FixMatch: 通过一致性和置信度简化半监督学习
- 原论文:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- 作者单位:Google Research
- 出版:arXiv 2001.07685
- code:https://github.com/google-research/fixmatch
摘要
半监督学习(SSL)提供了一种有效方法,可以利用未标记的数据来提高模型的性能。在本文中,作者演示了两种常见SSL方法的简单组合的力量:一致性正则化和伪标记。算法 FixMatch 首先使用模型对弱增强的未标记图像的预测生成伪标签。对于给定图像,仅当模型产生高置信度预测时才保留伪标签。然后,该模型被训练来预测当输入同一图像的强增强版本时的伪标签。尽管它很简单,但实验显示 FixMatch 在各种标准的半监督学习基准测试中都达到了最先进的性能,包括在250个标签的CIFAR-10上的准确度为94.93%,在40个标签上的准确度为88.61%,每个标签仅4个标签类。由于FixMatch与实现较差性能的现有SSL方法有许多相似之处,因此作者进行了广泛的消融研究,以找出对FixMatch成功至关重要的实验因素。我们通过以下网址提供了代码:https://github.com/google-research/fixmatch。
1.介绍
深度神经网络(Deep neural network)已成为计算机视觉应用的实际模型。它们的成功部分归因于其明显的可扩展性,即,根据经验观察,在较大的数据集上对其进行训练会产生更好的性能[25,17,35,46,34,18]。深度网络通常通过有监督的学习来实现其强大的性能,这需要一个标记的数据集。由于标注数据通常需要人工,因此使用较大的数据集所带来的性能优势可能会付出巨大的代价。极限情况下,标记如果通过专家实现,成本可能非常高,例如医学领域中的医生。
半监督学习(semi-supervised learning SSL)是一种在不需要大量标签的情况下训练大量数据模型的强大方法。SSL 通过提供一种利用未标记数据的方法来减轻对标记数据的需求。由于通常可以用最少的人力来获得未标记的数据,因此SSL所带来的任何性能提升通常都是低成本的。这导致了大量的,专为深度网络而设计的SSL方法的发展。
一类流行的SSL方法可以粗略地看做是为每个未标记图像生成一个人工标签,然后训练模型以在输入未标记图像作为输入时预测该人工标签。例如,伪标签(pseudo-labeling)[22](也称为自训练[27、46、37、40])使用模型的类别预测作为要进行训练的标签。同样,一致性正则化(consistency regularization)[39,21]在随机修改输入或模型函数后,使用模型的预测分布获得了人工标记。
在这项工作中,作者继续结合最新技术方法的趋势,这些方法结合了用于生产人工标签的各种机制[3,45,2,28]。作者引入 FixMatch,它使用一致性正则化和伪标签生成人工标签。至关重要的是,基于弱增强的未标记图像(例如,仅使用翻转和移位数据增强)生成人工标签,当模型被输入同一图像的强增强版本时,该人工标记将用作目标。受UDA [45]和ReMixMatch [2]的启发,作者利用CutOut [13],CTAugment [2]和RandAugment [10]进行强增强,它们都会产生给定图像严重失真的版本。遵循伪标签方法[22],如果模型将高概率分配给可能的类别之一,则仅保留人工标签。FixMatch的示意图如图1所示。
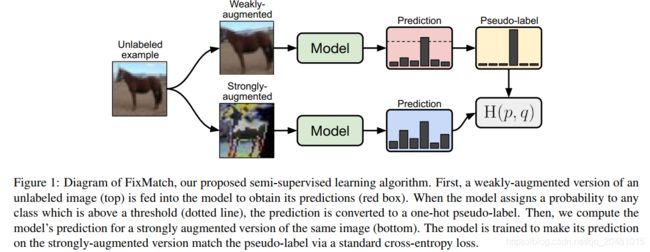
图1:半监督学习算法FixMatch的示意图。首先,将未标记图像的弱增强版本(顶部)输入模型中以获得其预测(红色框)。当模型为高于阈值(虚线)的任何类别分配概率时,预测将转换为单伪标记。然后,我们针对同一张图片的增强版本(底部)计算模型的预测。训练该模型,使其通过标准的交叉熵损失,使其在强增强版本上的预测与伪标记匹配。
