微软自动调参工具 NNI 使用事例教程
第一步:安装
nni的安装通过pip命令就可以安装了。并且提供了example供参考学习。
系统配置要求:tensorflow,python >= 3.5
# 安装nni
python3 -m pip install --upgrade nni
# 示例程序,用于学习
git clone https://github.com/Microsoft/nni.git
# 如果想运行这个示例程序,需要安装tensorflow
python3 -m pip install tensorflow
第二步:设置超参数的搜索范围
NNI的示例程序如下:
cd ./nni/examples/trials/mnist/
三个文件
- config.yml
- mnist.py
- search_space.json
这三个文件决定了NNI配置文件,main.py和超参数搜索空间。
1.打开 search_space.json文件
{
"batch_size": {"_type":"choice", "_value": [16, 32, 64, 128]},
"hidden_size":{"_type":"choice","_value":[128, 256, 512, 1024]},
"lr":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]},
"momentum":{"_type":"uniform","_value":[0, 1]}
}
在这里可以定义我们的超参数和搜索范围,可以根据自己的需要随意调整。
搜索的类型有很多种,常用的有uniform,choice等。
本案例只做了uniform,choice,其他所有案例根据git显示如下:
{"_type": "choice", "_value": options}
# dropout_rate":{"_type":"uniform","_value":[0.5, 0.9]}的结果为0.5或者0.9
{"_type": "uniform", "_value": [low, high]}
# 变量是 low 和 high 之间均匀分布的值。
# 当优化时,此变量值会在两侧区间内。
{"_type": "quniform", "_value": [low, high, q]}
# 从low开始到high结束,步长为q。
# 比如{"_type": "quniform", "_value": [0, 10, 2]}的结果为0,2,4,6,8,10
{"_type": "normal", "_value": [mu, sigma]}
# 变量值为实数,且为正态分布,均值为 mu,标准方差为 sigma。 优化时,此变量不受约束。
{"_type": "randint", "_value": [lower, upper]}
# 从 lower (包含) 到 upper (不包含) 中选择一个随机整数。
第二步:配置config.yaml
打开config.yaml
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 20
#choice: local, remote, pai
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner, MetisTuner, GPTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python mnist.py
codeDir: .
gpuNum: 0
# 基础设置
authorName: az # 必填
experimentName: demo # 必填
trialConcurrency: 5 # 必填,指定同时运行的 Trial 任务的最大数量。
# ! 如果 trialGpuNum 大于空闲的 GPU 数量,并且并发的 Trial 任务数量还没达到 trialConcurrency,Trial 任务会被放入队列,等待分配 GPU 资源。
maxExecDuration: 24h # 可选。 整个调参过程最长运行时间。 默认值:999d。
maxTrialNum: 10 # 可选。 NNI 创建的最大 Trial 任务数。 默认值:99999。
trainingServicePlatform: local # 指定运行 Experiment 的平台,包括 local, remote, pai, kubeflow, frameworkcontroller
# 搜索空间文件
searchSpacePath: search_space.json
useAnnotation: false # 如果 useAnnotation 为 true,searchSpacePath 字段会被删除。
# 日志
logDir: ./log # 可选。 目录的路径。 默认值:/nni-experiments
logLevel: info
# 调参器
tuner:
builtinTunerName: TPE # 指定内置的调参算法
# 运行的命令,以及 Trial 代码的路径
trial:
command: python3 run_demo.py
codeDir: . # 必需字符串。 指定 Trial 文件的目录。
gpuNum: 1 # 可选、整数。 指定了运行每个 Trial 进程的 GPU 数量。 默认值为 0。
# 本机模式下配置,可选。
localConfig:
gpuIndices: 0,3 # 默认值none。设置后,只有指定的 GPU 会被用来运行 Trial 任务。
# ! 和CUDA_VISIBLE_DEVICE=0,3 的效果相同,在程序内部的gpu编号依旧是从0开始的
maxTrialNumPerGpu: 2 # 默认值1。指定1个GPU上最大并发trail的数量
useActiveGpu: false # 默认值false。是否使用已经被其他进程使用的gpu。
除了command,maxExecDuration,trialConcurrency,gpuNum,optimize_mode需要更改,这里的参数一般不需要更改。
command是nni的运行后将要执行的指令,mnist.py改为你的main.py或者train.py等等主程序。
maxExecDuration是整个NNI自动调参的时间,注意不是一次训练的时间。
trialConcurrency是trail的并发数,这个需要根据自己的GPU数量设置,而不是下面的gpuNum,trail代表一次调参的过程,理解为用一种超参数在运行你的train.py,并发数设为x,就有x个trainer在训练!
gpuNum是每个trail所需要的gpu个数,而不是整个nni调参所需要的gpu个数。对于大型任务,单独训练一次需要N个GPU的话,这个值就设置为N;如果单次训练,一个GPU就足够,请把这个值设置为1。
需要的GPU总数为trialConcurrencygpuNum,即 trail的个数每个trail需要的gpu个数
optimize_mode对应着优化的方向,有最大和最小两种方式,具体如何设置在下一步中提到。
第三步 修改我们的代码
"""
A deep MNIST classifier using convolutional layers.
