论文笔记:CycleISP: Real Image Restoration via Improved Data Synthesis
摘要
(1)对于单图像降噪问题,捕获真实数据集是不可接受的昂贵且麻烦的过程。 因此,图像去噪算法大部分是根据合成数据开发和评估的,而合成数据通常是在广泛假定加性高斯白噪声(AWGN)的前提下生成的。
(2)尽管CNN在这些合成数据集上取得了令人印象深刻的结果,但如在最近的基准数据集中所报道的那样,当将它们应用于真实的相机图像时,它们的表现并不理想。 这主要是因为AWGN不足以对真实的相机噪声进行建模,而实际的相机噪声取决于信号并由相机成像管道进行大量转换。
(3)本文中,作者提出了一个框架,该框架可以在正向和反向方向上对相机成像管道进行建模。 它使我们能够生成任意数量的逼真的图像对,以在RAW和sRGB空间中进行降噪。 通过在逼真的合成数据上训练新的图像去噪网络,我们在真实的相机基准数据集上实现了最先进的性能。 我们模型中的参数比以前用于RAW降噪的最佳方法小约5倍。 此外,我们证明了所提出的框架可以推广到图像去噪问题之外,例如,用于立体电影院中的色彩匹配。
1. Introduction
-
获取噪声配对数据的典型过程是拍摄同一场景的多个噪声图像,并通过逐像素平均生成干净的真实图像。实际上,由于照明条件和相机/物体运动的变化,不可避免地会出现空间像素不对齐,颜色和亮度不匹配的情况。
-
而且,由于不同的相机传感器表现出不同的噪声特性,因此需要重复使用昂贵昂贵的获取图像对的练习。 因此,单个图像去噪主要是在合成环境中形成的:拍摄大量干净的sRGB图像并添加合成噪声以产生其噪点。
-
在合成数据集上,现有的基于深度学习的降噪模型可产生比较好的结果,但与传统方法相比,它们对真实相机数据的泛化性较差。 最近的基准测试也证明了这一点。 此类行为源于以下事实:对深层CNN进行合成数据训练,该合成数据通常是在加性高斯白噪声(AWGN)假设下生成的。 真实的摄像头噪声从根本上不同于AWGN,从而给深层CNN带来了重大挑战。
(1)在本文中,作者提出了一种合成数据生成方法,该方法可以在RAW和sRGB空间中均产生逼真的噪声图像。 主要思想是将噪声引入通过我们学到的设备不可知转换(device-agnostic transformation)获得的RAW图像中,而不是直接注入sRGB图像中。
(2)我们框架背后的关键想法是:sRGB图像中存在的真实噪声被常规的图像信号处理(image signal processing, ISP)管道中执行的一系列步骤所困扰。
(3)因此,与RAW Sensor数据相比,用sRGB建模真实的相机噪声是一项固有的难题。 举例来说,RAW Sensor空间的噪声取决于信号。 去马赛克后,它成为时空相关的。 在通过管道的其余部分后,其概率分布不一定保持高斯分布。 这意味着相机的ISP会严重改变Sensor的噪声,因此,与统一的AWGN模型相比,需要更复杂的模型来考虑成像管道的影响来合成真实的噪声。
- 为了利用Internet上可用的sRGB照片的丰富性和多样性,提出的合成方法的主要挑战是如何将它们转换回RAW测量。 布鲁克斯等人提出了一种技术,可逐步将相机ISP反转,从而实现从sRGB到RAW数据的转换。 但是,这种方法需要有关目标相机设备的先验信息(例如,色彩校正矩阵和白平衡增益),这使其特定于给定设备,因此缺乏通用性。 此外,相机管线中的一些操作是专有的,并且这种黑匣子很难逆向工程。
为了解决这些挑战,在本文中,作者提出了一个Cycle ISP框架,该框架将sRGB图像转换为RAW数据,然后再转换回sRGB图像,而无需任何相机参数知识。 此属性使我们能够在RAW和sRGB空间中合成任意数量的干净逼真的噪点图像对。
