史上最全的TCP/IP协议原理
TCP/IP协议原理
一、TCP/IP协议简介及起源
起初,计算机只是以单机模式(独立模式)被广泛应用,随着发展,计算机被一个个的连接起来,形成了一个计算机网路,从而实现了信息共享,远距离传递信息等工作,计算机网络,根据规模可分为2种:
WAN:Wide Area Network(广域网)
LAN:Local Area Nerwork(局域网)
异构型计算机连接和电子邮件、万维网等信息传播方式促使互联网开始从大到整个公司小到一个家庭内部开始普及互联网,实现了世界各地用户通过接入互联网而即时沟通与交流。
计算机通信诞生之初,系统化与标准化未收到重视,不同厂商只出产各自的网络来实现通信,这样就造成了对用户使用计算机网络造成了很大障碍,缺乏灵活性和可扩展性。为解决该问题,ISO(国际标准化组织)制定了一个国际标准OSI(开放式通信系统互联参考模型)。TCP/IP并非ISO指定,是由IETF(国际互联网工程任务组)建议、致力推进标准化的一种协议,其中,大学等研究机构和计算机行业是推动标准化的核心力量,现已成为业界标准协议。
这种标准协议就是计算机之间通过网络实现通信时事先达成的一种“约定”;这种“约定”使那些由不同厂商的设备,不同CPU及不同操作系统组成的计算机之间,只要遵循相同的协议就可以实现通信。协议可以分很多种,每一种协议都明确界定了它的行为规范:2台计算机之间必须能够支持相同的协议,并且遵循相同的协议进行处理,才能实现相互通信。
互联网中常用的代表性的协议有IP、TCP、HTTP等,LAN中常用协议有IPX、SPX等。“计算机网络体系结构”将这些网络协议进行了系统的归纳,TCP/IP就是这些协议的集合。
1、TCP/IP的定义
TCP/IP是Transmission Control Protocol / Internet Protocol(传输控制协议/互联网络协议)的缩写。TCP和IP只是其中的2个协议,也是很重要的2个协议,所以用TCP/IP来命名这个互联网协议族,实际上,它还包括其他协议,比如UDP、ICMP、IGMP、ARP/RARP等。传输控制协议:用于处理任何长度消息的可靠传输,互联网络协议除了具有其他能力之外,用于管理从发送方到接收方的网络传输路由。
总之:TCP/IP协议族是一组协议的集合,也叫互联网协议族,用来实现互联网上主机之间的相互通信。
2、TCP/IP的起源和历史
TCP/IP的历史可以追溯到1969年,美国国防部下属的一家秘密机构,称之为ARPA(Advanced Research Projects Agency,高级研究计划部署),资助了一项特殊类型长距离网络的学术研究,称之为分组交换网络,建立了著名的ARPANET。ARPANET是最早出现的计算机网络之一,现代计算机网络的许多概念和方法来自ARPANET。了实现异种网之间的互联(Interconnection)与互通(Intercommunication),ARPA不断鼓励在ARPANET上进行分组交换技术的研究开发。于1977到1979年间推出目前形式的TCP/IP体系结构和协议规范。
1983年,国防部通信局,现称为国防部信息统计局从ARPA手中接管了ARPANET的运营。随后美国国防部要求Internet上所有的计算机都从先前扎乱的协议切换到TCP/IP上。也正是同年,UNIX(4.2BSD版)在操作系统中植入了对TCP/IP的支持。
1986年,国家科学基金会建立了一个长距离、高速网络,称之为NSFNET(一条运行速度为56kb/s的网络主干路,比今天的调制解调器的速度略微快一点),NSF也定制了一组策略,称之为合理使用策略AUP(Acceptable Use Policies),它说明了如何使用Internet。
1989年,Internet上的主机数量突破了100000台,NSFNET主干网升级到了T1速度,为每秒1.544M位(Mb/s)。
1990年,麦吉尔大学发布了基于TCP/IP的Arichie协议和服务,它支持Internet上的用户搜索任意位置、任意类型的基于文本的文档归档,特别是FTP站点上的内容。
1991年,商业互联网交互成立。
1992年,国际互联网协会(ISOC)成立。Internet上的主机数量突破了一百万。NSFNET主干网升级到了T3速度,为44.736Mb/s。CERN公开发布HTTP和Web服务器技术(Web诞生)。
1995年,Netscape创建了Netscape Navigator,并启动了Web的商业化。
1996年,微软开发了IE浏览器。
2000年-2001年,情书(Love Letter)蠕虫感染了百万台感染计算机、Sircam病毒和红色代码(Code Red)感染了数千台Web服务器和数千个电子邮件账户。
直到今天,新的服务新的协议不断的浮现在Internet上,但TCP/IP依然蓬勃强劲。
3、OSI网络参考模型
国际标准化组织开发系统互联网络参考模型,有时候也称ISO/OSI网络参考模型,也叫七层模型。其目标是建立一个全新的、经过改进的、专门设计的协议套件来取代TCP/IP。但是并未被广泛采用,却成了讨论组网、解释网络如何运行的标准方法。

3.1、物理层
3.2、数据链路层
3.3、网络层
一般地,数据链路层是解决同一网络内节点之间的通信,而网络层主要解决不同子网间的通信。
发送者如何知道接收者的MAC地址?又如何知道接受者是否和自己属于同一子网?不再同一子网的又如何发送?为了解决这些问题,网络层引入了三个协议,分别是IP协议、ARP协议、路由协议。
3.3.1、 IP协议
数据链路层中使用的物理地址(如MAC地址)仅解决网络内部的寻址问题。在不同子网之间通信时,为了识别和找到网络中的设备,每一子网中的设备都会被分配一个唯一的地址。由于各子网使用的物理技术可能不同,因此这个地址应当是逻辑地址(如IP地址)。因此,网络层引入了IP协议,制定了一套新地址,使得我们能够区分两台主机是否同属一个网络,这套地址就是网络地址,也就是所谓的IP地址。
IP地址目前有两个版本,分别是IPv4和IPv6,IPv4是一个32位的地址,常采用4个十进制数字表示。IP协议将这个32位的地址分为两部分,前面部分代表网络地址,后面部分表示该主机在局域网中的地址。
3.3.2、ARP协议
地址解析协议,是根据IP地址获取MAC地址的一个网络层协议。
ARP首先会发起一个请求数据包,数据包的首部包含了目标主机的IP地址,然后这个数据包会在链路层进行再次包装,生成以太网数据包,最终由以太网广播给子网内的所有主机,每一台主机都会接收到这个数据包,并取出标头里的IP地址,然后和自己的IP地址进行比较,如果相同就返回自己的MAC地址,如果不同就丢弃该数据包。
3.3.3、路由协议
ARP的MAC寻址还是局限在同一个子网中,因此网络层引入了路由协议,首先通过IP协议来判断两台主机是否在同一个子网中,如果在同一个子网,就通过ARP协议查询对应的MAC地址,然后以广播的形式向该子网内的主机发送数据包;如果不在同一个子网,以太网会将该数据包转发给本子网的网关进行路由。网关是互联网上子网与子网之间的桥梁,所以网关会进行多次转发,最终将该数据包转发到目标IP所在的子网中,然后再通过ARP获取目标机MAC,最终也是通过广播形式将数据包发送给接收方。
网络层的主要工作是:定义网络地址,区分网段,子网内MAC寻址,对于不同子网的数据包进行路由。
3.4、传输层
链路层定义了主机的身份,即MAC地址, 而网络层定义了IP地址,明确了主机所在的网段,有了这两个地址,数据包就从可以从一个主机发送到另一台主机。而每台电脑都有可能同时运行着很多个应用程序,所以当数据包被发送到主机上以后,是无法确定哪个应用程序要接收这个包。
因此传输层引入了UDP协议来解决这个问题,为了给每个应用程序标识身份,UDP协议定义了端口,同一个主机上的每个应用程序都需要指定唯一的端口号,并且规定网络中传输的数据包必须加上端口信息。 这样,当数据包到达主机以后,就可以根据端口号找到对应的应用程序了。
UDP协议比较简单,实现容易,但它没有确认机制, 数据包一旦发出,无法知道对方是否收到,因此可靠性较差,为了解决这个问题,提高网络可靠性,TCP协议就诞生了,TCP即传输控制协议,是一种面向连接的、可靠的、基于字节流的通信协议。简单来说TCP就是有确认机制的UDP协议,每发出一个数据包都要求确认,如果有一个数据包丢失,就收不到确认,发送方就必须重发这个数据包。
为了保证传输的可靠性,TCP 协议在 UDP 基础之上建立了三次对话的确认机制,也就是说,在正式收发数据前,必须和对方建立可靠的连接。
传输层的主要工作是:传输层建立了主机端到端的链接,端口号既是这里的“端”(标识应用程序身份),TCP协议可以保证数据传输的可靠性。
3.5、会话层
会话层就是负责建立、管理和终止表示层实体之间的通信会话。该层的通信由不同设备中的应用程序之间的服务请求和响应组成。
主要任务是:向两个实体的表示层提供建立和使用连接的方法。将不同实体之间的表示层的连接称为会话。因此会话层的任务就是组织和协调两个会话进程之间的通信,并对数据交换进行管理。
3.6、表示层
表示层提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别。如果必要,该层可提供一种标准表示形式,用于将计算机内部的多种数据格式转换成通信中采用的标准表示形式。数据压缩和加密也是表示层可提供的转换功能之一。
3.7、应用层
有了上诉基层协议,数据已经可以从一个主机上的应用程序传输到另一台主机的应用程序了,但此时传过来的数据是字节流,不能很好的被程序识别,操作性差。因此,应用层定义了各种各样的协议来规范数据格式,常见的有 HTTP,HTTPS,FTP,POP3、SMTP等。
4、TCP/IP网络模型
TCP/IP四层模型如下:

| OSI七层模型 | TCP/IP四层模型 | 对应网络协议 |
| 应用层(Appliation) | 应用层 | HTTP、TFTP、FTP、NFS、WAIS、SMTP、POP3 |
| 表示层(Presentation) | Telnet、Rlogin、SNMP、Gopher | |
| 会话层(Session) | SMTP、DNS | |
| 传输层(Transport) | 传输层 | TCP、UDP |
| 网络层(Network) | 网络层 | IP、ICMP、ARP、RARP、AKP、UUCP、BOOTP(DHCP)、RIP、BGP |
| 数据链路层(Data Link) | 网络接口层(网络访问层) | PPP(PPPoE) 、SLIP、Ethernet、FDDI、Arpanet、PDN |
| 物理层(Physical) | IEEE 802.1-互联网络 802.2-逻辑链路/媒体访问控制 802.3- 多路访问 802.5-令牌环 802.11-Wi-Fi |
4.1、网络接口层
用于协作IP数据在已有网络介质上传输的协议。实际上TCP/IP标准并不定义与ISO数据链路层和物理层相对应的功能。它提供TCP/IP协议的数据结构和实际物理硬件之间的接口。
IEEE 802规范定义了网卡如何访问传输介质(如光缆、双绞线、无线等),以及如何在传输介质上传输数据的方法,还定义了传输信息的网络设备之间连接建立、维护和拆除的途径。遵循IEEE 802标准的产品包括网卡、桥接器、路由器以及其他一些用来建立局域网络的组件。
1)802.1-互联网络:给出了整个802系列中互联网络如何工作的描述;
2)802.2-逻辑链路/媒体访问控制:设备之间建立和管理逻辑链路的描述和媒体接口访问的描述;
3)802.11-Wi-Fi:无线数据包无限组网标准。
4)PPP协议:常见的变体为PPPoE,以太网上的PPP,是一种串行线路协议。
4.2、网络层
本层包含IP协议、RIP协议(Routing Information Protocol,路由信息协议),负责数据的分片、寻址和路由。同时还包含网间控制报文协议(Internet Control Message Protocol,ICMP)用来提供网络诊断信息。
在网络层,有以下重要协议:
1)IP(网际协议):将数据包从发送方路由传输到接收方。
2)ICMP(控制消息协议):处理基于IP路由和网络行为的消息。
3)ARP(地址解析协议):在特定的电缆网段上将数字IP网络地址转换为媒体访问控制(MAC)地址。
4)RARP(反向地址解析协议):将MAC地址转换成数字IP地址。
5)BOOTP(引导协议):是动态主机配置协议(DHCP)的前导协议,DHCP管理网络IP地址分配和其他IP配置数据,BOOTP支持网络设备从网络上获取引导和配置数据。
6)RIP(路由信息协议)、BGP(边界网关协议)
4.3、传输层
传输层有时候也称为主机到主机层,提供两种端到端的通信服务。
1)TCP协议(Transmission Control Protocol)提供可靠的数据流运输服务。
2)UDP协议(Use Datagram Protocol)提供不可靠的用户数据报服务。
4.4、应用层
应用层对应于OSI参考模型的应用层、表示层、会话层,为用户提供所需要的各种服务,例如:HTTP、TFTP、FTP、NFS、SMTP等。应用层是协议栈与主机上应用程序或进程接口的地方,因此,也被称为处理层。TCP/IP服务的运行依赖于下面两个要素:
1)守护程序(侦听进程):处理特定服务的入栈用户请求。
2)端口地址:用于识别特定的进程和服务。端口地址使用16位数表示(2的16次方,也就是说一个主机最多有65535个端口)。在范围0-1024之间的端口地址经常被称为公认端口地址。如:FTP的公认端口为21。
常见的协议:
1)HTTP超文本传输协议:这是一种最基本的客户机/服务器的访问协议;浏览器向服务器发送请求,而服务器回应相应的网页。
2)TFTP简单文件传送协议:客户服务器模式,使用UDP数据报,只支持文件传输,不支持交互,TFTP代码占内存小 。
3)FTP文件传送协议:提供交互式的访问,基于客户服务器模式,面向连接 使用TCP可靠的运输服务,减少/消除不同操作系统下文件的不兼容性 。
4)SMTP简单邮件传送协议:Client/Server模式,面向连接 ,基本功能:写信、传送、报告传送情况、显示信件、接收方处理信件。
二、IP简介
1、IP定义
21世纪关于网络,人们最长听见的用词之一便是:IP地址!
关于IP的定义:是Internet Protocol的缩写,指TCP/IP网络体系中的网际互联协议。IP协议规定了所有连接到互联网中的设备都必须拥有自己唯一的“身份号”—IP地址,网络设备间进行信息交互时,必须在数据报文中设定目标设备的IP地址方能将数据准确传输至目标设备,好比快递必须填写收件人地址,快递员方能根据收件人地址将快递顺利送至收件人处。互联网中的一台网络设备可以拥有多个IP地址,但一个IP地址只能对应一台网络设备,即IP地址具有唯一性。
2、 IP地址的构成
IP地址是一串数字,遵循国际编写规范,共由32位二进制数字0/1组成。当以十进制数字表达时,数字IP地址使用点分割十进制表示法,采用格式n.n.n.n,每8位为一组,用标准的IP术语来说称为八位元组(每个字段最大值是255)。如192.168.0.0,即地址格式为:IP地址=网络地址+主机地址 或IP地址=主机地址+子网地址+主机地址。地址总容量近43亿个(2^32=4294967296)。然而随着互联网的发展以及全世界庞大的人口数量,IPv4地址远远不够用。因此,诞生了IPv6,IPv6地址采用128位标识,数量为2的128次方,相当于IPv4地址空间的4次幂。本文介绍的IP为IPv4。
最初设计互联网络时,为了便于寻址以及层次化构造网络,每个IP地址包括两个标识码(ID),即网络ID和主机ID。同一个物理网络上的所有主机都使用同一个网络ID,网络上的一个主机(包括网络上工作站,服务器和路由器等)有一个主机ID与其对应。各种网络的差异很大,有的网络中有很多主机,而有的网络中主机数很少,只需做到在该单位管辖的范围内无重复的主机号即可。把IP地址划分为不同的类别是为了更好地满足不同用户的需求。IP地址根据网络ID的不同分为5种类型,A类地址、B类地址、C类地址、D类地址和E类地址。