This file is a modification of the official pytorch mnist example:
https://github.com/pytorch/examples/blob/master/mnist/main.py
"""
import os
import argparse
import logging
import nni
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from nni.utils import merge_parameter
from torchvision import datasets, transforms
logger = logging.getLogger('mnist_AutoML')
class Net(nn.Module):
def __init__(self, hidden_size):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, hidden_size)
self.fc2 = nn.Linear(hidden_size, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if (args['batch_num'] is not None) and batch_idx >= args['batch_num']:
break
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args['log_interval'] == 0:
logger.info('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
logger.info('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset), accuracy))
return accuracy
def main(args):
use_cuda = not args['no_cuda'] and torch.cuda.is_available()
torch.manual_seed(args['seed'])
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
data_dir = args['data_dir']
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(data_dir, train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args['batch_size'], shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(data_dir, train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1000, shuffle=True, **kwargs)
hidden_size = args['hidden_size']
model = Net(hidden_size=hidden_size).to(device)
optimizer = optim.SGD(model.parameters(), lr=args['lr'],
momentum=args['momentum'])
for epoch in range(1, args['epochs'] + 1):
train(args, model, device, train_loader, optimizer, epoch)
test_acc = test(args, model, device, test_loader)
# report intermediate result
nni.report_intermediate_result(test_acc)
logger.debug('test accuracy %g', test_acc)
logger.debug('Pipe send intermediate result done.')
# report final result
nni.report_final_result(test_acc)
logger.debug('Final result is %g', test_acc)
logger.debug('Send final result done.')
def get_params():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument("--data_dir", type=str,
default='./data', help="data directory")
parser.add_argument('--batch_size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument("--batch_num", type=int, default=None)
parser.add_argument("--hidden_size", type=int, default=512, metavar='N',
help='hidden layer size (default: 512)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--no_cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--log_interval', type=int, default=1000, metavar='N',
help='how many batches to wait before logging training status')
args, _ = parser.parse_known_args()
return args
if __name__ == '__main__':
try:
# get parameters form tuner
tuner_params = nni.get_next_parameter()
