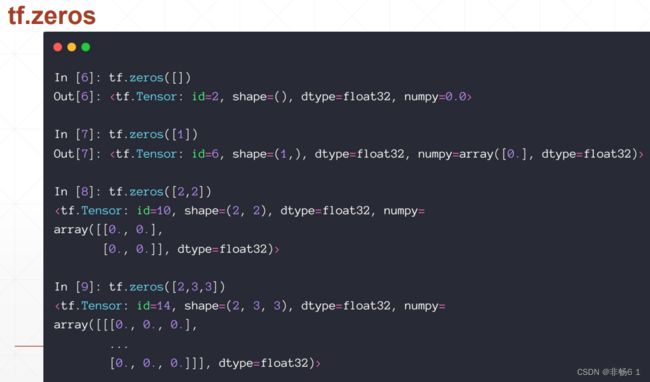
创建Tensor

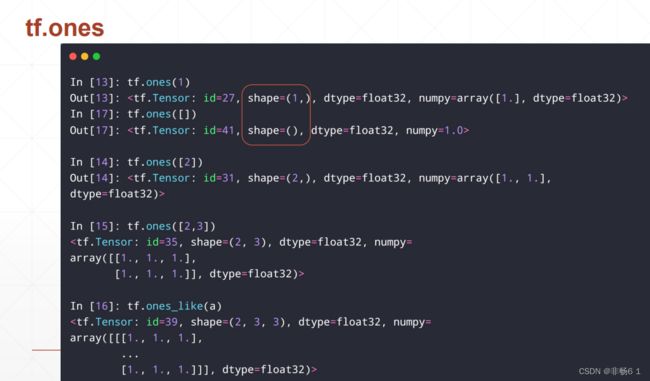
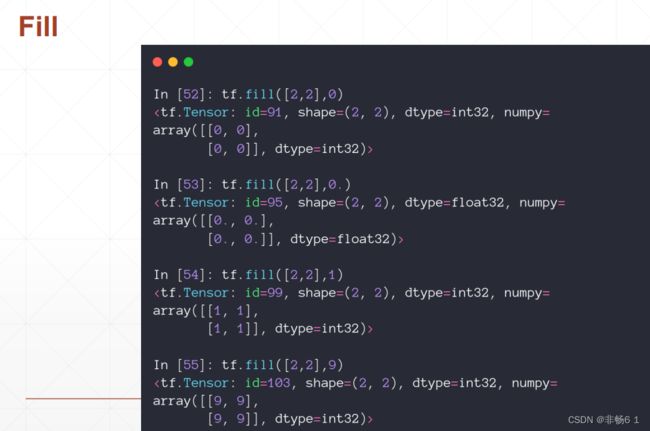
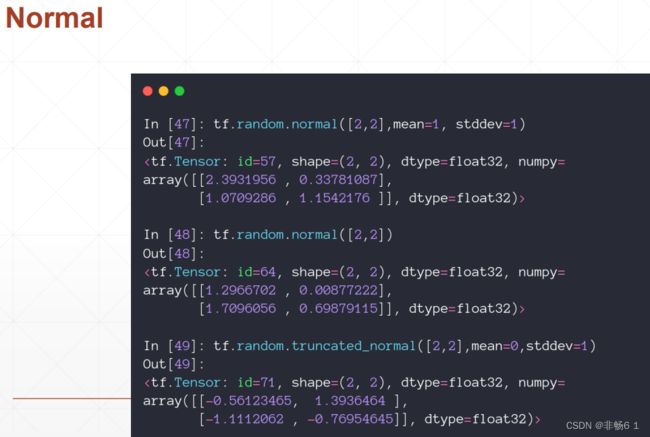

