一步步看α-β剪枝算法
最近在看人工智能的部分内容,这个α-β剪枝算法可是让我服了,看了PPT又看了网上好多blog,感觉一个也没讲清楚是怎么回事,什么上界下界上界小于下界的…现在终于搞明白是怎么一回事了。这篇blog实际上不应该出现在机器学习专栏里面的,因为不涉及任何数学的知识,主要是想从头到尾梳理一下这个的内容,最后的实现应该会放到编程笔记专栏里。
封面:电影《龙猫》
算法思想
首先要说的是,alpha-beta剪枝建立在两个假设上:
- 整个博弈过程属于零和博弈,即一方的收益必然意味着另一方的损失,博弈双方的收益和损失相加总和永远是零,双方不存在任何合作的可能。粗俗理解就是你赚了我就亏了。
- 博弈双方足够聪明,即每一方在决策时总会选择使自己利益最大化的决策。粗俗理解就是,假设是在下棋,那么大家下棋时大家走的都是固定的且是对自己最好的,下多少局也是这样。
在满足这样的假设的情况下,整个α-β剪枝的核心思想就是,当你知道你有一个选择A时,此时你知道了B选择不如A选择好,那么你就不需要知道B选择有多坏。
这句话可能有些抽象,看下面我在别的地方偷来的图:

假设我们在玩游戏,我有两个钱包,我们可以依次从钱包里拿一张钱给你去买饮料,我先拿你再拿。钱包A里面装着5毛钱和X块钱,钱包B里面装着2块钱和10块钱,我和你知道的只有这些。问你这时候去哪个钱包拿钱?
当然是从B钱包拿钱了!因为此时你知道我为了让你不拿走我太多的钱,我肯定会先从A钱包拿一张最小的钱(可能是0.5,也可能是X)给你,或者先从B钱包里拿2块钱(最优选择)给你。那么从B钱包里你至少能拿到2块钱,而A钱包里现在最多就能拿出来5毛钱了,因为如果X大于0.5(例如图中的100块)我是不会给你的。因此你不需要再考虑B钱包里放的X块钱到底是多少钱了,和你没关系,最多你只能拿到0.5。
所以这时我们就可以不考虑这个B钱包了,因为无论X是多少钱,选择B都会亏,因为敌人太聪明,永远给你的都是五毛钱。这样我们就可以减少一些考虑的情况,我们称之为剪枝。
算法流程
整个算法流程的前提是固定深度的搜索,也就是我们平时说的下棋看多少步,同时我们还要有能力推演到达多少步后对我们的有利程度。
假设我们继续玩这个游戏,不过现在我们有了很多钱包和很多面值的钱。正方形代表我们做的决策,圆形代表对手的决策。
首先我们推演走两步之后,对手可以给我们选的是5块钱和6块钱,但是我们知道敌人足够聪明,因此他会给我们选5块,此时我们最少是获得五块
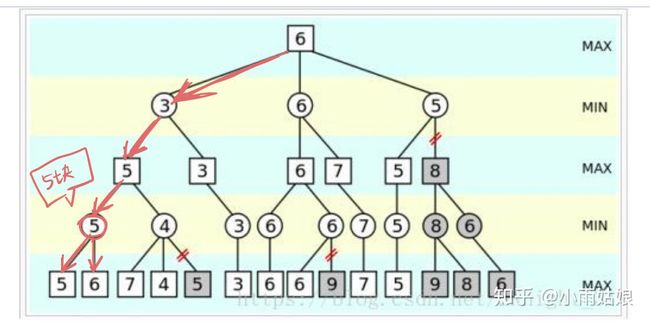
然后我们开始看看第二步选择别的会是什么结果,我们遍历完7块觉得不错,然后遍历到4块的时候,就发现不对了。既然有4块,那么对手给我们的肯定是4块或者后面还没遍历到的那些,如果那些大于4块,对手肯定会给我个4块的,如果小于4块,那给了我岂不是更亏了。因此我不能选这个分支,我只能选上一步那个分支,那后面是多少钱实际上和我都没关系了。
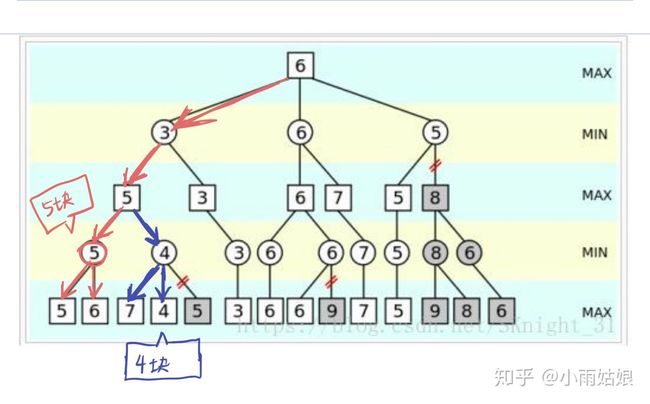
遍历完这些,我们已经保底知道目前我们最多能拿个5块钱了。同理,在另一条分支我们也可以知道最多可以拿个3块钱。而站在对手的角度,我们也知道,他肯定会选让我们仅仅能拿到3块钱的方案。

