第十章 文本生成
10.1 文本生成简介
10.2 文本生成方法
10.2.1 传统文本生成方法
10.2.2 神经网络文本生成方法
10.2.2.1 回顾
10.2.2.1 自回归方法
10.2.2.2 非自回归方法
10.2.3 文本生成方法对比
10.3 文本生成应用
10.3.1 常见任务
10.3.1.1 文本摘要
10.3.1.2 故事生成(Storytelling)
10.3.1.3 诗歌生成
10.3.1.4 其他应用
10.3.2 可控文本生成
10.3.3 知识指导的文本生成
10.4 当前趋势和未来
10.1 文本生成简介
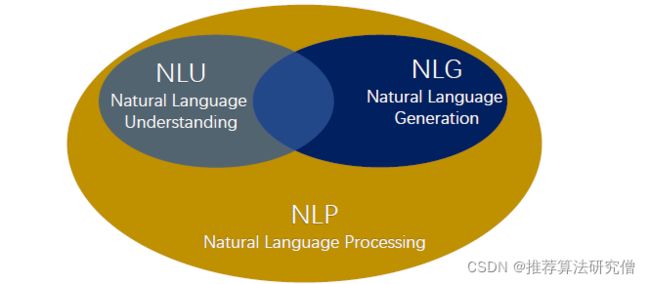
文本生成的定义:从非语言的表示生成人类可以理解的文本,文本->文本、数据->文本都是文本生成任务关注的。上图是NLP领域的几大核心任务,可见,文本生成和文本理解在技术路线上是有着千丝万缕的联系的。
文本生成的任务:
文本生成的任务可以归为以下几项:

机器翻译、对话系统(目标导向、开放式)、故事生成、诗歌生成、文本摘要等
10.2 文本生成方法
10.2.1 传统文本生成方法
 传统文本生成系统架构(流水线)
传统文本生成系统架构(流水线)
10.2.1.1 基于规则/模板
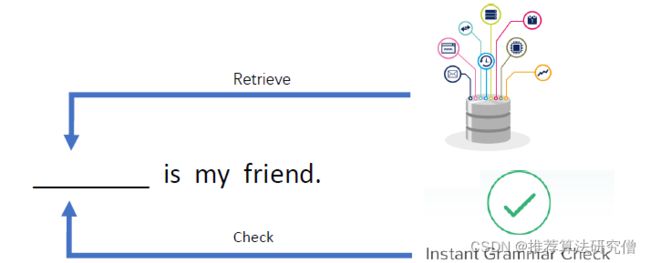
句子模板->搜索答案词->语法检查
10.2.1.2 基于统计
核心思想:根据数据建立统计模型,类似于统计机器翻译的方法。

从数据中得到 (|)和 (),用各种算法计算argmax。
10.2.2 神经网络文本生成方法
10.2.2.1 回顾
语言建模
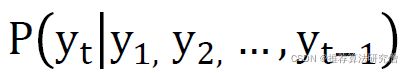
语言建模:给定到目前为止的单词,预测下一个任务。产生这种概率分布的系统称为语言模型。
条件语言建模

条件语言建模:根据给定的单词以及其他一些输入 ,预测下一个单词的任务
比如在机器翻译中,X为原文,Y为译文;在文本摘要中,X为原文,Y为摘要等。
10.2.2.1 自回归方法
给定来源 = (1,2,…,) 和目标 y = (1,2,…,)