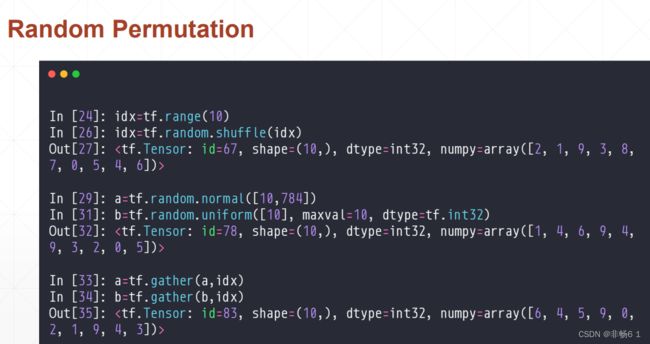

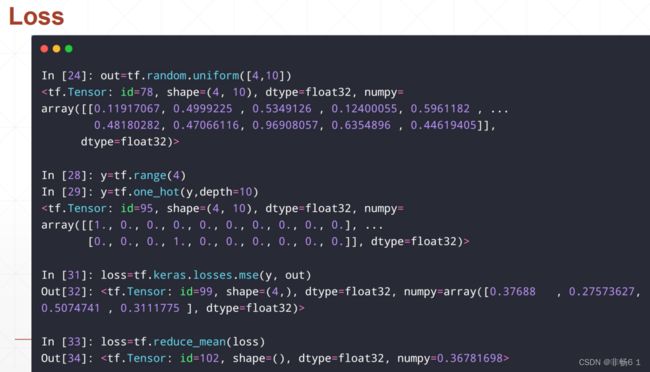
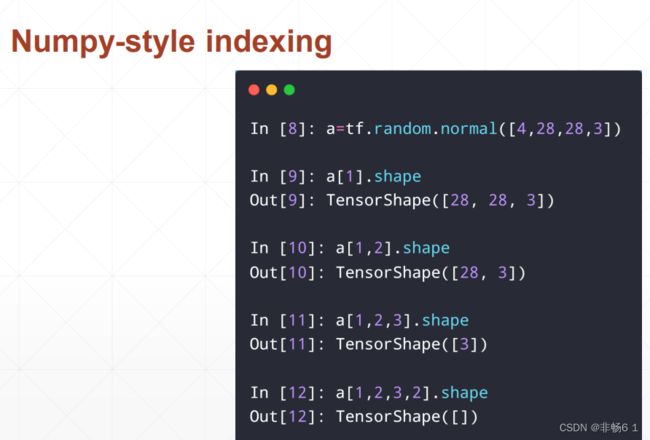
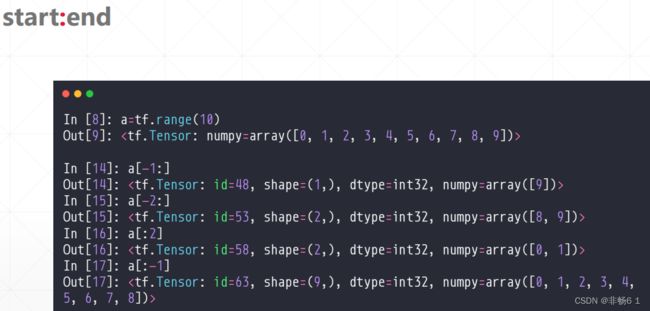
索引