我们总结出第一条能够剪枝的方案,对手发现可以给我们一个比我们当前可获得最大收益值更小的值时,触发剪枝。另一种情况在图上没有画出,即当我们发现可以获得一个比对手可让我们获得最小收益值更大的值时,触发剪枝(例如下图,蓝字第一行是最少写错了)。

对手发现可以给我们一个比我们当前可获得最大收益值更小的值时,触发剪枝。
我们发现可以获得一个比我们当前获得最小收益值更大的值时,触发剪枝。
通过仔细研究这两句话和上图,我们发现,对手遍历的结点和我们可获得最大收益的结点都是同一类结点,即方块结点,同理我们遍历的结点和我们可获得最小收益的结点都是圆圈结点。因此我们需要在对手遍历结点时考虑我们的最大收益,在我们遍历结点时考虑我们的最小收益,因此我们才需要了上界和下界两个变量。
下面翻译一下定义:
对于一个结点MIN(敌人结点),若能估计出其倒推值的上界(遍历的值),若这个上界不大于(小于)MIN的父节点(最大收益),及时停止那些已无必要再扩展的结点……
伪代码几行的事情:
function minimax(node, depth, a, b)
if node is a terminal node or depth = 0
return the heuristic value of node
if #opposite
foreach child of node
b := min(a, minimax(child, depth-1, a, b))
if b <= a
return b
return b
else we
foreach child of node
a := max(b, minimax(child, depth-1, a, b))
if b <= a
return a
return a实际上,如果记住这个结论会很方便,而且也避免了把自己绕进去的问题发生,好像即使知道了也没有太多的意义,更多的是让自己更舒服一点。
这个问题感觉像是个逻辑上的问题,大概的逻辑就是,我知道你会选那个让我最差的A,那么如果有让我更差B的出现,我会选那个你会选的让我更差A的那个的上一步,让你只能选A,然后无限递归下去。从小到大没接受过逻辑训练,真的把自己绕进去了。
但是我想可能会有几个问题:
第一个是,对方一定会选择使自己最差的思路这个先验知识,在真实情况下本身就不正确的,因为无法确定对方的博弈策略是否和自己一致。如果对方做的策略不是最优,那么我的策略是最优的假设也不复存在。
第二个是,这个和位置的相关性很大,实际上可能和深度优先搜索的复杂度差不了多少。
第三个是,很难确定你评估的上界和下界是否是真实的,如果回溯的深度不够,感觉很容易陷入局部最优。所以我还是更相信概率模型(类似马尔可夫决策以及强化学习,虽然我对他们的了解不多)