logger.debug(tuner_params)
params = vars(merge_parameter(get_params(), tuner_params))
print(params)
main(params)
except Exception as exception:
logger.exception(exception)
raise
第四步 代码运行
nnictl create --config examples\trials\mnist-pytorch\config_windows.yml --port 8088
切换到代码的目录下,直接运行。
-p代表使用的端口号。注意如果代码使用的是conda虚拟环境,需要激活conda虚拟环境。
第五步 查看训练过程
打开命令行给的网站,如下图
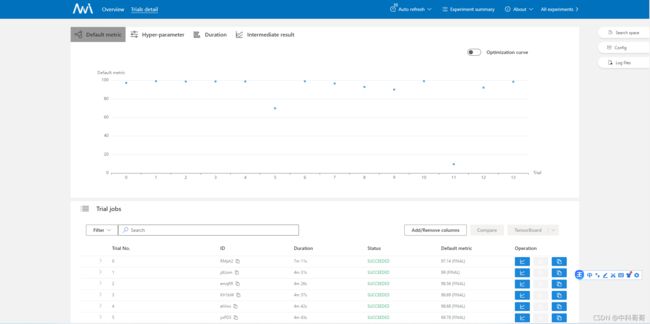
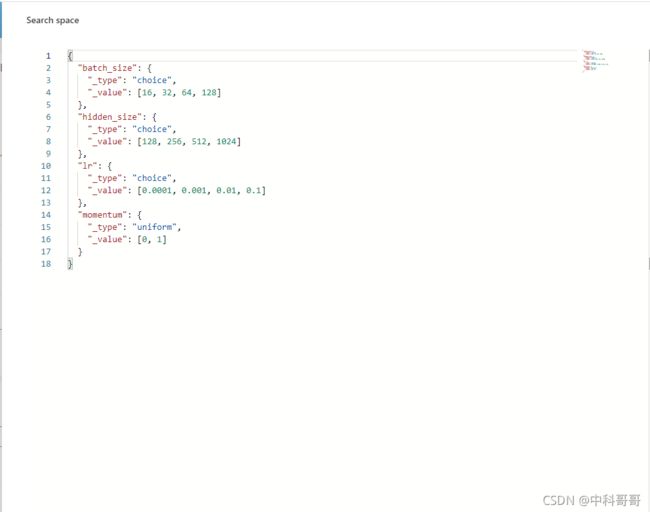
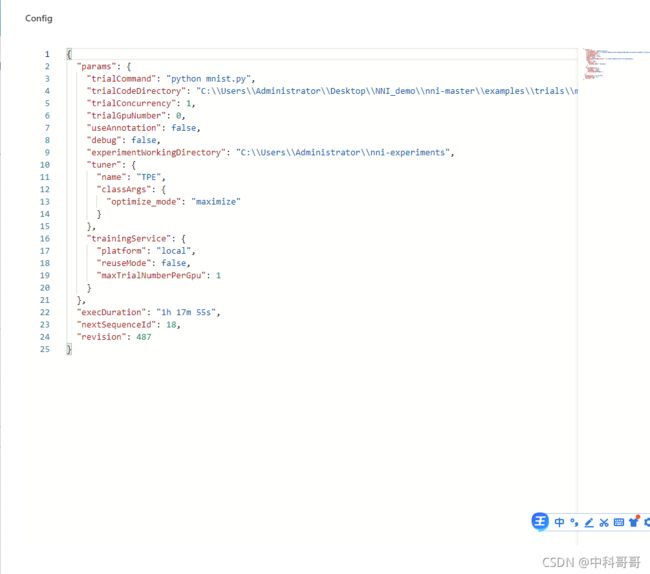
图中,左上脚,select space,Config,logfiles 点击,体现出设置的参数。如下图所示
Hyper-parameter 体现参数训练结果
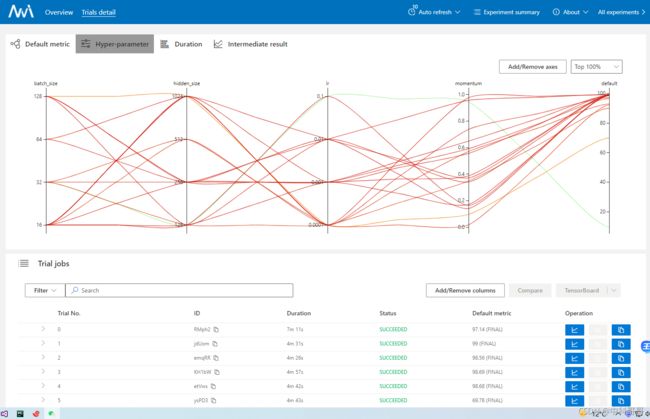
Trial jobs 体现每一次参数调整测试结果与测试图

第六步 停止
nnictl stop #停止自动调参
常见基本操作
参考网站:https://nni.readthedocs.io/en/latest/Tutorial/WebUI.html
The Web UI urls are: http://223.255.255.1:8080 http://127.0.0.1:8080
-----------------------------------------------------------------------
You can use these commands to get more information about the experiment
-----------------------------------------------------------------------
commands description
1. nnictl experiment show show the information of experiments
2. nnictl trial ls list all of trial jobs
3. nnictl top monitor the status of running experiments
4. nnictl log stderr show stderr log content
5. nnictl log stdout show stdout log content
6. nnictl stop stop an experiment
7. nnictl trial kill kill a trial job by id
8. nnictl --help get help information about nnictl
-----------------------------------------------------------------------
常见问题汇总
1.参数应该是个字典,比如args[‘batch_size’]而非args.batch_size
因为nni.get_next_parameter()获取到的是一个字典,并且对于params使用的是字典的update方法params.update(tuner_params),所以params应该是字典格式的,使用params[‘batch_size’]
- Fail了怎么办?
nni启动成功,打开网站也RUNNING了,但是没跑完一个epoch就FAILED了。这种情况,建议把以下三行代码
nni.get_next_parameter(), nni.report_final_result(), nni.report_intermediate_result()
都注释掉然后跑一下程序看看有没有bug!
没有bug的话,就看看report的值是不是数字。report的必须是数字,不是tensor等其他变量。另外还需要看看GPU可不可用,如果GPU内存不够,就会报错。
3.一直Waiting
nni启动了,但是一直WATING,可能是你的config.yaml配置错了,参照第二步,检查gpuNum和trialConcurrency的值,实在不行就都填写1。另外,nvidia-smi看看你的GPU使用情况,如果
第六步的停止只是stop,没有kill进程,你的GPU可能还在跑之前的trail。
- train detail没有result
程序一直在跑,早该跑完一个epoch了但是网页中没有数值显示?检查report函数,report的必须是数字,不是tensor等其他变量
5.网页打不开
如果用的是Linux远程GPU服务器,本地打不开网页,怎么办?
可以重定向。在本地命令行输入
ssh -p
remote_port是服务器端口号,
127.0.0.1代表localhost,
前面的8088是第四步-p后面写的端口号, 后面的8088是你要重定向到本机的端口号,可以随意填写
username是服务器的用户名,remote_ip是服务器的ip地址 然后在自己电脑上打开浏览器,输入127.0.0.1:8888即可。
6.报错NoneType
请注意,使用nni,必须使用nnictl create --config config.yml启动程序,不能直接Run
7.学会利用日志log
虽然在终端上不能直接看到训练日志,但是实际上在我们设置的实验路径下,有一个log文件,里面记录了所有的stdout内容,可以方便我们调试程序。
最后本文测试的源代码基于pytorch1.7.1 附上源码参考本博客源码链接如下:
https://download.csdn.net/download/weixin_38353277/39662928
Finished!
部分bug测试参考链接:https://blog.csdn.net/weixin_43653494/article/details/101039198#t8