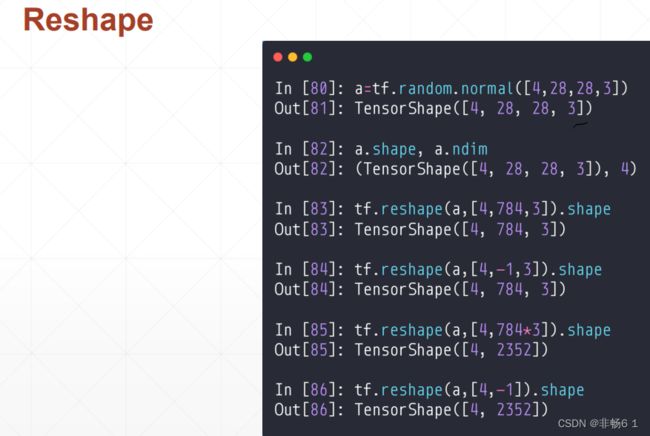
维度变换

Broadcasting

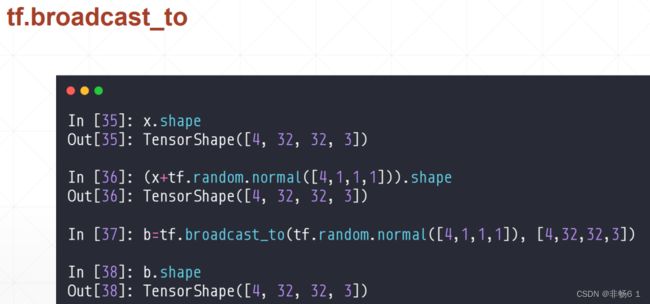
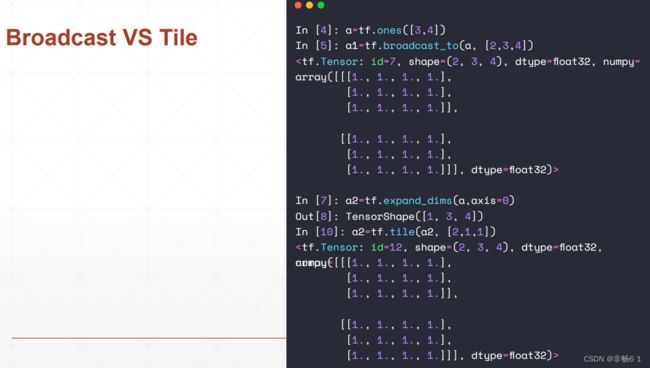
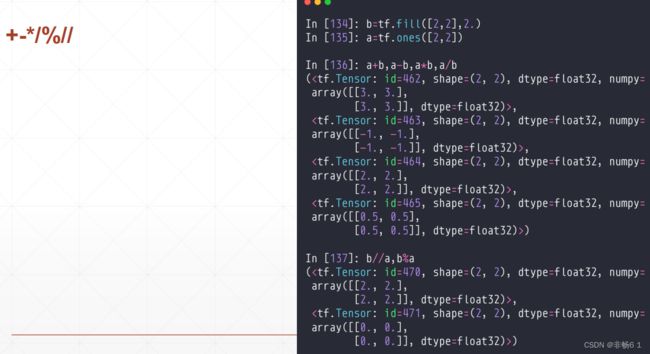
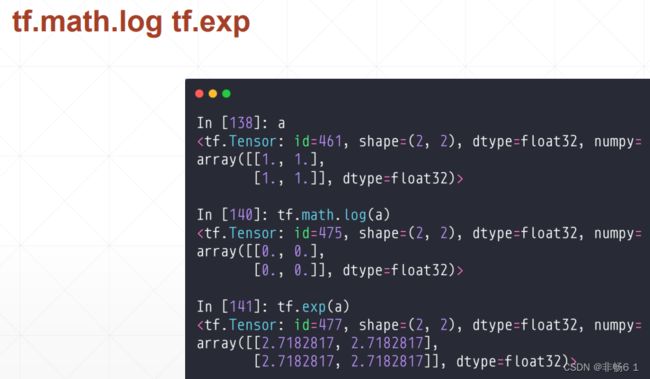
数学运算


前向传播(张量)

import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# x: [60k, 28, 28],
# y: [60k]
(x, y), _ = datasets.mnist.load_data()
# x: [0~255] => [0~1.]
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.int32)
print(x.shape, y.shape, x.dtype, y.dtype)
print(tf.reduce_min(x), tf.reduce_max(x))
print(tf.reduce_min(y), tf.reduce_max(y))
train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128)
train_iter = iter(train_db)
sample = next(train_iter)
print('batch:', sample[0].shape, sample[1].shape)
# [b, 784] => [b, 256] => [b, 128] => [b, 10]
# [dim_in, dim_out], [dim_out]
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
lr = 1e-3
for epoch in range(10): # iterate db for 10
for step, (x, y) in enumerate(train_db): # for every batch
# x:[128, 28, 28]
# y: [128]
# [b, 28, 28] => [b, 28*28]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape: # tf.Variable
# x: [b, 28*28]
# h1 = x@w1 + b1
# [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b, 256] + [b, 256]
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1)
# [b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# [b, 128] => [b, 10]
out = h2@w3 + b3
# compute loss
# out: [b, 10]
# y: [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# mse = mean(sum(y-out)^2)
# [b, 10]
loss = tf.square(y_onehot - out)
# mean: scalar
loss = tf.reduce_mean(loss)
# compute gradients
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# print(grads)
# w1 = w1 - lr * w1_grad
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
if step % 100 == 0:
print(epoch, step, 'loss:', float(loss))