主要的语言模型有RNN、Seq2seq、Transformer
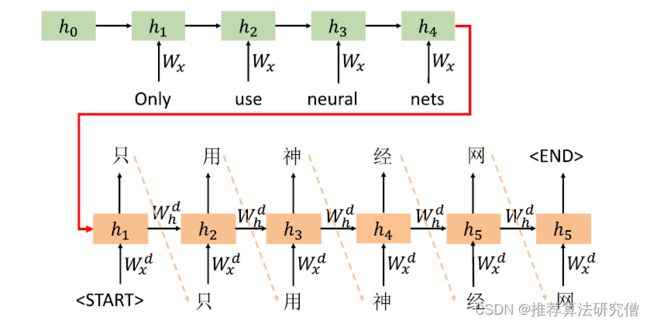
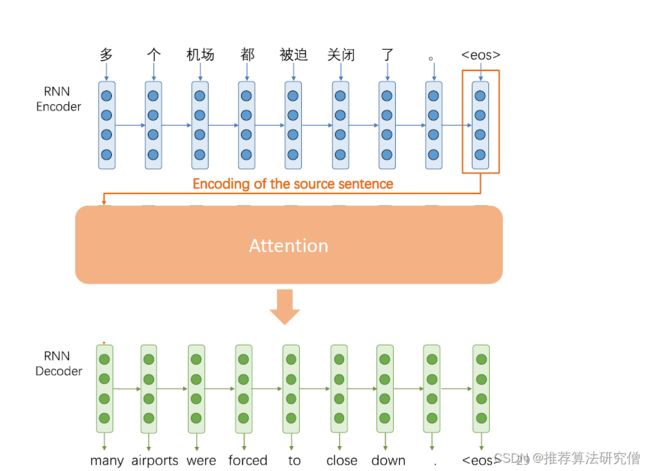
RNN 擅长建模顺序性的信息,可使用RNN作为编码器来构建句子的语义表示;解码算法是一种用于从语言模型生成文本的自回归算法。常见的解码算法有Greedy decoding、Beam search、Sampling-based等
Greedy Decoding
贪婪算通过在解码器上的每一步采用argmax来生成目标句子

由于缺少回溯,输出可能会很差(例如不符合语法,不自然,无意义)
Beam Search Decoding
总体思路:在解码器的每一步,都要跟踪 个最有可能最有可能的部分序列,达到停止条件后,选择概率最高的序列,但不一定是最佳序列。

Beam Size取值的一些问题:
- 小的与贪婪解码会有类似问题 ( 不合语法,荒谬)
- 越大表示考虑的假设越多,但计算量会增高
- 盲目增大会带来其他问题:对于神经机器翻译,增加 过多会降低BLEU得分,对于对话系统大会使输出更通用 (贬义 )
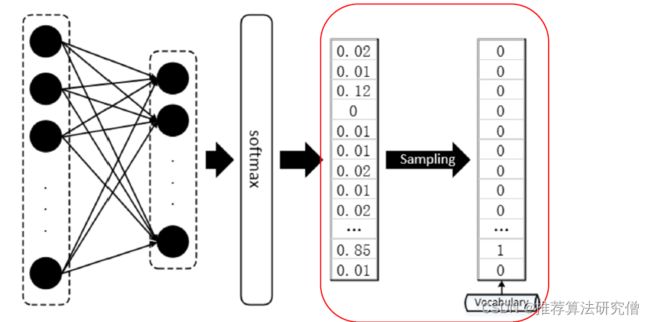
Sampling-based Decoding
Pure sampling
在每个步骤t,从概率分布Pt中随机采样以获得下一个单词
Top-n sampling
在每个步骤t,从 Pt中随机抽样中随机抽样,仅限于前n个最可能的单词
- n=1是greedy search;n=V是pure sampling
- 增加n可以获取更多样化 /风险更高的输出
- 减少n可以获得更通用 /安全输出
两者都比Beam serch高效
Decoding-based文本生成方法的对比:

Attention
流水线方案(类Seq2seq模型)的主要问题:
- 很难将监督信号传播到每个 部分
- 更改任务后,需要从头开始训所有部分
Attention为瓶颈问题提供了解决方案,其核心思想是在解码器的每个步骤,专注于源序列的
特定部分,Attention有助于消除梯度消失问题。
10.2.2.2 非自回归方法
给定来源 = (1,2,…,) 和目标 y = (1,2,…,)