本文的贡献:
- 学习一种与设备无关的转换:即Cycle ISP,该转换使我们可以在sRGB和RAW图像空间之间来回转换。
- 真实图像噪声合成器:用于在RAW和sRGB空间中生成干净/有噪声的配对数据。
- 具有双重关注机制的深层CNN可在多种任务中有效:(1)学习Cycle ISP,(2)合成真实的噪声, (3)图像降噪。
- 从RAW和sRGB图像中去除噪声的算法:在DND 和SIDD 的实际噪声基准上设置了最新的技术水平(见图1)。 而且,我们的降噪网络的参数(2.6M)比以前的最佳模型(11.8M)少得多。
- Cycle ISP框架不仅可以进行去噪处理而且可以进行泛化:我们通过其他应用程序(即立体电影院中的色彩匹配)进行了演示。

图1显示了:对来自DND数据集中真实的摄像机图像进行降噪。 作者的模型可有效消除真实噪声,尤其是低频色度和缺陷像素噪声。
2. Related Work
- 去噪的经典方法主要基于以下两个原理。
(1)使用DCT ,小波等修改变换系数。
(2)平均邻域值:在所有方向上使用高斯核,仅当像素具有相似的值并沿着轮廓时,才在所有方向上显示。 - NLM方法利用自然图像中存在的冗余或自相似性。,去噪效果较好。
- 在大型合成噪声数据集上训练简单的多层感知器(MLP)。 与以前的复杂算法相比,该方法表现良好。 几种最新的方法使用深的CNN,并证明了有希望的降噪性能。
- 图像去噪可以应用于RAW或sRGB数据。 然而,捕获各种大规模的真实噪声数据是一个昂贵而乏味的过程,因此,我们不得不在合成环境中研究降噪。用于开发和评估图像去噪的最常用噪声模型是AWGN。 这样,为AWGN设计的算法无法有效地消除真实图像中的噪声,如最近的基准测试所报道的。 真实RAW传感器噪声的更准确模型包含信号相关的噪声成分 (散粒噪声, shot noise) 和信号独立的加性高斯分量 (读取噪声, read noise)。
- 相机ISP将RAW Sensor噪声转换为复杂形式(时空相关,不一定是高斯分布)。 因此,估计用于在sRGB空间中进行降噪的噪声模型需要仔细考虑ISP的影响。
在本文中,作者提出了一个框架,该框架能够合成用于训练CNN的有效噪声数据,以有效地去除RAW和sRGB图像中的噪声。
3. CycleISP
为了合成真实的噪声数据集,需要两个阶段:
第一个阶段:作者设计了一个框架,该框架可以在正向和反向对摄像机ISP进行建模。
第二个阶段:使用CycleISP,我们合成了逼真的噪声数据集用于RAW去噪和sRGB图像的去噪任务。
在本节中,我们仅描述将Cycle ISP建模为深度CNN系统的CycleISP框架。 图2显示了CycleISP模型的模块:(a)RGB2RAW网络分支,和(b)RAW2RGB网络分支。 此外,我们引入了一个辅助色彩校正网络分支(The auxiliary color correction),该分支为RAW2RGB网络提供了显式的色彩注意,能正确的恢复原始sRGB图像。
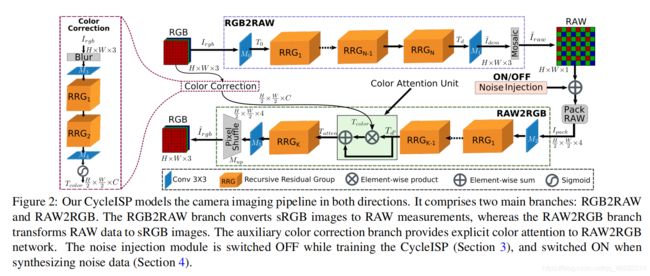
- 图2显示了:CycleISP可以在两个方向上对相机成像管道进行建模。 它包括两个主要分支:RGB2RAW和RAW2RGB。 RGB2RAW分支将sRGB图像转换为RAW测量,而RAW2RGB分支将RAW数据转换为sRGB图像。 辅助色彩校正分支(The auxiliary color correction)为RAW2RGB网络提供了明确的色彩注意。 训练CycleISP时,噪声注入模块(Noise injection)将关闭(第3节),而在合成噪声数据时,噪声注入模块(Noise injection)将打开(第4节)。