2.1、IP地址分类简介
| 类别 | 最大网络数 | 最大主机数 | 地址范围 | 适用规模 | 私有地址 |
| A类 | 126(2^7-2) | 16777214(2^24-2) | 1.0.0.0~126.0.0.0 | 大型 | 10.0.0.0-10.255.255.255 |
| B类 | 16382(2^14-2) | 65534(2^16-2) | 128.0.0.0~191.255.0.0 | 中型 | 172.16.0.0~172.31.255.255 |
| C类 | 2097150(2^21-2) | 254(2^8-2) | 192.0.1.0~223.255.255.255 | 小型 | 192.168.0.0~192.168.255.255 |
1)A类地址
A类地址总是采用如下二进制格式:0bbbbbbb,hhhhhhhh,hhhhhhhh,hhhhhhhh
A类IP=第一个字节作为网络地址,后三个字节作为主机地址
网络地址的前导数字总是0,其他位置可以是0也可以是1,这样其网络地址最多的可能有:2^7=128种,其范围为(00000000~01111111,即0-127),其地址范围为:0.0.0.0到127.255.255.255,但是在任何IP网络上,网络号全是0和1的地址用保留用于专用目的,不能作为网络地址,其中0代表任何地址,127段为回环测试地址。所以A类地址的最大网络数为2^7-2=126.(1.0.0.0到126.0.0.0),而RFC1918中规定网络10.0.0.0是私有地址(所谓的私有地址就是在互联网上不使用,而被用在局域网络中的地址),主机号全0表示所在网络的网络号,全1表示广播地址,因此每个网络能容纳16777214个主机(224-2=16777216-2=16777214)。
2)B类地址
B类地址总是采用如下二进制格式:10bbbbbb,bbbbbbbb,hhhhhhhh,hhhhhhhh
B类IP=前两个字节作为网络地址,后两个字节作为主机地址
网络地址的前导数字总是10,其他位置可以是0也可以是1,前两个字节作为网络号,这样其网络地址最多的可能有:2^14=16382种,因此最大可用网络地址数量为2^14-2(总是要减去全是0和全是1的两个地址),而RFC1918中规定172.16.0.0~172.31.255.255的16个B类网络地址是私有地址。
3)C类地址
C类地址总是采用如下二进制格式:110bbbbb,bbbbbbbb,bbbbbbbb,hhhhhhhh
C类IP=前三个字节作为网络地址,最后一个字节作为主机地址
网络地址的前导数字总是110,其他位置可以是0也可以是1,前两个字节作为网络号,这样其网络地址最多的可能有:2^21=2097152种,因此最大可用网络地址数量为2^21-2(总是要减去全是0和全是1的两个地址),而RFC1918中规定192.168.0.0~192.168.255.255的256个C类网络地址是私有地址。
4)D类地址
D类地址主要用于多点广播(Multicast)的地址,并不指向特定的网络。D类IP地址第一个字节以1110开始,它是一个专门保留的地址。它并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中。多点广播地址用来一次寻址一组计算机(同时向同一子网所有主机发送报文),它标识共享同一协议的一组计算机。224.0.0.0~239.255.255.255用于多点广播。
5)E类地址
E类IP地址以11110开始,为将来使用保留。主要用于Internet试验和开发,地址范围为240.0.0.0~255.255.255.254,255.255.255.255用于广播地址。
3、子网与子网掩码
在了解子网掩码之前我们有必要先了解一下子网,为什么会出现子网,子网是什么?
子网就是将主机地址的几位用来做网络地址来将网络划分为若干个子网,便于管理还能减少IP的浪费。
子网的出现是基于以下原因:
- 节约IP资源:随着互联的发展IPV4地址资源可能会耗尽,如果不划分子网直接将一个C类地址分给一个企业,C类地址可容纳256台主机,但是可能该企业只有20台计算机,这就造成极大浪费
- 减少网络流量,优化网络性能:隔离数据在整个网络内广播,提高信息传输速率。如:C类广播到256台和广播到20台效率显而易见。
子网掩码:又叫网络掩码,它是一种用来指明一个IP地址的哪些位标识的是主机所在的子网,以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,必须配合IP使用。
用途:通过子网掩码计算出一台主机所在的子网和其他网络的关系,进行正确的通信(网络地址相同,表明接受方在本网络上,那么可以把数据包直接发送到目标主机,否则就需要路由网关将数据包转发送到目的地)。
组成:但是为了方便记忆和美观,IP地址通常是将每8位二进制数转化为十进制来表示,中间用'.'分隔,如255.255.255.0
A/B/C类地址的缺省子网掩码:
A类:255.0.0.0 B类:255.255.0.0 C类:255.255.255.0
3.1、子网掩码的计算
1)利用子网数来计算
步骤:a)将子网数目转化为二进制来表示;b) 取得该二进制的位数N;c)取得该IP地址的类子网掩码,将其主机地址部分的的前N位置为1,即得出该IP地址划分子网的子网掩码。
例如:将C类地址,192.168.10.0 划分成4个子网
a)4的二进制表示:4=100,该二进制的位数为N=3(这里的3为,表示为最接近子网数的二次幂,子网数+2=6,最接近的2^3=8)
IP:11000000 10101000 00001010 00000000(主机位)
子网掩码:11111111 11111111 11111111 11100000 (将主机位自顶向下保留(窃入)N位) ==》得到的子网掩码:255.255.255.224
192.168.10.0 划分成4个子网,大致可以这么分,我们可以在中间6个组中选四个:
000 00000 建议不使用,但也并不是不能使用
001 00000 网络号:192.168.10.32 主机范围起始地址:192.168.10.33 (32+1)主机范围结束地址:192.168.10.62 (64-2)
010 00000 网络号:192.168.10.64 主机范围起始地址:192.168.10.65 主机范围结束地址:192.168.10.94
011 00000 网络号:192.168.10.96 主机范围起始地址:192.168.10.97 主机范围结束地址:192.168.10.126
100 00000 网络号:192.168.10.128 主机范围起始地址:192.168.10.129 主机范围结束地址:192.168.10.158
101 00000 网络号:192.168.10.160
110 00000 网络号:192.168.10.192
111 00000 建议不使用,但也并不是不能使用
2)利用主机数来计算
步骤:a)将主机数目转化为二进制来表示;b)取得该主机的二进制位数,为N(如果主机数小于或等于254(注意去掉保留的两个IP地址),则这里肯定 N<8,如果大于254,则 N>8);c)使用255.255.255.255来将该类IP地址的主机地址位数全部置1,然后从后向前的将N位全部置为 0,即为子网掩码值。
例如:欲将B类IP地址168.195.0.0划分成若干子网,每个子网内有主机700台。(大于254)
a)700的二进制:700=1010111100,该二进制的位数为N=10
将该B类地址的子网掩码255.255.0.0的主机地址全部置为1,得到255.255.255.255,然后再从后向前将后10位置0,即为:11111111.11111111.11111100 00000000,即255.255.252.0为子网掩码值。
3)等分或不等分技巧
等分法:

等分成8份,2^3,至少要三位的二进制,即需要将子网掩码右移3位,可得出子网掩码为:255.255.255.224
不等分:将180台机器,按100、50、20、10分。子网掩码分别是多少?
按1/2分(100台),只需要右移1位,子网掩码:255.255.255.128(可用地址1-126)
按1/4分(50台),右移2位,子网掩码:255.255.255.192(可用地址129-190)
按1/8分(20台),右移3位,子网掩码:255.255.255.224(可用地址193-222)
按1/16分(10台):右移4位,子网掩码:255.255.255.240(可用地址225-238)
4)快速计算子网/主机数的方法
题目1:如果所需子网数为7,求子网掩码。
解答:与7最近的2^x是8(2^3),而此时只能有6个子网可以分配(一个用于网络一个用于广播,所以需要减去2,一般最小地址作为网络地址,最大地址作为广播地址),不能满足 7个子网的需求,所只能取16(2^4),256-16=240,所以子网掩码为 255.255.255.240
题目2:A类IP地址,子网掩码为255.224.0.0,它所能划分的最大有效子网数是多少?
解答:将子网掩码转换成二进制表示11111111.11100000.00000000.00000000,统计一下它的网络位共有11位,A类地址网络位的基础数是8,二者之间的位数差是3,最大有效子网数就是2的3次方,即最多可以划分8个子网络。
题目3:A类IP地址,子网掩码为255.252.0.0,将它划分成若干子网络,每个子网络中可用主机数有多少?
解答:将子网掩码转换成二进制表示11111111.11111100.00000000.00000000,统计一下它的主机位共有18位,最大可用主机数就是2的18次方减2(除去全是0的网络地址和全是1广播地址),即每个子网络最多有262142台主机可用。
4)计算网段。
ip地址:192.168.1.1 子网掩码:255.255.255.0 , ip地址:192.168.1.2 子网掩码:255.255.255.0
我们可以直接的判断,他们是同属于一个网段的ip地址。
那么对于下面这样的呢?
ip地址:192.168.1.1 子网掩码:255.255.255.0 ,ip地址:192.168.1.2 子网掩码:255.255.0.0
这两个ip地址虽然在不看掩码的情况下,比较像,但他们并不是同一个网段内的。这个可以从子网掩码来判断:将IP地址和子网掩码做与位运算:
192.168.1.1的二进制: 11000000 10101000 00000001 00000001
255.255.255.0的二进制: 11111111 11111111 11111111 00000000
与位得出结果(192.168.1.0):11000000 10101000 00000001 00000000
192.168.1.1 255.255.255.0是属于192.168.1.0网段的。
而192.168.1.2 255.255.0.0是属于192.168.0.0网段。
3.2、CIDR斜线表示法
也许我们常常会见到这种写法:192.168.10.32/28,其中用28位表示网络ID。
CIDR( Classless Inter-Domain Routing ,无类域间路由选择),它是ISP( Intemet Service Provider ,因特网服务提供商)用来将大量地址分配给客户的一种方法。ISP 以特定大小的块提供地址。从ISP那里获得的地址块类似于192.168.10.32/28,这指出了子网掩码。这种斜杠表示法(/)指出了子网掩码中有多少位为1 ,显然最大为/32 ,因为一个字节为8 位,而IP 地址长4B (4 x 8=32)。注意,最大的子网掩码为/32 (不管是哪类地址)。
例如:
255.0.0.0 /8
255.255.0.0 /16
255.255.255.0 /24
255.255.255.192 /26
255.255.255.224 /27
255.255.255.240 /28
255.255.255.248 /29
255.255.255.252 /30
255.255.255.254 /31
255.255.255.255 /32
超网是与子网类似的概念,IP地址根据子网掩码被分为独立的网络地址和主机地址。但是,与子网把大网络分成若干小网络相反,它是把一些小网络组合成一个大网络,即超网。
假设现在有2个C类网络,从192.168.0.0到192.168.1.0,它们可以用子网掩码255.255.254.0统一表示为网络192.168.0.0。但是,并不是任意的地址组都可以这样做,例如2个C类网络192.168.1.0到192.168.2.0就不能形成一个统一的网络。
192.168.00000000 00000000
192.168.00000001 00000000
255.255.11111110 00000000
合并成超网是往左移,与运算得出的网络号相同。
扩展:网关
按照不同的分类标准,网关也有很多种。TCP/IP协议里的网关是最常用的,在这里我们所讲的“网关”均指TCP/IP协议下的网关。
在配置网络的时候经常看到这几个参数,那么网关是什么呢? :
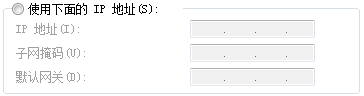
IP地址是以网络号和主机号来表示网络上的主机的,只有在一个网络号下的计算机之间才能“直接”互通(同一网段的子网内的主机之间通信是不需要经过网关的,发送的是广播报文),子网掩码的作用就是用来判断任意两个IP地址是否属于同一子网络,这时只有在同一子网的计算机才能"直接"互通。不同网络号的计算机要通过网关(Gateway)才能互通,简单来说,网关它就是为了管理不同网段的IP,网关实质上是一个网络通向其他网络的IP地址。网关既可以用于广域网互连,也可以用于局域网互连。
1984年12月,思科系统公司(Cisco Systems, Inc.)在美国成立,创始人是斯坦福大学的一对教师夫妇:计算机系的计算机中心主任莱昂纳德·波萨克(Leonard Bosack)和商学院的计算机中心主任桑蒂·勒纳(Sandy Lerner),夫妇二人设计了叫做“多协议路由器”的联网设备,用于斯坦福校园网络(SUNet),将校园内不兼容的计算机局域网整合在一起,形成一个统一的网络。思科因为路由器发展成全球最大的公司之一。故事看到这里,网关的作用就已经清晰了,就是帮助两个不能直接互通的网络,进行数据转发的。
网关是逻辑概念,路由器是物理设备,路由器(路由器在LAN的IP地址)可以作为网关来使用。路由器是一个设备,而网关是一个结点(概念层)。应该说:路由器可以实现网关的功能,把家庭局域网和互联网相连。另外,网关的功能还可以由局域网中一台双网卡的机器(其中一块网卡接入广域网)来实现。手机可以做网关,手机开了热点,笔记本接进来,手机作为网关把笔记本和互联网相连。
我们平时的家用路由器实际上是路由器+交换机(一个WAN口+若干个LAN口)一个wan口用来连接外网,其他的几个LAN口实质上就是一个交换机。WAN是英文Wide Area Network的首字母所写,即代表广域网;而LAN则是Local Area Network的所写,即本地(或叫局域网)。宽带路由器的路由功能就体现在wan口IP地址和lan口IP地址之间的数据路由上,通常我们根据网络运营商所提供的接入方式来设置WAN口的网络参数,通常有静态IP地址、动态IP地址或PPPOE等方式,它与网络运营商的接入设备处于同一个外网。而将LAN口的IP地址则设置为本地局域网内的IP地址,通常是我们自己可以在宽带路由器上自行设定的IP地址,LAN口下所连接的计算机组成一个“本地网”,路由器的LAN口IP地址是这个网络的网关。家庭内部网络的机器都是接lan口,通过lan口向外部网络发送数据包,首先发送一个请求到默认网关,路由器在分析下面发送来的数据包后,检查数据包中的内网IP地址时会检查设备本身的NAT地址转换表。在找到相应条目后,把源地址也就是本来的内网IP地址换成wan口的IP地址,目的地址不变,发送到外网上去。外部网络接受到数据包后,会解析出数据包中的路由器wan口IP地址,将响应数据包返回到这个wan口IP地址,发送回路由器。路由器将这个返回数据包中目的地址(wan口IP)NAT转换为内网IP,最终共完成整个数据包的发送和接受。
计算机之间是如何互相通信的
linux路由表主要字段说明