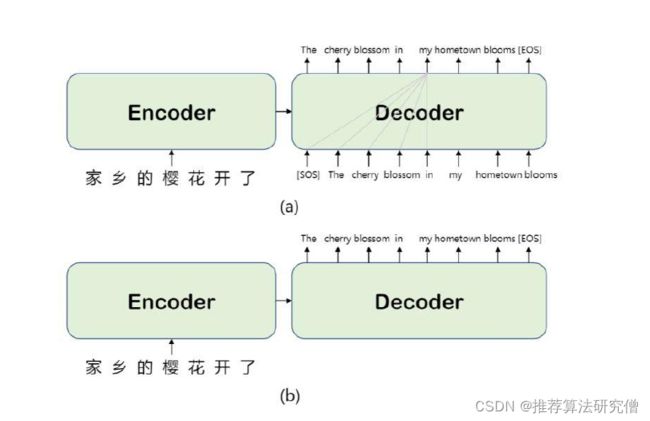
非自回归首先要确定目标序列的长度P(m|x),编码器与自回归编码器相同,输入项 =(;), 并行生成目标序列。
Transformer
动机:RNN系列模型无法并行运算,可以用Transformer的Decoder部分进行文本生成。

GAN-based
动机:GAN在图像生成方面卓有成效,可以将其引入文本生成领域。
问题1:GAN在连续的数据上效果更好,但离散不佳,生成模型的离散输出难以将梯度传递给生 成模型。
前沿进展:Gumbel-softmax、WGAN、WGAN-GP等
问题2:GAN评估器只能评估完整序列,对于部分生成的序列,难以平衡分数。
前沿进展:SeqGAN等
10.2.3 文本生成方法对比
传统方法和神经网络方法对比:

另外传统方法需要很多手工工程和特征工程、系统极其复杂、需单独设计子组件、耗费人力。
自回归方法的特点:
- 解码器的各个步骤必须顺序进行,而不是并行运行
- 时间复杂度较高
- 缺乏全局信息(Transformer的模型试图解决此问题)
非自回归方法的特点:
- 同时解码目标输出
- 快速(比自回归快20倍)
- 在解码期间可以很好地保持上下文信息
- 类似于BERT Masked LM解码
10.3 文本生成应用
10.3.1 常见任务
文本生成任务:机器翻译、对话系统(目标导向、开放式)、故事生成、诗歌生成、文本摘要等
场景:各种数据(图片、表格、提示)->文本,文本 -> 文本
10.3.1.1 文本摘要
场景:文本 -> 文本

1. 提取式:神经网络之前的摘要系统主要是提取式的,标准流程为:内容选择(句子评分函数、基于图的算法)-> 信息排序 -> 句子改写(Sentence Realization)

2. 神经网络方法
神经网络生成式文本摘要系统Seq2seq + attention擅长流畅的输出,但不擅长复制细节。
加入复制机制(Copy mechanisms)使Seq2seq系统能够轻松地将单词和短语从输入复制到输出,复制机制核心和计算下一个词语是生成还是拷贝的概率,可以缓解细节不足的问题。
3. 文本摘要的挑战
- 生成式和提取式的平衡。
- 不擅长覆盖全貌的内容选择,尤其是输入文档很长的情况下。
- 没有选择内容的整体策略。
4. 文本摘要的改进
前神经网络方法分为内容选择和文本生成两阶段。标准的End2End(Seq2seq+attention)方法将两阶段融合,靠解码器生成文本,靠注意力选择内容(词粒度)。但由于缺少全局选择策略,词级内容选择表现不佳,一般解决方案是自下而上的摘要。
自下而上的摘要:

内容选择阶段:使用神经网络标记模型将单词标记为包含或不包含
自下而上的注意阶段:使用Seq2seq+attention。不关注标记为不包含的单词。
10.3.1.2 故事生成(Storytelling)
场景:文本->文本
提示到文本
2018年, [Fan et al]发布了从Reddit的WritingPrompts subreddit 收集的新故事生成数据集,每个 故事都有一个相关的简短写作提示。[Fan et al] 还提出一个复杂的seq2seq提示故事模型。
- 基于卷积
- 使用Gated multi-head multi-scale self-attention
- 模型融合
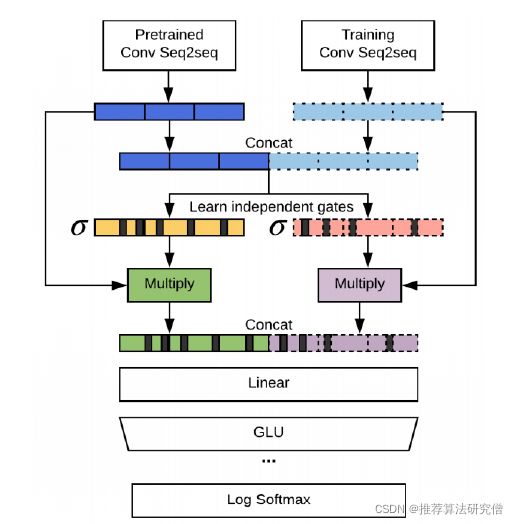
优点:
- 与提示相关
- 多样、非通用
- 极具戏剧性
缺点:
- 主要是氛围的、描述的场景设置,故事情节较少
- 当生成长文本时,大部分停留在相同想法上,缺少推进
事件到文本

