基于隐马科夫模型,HMM用于中文分词
HMM用于中文分词
一、在分词、分句前用规则处理句子
#在分词前用规则处理句子
def preprocess(oriSentence):
#删除后缀
oriSentence = deleteTMword(oriSentence,'\r')
oriSentence = deleteTMword(oriSentence,'\n')
oriSentence = deleteTMword(oriSentence,'\t')
#load the rules
#加载规则
deletes = Rule.Rules["DELETE"]
updates = Rule.Rules["CHANGE"].keys()
#we must delete the whitespaces.
#对于空格进行删除
deletes.append(' ')
deletes.append(' ')
sentence = ''
for char in oriSentence:
#对于词组进行删除操作
if(char in deletes):
sentence += ''
#对词组进行替换操作
elif(char in updates):
sentence += Rule.Rules["CHANGE"][char]
#不进行操作
else:
sentence += char
return sentence
二、获取文本中所有的句子
##将一个段落切割成几个最简单的句子
def segmentSentence(text,isForSegmentWord=False):
#载入需要进行切割的符号
lst = [',','!','?','…',',','。','!','?','"','“','”','\'','‘','’',':',':',';',';','—','(',')','(',')']
#是否需要进一步切分
if(isForSegmentWord):
#these punctuations shouldn't cut the sentence.
#这些标点不应该删减句子。
lst += ['、','《','》','<','>']
#这里是对于输出格式的处理
assert isinstance(text, str)
text_seg = ""
for char in text:
text_seg += char in lst and '|' or char
sentence_lst = text_seg.split('|')
while('' in sentence_lst):
sentence_lst.remove('')
return sentence_lst
三、获取文本中所有的词组
(1)解析离线统计词典文本文件,将词和词频提取出来,获取每个单词所有的前缀词,如果某前缀词不在前缀词典中,则将对应词频设置为0。
#将Dict中的每个单词切成作为前缀,基于前缀词典,对输入文本进行切分,便于之后构造无环图
def generatePrefixDict():
global Possibility,PrefixDict,total,Dictionary_URL
fo = Lexicon.loadDict(Dictionary_URL)
PrefixDict = set()
FREQ = {}
for line in fo.read().rstrip().split("\n"):
word,freq = line.split(' ')[:2]
FREQ[word] = float(freq)
total += float(freq) #calculate the total number of words
for idx in range(len(word)): #generate the prefix dictionary
prefix = word[0:idx+1]
PrefixDict.add(prefix)
fo.close()
#将频率转化为可能性
Possibility = dict((key,log(value/total)) for key,value in FREQ.items())
(2)构造有向无环图,对于每一种划分,都将相应的位置相连:
从前往后依次遍历文本的每个位置,对于位置k,首先形成一个片段,这个片段只包含位置k的字,然后就判断该片段是否在前缀词典中,如果这个片段在前缀词典中,
1.如果词频大于0,就将这个位置i追加到以k为key的一个列表中;
2.如果词频等于0,则表明前缀词典存在这个前缀,但是统计词典并没有这个词,继续循环;
如果这个片段不在前缀词典中,则表明这个片段已经超出统计词典中该词的范围,则终止循环;然后该位置加1,然后就形成一个新的片段,该片段在文本的索引为[k:i+1],继续判断这个片段是否在前缀词典中。
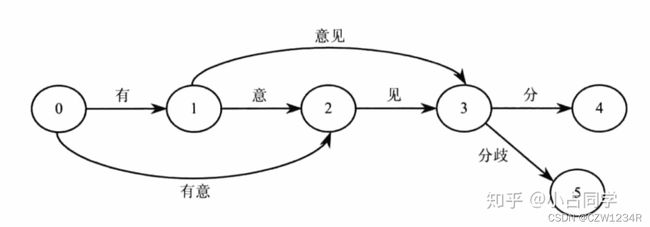
#对于每一种划分,都将相应的位置相连,构造有向无环图
def getDAG(sentence:str):
global PrefixDict,Possibility
DAG = {}
N = len(sentence)
for i in range(N):
lst_pos = []
#这个列表是保存那些可以用第i个字符组成单词的字符的索引。
j = i
word = sentence[i]
lst_pos.append(i)
while(j
if(word in Possibility):
if(lst_pos[0]!=j):
lst_pos.append(j)
j+=1
word = sentence[i:j+1]
#把这个第i个列表放入DAG[i]
DAG[i]=lst_pos
return DAG
(3)函数根据已经构建好的有向无环图计算最大概率路径,动态规划查找最大概率路径,计算每个开始字符的最可能路线,找出基于词频的最大切分组合
#动态规划查找最大概率路径,计算每个开始字符的最可能路线,找出基于词频的最大切分组合
def calculateRoute(DAG:dict,route:dict,sentence:str):
#from right to left
global Possibility , min_Possibility
N = len(sentence)
route[N]=(0.0,'')
#In fact, it is a recurse procedure.