图2中的噪声注入模块(Noise injection)仅在合成噪声数据时才需要(第4节),因此我们在学习CycleISP时将其保持在“ OFF”状态。 CycleISP的训练过程分为两个步骤:首先独立地训练RGB2RAW和RAW2RGB网络,然后执行联合微调。 请注意,我们使用RGB而不是sRGB来避免符号混乱。
3.1. RGB2RAW Network Branch
数码相机对RAW传感器数据进行一系列操作,以生成可用于显示器的sRGB图像。
- 作者设计的的RGB2RAW网络分支旨在反转相机ISP的效果。 与(之前CVPR2019的一篇论文)的未处理技术相比,RGB2RAW分支不需要任何相机参数。
- 给定输入的RGB图像 I r g b ∈ R H × W × 3 I_{rgb}∈R^{H×W×3} Irgb∈RH×W×3,RGB2RAW网络首先使用卷积层 M 0 M_0 M0提取低级特征 T 0 ∈ R H × W × C T_0∈R^{H×W×C} T0∈RH×W×C,如: T 0 = M 0 ( I r g b ) T_0 = M_0(I_{rgb}) T0=M0(Irgb)。 接下来,我们通过N个递归残差组(recursive residual groups, RRG)传递低级特征图 T 0 T_0 T0,以提取深特征 T d ∈ R H × W × C T_d∈R^{H×W×C} Td∈RH×W×C:
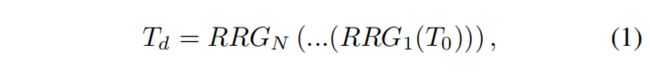
每个RRG包含多个双重注意力块。
然后,我们将最终卷积运算 M 1 M_1 M1应用于特征 T d T_d Td,并获得去马赛克图像 I ^ d e m ∈ R H × W × 3 \hat{I}_{dem}∈R^{H×W×3} I^dem∈RH×W×3。 我们特意将 M 1 M_1 M1层的输出通道数设置为3,而不是1,以便尽可能保留原始图像的结构信息。 此外,我们从经验上发现,它有助于网络更快更准确地学习从sRGB到RAW的映射。
在这一点上,网络能够反转色调映射,伽玛校正,色彩校正,白平衡和其他变换的效果,并为我们提供图像 I ^ d e m \hat{I}_{dem} I^dem,其值与场景辐射度(光芒)线性相关。 最后,为了生成镶嵌的RAW输出 I ^ d e m ∈ R H × W × 1 \hat{I}_{dem}∈R^{H×W×1} I^dem∈RH×W×1,将Bayer采样函数 f B a y e r f_{Bayer} fBayer应用于 I ^ d e m \hat{I}_{dem} I^dem,根据Bayer模式,每个像素省略两个颜色通道:
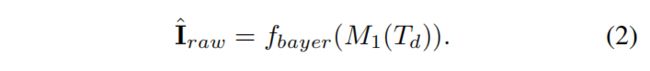
RGB2RAW网络使用线性域和对数域中的 L 1 L_1 L1 LOSS进行了优化,如下所示:
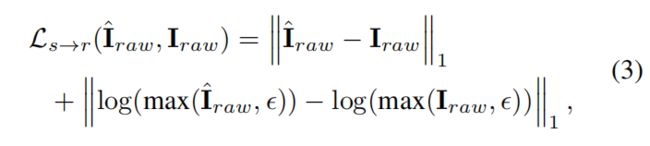
ε ε ε其中是一个数值稳定的小常数,而 I r a w I_{raw} Iraw是真实的RAW图像。 对数损失项被添加以对所有图像值实施近似相等的处理; 否则,网络将致力于恢复高光区域(the highlight regions)。
3.2. RAW2RGB Network Branch
尽管RAW2RGB网络的最终目标是为sRGB图像降噪问题生成合成的现实噪声数据,但在本节中,我们首先描述如何将干净的RAW图像映射到干净的sRGB图像(保留噪声注入模块图2中的“OFF”)。