| Destination | Gateway | Genmask | Flags | Metric | Ref | Use | Iface |
| 目的地,终点,就是我们要去访问的目的IP,可以是主机地址、网络地址,常用的是网络地址 | 网关地址,所有未知地址都会找网关,有网关统一转发,只有边缘网络才会配置网关,并且直连网络不需要配置网关 | 目的地址的子网掩码 | U——该路由可以使用,G——该路由是到一个网关,如果没有该标志,说明目的地是直连的,H——该路由是到一个主机,D——该路由是由重定向报文创建的,M——该路由已被重定向报文修改,标志G很重要,它区分了间接路由和直接路由 | 优先级(数字越大优先级越低) | 路由项引用次数(linux 内核中没有使用) | 此路由项被路由软件查找的次数 | 接口,去往目的地址的网络路径的出口 |
第一行:
意思就是去往所有目标地址(#0.0.0.0代表的是匹配所有目标地址)数据包由网关192.168.170.2 通过网卡ens33来转发; Flags那一列中如果标志是 U,则说明是可达路由(活动的);如果是有 G,则说明这个网络接口连接的是网关,H则说明目标是一个主机。
第三行:
意思是主机所在网络的地址为192.168.170.0,若数据传送目标是在本局域网内通信,则可直接通过eth0转发数据包;
案例:
| PC | 网关 | 子网掩码 | 网段 |
| 小明(10.1.1.2/24) | 10.1.1.1/24 | 255.255.255.0 | 10.1.1.0 |
| 小美(10.1.1.3/24) | 10.1.1.1/24 | 255.255.255.0 | 10.1.1.0 |
| 小丽(10.1.2.2/24) | 10.1.2.1/24 | 255.255.255.0 | 10.1.2.0 |
从上表我们大概可以看到,小明和小美是处在同一个局域网内的,而小丽和他们都不在一个局域网内,那么肯定就会有两种情况发生,一种是统一局域网之间的通信,还有一种情况就是不同局域网之间的通信。
相同网段的通信:
小明和小美之间通信,其实就相当于小明主机ping10.1.1.3。下面我们来分析一下ping的这个流程。
1)小明利用自身的子网掩码和小美的ip地址进行&运算,得到小美的网段号。然后小明发现自己和小美处在同一个网络中。
2)检查自身的arp缓存
当IP层的ARP高速缓存表中存在目的IP对应的MAC地址时:直接封装这个ping包并发送给小美
当IP层的ARP高速缓存表中不存在目的IP对应的MAC地址时:小明按照路由表中的默认接口ETH0发送广播给整个局域网,局域网内的每台主机都收到了这个信息,其他主机都无反应,但是小美这台主机10.1.1.3意识到这是在叫自己。然后采取点对点单播回复小明:我在这里,我的mac地址是xxxx.以后你可以用这个联系方式联系我。小明收到此回复后,保存到自己的通讯录中(arp缓存中),方便下次联系。然后通过刚才记录的小红的mac地址发送ping包,依照类似的步骤,很快小红发出了回信。小明主机收到ping包的返回内容。
不同网段的通信:
小明和小丽之间的通讯
1)小明将自己的子网掩码和小丽的ip进行&运算,发现二人不在同一个网络内。小明无法直接通讯。
2)既然无法直接通信,小明就想有没有别的道路能够到达小丽。于是他查看了自己的路由表,信息如下:

路由表内并没有小丽的Ip信息。走投无路的小明决定走0.0.0.0这条路,0.0.0.0是默认路由,它的终点站是默认网关。
3)小明将网关的ip进行了第一步的操作,发现他们是在同一个网络中,于是利用arp协议小明得到了默认网关的mac地址,发送ping包给网关,网关接收以太网帧。
4)网关路由转发
网关ip层查看这个ping包,去路由表里尝试能否匹配到小丽的ip,下面是默认网关的路由表信息

刚好路由表里的第二条匹配到了小丽的网段号,到达下一条的方式是广播,所以网关开始发送ARP广播,并得到了小丽的mac地址,于是网关将这个ping包发送给了小丽
5)小丽收到这个ping包后,不修改任何内容,重复上面的步骤,将这个ping包发送给了小明。
三、物理层简介
物理层解决如何在连接各种计算机的传输媒体上传输数据比特流,而不是具体的传输媒体。物理层主要任务描述为:确定传输媒体的接口和一些特性,即:
机械特性:例接口形状、大小、引用数目。(如:以太网水晶网线8根)
电器特性:例规定电压范围(-5V到+5V)。
功能特性:例规定-5V表示0,+5v表示1。
过程特性:也称规程特性,规定建立连接时各个相关部件的工作步骤。
1、物理层常见的概念名词解释
1.1、信道
一般是表示向一个方向传送信息的媒体。信道可以分为:
单向通信(单工通信):只能有一个方向的通信而没反向的交互。
双向交替通信(半双工通信):通信的双方都可以发送信息,但是双方不能同时发送。
双向同时通信(全双工通信):通信的双方可以同时发送和接收信息。
1.2、基带信号和带通信号
基带信号:即基本频带信号,来自信源的信号。像计算机输出的各种文字或图像文件的数据信号都属于基带信号,基带信号就是发出直接表达了要传输的信息的信号,比如我们说话的声波就是基带信号。
带通信号:把基带信号记过载波调制后,把信号的频率范围搬移到较高频段以便在信道中传输(仅在一段频率范围内能够通过信道)
因此在传输距离较近时,计算机网络都采用基带传输方式,由于在近距离范围内基带信号的衰减不大,从而信号内容不会发生变化。如:计算机到监视器、打印机等外设的信号都是基带传输的。
后续还出现了曼彻斯特编码信号和差分曼彻斯特编码信号。
1.3、奈式准则和香农公式
奈式准则:1924年,奈奎斯特,提出了著名的奈式准则。在任何信道中,码元传输的速率是有上限的,否则就会出现码间串状的问题,使接收端对码元的判决(即识别)成为不可能。如果信道的频带越宽,也就是能够通过的信号高频分量越多。
香农公式:香农用信息理论推导出了带宽受限且有高斯白噪声干扰的信道极限、无差错的信息传输速率。信道的极限传输速率C可表 达为:![]() b/s
b/s
W为信道的带宽(以Hz为单位),S为信道内所传信号的平均功率,N为信道内的高斯噪声功率
2、物理层下的传输媒体
2.1、导向传输媒体
双绞线:屏蔽双绞线STP、无屏蔽双绞线UTP

同轴电缆:50Ω同轴电缆用于数字传输,由于多用于基带传输。也叫基带同轴电缆;75Ω同轴电缆用于模拟传输,即带宽同轴电缆。不过现在比较少用。

网线:
1)直通线:具体的线序制作方法是:双绞线夹线顺序两边一致,统一都是八根。
从左起线的排序:
EIA/TIA 568A标准:白绿、绿、白橙、蓝、白蓝、橙、白棕、棕。
EIA/TIA 568B标准:白橙、橙、白绿、蓝、白蓝、绿、白棕、棕。
100M的其实只用1、2、3、6这几根,1000M的才会8根都用。直通线应用最广泛,主要是主机到交换机或集线器、路由器到交换机或集线器用直通线。
光纤:光纤(Fiber Optic Cable)以光脉冲的形式来传输信号,因此材质也以玻璃或有机玻璃为主。它由纤维芯、包层和保护套组成。光纤的结构和同轴电缆很类似,也是中心为一根由玻璃或透明塑料制成的光导纤维,周围包裹着保护材料,根据需要还可以多根光纤并合在一根光缆里面。根据光信号发生方式的不同,光纤可分为单模光纤和多模光纤。
2.2、非导向传输媒体
非导向传输媒体就是自由空间,其中的地磁波传输被称为无线传输。无线传输所使用的频段很广,短波通信主要是靠电离层的反射,但是短波信道的通信质量较差,微波在空间主要是直线传播。

2.3、物理层设备
集线器: 他在网络中只起到信号放大和重发作用,其目的就是扩大网络的传输范围,而不具备信号的定向传送能力。所有端口同属一个冲突域,主要用来延伸网络访问距离,扩展终端数量。
现在多用交换机,而不用集线器。交换机工作于数据链路层,它的每个端口相当于一个集线器,原理是根据数据帧头的MAC地址转发帧到合适的端口,每个端口是一个独立的冲突域。
总之,交换机的网络性能要远远优于集线器。随着技术的进步,交换机的成本已经降低,集线器逐步退出了市场。
四、数据链路层
1、数据链路层简介
数据链路层是物理层的上层,物理层是把电脑连接起来的物理手段,它主要规定了网络的一些电气属性,其作用是负责传送0和1的电信号。数据链路层位于物理层的上层,简单的阐述它的作用就是确定0和1的分组方式。数据链路层在不可靠的物理介质上提供可靠的传输。
数据链路层使用的信道主要有以下两种类型:1)点到点信道:这种信道使用一对一的点对点通信方式;2)广播信道:这种信道使用一对多的广播通信方式,因此过程比较复杂。广播信道上连接的主机很多,因此必须使用专用的共享信道协议来协调这些主机数据发送。
链路:其实就是指从一个结点到相邻结点的一段物理线路(有线或无线),中间没有任何其他的交换结点。可知,一条链路只是一条通路的一个组成部分。
数据链路:除了物理线路外,还必须有通信协议来控制这些数据的传输。若把实现这些协议的硬件和软件加到链路上,就构成了数据链路。
在数据链路层的协议数据单元PDU是帧,数据链路层传送的是帧。现在再来说一下数据链路层的作用:数据链路层把网络层交下来的数据(网络层的PDU是IP数据报或叫分组,包)构成帧发送到链路上,以及把接受到的帧中的数据取出来并上交给网络层。

2、帧及传输的三个问题
在数据链路层中应该有一些协议来控制帧的传输,数据链路层的协议有许多种,但都需要解决三个基本的问题:封装成帧、透明传输、差错控制。
2.1、封装成帧
封装成帧 (framing) 就是在一段数据的前后分别添加首部和尾部,然后就构成了一个帧。为什么要封装成帧?这一点我们从分组交换的概念中应该能够知道一些,因为在互联网上传送的数据都以分组(IP数据报)为传送单位,而网络层的下一层就是数据链路层,将分组加上首部和尾部就变成了帧。首部和尾部的一个重要作用就是帧定界(确定帧的界限),当然也包括一些重要的控制信息。
显然,为了提高帧的传输效率,应当使帧的数据部分(IP数据报)尽可能地大于首部和尾部的长度。当是每一种链路层的协议都规定了帧的数据部分的最大长度--MTU,下面的图给出了帧的首部和尾部的位置,以及帧的数据部分和MTU的关系。

当数据是由可打印的 ASCII 码组成的文本文件时,帧定界可以使用特殊的帧定界符。 控制字符 SOH (Start Of Header) 放在一帧的最前面,表示帧的首部开始。另一个控制字符 EOT (End Of Transmission) 表示帧的结束。假定发送端在发送时出现故障,某个帧没有发送完,接收端可以通过是否有EOT来确定这个帧是否完整。
2.2、透明传输
所谓的透明传输是指在数据链路层传送的数据,都能够按照原样没有差错的通过这个数据链路层。也就是相当于数据链路层对于这些数据是透明的。上面,已经说过可以通过控制字符来确定一个帧的开始与结尾,但是如果一个字节的二进制编码恰好和控制字符SOH或EOT一样,那么就会出现帧定界的错误。

所以怎么解决这个问题呢?解决方法:字节填充 (byte stuffing) 或字符填充 (character stuffing)。 发送端的数据链路层在数据中出现控制字符“SOH”或“EOT”的前面插入一个转义字符“ESC” (其十六进制编码是 1B)。接收端的数据链路层在将数据送往网络层之前删除插入的转义字符。 如果转义字符也出现在数据当中,那么应在转义字符前面插入一个转义字符 ESC。当接收端收到连续的两个转义字符时,就删除其中前面的一个。

2.3、差错检测
这里所说的“差错”是“比特差错”,1 可能会变成 0 而 0 也可能变成 1。在一段时间内,传输错误的比特占所传输比特总数的比率称为误码率 BER (Bit Error Rate)。 误码率与信噪比有很大的关系。 为了保证数据传输的可靠性,在计算机网络传输数据时,必须采用各种差错检测措施。
差错检测不是100%可靠! 1)可能漏掉某些差错,但是非常少;2)较大的EDC字段通常有更好的检测性能;
常用的检错码:1)奇偶校验码(垂直奇(偶)校验、水平奇(偶)校验水平、垂直奇(偶)校验(方阵码) );2)循环冗余编码CRC。
在数据链路层传送的帧中,广泛使用了循环冗余检验 CRC 的检错技术。
在数据后面添加上的冗余码称为帧检验序列 FCS (Frame Check Sequence)。
循环冗余检验 CRC 和帧检验序列 FCS并不等同。CRC 是一种常用的检错方法,而 FCS 是添加在数据后面的冗余码。FCS 可以用 CRC 这种方法得出,但 CRC 并非用来获得 FCS 的唯一方法。

仅用循环冗余检验 CRC 差错检测技术只能做到无差错接受(accept)。“无差错接受”是指:“凡是接受的帧(即不包括丢弃的帧),我们都能以非常接近于 1 的概率认为这些帧在传输过程中没有产生差错”。也就是说:“凡是接收端数据链路层接受的帧都没有传输差错”(有差错的帧就丢弃而不接受)。
3、点对点协议PPP
前面已经说过了在点对点信道上协议应该要解决的三个基本的问题,下面就来说一下在数据链路层用得最广泛的协议--点对点协议PPP。
串行线路网际协议(SLIP)是用于WAN链路上封装TCP/IP流量的最早的点到点协议。点对点协议PPP(Point-to-Point Protocol),它克服了SLIP的缺点,PPP不仅提供了帧定界,而且提供了协议标识和位级完整性检查服务。
PPP协议的用处:用户使用拨号电话线接入互联网时, 用户计算机和 ISP 进行通信时所使用的数据链路层协议就是 PPP 协议。
3.1、PPP 协议应满足的需求
- 简单——这是首要的要求
接受方每收到一个帧,就进行 CRC 检验。如果 CRC 检验正确,就收下这个帧;反之,就丢弃这个帧。使用 PPP 的数据链路层向上不提供可靠传输服务,如需可靠传输,则由运输层来完成。 - 封装成帧
- 透明性
- 多种网络层协议
- 多种类型链路
- 差错检测
- 检测连接状态
- 最大传送单元
- 网络层地址协商
- 数据压缩协商
3.2、PPP 协议的组成
1992 年制订了 PPP 协议。经过 1993 年和 1994 年的修订,现在的 PPP 协议已成为因特网的正式标准[RFC 1661]。
PPP 协议有三个组成部分:
1)一个将 IP 数据报封装到串行链路的方法。
PPP支持面向字符的异步链路(无奇偶检验的8位比特数据)和面向比特的同步链路。
2)链路控制协议 LCP (Link Control Protocol)。
3)网络控制协议 NCP (Network Control Protocol)。
3.3、PP协议帧的格式
PPP 帧的首部和尾部分别为 4 个字段和 2 个字段。 标志字段 F = 0x7E (符号“0x”表示后面的字符是用十六进制表示。十六进制的 7E 的二进制表示是 01111110)。 地址字段 A 只置为 0xFF。地址字段实际上并不起作用。 控制字段 C 通常置为 0x03。
PPP 是面向字节的,所有的 PPP 帧的长度都是整数字节。
 3.4、PPP协议透明传输的问题
3.4、PPP协议透明传输的问题
与上面在信道传输的数据一样、PPP协议也是要解决透明传输的问题,来确保我们的帧的定界。
- 当 PPP 用在同步传输链路时,协议规定采用硬件来完成比特填充(和 HDLC 的做法一样)。
- 当 PPP 用在异步传输时,就使用一种特殊的字符填充法。
字符填充:
1)将信息字段中出现的每一个 0x7E 字节转变成为 2 字节序列 (0x7D, 0x5E)。
2)若信息字段中出现一个 0x7D 的字节, 则将其转变成为 2 字节序列 (0x7D, 0x5D)。
3)若信息字段中出现 ASCII 码的控制字符(即数值小于 0x20 的字符),则在该字符前面要加入一个 0x7D 字节,同时将该字符的编码加以改变。
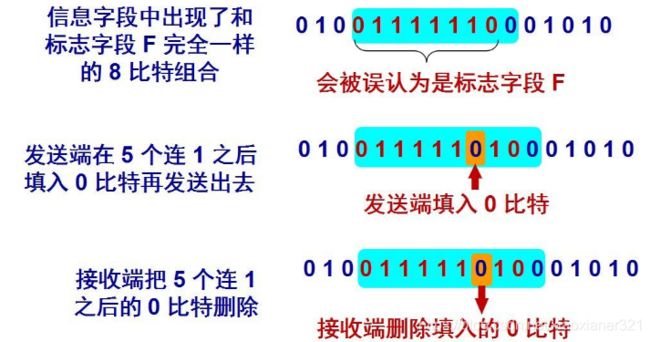
零比特填充:
1)PPP 协议用在 SONET/SDH 链路时,使用同步传输(一连串的比特连续传送)。这时 PPP 协议采用零比特填充方法来实现透明传输。
2)在发送端,只要发现有 5 个连续 1,则立即填入一个 0。
3)接收端对帧中的比特流进行扫描。每当发现 5 个连续1时,就把这 5 个连续 1 后的一个 0 删除。
在数据链路层出现差错的概率不大时,使用比较简单的 PPP 协议较为合理。
3.5、PPP工作状态
1)当用户拨号接入 ISP 时,路由器的调制解调器对拨号做出确认,并建立一条物理连接。
2)PC 机向路由器发送一系列的 LCP 分组(封装成多个 PPP 帧)。
3)这些分组及其响应选择一些 PPP 参数,并进行网络层配置,NCP 给新接入的 PC 机分配一个临时的 IP 地址,使 PC 机成为因特网上的一个主机。
4)通信完毕时,NCP 释放网络层连接,收回原来分配出去的 IP 地址。接着,LCP 释放数据链路层连接。最后释放的是物理层的连接。
可见,PPP 协议已不是纯粹的数据链路层的协议,它还包含了物理层和网络层的内容。
4、以太网的特点
4.1、局域网拓扑结构

