资金流入流出预测实践
一、数据探索与分析
首先来看看seaborn这个库的用法,因为我们在作分析的时候,会频繁的使用这个库。
Seaborn是一种基于matplotlib的图形可视化python libraty。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。掌握seaborn能很大程度帮助我们更高效的观察数据与图表,并且更加深入了解它们。

安装seaborn
pip install seaborn
# anaconda 环境中
conda install seaborn
boxplot :箱型图又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。它能显示出一组数据的最大值、最小值、中位数及上下四分位数。因形状如箱子而得名。在各种领域也经常被使用,常见于品质管理。图解如下:
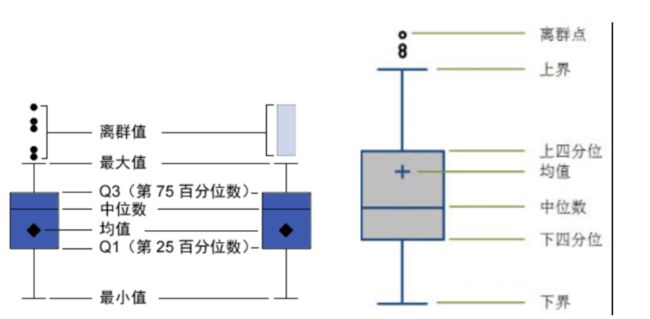
先来介绍下箱型图的一些统计学的意义:
- IQR = Q3-Q1,即上四分位数与下四分位数之间的差,也就是盒子的长度。
- 最小观测值为min = Q1 - 1.5*IQR,如果存在离群点小于最小观测值,则胡须下限为最小观测值,离群点单独以点汇出。如果没有比最小观测值小的数,则胡须下限为最小值。
- 最大观测值为max = Q3 +1.5*IQR,如果存在离群点大于最大观测值,则胡须上限为最大观测值,离群点单独以点汇出。如果没有比最大观测值大的数,则胡须上限为最大值。
接下来我们介绍Seaborn中的箱型图的具体实现方法,这是boxplot的API:
seaborn.``boxplot(x=None,y=None,hue=None, data=None, order=None, hue_order=None, orient=None,color=None,palette=None, saturation=0.75,width=0.8,dodge=True,fliersize=5, linewidth=None,whis=1.5,ax=None, kwargs)
-
x,y:dataframe中的列名(str)或者矢量数据
-
data:dataframe或者数组
-
**palette:**调色板,控制图像的色调
-
plt.subplot(1, 2, 1) sns.boxplot(x="catagory",y="pw",data=data) #左图 plt.subplot(1, 2, 2) sns.boxplot(x="catagory",y="pw",data=data,palette="Set3") #右图 # 这边使用的是鸢尾花数据集,category代表的是分类,pw则是其中的一个特征。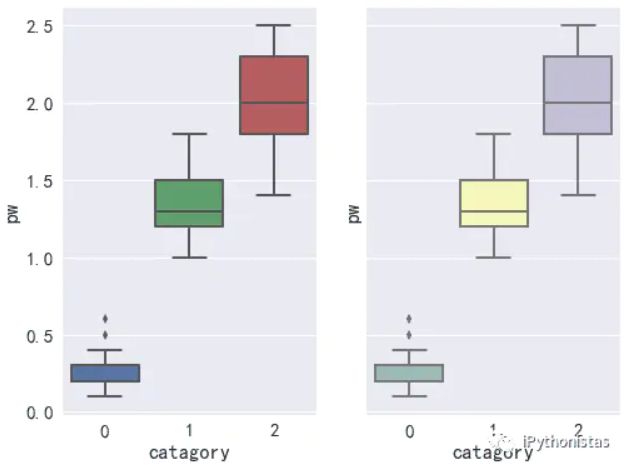
-
order, hue_order (lists of strings):用于控制条形图的顺序
sns.boxplot(x="catagory",y="pw",data=data,palette="Set3",order=[2,1,0])
-
orient:“v”|“h” 用于控制图像使水平还是竖直显示(这通常是从输入变量的dtype推断出来的,此参数一般当不传入x、y,只传入data的时候使用)
plt.subplot(1,2,1) sns.boxplot(data=data,orient="v",palette="Set3") #竖直显示 plt.subolot(1,2,2) sns.boxplot(data=data,orient="h",palette="Set3") #水平显示
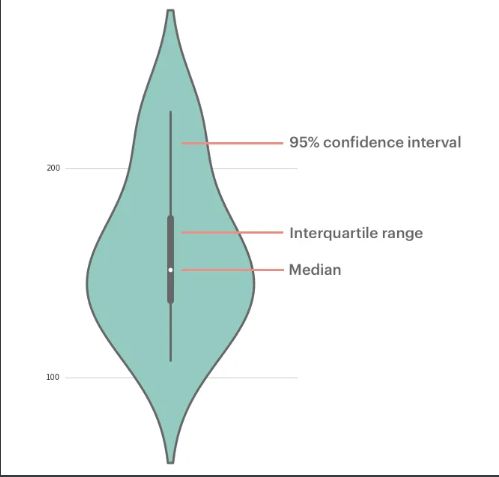
violinplot 小提琴图,violinplot与boxplot扮演类似的角色,它显示了定量数据在一个(或多个)分类变量的多个层次上的分布,这些分布可以进行比较。不像箱形图中所有绘图组件都对应于实际数据点,小提琴绘图以基础分布的核密度估计为特征。具体用法如下:
seaborn.``violinplot(x=None, y=None , hue=None , data=None , order=None , hue_order=None , bw=‘scott’ , cut=2 , scale=‘area’ , scale_hue=True , gridsize=100 , width=0.8 , inner=‘box’ , split=False , dodge=True , orient=None , linewidth=None , color=None , palette=None , saturation=0.75 , ax=None , kwargs)
- bw:‘scott’, ‘silverman’, float,控制拟合程度。在计算内核带宽时,可以引用规则的名称(‘scott’, ‘silverman’)或者使用比例(float)。实际内核大小将通过将比例乘以每个bin内数据的标准差来确定;
- cut:空值外壳的延伸超过极值点的密度,float;
- scale:“area”, “count”, “width”,用来缩放每把小提琴的宽度的方法;
- scale_hue:当使用hue分类后,设置为True时,此参数确定是否在主分组变量进行缩放;
- gridsize:设置小提琴图的平滑度,越高越平滑;
- inner:“box”, “quartile”, “point”, “stick”, None,小提琴内部数据点的表示。分别表示:箱子,四分位,点,数据线和不表示;
- split:是否拆分,当设置为True时,绘制经hue分类的每个级别画出一半的小提琴;
barplot 条形图
条形图因为平时见得比较多,也很容易理解,这边就不细说了,直接看看api文档:
seaborn.``barplot(* x=None , y=None , hue=None , data=None , order=None , hue_order=None , estimator=
heatmap 热力图。将数据绘制为颜色方格(编码矩阵)
seaborn.``heatmap**(data , vmin=None , vmax=None , cmap=None , center=None , robust=False , annot=None , fmt=’.2g’ , annot_kws=None , linewidths=0 , linecolor=‘white’ , cbar=True , cbar_kws=None , cbar_ax=None , square=False , xticklabels=‘auto’ , yticklabels=‘auto’ , mask=None , ax=None , kwargs)
- data : 要显示的数据
- vmin, vmax : 显示的数据值的最大和最小的范围
- cmap : matplotlib颜色表名称或对象,或颜色列表,可选从数据值到色彩空间的映射。如果没有提供,默认设置
- center : 指定色彩的中心值
- linewidths : 划分每个单元格的线的宽度。
- linecolor : 划分每个单元格的线的颜色。
kdeplot(核密度估计图)
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。具体用法如下:
seaborn.``kdeplot**(data , data2=None , shade=False , vertical=False , kernel=‘gau’ , bw=‘scott’ , gridsize=100 , cut=3 , clip=None , legend=True , cumulative=False , shade_lowest=True , cbar=False , cbar_ax=None , cbar_kws=None , ax=None , kwargs)
绘制简单的一维kde图像
x=np.random.randn(100) #随机生成100个符合正态分布的数sns.kdeplot(x)