故事生成的挑战
- 挑战:基于神经语言模型产生的故事听起来很流利,但是没有意义,也没有连贯的情节。
- 少了什么东西?语言模型对单词序列进行建模,但是故事是事件的序列。
- 要讲一个故事,我们需要理解和建模。(事件因果、角色、世界状况、叙事结构等)。
- 在NLU中,追踪事件、实体的状态非常困难,应用于文本生成就更加困难了。
10.3.1.3 诗歌生成
场景:文本到文本
Hafez: 诗歌生成系统
- 用户提供主题 ,获取一组与主题相关的词
- 识别押韵的主题词, 这些将是每一行的结尾
- 使用受 FSA 约束的 RNN -LM 生成诗歌
- RNN-LM 是倒退的(从右到左) 。这是必需的,因为每行的最后一个单词是固定的。

在后续论文中,作者进一步使该系统具有交互性并且可由用户控制。控制方法很简单:在Beam search期间,增加具有所需特征的单词分数。
10.3.1.4 其他应用
场景:各种数据 -> 文本
图像描述
问题:如何解决缺乏平行数据问题?
方案:使用常见的句子编码空间,使用image captioning数据集学习映射,训练RNN-LM进行解码。

表格到文本

根据病历表格分别给不同人提供不同报告。
10.3.2 可控文本生成
- 语言模型微调
- 条件语言微调
- Plug and play Language Model
10.3.3 知识指导的文本生成
类似人思维过程 ,语言模型捕获知识并生成语言。
Graph Transformer
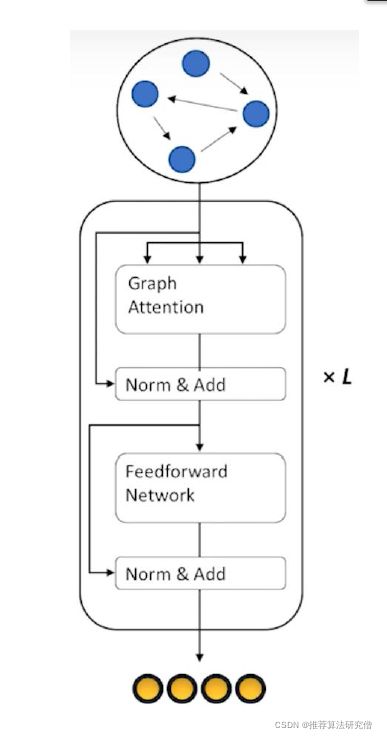
• 适应图结构输入的Transformer编码器
• 数据集 : Knowledge-graph-to-text
• 输入 :节点表示 + 邻接矩阵
• 输出 : 图上下文敏感的节点编码信息
• 无序
• 用于下游任务如文本生成
整体架构


10.4 当前趋势和未来
研究趋势:
1. 融合知识的文本生成
有助于真正需要知识的任务,例如故事生成,面向任务的对话系统等。
2. 取代严格从左到右生成的方法
并行生成,迭代细化,自顶向下生成,可生成更长的文本
3. 由教师强迫(teacher forcing)替代最大似然(maximum likelihood)训练目标
建立考虑更全面的句子级别(而不是单词级别)的目标
发展方向:
文本生成研究正在迅速成熟
- 在NLP+DeepLearning的早期,主要是将神经机器翻译迁移到文本生成。
- 现在,越来越多的关于文本生成的研讨会和竞赛被召开,尤其是针对开放式文本生成。
- 未来,需要有组织的研究社区,提高工作的可复现性,建立标准化评估。
- 目前文本生成技术进展的最大障碍是如何进行有效的评估。