基于PP-OCR训练表格识别模型
参考:百度官网
一. 配置PP-OCR环境
pp-ocr环境配置教程
二. 训练数据准备
数据下载地址
或者用命令下载数据
curl -o ./PubTabNet.tar.gz https://dax-cdn.cdn.appdomain.cloud/dax-pubtabnet/2.0.0/pubtabnet.tar.gz
下载数据后解压,并用代码将其划分为训练集和验证集,代码如下:
import jsonlines
"""
把PubTabNet_2.0.0.jsonl分成PubTabNet_2.0.0_train.jsonl和PubTabNet_2.0.0_val.jsonl两个文件
test文件夹中的图片没有标注信息
"""
if __name__ == "__main__":
with jsonlines.open("PubTabNet_2.0.0.jsonl", "r") as f:
with jsonlines.open("PubTabNet_2.0.0_train.jsonl", "w") as train_f:
for data in f:
if data['split'] == "train":
train_f.write(data)
with jsonlines.open("PubTabNet_2.0.0.jsonl", "r") as f:
with jsonlines.open("PubTabNet_2.0.0_val.jsonl", "w") as val_f:
for data in f:
if data['split'] == "val":
val_f.write(data)
三. 训练模型
# 单机单卡训练
python3 tools/train.py -c configs/table/table_mv3.yml
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/table/table_mv3.yml
如果要用到预训练模型,则用如下命令:
CUDA_VISIBLE_DEVICES=5 nohup python3 tools/train.py -c configs/table/table_mv3.yml -o Global.checkpoints="./output/table_mv3/best_accuracy"
我的table_mv3.yml内容如下:
Global:
use_gpu: true
epoch_num: 400
log_smooth_window: 20
print_batch_step: 5
save_model_dir: ./output/table_mv3/
save_epoch_step: 3
# evaluation is run every 400 iterations after the 0th iteration
eval_batch_step: [0, 400]
cal_metric_during_train: True
pretrained_model:
checkpoints:
save_inference_dir:
use_visualdl: False
infer_img: doc/table/table.jpg
# for data or label process
character_dict_path: ppocr/utils/dict/table_structure_dict.txt
character_type: en
max_text_length: 100
max_elem_length: 800
max_cell_num: 500
infer_mode: False
process_total_num: 0
process_cut_num: 0
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
clip_norm: 5.0
lr:
learning_rate: 0.001
regularizer:
name: 'L2'
factor: 0.00000
Architecture:
model_type: table
algorithm: TableAttn
Backbone:
name: MobileNetV3
scale: 1.0
model_name: large
Head:
name: TableAttentionHead
hidden_size: 256
l2_decay: 0.00001
loc_type: 2
max_text_length: 100
max_elem_length: 800
max_cell_num: 500
Loss:
name: TableAttentionLoss
structure_weight: 100.0
loc_weight: 10000.0
PostProcess:
name: TableLabelDecode
Metric:
name: TableMetric
main_indicator: acc
Train:
dataset:
name: PubTabDataSet
data_dir: /home/work/data/guopei/pubtabnet/train/
label_file_path: /home/work/data/guopei/pubtabnet/PubTabNet_2.0.0_train.jsonl
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- ResizeTableImage:
max_len: 488
- TableLabelEncode:
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- PaddingTableImage:
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'structure', 'bbox_list', 'sp_tokens', 'bbox_list_mask']
loader:
shuffle: True
batch_size_per_card: 48
drop_last: True
num_workers: 16
Eval:
dataset:
name: PubTabDataSet
data_dir: /home/work/data/guopei/pubtabnet/val/
label_file_path: /home/work/data/guopei/pubtabnet/PubTabNet_2.0.0_val.jsonl
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- ResizeTableImage:
max_len: 488
- TableLabelEncode:
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- PaddingTableImage:
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'structure', 'bbox_list', 'sp_tokens', 'bbox_list_mask']
loader:
shuffle: False
drop_last: False
batch_size_per_card: 16
num_workers: 8
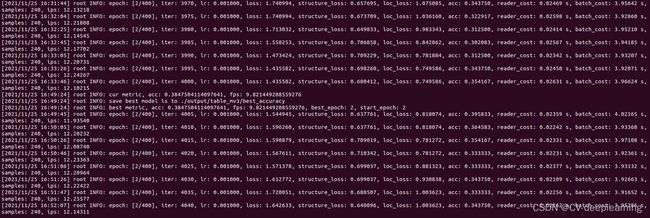
通过上述步骤,你的表格识别模型就训练起来了,如下图所示:
四. 将训练的模型转化为推理模型
CUDA_VISIBLE_DEVICES=6 python tools/export_model.py -c configs/table/table_mv3.yml -o Global.pretrained_model=/home/work/guopei/workspace/OCR/table_recog/paddle/PaddleOCR/output/table_mv3/best_accuracy Global.load_static_weights=False Global.save_inference_dir=./table_infer
该命令会把output/table_mv3/best_accuracy.pdparams 转换成推理模型并存在./table_infer文件夹下。如下图所示:

五. 测试训练好的表格识别模型
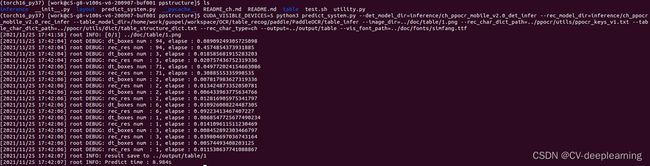
CUDA_VISIBLE_DEVICES=5 python3 predict_system.py --det_model_dir=inference/ch_ppocr_mobile_v2.0_det_infer --rec_model_dir=inference/ch_ppocr_mobile_v2.0_rec_infer --table_model_dir=/home/work/guopei/workspace/OCR/table_recog/paddle/PaddleOCR/table_infer --image_dir=../doc/table/1.png --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --rec_char_type=ch --output=../output/table --vis_font_path=../doc/fonts/simfang.ttf
测试结果如下:
六. 测试表格结构识别的测试指标
首先,根据官网,获得gt.json,我选了pubtabnet验证集中的500张表格测试。
生成gt.json的代码如下:
import jsonlines
import json
import os
def data_process(data):
data_new = {}
img_name = data["filename"]
img_path = os.path.join("/home/work/data/guopei/pubtabnet/val", img_name)
html = data['html']["structure"]['tokens']
html = ["", "", ""] + html + ["
", "", ""]
tokens = []
bboxes = []
for cell in data['html']["cells"]:
if len(cell['tokens']) == 0 or "bbox" not in cell.keys():
continue
tokens.append(cell['tokens'])
bboxes.append(cell['bbox'])
label = [html, bboxes, tokens]
return img_path, label
if __name__ == "__main__":
datas = {}
idx = 0
with jsonlines.open("PubTabNet_2.0.0_val.jsonl", "r") as f:
for data in f:
idx += 1
if idx > 500:
break
img_path, label = data_process(data)
datas[img_path] = label
json.dump(datas, open("test.json", "w"), indent=2, ensure_ascii=False)
测试命令如下:
CUDA_VISIBLE_DEVICES=2 python3 table/eval_table.py --det_model_dir=inference/ch_ppocr_mobile_v2.0_det_infer --rec_model_dir=inference/ch_ppocr_mobile_v2.0_rec_infer --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer --image_dir='' --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --rec_char_type=ch --det_limit_side_len=736 --det_limit_type=min --gt_path=/home/work/data/guopei/pubtabnet/test.json
我稍微修改了一下代码,测试的结果是表格结构的teds,测试结构如下:
![]()
我们的表格识别技术解决方案
每天进步一点,欢迎技术交流!!!