-
cut:参数表示绘制的时候,切除带宽往数轴极限数值的多少(默认为3)
sns.kdeplot(x,cut=0)
-
cumulative :是否绘制累积分布
sns.kdeplot(x,cumulative=True)
-
shade:若为True,则在kde曲线下面的区域中进行阴影处理,color控制曲线及阴影的颜色
sns.kdeplot(x,shade=True,color="g")
-
vertical:表示以X轴进行绘制还是以Y轴进行绘制
sns.kdeplot(x,vertical=True)
displot
displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。具体用法如下:
seaborn.``distplot(a , bins=None , hist=True , kde=True , rug=False , fit=None , hist_kws=None , kde_kws=None , rug_kws=None , fit_kws=None , color=None , vertical=False , norm_hist=False , axlabel=None , label=None , ax=None)
先介绍一下直方图(Histograms):
直方图又称质量分布图,它是表示资料变化情况的一种主要工具。用直方图可以解析出资料的规则性,比较直观地看出产品质量特性的分布状态,对于资料分布状况一目了然,便于判断其总体质量分布情况。直方图表示通过沿数据范围形成分箱,然后绘制条以显示落入每个分箱的观测次数的数据分布。
sns.distplot(x,color="g") # 数据还是上面的数据
通过hist和kde参数调节是否显示直方图及核密度估计(默认hist,kde均为True)
import matplotlib.pyplot as plt
plt.subplot(1,3,1)
sns.distplot(x) #左图
plt.subplot(1,3,2)
sns.distplot(x,hist=False) #中图
plt.subplot(1,3,3)
sns.distplot(x,kde=False) #右图

bins:int或list,控制直方图的划分
plt.subplot(1,2,1)
sns.distplot(x,kde=False,bins=20) #左图:分成20个区间
plt.subplot(1,2,2)
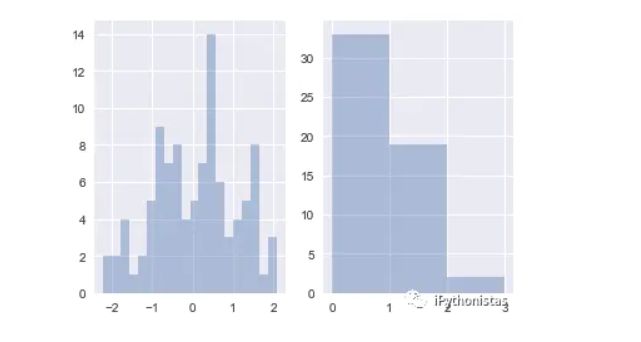
sns.distplot(x,kde=False,bins=[x for x in range(4)]) #右图:以0,1,2,3为分割点,形成区间[0,1],[1,2],[2,3],区间外的值不计入。
rag:控制是否生成观测数值的小细条
plt.subplot(1,2,1)
sns.distplot(x,rug=True) #左图
plt.subplot(1,2,2)
sns.distplot(x) #右图

fit:控制拟合的参数分布图形,能够直观地评估它与观察数据的对应关系(黑色线条为确定的分布)
from scipy.stats import *
sns.distplot(x,hist=False,fit=norm) #拟合标准正态分布

norm_hist:若为True, 则直方图高度显示密度而非计数(含有kde图像中默认为True)
plt.subplot(1,2,1)
sns.distplot(x,norm_hist=True,kde=False) #左图
plt.subplot(1,2,2)
sns.distplot(x,kde=False) #右图

参考博客:
https://www.jianshu.com/p/96977b9869ac
https://www.cnblogs.com/tsingke/p/6565605.html
https://www.jianshu.com/p/844f66d00ac1