局域网的特点与优点:
局域网最主要的特点是:网络为一个单位所有,且地址范围和节点数据均有限。局域网具有如下的一些主要优点:
1)具有广播功能,从一个站点可很方便的访问全网。局域网上的主机共享连接在局域网上的各种硬件和软件资源。
2)便于系统的扩展和逐渐地演变,各设备的位置可灵活调整和改变。
3)提高了系统的可靠性、可用性和生存性。
4.2、以太网的两个标准
DIX Ethernet V2 是世界上第一个局域网产品(以太网)的规范。
IEEE的802.3标准:DIX Ethernet V2标准与 IEEE的802.3标准只有很小的差别,因此可以将802.3局域网简称为“以太网”,严格来说,以太网应当是值符合DIX Ethernet V2标准的局域网。
为了使数据链路层能更好的适应多种局域网标准,802委员会就将局域网的数据链路层拆分成了两个子层:
1)逻辑链路控制LLC(Logical Link Control)子层
2)媒体接入控制MAC(Medium Access Control)子层
与接入到传输媒体有关的内容都放在MAC子层,而LLC子层则与传输媒体无关,不管采用何种协议的局域网对LLC子层来说都是透明的。由于TCP/IP体系经常使用的局域网是DIX Ethernet V2而不是802.3标准中的几种局域网,因此现在802委员会制定的逻辑链路控制子层LCC(即802.2标准)的作用已经不大了。很多厂商生成的适配器上仅装有MAC协议而没有LLC协议。
以太网提供的服务是不可靠的交互,即尽最大努力的交互。
4.3、MAC层的硬件地址(MAC地址)
在局域网中,硬件地址又称为物理地址,或MAC地址(唯一标识一个网卡,由设备商烧入)。802标准所说的地址,严格的将应当是每一个站的名字或标识符。
IEEE的注册管理机构RA负责向厂家分配地址字段的前三个字节(即高位24位),地址字段中的后三个字节(即地位24位)由厂家自行指派,称为扩展标识符,必须保证生产出的适配器没有重复的地址。一个地址块可以生成2^24个不同的地址。这种48位地址称为MAC-48,它的通用名称是BJI-48。
MAC地址实际上就是适配器地址或适配器标识符EUI-48。
例如:D8-CB-8A-D7-B2-AC 前三个字节D8-CB-8A即代表台州微星科技
适配器检查MAC地址:
适配器从网络上每收到一个MAC地址帧就首先用硬件检查MAC帧中的MAC地址,如果是发往本站的帧就收下,然后再进行其他的处理,否则就将此帧丢弃,不再进行其他的处理。发往本站的帧,包括以下三种:
1)单播(unicast)帧(一对一)
2)广播(broadcast)帧(一对全体)
3)多播(multcast)帧(一对多)
那么烧进网卡的地址一般是不可以改变的,要不使用这个物理地址也可以:
我的笔记本的物理地址是84-8F-69开头的(戴尔公司):
我们可以在网络连接中-本地连接-网络客户端-高级-网络地址中改一个:

当我再次查看的时候发现物理地址已经变了:

4.4、以太网帧格式

组成结构:
前同步码(Preamble):前同步码为8位字节长度,由交替的1和0组成。正如其名称所指示的,这个特殊位串放在实际以太网帧的前面,并且不算做整个帧长度的一部分。最后一个字节是一种模式,称为帧首定界符,值为10101011,指示目的地址字段的开始。
目的地址(Destination Address):目的地址字段长度为6个字节,指明目的IP主机的数据链路地址(也称为硬件地址或MAC地址)
源地址(Source Address):源地址字段长度为6个字节,指明发送方的硬件地址,该字段仅仅包含单播地址,不能包含广播和多播地址。
类型(Type):类型字段长2个字节,标识该帧类型的协议。如:0x0800,代表IPv4协议,0x0806代表地址解析协议(ARP)
数据(Data):数据字段长度在64字节到1500字节之间。
帧校验序列(Frame Check Sequence):帧校验序列长4个字节,包含了CRC计算结果。
例如:
使用抓包工具,大概会看到这些内容:

Frame: 物理层数据帧概况。(包括:时间啊、帧长度、帧内封装的协议、着色标记的协议...)

Ethernet II, Src: 数据链路层以太网帧头部信息。(包括:目标MAC地址、源MAC地址、类型:IPv4...)

Internet Protocol Version 4, Src: 互联网层IP包头部信息。(包括:IP包的总长度、源IP地址、目标IP地址...)

Transmission Control Protocol, Src Port: 传输层数据段头部信息,此处是TCP协议。(包括:源端口号、目标端口号、TCP段长度....)

Hypertext Transfer Protocol:应用层信息,此处是HTTP协议。(包括:请求方式get/post、数据....)

4.5、交换机优化以太网
早期的集线器、网桥,只适合于用户数不太多和通信量不太大的局域网。目前用交换机(以太网交换机实质上就是一个多接口的网桥)的比较多。
交换机和集线器的本质区别就在于:当A发信息给B时,如果通过集线器,则接入集线器的所有网络节点都会收到这条信息(也就是以广播形式发送),只是网卡在硬件层面就会过滤掉不是发给本机的信息;而如果通过交换机,除非A通知交换机广播,否则发给B的信息C绝不会收到。
以太网交换机厂商根据市场需求,推出了三层甚至四层交换机。但无论如何,其核心功能仍是二层的以太网数据包交换,只是带有了一定的处理IP层甚至更高层数据包的能力。
虚拟局域网VLAN:是由一些局域网网段构成的与物理位置无关的逻辑组。交换机的使用使得VLAN的创建成为可能。

VLAN1和VLAN2可以达到:VLAN1中的计算机发广播到VLAN2中的计算机中。
五、网络层
网络层位于数据链路层和传输层之间,使用数据链路层提供的服务,为传输层提供服务。数据链路层负责在相邻两个节点间实现数据帧透明、可靠的传输,而网络层的任务要以分组为单位将数据信息从源节点传送到目的节点。
网络层关注的是如何将分组从源端沿着网络路径送达目的端。在计算机网络领域,网络应该向运输层提供怎样的服务?一直存在争议,但主要有两种观点:
一种观点:让网络负责可靠交付。即网络层提供:虚电路服务(首先要发出连接请求,与目的端建立连接-数据通信-拆除连接)。
- 虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
另一种观点是:网络提供数据报服务。
- 网络层向上只提供简单灵活的、无连接的、尽最大努力交付的数据报服务。
- 网络在发送分组时不需要先建立连接。每一个分组(即 IP 数据报)独立发送,与其前后的分组无关(不进行编号)。
- 网络层不提供服务质量的承诺。即所传送的分组可能出错、丢失、重复和失序(不按序到达终点),当然也不保证分组传送的时限。

实质上,目前互联网采用的都是数据报服务。
网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一。前面我们也介绍过IP的构成、分类、子网划分。
- 分类的 IP 地址。这是最基本的编址方法,在1981年就通过了相应的标准协议。
- 子网的划分。这是对最基本的编址方法的改进,其标准[RFC 950]在1985年通过。
- 构成超网。这是比较新的无分类编址方法。1993年提出后很快就得到推广应用。
计算机都有硬件地址(物理地址),为什么需要IP地址呢?MAC地址决定下一跳(不一定是终点),IP地址决定终点到哪去。如果都能得到MAC地址的话,也许就不用IP地址了,但是如果都用广播发通知,那全球的广播泛滥了。
1、IP 地址的一些重要特点
1)IP 地址是一种分等级的地址结构。
分两个等级的好处是:
第一,IP 地址管理机构在分配 IP 地址时只分配网络号,而剩下的主机号则由得到该网络号的单位自行分配。这样就方便了 IP 地址的管理。
第二,路由器仅根据目的主机所连接的网络号来转发分组(而不考虑目的主机号),这样就可以使路由表中的项目数大幅度减少,从而减小了路由表所占的存储空间。
2)实际上 IP 地址是标志一个主机(或路由器)和一条链路的接口。
当一个主机同时连接到两个网络上时,该主机就必须同时具有两个相应的 IP 地址,其网络号 net-id 必须是不同的。这种主机称为多归属主机 (multihomed host)。
由于一个路由器至少应当连接到两个网络(这样它才能将 IP 数据报从一个网络转发到另一个网络),因此一个路由器至少应当有两个不同的 IP 地址。
3)用转发器或网桥连接起来的若干个局域网仍为一个网络,因此这些局域网都具有同样的网络号 net-id。
4)所有分配到网络号 net-id 的网络,无论是范围很小的局域网,还是可能覆盖很大地理范围的广域网,都是平等的。
与 IP 协议配套使用的还有三个协议:
①地址解析协议 ARP (Address Resolution Protocol)
②网际控制报文协议 ICMP (Internet Control Message Protocol)
③网际组管理协议 IGMP (Internet Group Management Protocol)
2、ARP与RARP协议
2.1、ARP定义
百度百科给出的解释:
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。地址解析协议是建立在网络中各个主机互相信任的基础上的,局域网络上的主机可以自主发送ARP应答消息,其他主机收到应答报文时不会检测该报文的真实性就会将其记入本机ARP缓存;由此攻击者就可以向某一主机发送伪ARP应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个ARP欺骗。ARP命令可用于查询本机ARP缓存中IP地址和MAC地址的对应关系、添加或删除静态对应关系等。相关协议有RARP、代理ARP。NDP用于在IPv6中代替地址解析协议。
2.2、ARP原理及流程
在同一局域网:主机A怎么把数据报发送给主机B

1)首先A主机在网络层运行的IP进程,封装IP数据报(含有B的IP);
2)查看本地主机的“ARP缓存(或表)”中是否已经缓存了ip地址与mac地址之间的映射,如果没有缓存,则进入下面的步骤。
3)运行ARP进程,A的ARP进程,向“所有主机”发送一个称为“ARP请求”的以太网帧。这种行为被称为“以太网广播”(也叫链路层广播)。而“ARP请求”的目的是:如果某主机接收了该ARP请求,且该主机IPv4地址也与209.0.0.6一致,那么这台主机请返回给我你的MAC地址。B响应(不是B,不理睬),向A发送ARP响应分组,A主机收到得到MAC.B,写入缓存。
4)主机A交给数据链路层,封装成MAC帧,交给物理层,转换成信号,发送出去。
5)主机B就能收到该MAC帧,得到A交付的IP数据报。
不在同一局域网:
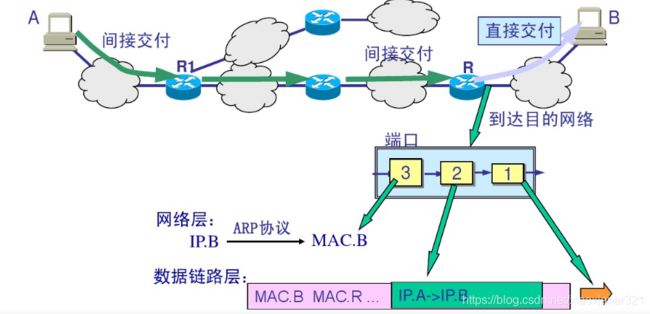
首先判断A和B是不是在同一局域网内,不是,主机A把数据报交付给本地路由器,中间路由器进一步转发,最后到达目的网络,目的网络路由器进行直接交付。
2.3、RARP协议
反向地址转换协议(RARP:Reverse Address Resolution Protocol) 反向地址转换协议(RARP)允许局域网的物理机器从网关服务器的 ARP 表或者缓存上请求其 IP 地址。网络管理员在局域网网关路由器里创建一个表以映射物理地址(MAC)和与其对应的 IP 地址。当设置一台新的机器时,其 RARP 客户机程序需要向路由器上的 RARP 服务器请求相应的 IP 地址。假设在路由表中已经设置了一个记录,RARP 服务器将会返回 IP 地址给机器,此机器就会存储起来以便日后使用。 RARP 可以使用于以太网、光纤分布式数据接口及令牌环 LAN。
BOOTP(BOOT Protocol,引导协议),引导无盘计算机或者第一次启动的计算机获取以下网络配置信息:
- 主机的IP地址、子网掩码
- 路由器(网关)的IP地址
- DNS服务器IP地址
最终DHCP(Dynamic Host Configuration Protocol,动态主机配置协议,RFC 2131)取代了RARP ,DHCP是BOOTP的扩充和增强,与BOOTP向后兼容,在有限期间内提供临时的静态的或动态配置。
3、IP数据报
3.1、IP数据报组成
一个IP数据报由首部和数据两部分组成:首部的前一部分是固定长度,共20字节,是所有IP数据报必须具有的;在首部的固定部分的后面是一些可选字段,其长度是可变的。

IP数据报详细图:

IP数据报首部的组成:
1)版本:IP首部的第一个字段是Version(版本)字段,当前在用的协议版本是4(即IPv4)。
2)首部长度:用于指明IP首部的长度(因为包含可选字段,其长度可变)。占4位,可表示的最大数值是(2^4-1)15个单位(一个单位4字节),因此IP首部的最大值是60字节。
备注:首部长度占4位,这个字段所表示数的单位是32位字长(1个32位字长是4字节),可表示的最大十进制数值是15(1111),最常用的首部长度就是20字节(即首部长度为0101),这时不使用任何选项。
3)区分服务(服务类型):占8位,用来获得更好的服务,在旧标准中叫做服务类型,但实际上一直未被使用过。1998年,这个字段改名为区分服务,只有在使用区分服务时这个字段才起作用,它实际由两部分,优先级和服务类型。优先级在前三位中定义,路由器可由它优化穿越路由队列的流量。服务类型在后四位定义,最后一位被保留(即PPPTTTT0)。
优先级:二进制111
4)总长度:首部和数据之和的长度,单位为字节。数据报最大长度为2^16-1 = 655252 字节。总长度必须不超过最大单元MTU。
5)标识:IP 软件在存储器中维持一个计数器,每产生一个数据报,计数器就加 1,并将此值赋给标识字段。当数据报由于长度超过网络的 MTU 而必须分片时,这个标识字段的值就被复制到所有的数据报片的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报。
6)标志:占 3 位,目前只有两位有意义。标志字段中的最低位记为 MF (More Fragment)。MF = 1 表示后面“还有分片”的数据报。MF = 0 表示这已是若干数据报片中的最后一个。
标志字段中间的一位记为 DF (Don’t Fragment)。意思是“不能分片”。只有当 DF = 0 时才允许分片。
7)片便宜(分段偏移):较长的分组在分片后,某片在原分组中的相对位置。即,相对于用户数据字段的起点。片偏移以 8 个字节为偏移单位。

8)生存时间(TTL):表明这是数据报在网络中的寿命。由发出数据报的源点设置这个字段。其目的是防止无法交付的数据报无限制地在互联网中兜圈子。
现在 TTL 的单位是跳数。TTL 的意义是指明数据报在互联网中至多可经过多少个路由器。最大数值是 255。
若把 TTL 的初始值设置为 1,就表示这个数据报只能在本局域网中传送。因为这个数据报一传送到局域网上的某个路由器,在被转发之前 TTL 值就减小到零,被这个路由器丢弃。
不同的操作系统的默认TTL值是不同的, 所以我们可以通过TTL值来判断主机的操作系统,但是当用户修改了TTL值的时候,就会误导我们的判断,所以这种判断方式也不一定准确。下面是默认操作系统的TTL:
WINDOWS NT/2000 TTL:128
WINDOWS 95/98 TTL:32
UNIX TTL:255
LINUX TTL:64
WIN7 TTL:64
举个例子:
我ping baidu.com 的TTL=56,64->56=(9),也就是说我到百度,中途经过了9个路由。

我们再使用tracert 命令,跟踪一下:

注意一下有的值为“请求超时” ,原因是有的路由器是禁止Ping的(所以不会返回信息)。TTL值在注册表的位置是:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
TTL的推荐值是64。windows系统修改后重启才生效。![]()
9)协议:指出此数据报携带的数据是使用何种协议,以便使目的主机的 IP 层知道应将数据部分上交给哪个协议处理。
| 协议名 | ICMP | IGMP | IP | TCP | EGP | IGP | UDP | IPv6 | ESP | OSPF |
|---|---|---|---|---|---|---|---|---|---|---|
| 协议字段值 | 1 | 2 | 4 | 6 | 8 | 9 | 17 | 41 | 50 | 89 |
10)首部校验和:只检验数据报的首部,但不包括数据部分。IP 首部的检验和不采用复杂的 CRC 检验码而采用下面的简单计算方法:

二进制反码求和运算:从低位到高位逐列进行计算。0 + 0 = 0;0 + 1 = 1;1 + 1 = 0,产生一个进位 1,加到下一列。若最高位相加后产生进位,则最后得到的结果要加 1。
11)源地址:占4字节,这是发送IP数据报,IP的IP主机的IP地址。在某些情况下,比如在DHCP引导过程中IP主机或许不知道自己的IP,因此这个字段可以使用0.0.0.0。
12)目的地址:占4字节,这个字段能够包含单播、多播、广播地址。这是数据包最终目的地址。
13)可选字段(长度可变):从1字节到40字节不等,取决于所选择的项目。增加首部的可变部分是为了增加IP数据报的功能,但这同时也使得IP数据报的首部长度成为可变的。这就增加了每一个路由器处理数据的开销,实际上这些选项也很少被使用。
3.2、IP转发分组的流程
在互联网上转发分组时,是从一个路由器转发到下一个路由器。路由器是怎样转发分组的?路由表指出到某个网络应如何转发,每个路由器中的路由表中的每一行对应于一个网络。在路由表中,对每一条路由最主要的是两个信息:目的网络地址、下一跳地址
互联网所有的分组转发都是基于目的主机所在的网络,但在大多数情况下允许有特例,即对特定的目的主机指明一个路由。这种路由叫做特定主机路由。路由器还可采用默认路由 (default route) 以减小路由表所占用的空间何搜索路由表所用的时间。如:添加默认路由,route add 0.0.0.0 mask 0.0.0.0 192.168.1.1
分组转发算法:
(1) 从数据报的首部提取目的主机的 IP 地址 D,得出目的网络地址为 N。
(2) 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付,不需要再经过其他的路由器,直接把数据报交付目的主机 (包括把 D 转换为具体的硬件地址,把数据报封装为 MAC 帧,再发送此帧);否则就是间接交付,执行 (3)。
(3) 若路由器有目的地址为 D 的特定主机路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行 (4)。
(4) 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;否则执行 (5)。
(5) 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则执行 (6)。
(6) 报告转发分组出错。
注:IP数据报的首部没有地方可以用来指明下一跳的路由IP,而是使用ARP将下一跳路由器的IP地址转换成MAC地址,并将此MAC地址放在链路层的MAC帧的首部,然后根据这个MAC地址找到下一跳路由器。
3.3、路由表查找
最佳匹配:使用CIDR时,路由表中的每个项目由“网络前缀“和下一跳地址时,在查找路由表时可能匹配到的结果不止一个。应当从匹配结果中选择具有最长网络前缀的路由,网络前缀越长,其地址模块就越小,路由表就越具体。
当路由表项目数很大,怎样去减少路由表的查找时间?为了进行更有效的查找,这里最常用的就是二叉线索。
例如:

路由表的排列是有规则的,如果第一位是0,则走从0左边的那条开始,这样依次进行。
4、ICMP协议
4.1、ICMP协议定义
为了提高IP数据报交付成功的机会。在网际层使用了网际控制报文协议ICMP(Internet Control Message Protocol)。它是TCP/IP协议簇的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。
ICMP 允许主机或路由器报告差错情况和提供相关异常情况的报告。ICMP报文作为IP层数据报的数据,加上数据报的首部,组成IP数据报发送出去。
4.2、 ICMP典型运用—ping
ICMP的一个典型应用是Ping。
Ping是检测网络连通性的常用工具,同时也能够收集其他相关信息。
用户可以在Ping命令中指定不同参数,如ICMP报文长度、发送的ICMP报文个数、等待回复响应的超时时间等,设备根据配置的参数来构造并发送ICMP报文,进行Ping测试。
Ping常用的配置参数说明如下:
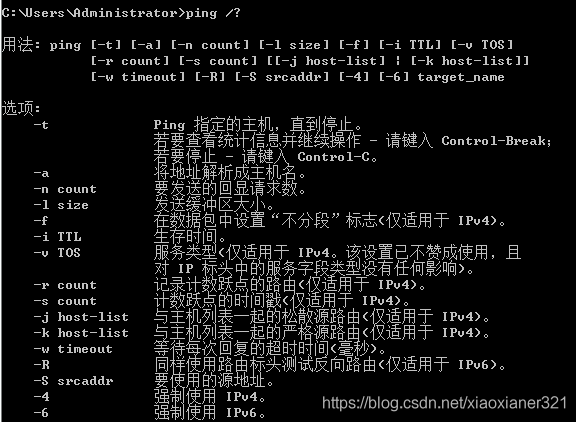
Ping命令的输出信息中包括目的地址、ICMP报文长度、序号、TTL值、以及往返时间。

4.3、 ICMP典型运用—Tracert
ICMP的另一个典型应用是Tracert。
Tracert基于报文头中的TTL值来逐跳跟踪报文的转发路径。
Tracert是检测网络丢包及时延的有效手段,同时可以帮助管理员发现网络中的路由环路。
Tracert常用的配置参数说明如下:

另外还有,pathping,pathping 命令是一个路由跟踪工具,它将 ping 和 tracert 命令的功能与这两个工具所不提供的其他信息结合起来,综合了二者的功能。

因为到第四条(节点)的时候,不支持ping,然后,程序就终止不在继续往下探测了。
4.4、ICMP类型
ICMP报文主要有两大功能:查询报文和差错报文。
对于查询报文,常用的ping命令,以及用于无盘系统启动获取网络子网掩码查询报文。

对于差错报文在一些情况下目标主机不会返回对应的数据包,当路由器收到一个无法传递下去的IP报文时,会发送ICMP目的不可达报文(Type为3)给IP报文的源发送方,报文中的Code就表示发送失败的原因(可能是主机不可达、端口不可达...)。
当路由器或主机处理数据报时,发现因为报文头的参数错误而不得不丢弃报文时,需要向源发送方发送参数错误报文(Type为12),当Code为0时,报文中的Pointer表示错误的字节位置。
当路由收到IP数据报,发现数据报的目的地址在路由表上没有,它就会发ICMP重定向报文(Type为5)给源发送方,提醒它想要发送的地址不在,去其他地方找找吧。
| TYPE | CODE | Description | Query | Error |
|---|---|---|---|---|
| 0 | 0 | Echo Reply——回显应答(Ping应答) | x | |
| 3 | 0 | Network Unreachable——网络不可达 | x | |
| 3 | 1 | Host Unreachable——主机不可达 | x | |
| 3 | 2 | Protocol Unreachable——协议不可达 | x | |
| 3 | 3 | Port Unreachable——端口不可达 | x | |
| 3 | 4 | Fragmentation needed but no frag. bit set——需要进行分片但设置不分片比特 | x | |
| 3 | 5 | Source routing failed——源站选路失败 | x | |
| 3 | 6 | Destination network unknown——目的网络未知 | x | |
| 3 | 7 | Destination host unknown——目的主机未知 | x | |
| 3 | 8 | Source host isolated (obsolete)——源主机被隔离(作废不用) | x | |
| 3 | 9 | Destination network administratively prohibited——目的网络被强制禁止 | x | |
| 3 | 10 | Destination host administratively prohibited——目的主机被强制禁止 | x | |
| 3 | 11 | Network unreachable for TOS——由于服务类型TOS,网络不可达 | x | |
| 3 | 12 | Host unreachable for TOS——由于服务类型TOS,主机不可达 | x | |
| 3 | 13 | Communication administratively prohibited by filtering——由于过滤,通信被强制禁止 | x | |
| 3 | 14 | Host precedence violation——主机越权 | x | |
| 3 | 15 | Precedence cutoff in effect——优先中止生效 | x | |
| 4 | 0 | Source quench——源端被关闭(基本流控制) | ||
| 5 | 0 | Redirect for network——对网络重定向 | ||
| 5 | 1 | Redirect for host——对主机重定向 | ||
| 5 | 2 | Redirect for TOS and network——对服务类型和网络重定向 | ||
| 5 | 3 | Redirect for TOS and host——对服务类型和主机重定向 | ||
| 8 | 0 | Echo request——回显请求(Ping请求) | x | |
| 9 | 0 | Router advertisement——路由器通告 | ||
| 10 | 0 | Route solicitation——路由器请求 | ||
| 11 | 0 | TTL equals 0 during transit——传输期间生存时间为0 | x | |
| 11 | 1 | TTL equals 0 during reassembly——在数据报组装期间生存时间为0 | x | |
| 12 | 0 | IP header bad (catchall error)——坏的IP首部(包括各种差错) | x | |
| 12 | 1 | Required options missing——缺少必需的选项 | x | |
| 13 | 0 | Timestamp request (obsolete)——时间戳请求(作废不用) | x | |
| 14 | Timestamp reply (obsolete)——时间戳应答(作废不用) | x | ||
| 15 | 0 | Information request (obsolete)——信息请求(作废不用) | x | |
| 16 | 0 | Information reply (obsolete)——信息应答(作废不用) | x | |
| 17 | 0 | Address mask request——地址掩码请求 | x | |
| 18 | 0 | Address mask reply——地址掩码应答 |
5、动态路由协议
在进行三层通信时,除了静态配置路由信息,还可以通过动态获取路由条目,而这就需要使用路由协议来帮助我们了。根据管理范围的不同,路由协议可以分为两个大类:
1) IGP:内部网关协议(Interior Gateway Protocol)
是一种专用于一个自治网络系统(比如:某个当地社区范围内的一个自治网络系统)中网关间交换数据流转通道信息的协议。网络IP协议或者其他的网络协议常常通过这些通道信息来决断怎样传送数据流。目前最常用的内部网关协议分别是:路由信息协议(RIP)和最短路径优先路由协议(OSPF)分级的链接状态路由协议(ISIS)
2)EGP:外部网关协议(Exterior Gateway Protocol)
外部网关协议(EGP)是一种在自治系统的相邻两个网关主机间交换路由信息的协议。 EGP 通常用于在因特网主机间交换路由表信息。它是一个轮询协议,利用 Hello 和 I-Heard-You 消息的转换,能让每个网关控制和接收网络可达性信息的速率,允许每个系统控制它自己的开销,同时发出命令请求更新响应。路由表包含一组已知路由器及这些路由器的可达地址以及路径开销,从而可以选择最佳路由。每个路由器每间隔 120 秒或 480 秒会访问其邻居一次,邻居通过发送完整的路由表以示响应,代表协议是边界网关协议(BGPv4)。
如果按照算法分,也可以分成两个大类:距离矢量型路由协议,代表:RIP;链路状态路由协议,代表:OSPF
5.1、RIP协议
RIP(Routing Information Protocol,路由信息协议)是一种内部网关协议(IGP),是一种动态路由选择协议,用于自治系统(AS)内的路由信息的传递。
RIP 被定义为距离矢量路由协议,而距离矢量路由协议的根本特征就是自己的路由表是完全从其它路由器学来的,并且将收到的路由条目一丝不变地放进自己的路由表,以供数据转发。正因为如此,对于路由是否正确,对于目标是否可达,RIP全然不知。
举个栗子:
比方我要到A大厦,位置是在东北边的。不知道怎么走,那我问个路人,路人说A大厦往北走,找不到地方对吧,好的,我又找个人去问,这个人又说,A大厦往西边走,结果你又去了西边,这样死循环下去,那你永远到达不了目的地。RIP就是这种传闻式的路由协议,最大的缺点就是太相信邻居,自己不会判断和思考,最终的结果就是导致路由环路的产生。
RIP 使用跳数作为 metric,跳数就是到达目标网络所需要经过的路由器个数,因为直连网络不需要经过任何路由器,所以直连网络的 metric 为 0。RIP 所支持网络的最大跳数为 15,也就是 metric 值最大为 15,一但大于 15,如 16,被 RIP 认为目标不可达,由此可见,RIP 并不适合大型网络。
RIP协议的管理距离为120。当路由表中出现了多条目标网段、子网掩码相同的路由信息时,优先选择管理距离小的协议所生成的路由信息。
RIP协议一共有两个版本:
Version 1 有类路由协议,广播更新。(由于不支持VLSM,RIPV1已经被淘汰,以RIPv2为主)
Version 2 无类路由协议,支持VLSM
RIP优点:
对于小型网络,RIP就所占带宽而言开销小,易于配置、管理和实现;
“好”消息传的快;
RIP缺点:
(1)网络规模被限制,最大跳数为15跳
(2)使用“跳数”作为度量值,以跳数的多少比较路由路径的优劣。 RIP 选择一个具有最少路由器的路由(即最短路由),哪怕还存在另一条高速(低时延)但路由器较多的路由。
(3)收敛速度慢。当网络中出现拓扑变化时,需要较长的时间才会收敛。可能会导致网络中路由表信息不一致。
(4)路由器之间交换的路由信息是路由器中的完整路由表,因而随着网络规模的扩大,开销也就增加。
5.2、OSPF协议
OSPF(Open Shortest Path First开放式最短路径优先)是一个内部网关协议(Interior Gateway Protocol,简称IGP),用于在单一自治系统(autonomous system,AS)内决策路由。是对链路状态路由协议的一种实现,隶属内部网关协议(IGP),故运作于自治系统内部。著名的迪克斯彻(Dijkstra)算法被用来计算最短路径树。OSPF支持负载均衡和基于服务类型的选路,也支持多种路由形式,如特定主机路由和子网路由等。
距离矢量路由协议的根本特征就是自己的路由表是完全从其它路由器学来的,并且将收到的路由条目一丝不变地放进自己的路由表,运行距离矢量路由协议的路由器之间交换的是路由表,距离矢量路由协议是没有大脑的,路由表从来不会自己计算,总是把别人的路由表拿来就用;而 OSPF 完全抛弃了这种不可靠的算法,OSPF是典型的链路状态路由协议,路由器之间交换的并不是路由表,而是链路状态,OSPF通过获得网络中所有的链路状态信息,从而计算出到达每个目标精确的网络路径。
举个例子:
OSPF是链路状态路由协议,有点类似于我们常用的高德地图和百度地图这类手机APP,能给你算出一条最优路径,走什么路,怎么走,在OSPF里面成为LSDB,那LSDB里面包含了LSA,有点像我去某个地方,一共有X个方案,到底是哪个方案更好,费用更省,时间更划算,那这个肯定是LSDB说了算。LSDB就相当于是最优方案,LSA是告诉你有多少个方案,而且万一这条路有修路,作为路由协议怎么样才知道呢?那肯定就是LSACK、LSU这些报文维护,会在本区域内部通告:某某某不能走了,能不能走另外一条,然后重新计算一条最优路径出来生成LSDB。
OSPF 工作在单个 AS,是个绝对的内部网关路由协议(Interior Gateway Protocol, 即 IGP)。
OSPF 对网络没有跳数限制,支持 CIDR和VLSM,没有自动汇总功能,但可以手工在任意比特位汇总,并且手工汇总没有任何条件限制,可以汇总到任意掩码长度。
OSPF 并不会周期性更新路由表,而采用增量更新,即只在路由有变化时,才会发送更新,并且只发送有变化的路由信息;事实上,OSPF 是间接设置了周期性更新路由的规则,因为所有路由都是有刷新时间的,当达到刷新时间阀值时,该路由就会产生一次更新,默认时间为 1800 秒,即 30 分钟,所以 OSPF 路由的定期更新周期默认为 30 分钟。
OSPF 所有路由的管理距离(Ddministrative Distance)为 110,OSPF 只支持等价负载均衡。
OSPF 支持认证,并且支持明文和 MD5 认证;OSPF 不可以通过 Offset list 来改变路由的度量值( metric)。
6、IGMP协议
Internet 组管理协议称为IGMP协议(Internet Group Management Protocol),是因特网协议家族中的一个组播协议。该协议运行在主机和组播路由器之间。IGMP协议共有三个版本,即IGMPv1、v2 和v3。
说到IGMP 不能不提“组播”的概念。假如现在一个主机想将一个数据包发给网络上的若干主机,有什么方法可以做到呢?一个方法是采用广播包发送,这样网络上的所有主机都能够接收到,另一种方式是将数据包复制若干份分别发给目的主机。这两个方法都存在问题:方法一,广播的方法导致网络上所有的主机都能接收到,占用了网络上其他主机的资源。方法二,由于所有目的主机接收的报文都是相同的,采用单播方式显然效率很低。为了解决上面所述的问题,人们提出了“组播”的概念,控制一个报文发送给对该报文感兴趣的主机,IGMP 就是组播管理协议。
7、VPN
VPN全称为“Virtual Private Network”,即虚拟专用网络。虚拟专用网是一种常用于连接中、大型企业或团体与团体间的私人网络的通讯方法。虚拟私人网络的讯息透过公用的网络架构(例如:互联网)来传送内联网的网络讯息。它利用已加密的通道协议(Tunneling Protocol)来达到保密、发送端认证、消息准确性等私人消息安全效果。