虽然FixMatch包含现有技术的简单组合,但我们证明它在最常研究的SSL基准测试上获得了最先进的性能。例如,FixMatch在CIFAR-10上实现了94:93%的准确率,有250个带标记的示例,而在[31]的标准实验设置中,以前的水平是93:73%的[2]。我们还通过将其应用于极为罕见的elabels机制来探索我们的方法的局限性,在每个类只有4个标签的情况下,CIFAR-10的准确率为88:61%。由于FixMatch类似于现有的方法,但取得了更好的性能,我们包括一个广泛的消融研究,以确定哪些因素对其成功贡献最大。我们的消融研究还包括在提出新的SSL方法(如优化器或学习速率计划)时经常被忽略或未被报告的基本实验选择。因为我们发现它们会对性能产生巨大的影响。
在下一节中,我们将介绍FixMatch及其基于的思想。在第3节中,我们将讨论FixMatch如何与现有的SSL算法相关。第4节和第5节分别介绍了我们的实验结果和消融研究。最后,对第六部分进行了总结,并对未来的工作进行了展望。
2.FixMatch
总的来说,FixMatch算法是两种常见的SSL方法的简单组合:一致性正则化和伪标记。它的主要新奇之处在于这两种成分的组合,以及在执行一致性正则化时使用单独的弱增强和强增强。在本节中,在详细描述FixMatch算法之前,我们首先回顾一致性正则化和伪标记。我们还描述了其他因素,如正则化,这有助于FixMatch的经验成功。
对于一个 类的分类问题
类的分类问题![]() ,这儿,
,这儿, 是BatchSIze,
是BatchSIze,![]() 是训练样本,
是训练样本,![]() 是one-hot编码。使用
是one-hot编码。使用![]() 表示一个Batch的未标记样本,这儿
表示一个Batch的未标记样本,这儿 表示
表示 和
和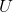 的相对大小。
的相对大小。![]() 表示模型对输入
表示模型对输入 预测的类别分布。两个类别
预测的类别分布。两个类别 和
和 的交叉熵为
的交叉熵为![]() 。作为FixMatch的一部分,我们执行两种类型的增强:强增强
。作为FixMatch的一部分,我们执行两种类型的增强:强增强![]() 和弱增强
和弱增强![]() 。
。
2.1 Background
一致性正则化是当前许多最先进的SSL算法的重要组成部分。一致性正则化利用未标记的数据,基于这样的假设,即当输入受到扰动的图像时,模型应该输出相似的预测。这个想法最早在[39,21]中被提出,模型通过标准监督分类损失和以下损失函数对未标记数据进行训练。
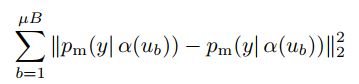
注意 和
和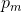 是随机函数,所以方程(1)中的两项有不同的值。扩展这个想法包括使用一个对抗转换代替,对的一次调用使用运行平均值或过去的模型预测等[43, 21],使用一个交叉熵损失替换
是随机函数,所以方程(1)中的两项有不同的值。扩展这个想法包括使用一个对抗转换代替,对的一次调用使用运行平均值或过去的模型预测等[43, 21],使用一个交叉熵损失替换![]() 损失,使用更强的增强形式[45, 2],并在更大的SSL管道中使用一致性正则化组件
损失,使用更强的增强形式[45, 2],并在更大的SSL管道中使用一致性正则化组件
伪标记利用了这样一种思想,即我们应该使用模型本身来为未标记的数据获取人工标记。这个想法是几十年前提出的[27,40]。伪标签特别指使用“硬”标签(即只保留人工标签,其最大类概率落在预定义的阈值[22]之上。假设![]() ,伪标记对未标记数据使用以下损失函数:
,伪标记对未标记数据使用以下损失函数:
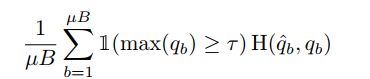
这儿,![]() ,
,![]() 是阈值超参数。注意,为简单起见,我们假设应用于概率分布的arg max生成一个有效的“onehot”概率分布。硬标签的使用使得伪标签与熵最小化密切相关[16, 38],其中模型的预测被鼓励为低熵(即未标记的数据
