python KNN分类算法 使用鸢尾花数据集实战
KNN分类算法,又叫K近邻算法,它概念极其简单,但效果又很优秀。
如觉得有帮助请点赞关注收藏啦~~~
KNN算法的核心是,如果一个样本在特征空间中的K个最相似,即特征空间中最邻近的样本中的大多数属于某一个类别,则该样本也属于这个类别
1:K值
K值也就是选择几个相邻的作为测量
2:距离的度量
距离决定了哪些是邻居哪些不是,度量距离有很多种方法,常用的是欧式距离
1:查看数据 使用鸢尾花数据集 由sklearn模块导入

from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib; matplotlib.use('TkAgg')
import pandas as pd
print("数据集的keys",iris_dataset.keys())
print("特征名",iris_dataset['feature_names'])
print("数据类型",type(iris_dataset['data']))
print("数据维度",iris_dataset['data'].shape)
print("标记名",iris_dataset['target_names'])
2:使用散点矩阵查看数据特征关系
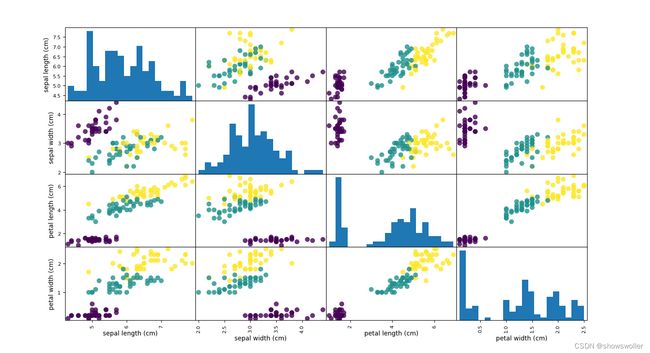
代码如下 绘图并且划分数据集与训练集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib; matplotlib.use('TkAgg')
import pandas as pd
iris_dataset=load_iris()
train_x,test_x,train_y,test_y=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=2)
print('trainx\n',train_x)
print('trainy\n',train_y)
print('testx\n',test_x)
print('testy\n',test_y)
print(test_x.shape)
print(test_x.shape)
irisdataframe=pd.DataFrame(train_x,columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(irisdataframe,c=train_y,figsize=(15,15),marker='o',hist_kwds={'bins':20},s=60,alpha=0.8)
plt.show()3:建立KNN模型进行预测
python中实现KNN方法使用的是KNeighborsClassifier类
核心操作分三步
3.1:创建KNeighborsClassifier对象 并进行初始化
3.2:调用fit()方法 对数据集进行训练
fit(x,y)以x为训练集 y为测试及对模型进行训练
3.3:调用predict函数进行预测

源代码如下
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib; matplotlib.use('TkAgg')
import pandas as pd
iris_dataset=load_iris()
iris=datasets.load_iris()
print("数据集结构",iris.data.shape)
iris_x=iris.data
iris_y=iris.target
iris_train_x,iris_test_x,iris_train_y,iris_test_y=train_test_split(iris_x,iris_y,test_size=0.2,random_state=0)
knn=KNeighborsClassifier()
knn.fit(iris_train_x,iris_train_y)
predictresult=knn.predict(iris_test_x)
print("测试集大小",iris_test_x.shape)
print("真实结果",iris_test_y)
print("预测结果",predictresult)
print("预测精确率",knn.score(iris_test_x,iris_test_y))