令 I r a w I_{raw} Iraw和 I ^ r g b \hat{I}_{rgb} I^rgb为RAW2RGB网络的输入和输出。这里的 I r a w I_{raw} Iraw 是相机原始的 RAW 图,不是 RGB2RAW 的输出,因为这两个 branch 是分开独立训练的。
-
首先,为了恢复翻译不变性并降低计算成本,我们将 I r a w I_{raw} Iraw的2×2块打包为四个通道(RGGB),从而将图像分辨率降低了一半。由于输入的RAW数据可能来自具有不同Bayer模式的不同相机,因此我们通过应用Bayer模式统一技术来确保打包图像的通道顺序为RGGB。
-
接下来,由K - 1个RRG模块组成的卷积层 M 2 M_2 M2将打包的RAW图像 I p a c k ∈ R H 2 × W 2 × 4 I_{pack}∈R^{\frac{H}{2}×\frac{W}{2}×4} Ipack∈R2H×2W×4编码为深特征张量 T d ′ ∈ R H 2 × W 2 × 4 T_{d^′}∈R^{\frac{H}{2}×\frac{W}{2}×4} Td′∈R2H×2W×4为:
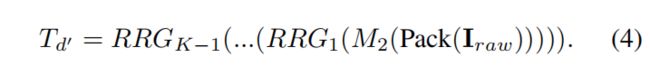
-
请注意, I r a w I_{raw} Iraw是原始相机RAW图像(而不是RGB2RAW网络的输出),因为我们的目标是首先独立学习从RAW到sRGB的映射。
3.2.1 Color attention unit.
为了训练CycleISP,作者使用MIT-Adobe FiveK数据集,该数据集包含来自具有不同和复杂ISP系统的几个不同摄像机的图像。CNN很难为所有不同类型的相机准确学习RAW到sRGB的映射功能(因为一个RAW图像可能会映射到许多sRGB图像)。 一种解决方案是为每个摄像机ISP训练一个网络。 但是,此类解决方案不可扩展,并且性能可能无法推广到其他相机。 为了解决此问题,我们建议在RAW2RGB网络中包括一个颜色注意单元(color attention unit),该单元通过色彩校正分支(color correction branch)提供显式的颜色注意。
色彩校正分支(color correction branch)是一个CNN,它以sRGB图像 I r g b I_{rgb} Irgb作为输入,并生成色彩编码的深度特征张量 T c o l o r ∈ R H 2 × W 2 × C T_{color}∈R^{\frac{H}{2}×\frac{W}{2}×C} Tcolor∈R2H×2W×C。 在颜色校正分支中,我们首先将高斯模糊应用于 I r g b I_{rgb} Irgb,然后再使用卷积层 M 3 M_3 M3,两个RRG和具有S型激活 σ σ σ的门控机制:
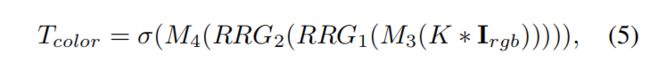
其中∗表示卷积,K是高斯核,根据经验将标准差设置为12。该高斯模糊运算可确保只有颜色信息才能通过该分支,而结构内容和精细纹理来自于主要的RAW2RGB网络。 使用较弱的模糊会破坏等式的特征张量 T d ′ T_{d^′} Td′的有效性。
整个颜色注意力单元(color attention unit)处理过程为:
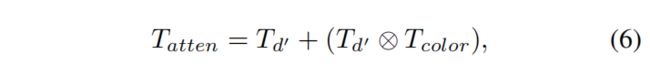
⊗是 Hadamard product(矩阵对应元素相乘)。 为了获得最终的sRGB图像 I ^ r g b \hat{I}_{rgb} I^rgb,来自颜色注意单元(color attention unit)的输出特征 T a t t e n T_{atten} Tatten分别通过RRG模块,卷积层 M 4 M_4 M4和放大层 M u p M_{up} Mup :