即在广域网中也封装了局域网的数据包。
8、NAT和PAT
8.1、网络地址转换NAT
NAT全称(Network Address Translation)网络地址转换,于1994年提出,需要在专用网络连接到因特网的路由器上安装NAT软件。装有NAT软件的路由器叫NAT路由器,他至少有一个外部全球地址IP,所有使用本地地址的主机在和外界通信时都要在NAT路由器上将其本地地址转换成IP,才能和因特网连接。
为什么会有NAT?
时光回到上个世纪80年代,当时的人们在设计网络地址的时候,觉得再怎么样也不会有超过32bits位长即2的32次幂台终端设备连入互联网,后来逐渐发现IP地址不够用了,然后就NAT就诞生了!NAT技术能够兴起的原因还是因为在我们国家公网IP地址太少了,不够用,所以才会采取这种地址转换的策略。可见,NAT的本质就是让一群机器公用同一个IP,这样就暂时解决了IP短缺的问题。
NAT 设备通常是路由器或防火墙。
8.2、NAT的实现方式
8.2.1、静态NAT
也就是静态地址转换。是指一个公网IP对应一个私有IP,是一对一的转换,建立和维护一张静态地址映射表。同时注意,这里只进行了IP转换,而没有进行端口的转换。
8.2.2、动态 NAT
是公网 IP 地址和私有 IP 地址有一对多的关系,同一个公网 IP 地址分配给不同的私网用户使用,使用时间必须错开。它包含一个公有 IP 地址池和一张动态地址映射表。
例如:
私网主机 A( 10.0.0.1 )需要访问公网的服务器 Server( 61.144.249.229 ),在路由器 RT 上配置 NAT ,地址池为 219.134.180.11 ~ 219.134.180.20 ,地址转换过程如下:

1)A 向 Server 发送报文,网关是 10.0.0.254 ,源地址是 10.0.0.1 ,目的地址是 61.144.249.229 。
2)RT 收到 IP 报文后,查找路由表,将 IP 报文转发至出接口,由于出接口上配置了 NAT ,因此 RT 需要将源地址 10.0.0.1 转换为公网地址。
3)RT 从地址池中查找第一个可用的公网地址 219.134.180.11 ,用这个地址替换数据包的源地址,转换后的数据包源地址为 219.134.180.11 ,目的地址不变。同时 RT 在自己的 NAT 表中添加一个表项,记录私有地址 10.0.0.1 到 公网地址 219.134.180.11 的映射。RT 再将报文转发给目的地址 61.144.249.229 。

4)Server 收到报文后做相应处理, 发送回应报文,报文的源地址是 61.144.249.229 ,目的地址是 219.134.180.11 。
5)RT 收到报文,发现报文的目的地址 219.134.180.11 在 NAT 地址池内,于是检查 NAT 表,找到对应表项后,使用私有地址 10.0.0.1 替换公网地址 219.134.180.11,转换后的报文源地址不变,目的地址为 10.0.0.1 。RT 在将报文转发给 A 。

6)A 收到报文,地址转换过程结束。
8.2.3、端口NAT(PAT),也叫NAPT
网络地址端口转换 NAPT(Network Address Port Translation)技术。在基础 NAT 中,私有地址和公网地址存在一对一地址转换的对应关系,即一个公网地址同时只能分配给一个私有地址。它只解决了公网和私网的通信问题,并没有解决公网地址不足的问题。

NAPT( Network Address Port Translation )对数据包的 IP 地址、协议类型、传输层端口号同时进行转换,可以明显提高公网 IP 地址的利用率。有了端口号,就能一对多,如果内部端口都是1024,回来的时候,外部地址,不知道该映射内部的哪个地址。

例如:

1)A 向 Server 发送报文,网关是 RT( 10.0.0.254 ),源地址和端口是 10.0.0.1:1024 ,目的地址和端口是 61.144.249.229:80
2)RT 收到 IP 报文后,查找路由表,将 IP 报文转发至出接口,由于出接口上配置了 NAPT ,因此 RT 需要将源地址 10.0.0.1:1024 转换为公网地址和端口。
3)RT 从地址池中查找第一个可用的公网地址 219.134.180.11 ,用这个地址替换数据包的源地址,并查找这个公网地址的一个可用端口,例如 2001 ,用这个端口替换源端口。转换后的数据包源地址为 219.134.180.11:2001 ,目的地址和端口不变。同时 RT 在自己的 NAT 表中添加一个表项,记录私有地址 10.0.0.1:1024 到 公网地址 219.134.180.11:2001 的映射。RT 再将报文转发给目的地址 61.144.249.229 。

4)Server 收到报文后做相应处理,Server 发送回应报文,报文的源地址是 61.144.249.229:80 ,目的地址是 219.134.180.11:2001 。
5)RT 收到报文,发现报文的目的地址在 NAT 地址池内,于是检查 NAT 表,找到对应表项后,使用私有地址和端口 10.0.0.1:1024 替换公网地址 219.134.180.11:2001,转换后的报文源地址和端口不变,目的地址和端口为 10.0.0.1:1024 。RT 再将报文转发给 A 。A 收到报文,地址转换过程结束。
6)如果 B 也要访问 Server ,则 RT 会从地址池中分配同一个公网地址 219.134.180.11 ,但分配另一个端口 3001 ,并在 NAT 表中添加一个相应的表项,记录 B 的私有地址 10.0.0.2:1024 到公网地址 219.134.180.12:3001 的映射关系。

六、传输层
网络层,数据链路层与物理层实现了网络中主机之间的数据通信,主要涉及IP(RIP/OSPF BGP)、ICMP、IGMP、ARP这些协议,而传输层的主要功能是实现分布式进程之间的通信。利用网络层提供的服务,在源主机的应用进程与目的主机的应用进程建立“端—端”连接。
传输层的两个主要协议:TCP和UDP协议。
UDP(User Datagram Protocol):用户数据报协议;
TCP(Transmission Control Protocol):传输控制协议;
两个对等运输实体在通信时传送的数据单位叫做运输协议数据单元TPDU(Transport Protocol Data Unit)。
TCP传送的协议数据单元是TCP报文段(segement);
UDP传送的协议数据单元是UDP报文或用户数据报;
1、概念解析
1.1、TCP与UDP的区别
UDP在传送数据之前不需要先建立连接。对方的数据在运输层在接收到UDP报文后,不需要给出任何确认。虽然UDP不提供可靠交付,但在某些情况下UDP是一种最有效的工作方式。(UDP 多用于一个数据包就能完成数据通信)
TCP则提供面向连接的服务。TCP不提供广播或多播服务。由于TCP要提供可靠的、面向连接的运输服务,因此不可避免地增加了许多的开销。这不仅使协议数据单元的首部增大很多,还要占用许多的处理机资源。
1.2、运输层的端口号
运行在计算机中的进程是用进程标识符来标志的。为了使运行不同操作系统的计算机的应用进程能够互相通信,就必须用统一的方法对 TCP/IP 体系的应用进程进行标志,解决这个问题的方法就是在传输层使用协议端口号或端口。虽然通信的终点是应用进程,但只要把要传送的报文交到目的主机的某一个合适的目的端口,剩下的工作(即最后交付目的进程)就由 TCP / UDP 来完成。端口号只具有本地意义,它只是为了标志本地计算机应用层的各个进程在和传输层交互时的层间接口。
硬件端口是不同硬件设备进行交互的接口,而软件端口是应用层的各种协议进程与运输实体进行层间交互的一种地址。

1.3、端口分类
端口号有两种基本分配方式:第一种叫全局分配这是一种集中分配方式,由一个公认权威的中央机构根据用户需要进行统一分配,并将结果公布于众,第二种是本地分配,又称动态连接,即进程需要访问传输层服务时,向本地操作系统提出申请,操作系统返回本地唯一的端口号,进程再通过合适的系统调用,将自己和该端口连接起来(binding,绑定)。
端口号可分为三大类:
1)公认端口(WellKnownPorts):一般从0到1023,它们紧密绑定(binding)于一些服务。通常这些端口的通讯明确表明了某种服务的协议。例如:
http=TCP+80,80端口实际上总是HTTP通讯;
https=TCP+443
ftp=TCP+21
SMTP=TCP+25
DNS=UDP+53 / TCP+53
POP3=TCP+110
共享文件夹=TCP+445
2)注册端口(RegisteredPorts):从1024到49151。使用这个范围的端口号必须在IANA登记,以防止重复。例如:
SQL=TCP+1433
MySQL=TCP+3306
3)动态/客户端口:从49152到65535。留给客户进程选择暂时使用。当服务器进程收到客户进程的报文时,就知道了客户进程所使用的动态端口号,通信结束后,这个端口号可供其他客户进程以后使用。
2、UDP协议
2.1、UDP 概述
UDP协议只在IP的数据报服务之上增加了复用、分发及差错检测的功能。UDP 传送的数据单位协议是 UDP 报文或用户数据报。
UDP的主要特点:
- 是无连接的,即发送数据之前不需要建立连接
- 使用最大努力交付,即不保证可靠交付
- 是面向报文的【UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界,即应用层交给UDP多长的报文,UDP就照样发送即一次发送一个报文。所以应用程序要选择合适大小的报文。传输层从IP层收到UDP数据报时,根据首部中的目的端口,把UDP数据报通过相应的端口,上交给应用进程。】
- UDP没有拥塞控制,所以网络出现的拥塞不会使源主机的发送速率降低
- 支持一对一,一对一多,多对一,多对多的交互通信
- 首部开销小,只有8个字节
2.2、UDP 的首部格式
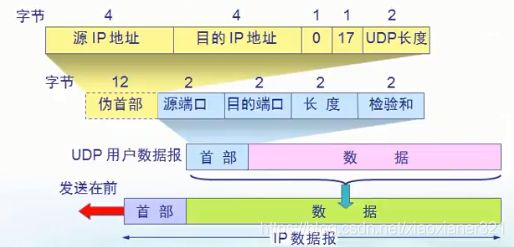
伪首部:在计算检验和时,临时把“伪首部”和 UDP 用户数据报连接在一起。伪首部仅仅是为了计算检验和。
 3、TCP 概述
3、TCP 概述
TCP(Transmission Control Protocol,传输控制协议)是面向连接的协议,也就是说,在收发数据前,必须和对方建立可靠的连接。
3.1、TCP 的特点
- TCP 是面向连接的运输层协议。
- 每一条 TCP 连接只能有两个端点 (endpoint),每一条 TCP 连接只能是点对点的(一对一)。
- TCP 提供可靠交付的服务。
- TCP 提供全双工通信。
- 面向字节流【流是指流入到进程或从进程流出的字节序列,虽然应用程序和 TCP 的交互是一次一个数据块,但 TCP 把应用程序交下来的数据看成仅仅是一连串无结构的字节流。TCP并不知道所传送字节流的含义。TCP不保证接收方应用程序所收到的数据块和发送方应用程序所发出的数据块大小一样,但接收方应用程序收到的字节流和发送方应用程序所发出的字节流完全一样】
3.2、TCP 的连接
TCP 连接的端点不是主机,不是主机的IP 地址,不是应用进程,也不是运输层的协议端口。TCP 连接的端点叫做套接字 (socket) 或插口。
套接字 (socket):端口号拼接到 (contatenated with) IP 地址即构成了套接字。