是阈值超参数。注意,为简单起见,我们假设应用于概率分布的arg max生成一个有效的“onehot”概率分布。硬标签的使用使得伪标签与熵最小化密切相关[16, 38],其中模型的预测被鼓励为低熵(即未标记的数据
2.2 Our Algorithm: FixMatch
FixMatch的损失函数由两个交叉熵损失项组成:一个监督损失项![]() ,一个无监督损失项
,一个无监督损失项![]() ,其中,
,其中,![]() 只是在弱增强标注的样本上的标准的交叉熵损失:
只是在弱增强标注的样本上的标准的交叉熵损失:
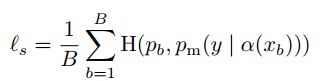
对于未标记的数据,FixMatch为每个样本计算一个人造标注,然后在交叉熵损失中使用。为了获得一个人早标注,我们首先对给定给定未标记图像的一个弱增强的图像,计算模型的预测类分布:![]() ,然后,我们使用
,然后,我们使用![]() ,作为伪标记,对
,作为伪标记,对![]() 的强增强数据,我们对模型的输出施加交叉熵损失。
的强增强数据,我们对模型的输出施加交叉熵损失。

这儿,![]() 是一个标量超参数,表示我们保留伪标签的阈值。总之,FixMatch最小化的损失就是
是一个标量超参数,表示我们保留伪标签的阈值。总之,FixMatch最小化的损失就是![]() ,其中
,其中![]() 是一个固定的标量超参数,表示未标记损失的相对权重。在补充材料的算法1中,我们提出了一个完整的FixMatch算法。
是一个固定的标量超参数,表示未标记损失的相对权重。在补充材料的算法1中,我们提出了一个完整的FixMatch算法。

注意,eq.(4)类似于eq.(2)中的伪标记损失,关键的区别在于,人工标记是基于弱增广图像计算的,而强增广图像的损失是针对模型输出的。这引入了一种形式的一致性正则化,正如我们将在第5节中展示的,这对FixMatch的成功至关重要。我们还要注意,在现代SSL算法中,训练期间,增加提高无标记损失项的权重(λu)是典型的作法。
2.3 Augmentation in FixMatch
FixMatch利用两种增强:“弱”和“强”。在我们所有的实验中,弱增强是标准的翻转-移位增强策略。具体来说,我们在水平方向上随机翻转图像,除了SVHN外,在所有数据集上的概率为50%,我们在垂直和水平方向上随机转换图像的概率最高为12.5%。
对于“强”增强:,我们尝试了两种基于自增强:的方法[9]。AutoAugment使用强化学习从Python图像库2学习基于转换的增强策略。这需要有标签的数据来学习扩充管道,这使得在有限的标签数据可用的SSL设置中使用有问题。因此,人们提出了自动增强:的变体,它不需要使用标记数据提前学习增强:策略。我们实验了两个这样的变体:Rand-Augment[10]和CT-Augment[2]。请注意,除非另有说明,否则我们使用Cutout[13]后跟其中一种策略。
给定一组变换(例如颜色反转、平移、对比度调整等),Rand-Augment随机选择小批量中每个样本的变换。正如最初提出的那样,Rand-Augment使用一个固定的全局幅度来控制所有失真的严重性[10]。幅度是一个超参数,必须在验证集上进行优化,例如,使用网格搜索。我们发现,在每一个训练步骤中从预先定义的范围中抽取一个随机量值(而不是使用固定的全局值)对于半监督训练效果更好,这与UDA中使用的方法类似[45].
CTAugment[2]没有随机设置转换量,而是在训练过程中在线学习。为此,将大范围的变换幅度值分成若干个bins(如AutoAugment[9]中所述),并为每个bin分配一个权重(最初设置为1)。所有的例子都用一条由两个变换组成的管道来扩充,这两个变换是随机均匀采样的。对于给定的变换,根据(规范化的)bin权重以概率随机地对一个震级bin进行采样。为了更新震级箱的权值,在一个有标签的例子中增加了两个变换,一个量级的bin随机均匀采样。然后,根据模型的预测与真实标签的接近程度,更新大小bin权重。关于CTAugment的更多细节,请参见[2]。
实验略。