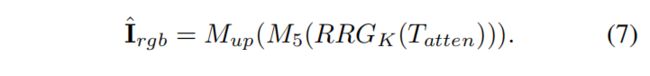
为了优化RAW2RGB网络,我们使用 L 1 L_1 L1 LOSS:

3.3. RRG: Recursive Residual Group
受到最近的基于残差学习框架低级视觉方法的发展的启发,作者提出了RRG模块,如图3所示。
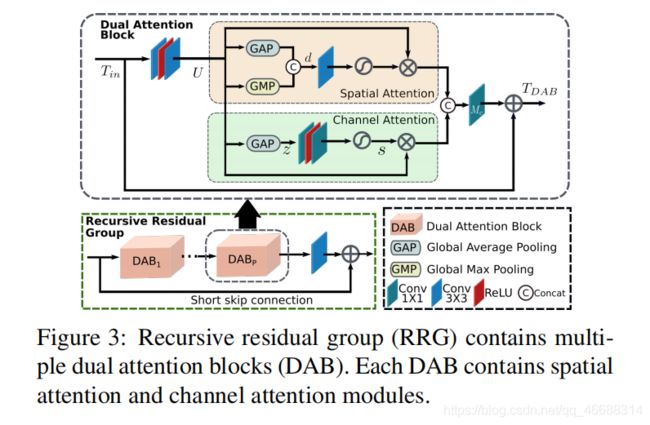
- 图3显示了递归残差组(RRG)包含多个双重注意块(DAB)。 每个DAB都包含空间注意力(spatial attention)和通道注意力(channel attention)模块。
RRG包含P个双重关注块 (DAB)。每个DAB的目的是抑制用处较少的特征,仅允许传播更多有价值的信息。DAB执行该特征的重新校准使用两种注意力机制:(1)通道注意( channel attention,CA)和(2)空间注意(spatial attention,SA)。整个过程是:
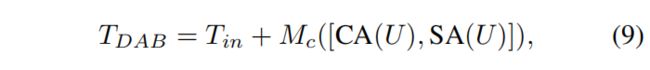
其中 U ∈ R H × W × C U∈R^{H×W×C} U∈RH×W×C表示特征图,该特征图是通过在DAB的开始对输入张量 T i n ∈ R H × W × C T_{in}∈R^{H×W×C} Tin∈RH×W×C进行两次卷积而获得的, M c M_c Mc是最后一个滤波器大小为1×1的卷积层 。
3.3.1 Channel attention
该分支旨在利用卷积后的特征通道之间的依赖性。 它首先执行挤压操作以对空间全局上下文进行编码,然后执行激励操作以完全捕获通道方向的关系。通过在特征图 U U U上应用全局平均池化(global average pooling, GAP)来实现挤压操作,从而生成描述符 z ∈ R 1 × 1 × C z∈R^{1×1×C} z∈R1×1×C。 激励算子使用两个卷积层重新校正描述符z,然后进行Sigmoid激活,并得到 s ∈ R 1 × 1 × C s∈R^{1×1×C} s∈R1×1×C。 最后,通过用激活s重新缩放U来获得CA分支的输出。
3.3.2 Spatial attention
- 该分支利用特征空间的内部关系并计算空间注意力图(spatial attention map),然后将其用于rescale (传入的特征U)。
- 为了生成空间注意力图(spatial attention map),首先对特征U独立地沿着通道维度应用全局平均池化和最大池化操作,并且连接输出图以形成空间特征描述符 d ∈ R H × W × 2 d∈R^{H×W×2} d∈RH×W×2。 接下来是卷积和Sigmoid激活,以获得空间注意力图(spatial attention map)。
3.4. Joint Fine-tuning of CycleISP
由于RGB2RAW和RAW2RGB网络最初是独立训练的。所以由于它们之间的断开连接,它们可能无法提供最佳质量的图像。 因此,我们执行联合微调(joint fine-tuning),其中RGB2RAW的输出成为RAW2RGB的输入。 联合优化的损失函数为:
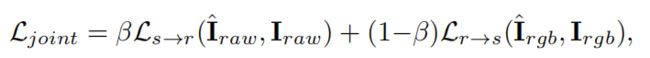
其中β是一个正的常数。 请注意,RAW2RGB网络从RAW2RGB 的子损失项(sub-loss)(仅第二项)接收梯度。 而RGB2RAW网络从两个子损失中接收梯度,从而有效地帮助了最终sRGB图像的重建。
4. Synthetic Realistic Noise Data Generation