TCP连接的端点是个很抽象的套接字。同一个IP地址可以有多个不同的TCP连接,同一个端口号也可以有多个不同的TCP连接。
3.3、TCP 报文段的首部格式
TCP 虽然是面向字节流的,但 TCP 传送的数据单元却是报文段。
一个 TCP 报文段分为首部和数据两部分,而 TCP 的全部功能都体现在它首部中各字段的作用。
TCP 报文段首部的前 20 个字节是固定的,后面有 4n 字节是根据需要而增加的选项 (n 是整数)。因此 TCP 首部的最小长度是 20 字节。
首部结构:

1)源端口和目的端口字段:各占 2 字节。端口是运输层与应用层的服务接口。运输层的复用和分用功能都要通过端口才能实现;
2)序号字段:占 4 字节。TCP 连接中传送的数据流中的每一个字节都编上一个序号。序号字段的值则指的是本报文段所发送的数据的第一个字节的序号;
3)确认号字段:占 4 字节,是期望收到对方的下一个报文段的数据的第一个字节的序号;
4)数据偏移(即首部长度):占 4 位,它指出 TCP 报文段的数据起始处距离 TCP 报文段的起始处有多远。“数据偏移”的单位是 32 位字(以 4 字节为计算单位);
5)保留字段:占 6 位,保留为今后使用,但目前应置为 0。
6)紧急 URG:当 URG ==1 时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)。
7)确认ACK(ACKnowlegment):当ACK=1,确认号字段才有效,当ACK=0,确认号字段无效。TCP规定,在连接建立后所有传送的报文段都必须把ACK置1。
8)推送PSH(PuSH):当两个进程通信时,有时一端的进程希望键入一个命令后,能立即收到对方的响应,这时TCP就可以将PSH=1,并立即创建一个报文段发送出去,接收方TCP收到PSH=1,就会尽快交付给接收端进程,而不会再等整个缓存填满后再交付。
9)复位 RST (ReSeT) :当 RST=1 时,表明 TCP 连接中出现严重差错(如由于主机崩溃或其他原因),必须释放连接,然后再重新建立运输连接RST置1可以用来拒绝一个非法的报文段或者拒绝打开一个连接。
10)同步SYN:在建立连接时用来同步序号,当SYN=1&&ACK=0,表示这是一个请求连接的报文段,若对方同意建立连接,则在响应报文段中使得SYN=1&&ACK=1。故SYN=1:表示这是一个连接请求和连接接收报文。
11)终止FIN:用来释放一个连接,当FIN=1,表示此报文段发送方的数据发送完毕,并要求释放连接。
12)窗口:我告诉你我的窗口值的目的是要你知道我一次性能接收多大的数据量。
2个字节,从0开始,窗口指的是发送本报文段的这一方的接收窗口(而不是自己的发送窗口),窗口值告诉对方:从本报文段首部的确认号开始算起,接收方目前允许(窗口值是经常动态变化的)对发送方发送的数据量。窗口字段明确指出了现在允许对方发送的数据量。
13)检验和:占 2 字节。检验和字段检验的范围包括首部和数据这两部分。在计算检验和时,要在 TCP 报文段的前面加上 12 字节的伪首部。
14)紧急指针:2个字节,当URG=1,紧急指针才有意义,指出本报文段中的紧急数据的字节数。注意:当窗口值为0,也可以发送紧急数据。
15)选项:最长为40字节,当没有选项时,TCP首部长度为20字节。
16)填充字段:这是为了使整个首部长度是 4 字节的整数倍。
3.4、TCP 可靠传输的实现
1)超时重传:TCP 每发送一个报文段,就对这个报文段设置一次计时器,如果不能及时收到一个确认,将重发这个报文段。这种可靠的传输协议常称为:自动重传请求ARQ(Automatic Repeat reQuest)
2)检验和:利用TCP报文头的校验和检测数据在传输过程中是否变化。如果改变,就丢弃这个报文段让发送端重传。
3)排序:TCP发送方给每一个数据包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。 且TCP的接收端会丢弃重复的数据包。
4)以字节为单位的滑动窗口技术:发送端发送一个数据包之后不需要等到对方应答后在发下一个数据包,只要发送的字节还没超过滑动窗口的大小就可以一直发送。在收到接收端的应答后滑动窗口开始移动。
5)流量控制:当接收端来不及处理发送端的数据,就减小自己的接收窗口,同时发送端也减小自己的发送窗口或者直接调成0,接收端处理完缓存里的数据在调整窗口开始接收数据包。
3.5、TCP 的传输连接管理
传输连接有三个阶段,即:连接建立、数据传送、连接释放。
TCP连接的建立采用:客户服务器方式,主动发起连接建立的应用进程叫客户(client);被动等待连接建立的应用进程叫做服务器(server)。
1)TCP 的连接建立
握手需要在客户和服务器之间交换三个 TCP 报文段。称之为三报文握手。采用三报文握手主要是为了防止已失效的连接请求报文段突然又传送到了,因而产生错误。
假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。
TCP 三次握手跟现实生活中的人与人打电话是很类似的:
三次握手:
“喂,你听得到吗?”
“我听得到呀,你听得到我吗?”
“我能听到你,今天 balabala……”

第一次握手:
建立连接之前客户端要保证服务器已经开始监听,然后客户端选择一个随机的端口开始和服务器进行socket通信。客户端向服务器发送建立连接的请求报文段,首部的同步位SYN=1,初始序号seq=x,进入SYN-SENT(同步以发送状态)。等待服务器确认;
第二次握手:
服务器收到该报文段后,向客户端发送确认,在确认报文段中SYN位和ACK位都置1,确认号ack=x+1,初始序号ack=y,此时服务器进入SYN_RECV状态;
第三次握手:
客户端收到服务器的确认后还要向服务器给一个确认,确认报文段的ACK是1,确认号ack=y+1,自己的序号seq=x+1,客户端进入ESTABLISHED(建立连接)状态,服务器收到客户端的确认后也进入建立连接状态。
注:小写的ack代表的是头部的确认号Acknowledge number, 缩写ack,是对上一个包的序号进行确认的号,ack=seq+1。大写的ACK,则是我们上面说的TCP首部的标志位,用于标志的TCP包是否对上一个包进行了确认操作,如果确认了,则把ACK标志位设置成1。
例如:我访问一个不存在的网址

我作为客户端去访问一个不存在的服务端,当我第一次握手,SYN_SENT之后,一直得不到服务端的响应。
2)TCP 的连接释放
TCP 连接释放过程是四次挥手即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。在socket编程中,这一过程由客户端或服务端任一方执行close来触发。

第一次挥手:
客户端先发送一个连接释放的报文并停止发送数据。该报文段首部的终止控制位FIN=1,序号seq=u(客户端上次传送数据最后一个字节的序号加1)。并进入FIN-WAIT-1(终止等待1)状态。等待服务器的确认。
第二次分手:
服务器收到该报文段后就发出确认,该报文段的确认号ack=u+1, 序号seq=v(服务器上次发送数据最后一个字节的序号加1)。进入了CLOSE=WAIT(关闭等待)状态。
第三次分手:
客户端收到服务器的确认后,就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文。服务器向客户端发送连接释放的报文段,该报文段的终止控制位 FIN=1,重复上次的确认号ack = u + 1,序号 seq = w(半关闭状态服务器可能向客户端发送了一些数据)。进入了LAST-ACK(最后确认)状态,等待客户端的确认。
第四次分手 :
客户端收到连接释放报文段后,给服务器一个确认结束的报文段,该报文段确认号ack = w + 1,序号 seq = u + 1。此时客户端就进入TIME-WAIT(时间等待)状态,服务器进入CLOSED(关闭)。客户端经过2*MSL(最长报文段寿命)的时间后(4分钟)后也进入关闭。
为什么关闭的时候是四次握手?
由于TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议,TCP是全双工模式。
这就意味着,关闭连接时,当Client端发出FIN报文段时,只是表示Client端告诉Server端数据已经发送完毕了。当Server端收到FIN报文并返回ACK报文段,表示它已经知道Client端没有数据发送了,但是Server端还是可以发送数据到Client端的,所以Server很可能并不会立即关闭SOCKET,直到Server端把数据也发送完毕。当Server端也发送了FIN报文段时,这个时候就表示Server端也没有数据要发送了,就会告诉Client端,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
为什么要等待2MSL?
有以下两个原因:
1)第一点:保证TCP协议的全双工连接能够可靠关闭:由于IP协议的不可靠性或者是其它网络原因,导致了Server端没有收到Client端的ACK报文,那么Server端就会在超时之后重新发送FIN,如果此时Client端的连接已经关闭处于CLOESD状态,那么重发的FIN就找不到对应的连接了,从而导致连接错乱,所以,Client端发送完最后的ACK不能直接进入CLOSED状态,而要保持TIME_WAIT,当再次收到FIN的收,能够保证对方收到ACK,最后正确关闭连接。
2)第二点:保证这次连接的重复数据段从网络中消失:如果Client端发送最后的ACK直接进入CLOSED状态,然后又再向Server端发起一个新连接,这时不能保证新连接的与刚关闭的连接的端口号是不同的,也就是新连接和老连接的端口号可能一样了,那么就可能出现问题:如果前一次的连接某些数据滞留在网络中,这些延迟数据在建立新连接后到达Client端,由于新老连接的端口号和IP都一样,TCP协议就认为延迟数据是属于新连接的,新连接就会接收到脏数据,这样就会导致数据包混乱。所以TCP连接需要在TIME_WAIT状态等待2倍MSL,才能保证本次连接的所有数据在网络中消失。
7、应用层
前面我们讲完了传输层,接下来我们在来看看应用层。在应用层中,定义了很多面向应用的协议,在操作系统术语中,进行通信的实际上是进程而不是程序。应用层的具体内容就是规定应用进程在通信时所遵循的协议。这些应用进程之间相互通信和协作通常采用一定的模式,常见的有客户/服务器模型和P2P模型。

在应用层有很多的协议,其中常见的协议有:

1、网络应用模型
1.1、客户/服务器模型(C/S 模型)

客户/服务器模型所描述的是进程之间的服务和被服务的关系。服务可以是任意的应用,如文件传输服务、电子邮件服务等。在这个模型中,客户是服务的请求方,服务器是服务的提供方。例如,主机A向主机B发出服务请求,主机A是客户机;而主机B向主机A提供服务,主机B是服务器。
在客户机上运行的软件通常是被用户(如操作计算机的人)调用后运行,在打算通信时主动向服务器发起通信。因此,客户程序必须知道服务器程序的地址。
客户/服务器模型主要特点如下∶
1)网络中各计算机的地位不平等,服务器可以通过对用户权限的限制来达到管理客户机的目的,使它们不能随意存储数据,更不能随意删除数据,或进行其他受限的网络活动。
2)整个网络的管理工作由少数服务器承担,所以网络的管理非常集中和方便。这一优势在大规模网络中更加明显。
3)可扩展性不佳。由于受服务器硬件和网络带宽的限制,服务器所能支持的客户数比较有限,当客户数增长较快时,会急剧影响网络应用系统的效率。
1.2、P2P模型

P2P模型指两个主机在通信时并不区分哪一个是服务请求方还是服务提供方。只要两个主机都运行了P2P软件,它们就可以进行平等的对等连接通信,比如双方都可以下载对方已经存储在硬盘中的共享文档(而在客户/服务器模型下,只有当客户机主动发起请求时,才能从服务器获得文档,或将文档传递给服务器,而且多个客户机之间如果想要共享文件,只能通过服务器中转)。例如,大家现在常用的QQLive和电驴等软件就是使用P2P模型。
P2P模型带来的好处是,任何一台主机都可以成为服务器,改变了原来需要专用服务器的模式,很显然,多个客户机之间可以直接共享文档。此外,可以借助P2P网络模型,解决专用服务器的性能瓶颈问题(如播放流媒体时对服务器的压力过大,而通过P2P模型,可以利用大量的客户机来提供服务)。
P2P 模型主要特点如下∶
1)繁重的计算机任务可以被分配到各个节点上,利用每个节点空闲的计算能力和存储空间,聚合实现强大的服务。
2)系统可扩展性好。传统的服务器有连接带宽的限制,只能达到一定的客户端连接数。但是在P2P模型中,能避免这个问题。
3)网络更加健壮,不存在中心节点失效的问题。当一部分节点连接失败之后,其余的节点仍然能形成完整的网络。
2、域名系统 DNS
2.1、DNS系统的概念
我们访问网站,其实都是通过IP来访问的,但是成千上万的网站都需要记忆其服务器的IP,那实在太难了。人们为了便于记忆,于是就出现了域名。(如:www.baidu.com)
域名系统(英文:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
从概念上可以将DNS分为3个部分∶层次域名空间、域名服务器、解析器。
2.2、层次域名空间
因特网采用了层次树状结构的命名方法。任何一个连接在因特网上的主机或路由器都有一个唯一的层次结构的名字,即域名(Domain Name)。域还可以被划分为子域,而子域还可被划分为子域的子域,这样就引入了顶级域名、二级域名、三级域名等。每个域名都由标号序列组成(各标号分别代表不同级别的域名),各标号之间用点隔开。例如:

顶级域名(Top Level Domain,TLD)主要分为以下三大类∶
1)国家顶级域名(nTLD),如.cn表示中国、.us表示美国、.k表示英国等。
2)通用顶级域名(gTLD):
| 顶级域名 | 域名 |
| .com | 表示商业机构,任何人都可以注册.COM 形式的域名。 |
| .net | 表示网络服务机构 |
| .org | 表示非营利性组织 |
| .gov | 表示政府机构 |
| .edu | 表示教育机构 |
| .mil | 表示军事机构 |
| .int | 表示国际机构 |
3)基础结构域名(Infrastructure Domain),这种顶级域名只有一个,即 arpa,用于反向域名解析,因此又称为反向域名。
2.3、域名服务器
因特网的域名系统(DNS)被设计成一个联机分布式的数据库系统,并采用客户/服务器模型。名字到域名的解析是由若干个域名服务器来完成的,域名服务器程序在专设的节点上运行,运行该程序的机器称为域名服务器。
一个服务器所负责管辖的(或有权限的)范围称为区(Zone)。全球有13个根域名服务器名称:a.root-servers.net. - m.root-servers.net.。目前世界上的大中型网站都是采用CDN做内容分发的,从而可以确保用户就近的接入、提升访问速度,不少的网站会使用DNS作为识别,因此如果本人在北京,却选择了上海的DNS,就有可能会被网站认为是上海的用户而引导到上海的服务器上去。
目前国内有不少的免费、安全而且无毒的DNS,常见的如:
百度提供的DNS:180.76.76.76
阿里提供的DNS:223.5.5.5和223.6.6.6
国内移动、电信和联通通用的DNS:114.114.114.114
当然还有国外的,例如:8.8.8.8是谷歌公司提供的DNS。
例如:使用114.114.114.114DNS服务器来解析百度的域名

2.4、域名解析过程
主机向本地域名服务器的查询都是采用递归查询。
如果主机所询问的本地域名服务器不知道被查询域名的IP地址,那么本地域名服务器就以DNS 客户的身份向其他域名服务器继续发出查询请求报文。
本地域名服务器向根域名服务器的查询通常采用迭代查询,当然也可以采用递归查询。
1)迭代查询
当根域名服务器收到本地域名服务器的迭代查询请求报文时,要么给出所要查询的IP地址,要么告诉本地域名服务器"下一步应当向哪一个域名服务器进行查询",然后让本地域名服务器进行后续的查询。