我们描述了使用提出的CycleISP方法在RAW和sRGB空间中合成真实的噪声图像对 用来进行降噪的过程。
4.1 Data for RAW denoising
-
CycleISP方法的RGB2RAW网络分支将干净的sRGB图像作为输入,并将其转换为干净的RAW图像。在训练CycleISP时我们一直保持关闭的噪声注入模块(noise injection module)现在变为 “ON” 状态。
-
噪声注入模块将不同级别的散粒噪声和读取噪声(shot noise and read noise)添加到RGB2RAW网络的输出中。
-
作者使用与(Unprocessing images for learned raw denoising. In CVPR, 2019)中相同的步骤来采样散粒/读取噪声因子。 这样,就可以从任何sRGB图像生成干净的图像及其相应的噪点图像对 R A W c l e a n , R A W n o i s y {RAW_{clean},RAW_{noisy}} RAWclean,RAWnoisy。
4.2 Data for sRGB denoising
- 给定合成的 R A W n o i s y RAW_{noisy} RAWnoisy图像作为输入,RAW2RGB网络将其映射为一个有噪声的sRGB图像; 因此,我们能够针对sRGB去噪问题生成图像对 s R G B c l e a n , s R G B n o i s y {sRGB_{clean},sRGB_{noisy}} sRGBclean,sRGBnoisy。
- 尽管这些合成图像对已经足够训练去噪网络,但我们可以通过以下步骤进一步提高其质量。
- 我们使用用真实摄像机捕获的SIDD数据集来微调CycleISP模型。 对于每个静态场景,SIDD在RAW和sRGB空间中都包含干净且有噪点的图像对。 微调过程如图4所示。请注意,添加随机噪声的噪声注入模块(noise injection module)被(仅用于微调)每像素噪声残差代替,该残差是通过从像素中减去真实 R A W c l e a n RAW_{clean} RAWclean图像获得的真实的 R A W n o i s y RAW_{noisy} RAWnoisy图像。 一旦微调过程完成,我们就可以通过将干净的sRGB图像馈送给CycleISP模型来合成逼真的噪声图像。
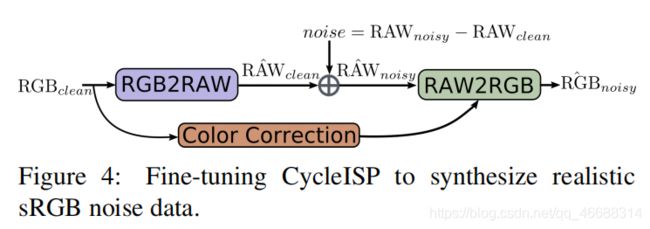
- 图4显示了:微调CycleISP以合成逼真的sRGB噪声数据。
5. Denoising Architecture
如图5所示,我们提出了一种采用多个RRG的图像去噪网络。 我们的目标是在两种不同的设置中应用提出的网络:
(1)对RAW图像进行降噪。
(2)对sRGB数据进行降噪。
我们在两种设置下都使用相同的网络结构,唯一的区别在于输入和输出的处理。
- 为了在sRGB空间中进行降噪,网络的输入和输出是3通道sRGB图像。
- 为了对RAW图像进行降噪,我们的网络将输入的4通道带有噪声打包图像(4-channel noisy packed image)与一个4通道噪声级别的映射(4-channel noise level map)连接在一起,最后得到一个4通道打包的去噪输出(4-channel packed denoised output)。
噪声水平图根据其散粒噪声和读取噪声参数提供对输入图像中噪声标准偏差的估计。
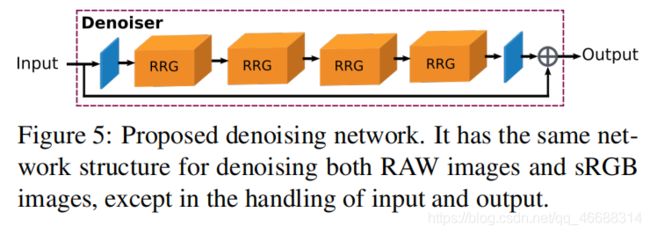
- 图5显示了:提出的降噪网络。 除了处理输入和输出外,它具有用于消除RAW图像和sRGB图像的相同网络结构。