2)递归查询
递归查询是指本地域名服务器只需向根域名服务器查询一次,后面的几次查询都是在其他几个域名服务器之间进行的。

3、动态主机配置协议DHCP
DHCP(Dynamic Host Configuration Protocol),动态主机配置协议,是一个应用层协议。当我们将客户主机ip地址设置为动态获取方式时,DHCP服务器就会根据DHCP协议给客户端分配IP,使得客户机能够利用这个IP上网。

假如,我们在学校,当上不同的课,要在不同的教室上课,而且每天,每个班的人 又多,老师要一个一个的分配静态地址,很麻烦。如果大家都自动获取,则DHCP服务器统一管理,自动分配,这样就简单多了。
3.1、DHCP工作原理
1)发现阶段
DHCP客户端寻找DHCP服务端的过程,对应于客户端发送DHCP Discovery,因为DHCP Server对应于DHCP客户端是未知的,所以DHCP 客户端发出的DHCP Discovery报文是广播包,源地址为0.0.0.0目的地址为255.255.255.255。网络上的所有支持TCP/IP的主机都会收到该DHCP Discovery报文,但是只有DHCP Server会响应该报文。
2)DHCP Server 提供阶段
DHCP Server收到DHCP Discovery报文后,解析该报文请求IP地址所属的网段。并从dhcpd.conf文件中与之匹配的网段中取出一个可用的IP地址,设置在DHCP Discovery报文中yiaddress字段中,表示为该客户端分配的IP地址,并且为该Lease设置该网段配置的Option,例如默认leases租期,***租期,router等信息。
DHCP从地址池中选择IP地址,以如下优先级进行选择:
当前已经存在的Ip Mac的对应关系、Client以前的IP地址、Discovery报文中的Requested Ip Address Option的值、从配置的网段中选择IP地址

3)DHCP Client 选择阶段
DHCP Client收到若干个DHCP Server响应的DHCP Offer报文后,选择其中一个DHCP Server作为目标DHCP Server。然后以广播方式回答一个DHCP Request报文,该报文中包含向目标DHCP请求的IP地址等信息。之所以是以广播方式发出的,是为了通知其他DHCP Server自己将选择该DHCP Server所提供的IP地址。
4)DHCP Server确认阶段
当DHCP Server收到DHCP Client发送的DHCP Request后,确认要为该DHCP Client提供的IP地址后,便想该DHCP Client响应一个包含该IP地址以及其他Option的报文,来告诉DHCP Client可以使用该IP地址了。 然后DHCP Client即可以将该IP地址与网卡绑定。另外其他DHCP Server都将收回自己之前为DHCP Client提供的IP地址。
5)DHCP Client重新登录网络
当DHCP Client重新登录后,发送一个以包含之前DHCP Server分配的IP地址信息的DHCP Request报文,当DHCP Server收到该请求后,会尝试让DHCP客户端继续使用该IP地址。并回答一个ACK报文。但是如果该IP地址无法再次分配给该DHCP Client后,DHCP回复一个NAK报文,当DHCP Client收到该NAK报文后,会重新发送DHCP Discovery报文来重新获取IP地址。
6)DHCP Client更新租约
DHCP获取到的IP地址都有一个租约,租约过期后,DHCP Server将回收该IP地址,所以如果DHCP Client如果想继续使用该IP地址,则必须更新器租约。更新的方式就是,当当前租约期限过了一半后,DHCP Client都会发送DHCP Renew报文来续约租期。
4、FTP协议
4.1、什么是FTP协议
FTP的中文名称是“文件传输协议”,是File Transfer Protocol三个英文单词的缩写。FTP协议是TCP/IP协议组中的协议之一,其传输效率非常高,在网络上传输大的文件时,经常采用该协议。
一个完整的FTP由FTP服务器和FTP客户端组成,客户端可以将服务器上的文件通过FTP协议下载到本地,也可以将本地数据通过FTP协议上传到服务器上。
服务器端需要安装FTP服务软件,常用的有:FileZilla Server、IIS、OSSFTP等等。
FTP客户端软件就比较多了,常用的有FileZilla、FlashFXP、WinSCP、甚至在浏览器和windows资源管理器中输入FTP地址都可以当做FTP客户端来使用。
4.2、控制连接与数据连接
在进行文件传输时,FTP的客户机和服务器之间要建立两个TCP连接,一个用于传输控制命令和响应,称为控制连接;另一个用于实际的文件内容传输,称为数据连接。

左侧为客户端,右侧为FTP服务器,无论是上传还是下载,客户端与服务器之间都会建立2个TCP连接会话,绿色是控制连接,红色的是数据连接。其中,控制连接用于传输FTP命令,如:删除文件、重命名文件、下载文件、列取目录、获取文件信息等。真正的数据传输时通过数据连接来完成的。
默认情况下,服务器21端口作为命令端口,20端口为数据端口。但被动模式下就有所差别了。
4.3、FTP主动模式
首先,来了解下FTP的主动模式,主动模式是FTP的默认模式,也称为PORT模式。
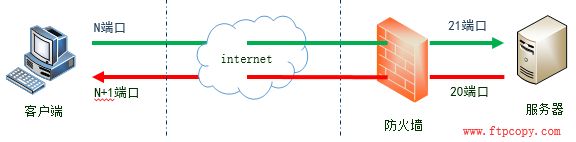
在主动模式下,客户端会开启N和N+n两个端口,N为客户端的命令端口,N+n为客户端的数据端口。
第一步,客户端使用端口N连接FTP服务器的命令端口21,建立控制连接并告诉服务器我这边开启了数据端口N+n。
第二步,在控制连接建立成功后,服务器会使用数据端口20,主动连接客户端的N+1端口以建立数据连接。这就是FTP主动模式的连接过程。
我们可以看到,在这条红色的数据连接建立的过程中,服务器是主动连接客户端的,所以称这种模式为主动模式。(这里的主动被动其实是相对于FTP服务器而言的)

每传一个文件,都会建立一个控制连接和一个数据连接。上面这张图是通过netstat命令查看到的ftp主动模式下TCP的连接信息,首先客户端使用49195端口连接服务器21端口建立控制连接,然后服务器使用20端口连接客户端49197端口建立数据连接。
主动模式有什么利弊呢?
主动模式对FTP服务器的管理有利,因为FTP服务器只需要开启21端口的“准入”和20端口的“准出”即可。但这种模式对客户端的管理不利,因为FTP服务器20端口连接客户端的数据端口时,有可能被客户端的防火墙拦截掉。
4.4、FTP被动模式
上面所讲的是FTP主动模式,简单的理解就是服务器的数据端口20主动连接客户端的数据端口,来建立数据连接,用来传输数据,这个数据连接的建立有可能被客户端防火墙拦截掉。为了解决这个问题就衍生出另外一种连接模式---被动模式。被动模式也称为passive模式。

第一步,客户端的命令端口N主动连接服务器命令端口21,并发送PASV命令,告诉服务器用“被动模式”,控制连接建立成功后,服务器开启一个数据端口P,通过PORT命令将P端口告诉客户端。
第二步,客户端的数据端口N+n去连接服务器的数据端口P,建立数据连接。
我们可以看到,在这条红色的数据连接建立的过程中,服务器是被动的等待客户端来连接的,所以称这种模式为被动模式。

上面这张图是通过netstat命令查看到的“被动模式”下的TCP连接情况,首先客户端49222端口去连接服务器的21端口,建立控制连接。然后客户端的49224端口连接服务器的6008端口去建立数据连接。 (服务器的数据端口P是随机的,这个客户端连接过来用的是6008端口,另外一个连接过来可能用的就是7009,不过P端口的范围是可以设置的)
被动模式有什么利弊呢?
被动模式对FTP客户端的管理有利,因为客户端的命令端口和数据端口都是“准出”,windows防火墙对于“准出”一般是不拦截的,所以客户端不需要任何多余的配置就可以连接FTP服务器了。但对服务器端的管理不利。因为客户端数据端口连到FTP服务器的数据端口P时,很有可能被服务器端的防火墙阻塞掉。(例如,FTP服务器只开了20和21端口)
5、Telnet协议简介
Telnet(teletype network)协议是TCP/IP协议族中的一员。是Internet远程登录服务的标准协议和主要方式之一,它通常在服务器端使用公认端口号23,在客户端使用动态端口号,它允许用户(Telnet 客户端)通过一个协商过程来与一个远程设备进行通信。
telnet是一个Server/Clicet模型的协议,所以需要在Server端开启Telnet服务,才能让Cilent使用telnet协议连接到Server上。
telnet的主要缺点在于通信传输过程中都是明文传输的,不安全,所以出于安全方面的考虑,需要用到远程登录服务的时候,我们通常使用SSH(Secure Shell)来实现。
telnet命令还可做别的用途,比如确定远程服务的状态,比如确定远程服务器的某个端口是否能访问。
6、RDP协议(远程桌面)
远程桌面协议(RDP)指的是用于远程使用桌面计算机的协议或技术标准。远程桌面软件可以使用几种不同的协议,如 RDP、独立计算架构(ICA)和虚拟网络计算(VNC)等,但 RDP 是最常用的协议。RDP 最初由微软公司发布,可用于大多数 Windows 操作系统,但 Mac 操作系统也提供相应的支持。
远程桌面采用的是一种类似TELNET的技术,他是从TELNET协议发展而来的。通俗的讲他就是图形化的TELNET。
RDP 协议开启一个专用的网络通道,用于在连接的两台计算机(远程桌面和当前使用的计算机)之间来回发送数据。为此,它始终使用网络端口 3389。鼠标移动、击键、桌面显示和所有其他必要的数据利用 TCP/IP 并通过此通道发送,这是用于大多数种类的 Internet 流量的传输协议。RDP 也会加密所有数据,提升通过公共互联网连接的安全性。
我们可以在控制面板-系统-高级系统设置-远程中开启远程桌面桌面服务。

开启之后,我们使用netstat -an就可以看到3389端口已经开启了:
![]()
然后我们就能在客户端使用远程桌面服务登陆。
7、WWW万维网
WWW(World Wide Web,万维网)简称为3W,它并非某种特殊的计算机网络。万维网是一个大规模的、联机式的信息储藏所。它的特点在于用链接的方法能非常方便地从因特网上的一个站点访问另一个站点,从而主动地按需获取丰富的信息。WWW还提供各类搜索引擎,使用户能够方便地查找信息。
WWW把各种信息按照页面的形式组合,一个页面包含的信息可以有文本、图形、图像、声音、动画、链接等各种格式,这样一个页面也称为超媒体(如果页面中只有文字和链接,则称为超文本,注意区分),而页面的链接均称为超链接。
WWW使用统一资源定位符(URL)来标志WWW上的各种文档。URL的一般格式为:
<协议>∶//<主机>∶<端口号>/<路径>
其中常见的协议有HTTP、FTP等。主机部分是存储该文档的计算机,可以是域名也可以是IP地址,端口号是服务器监听的端口(根据协议可以知道端口号,一般省略),路径一般也可省略,并且在 URL中的字符对大写或小写没有要求。
万维网以客户/服务器方式工作。浏览器是在用户计算机上的万维网客户程序,而万维网文档所驻留的计算机则运行服务器程序,这个计算机称为万维网服务器。客户程序向服务器程序发出请求,服务器程序向客户程序送回客户所要的文档。完整的工作流程如下∶
1)Web用户使用浏览器(指定URL)与Web服务器建立连接,并发送浏览请求。
2)Web服务器把URL转换为文件路径,并返回信息给 Web浏览器。
3)通信完成,关闭连接。
7.1、HTTP协议
超文本传送协议(HTTP)是在客户程序(如浏览器)与WWW服务器程序之间进行交互所使用的协议。HTTP是面向事务的应用层协议,它使用TCP连接进行可靠传输,服务器默认监听在80端口。
从协议执行的过程来说,当浏览器要访问WWW服务器时,首先要完成对WWW 服务器的域名解析。一旦获得了服务器的IP地址,浏览器将通过TCP向服务器发送连接建立请求。
每个服务器上都有一个服务进程,它不断地监听TCP的端口80,当监听到连接请求后便与浏览器建立连接。TCP连接建立后,浏览器就向服务器发送要求获取某一Web页面的HTTP 请求。服务器收到HTTP请求后,将构建所请求的Web页的必需信息,并通过HTTP响应返回给浏览器。浏览器再将信息进行解释,然后将Web页显示给用户。最后,TCP连接释放。
其主要特点:
1)简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2)灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3)无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4)无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5)支持B/S及C/S模式。
7.2、HTTP之URL
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。
http://www.abc.com:8080/news/index?boardID=5&ID=24618&page=1#name
1)协议部分(http:):这代表网页使用的是HTTP协议,在"HTTP"后面的“//”为分隔符;
2)域名部分(www.abc.com):一个URL中,也可以直接使用IP地址;
3)端口部分(8080):域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口。
4)虚拟目录部分(/news/):从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。
5)文件名部分(index):从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分。
6)参数部分(boardID=5&ID=24618&page=1):从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。
7)锚部分(name):从“#”开始到最后,都是锚部分。
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
HTTP的报文结构有两类报文:请求报文、响应报文
7.3、HTTP请求报文

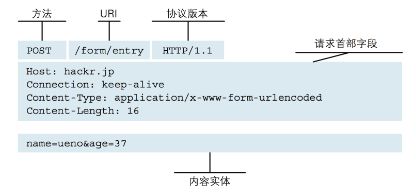
7.4、HTTP响应报文


7.5、HTTP请求方法
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
| 请求方法 | 解释 |
| GET | 请求指定的页面信息,并返回实体主体。 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
7.6、HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型:
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
部分状态码如下:
| 状态码 | 定义 |
| 100 | 继续 |
| 101 | 切换协议 |
| 200 | OK |
| 201 | 创建 |
| 205 | 重置内容 |
| 300 | 多重选项 |
| 307 | 临时重定向 |
| 400 | 坏的请求 |
| 404 | 未找到 |
| 408 | 请求超时 |
| 500 | 服务器错误 |
| 503 | 服务不可用 |
| 504 | 网关超时 |
| 505 | HTTP版本不支持 |
8、电子邮件
电子邮件由信封和内容两部分组成。一般只规定了邮件内容中的首部格式,而邮件的主体部分由用户自由撰写。用户写好首部后,邮件系统自动将信封所需的信息提取出来并写在信封上。
邮件内容首部包含一些关键字,后面加上冒号,如"To∶"是收信人的邮件地址,"Subject∶"是邮件的主题等。
补充知识点∶电子邮件地址的格式。TCP/IP体系的电子邮件系统规定电子邮件地址的格式∶收件人邮箱名@邮箱所在主机的域名,符号"@"读作"at",表示"在"的意思。
8.1、SMTP与POP3
SMTP:
SMTP所规定的就是在两个相互通信的SMTP进程之间应如何交换信息。
SMTP运行在TCP基础之上,使用25号端口,也使用客户/服务器模型。
SMTP规定了14条命令和21种应答信息。
SMTP通信的3个阶段如下∶
1)连接建立。连接是在发送主机的SMTP客户和接收主机的SMTP服务器之间建立的。SMTP不使用中间的邮件服务器。
2)邮件传送。
3)连接释放。邮件发送完毕后,SMTP应释放TCP连接。
POP3:
POP是一个非常简单,但功能有限的邮件读取协议。现在使用的是它的第三个版本POP3。
POP也使用客户/服务器的工作方式。在接收邮件的用户计算机中必须运行 POP客户程序,而在用户所连接的ISP的邮件服务器中运行 POP服务器程序。
POP3的一个特点是只要用户从POP服务器读取了邮件,POP服务器就将该邮件删除。