for i in range(N-1,-1,-1):
max_psblty = None
max_cur = i
for j in DAG[i]:
#to consider every possible word
word = sentence[i:j+1]
posb1 = Possibility.get(word,min_Possibility)
posb2 = route[j+1][0]
posb = posb1 + posb2
if max_psblty is None:
max_psblty = posb
if(posb>=max_psblty):
max_psblty = posb
max_cur = j
route[i] = (max_psblty,max_cur)
(4)对于不在词典中的词,使用HMM的方法,对这些词进行标注
__init__.py 实现了HMM模型识别未登录词;
prob_start.py 存储了已经训练好的HMM模型的状态初始概率表;
prob_trans.py 存储了已经训练好的HMM模型的状态转移概率表;
prob_emit.py 存储了已经训练好的HMM模型的状态发射概率表;
1)获取无法识别单词的索引,作为标志来分割句子
#删去不认识的句子,这句话可以用eng和chs处理
def cutUnrecognized(sentence):
#first we need to find all indexes of abnormal char
#首先我们需要找到异常单词的所有索引
eng_dgt_start,eng_dgt_end = findEngAndDigits(sentence)
cur = 0
N = len(eng_dgt_start)
L = len(sentence)
words = []
#And then we need to ues them as the flag to segment the sentence
#然后我们需要将它们作为标志来分割句子
if(N!=0):
for t in range(N):
begin = eng_dgt_start[t]
end = eng_dgt_end[t]
if(t==0 and begin!=0):
buf = sentence[0:begin]
words += cutWithHMM(buf)
if(t!=N-1):
next_start = eng_dgt_start[t+1]
buf = sentence[begin:end+1]
words.append(buf)
buf = sentence[end+1:next_start]
words += cutWithHMM(buf)
else:
buf = sentence[begin:end+1]
words.append(buf)
if(end!=L-1):
buf = sentence[end+1:L]
words += cutWithHMM(buf)
else:
words += cutWithHMM(sentence)
return words
2)调用viterbi算法,求出输入句子的隐藏状态,然后基于隐藏状态进行分词。
def cutWithHMM(sentence):
#possess the english and digits
#find their indexes
init_P()
words = []
#Viterbi是隐马尔科夫模型中用于确定(搜索)已知观察序列在HMM;下最可能的隐藏序列
#通过viterbi算法求出隐藏状态序列
prob,path = viterbi(sentence)
buf = "" # temporary variable
#基于隐藏状态序列进行分词
for i in range(len(sentence)):
flag = path[i]
if(flag=='S'):
buf = sentence[i]
words.append(buf)
buf=""
elif(flag=='B'):
buf = sentence[i]
elif(flag=='M'):
buf = buf + sentence[i]
elif(flag=='E'):
buf = buf+sentence[i]
words.append(buf)
buf=""
return words
3)viterbi算法的实现
MIN_FLOAT = -3.14e100
#states
States = ('B','M','E','S')
#every possible previous of each state
PrevStatus = {
'B':('E','S'),
'M':('M','B'),
'S':('S','E'),
'E':('B','M')
}
def viterbi(obs):
V = [{}]
path={}
#possess the first char
for s in States:
#this state's possibility is the start * emit
V[0][s] = start_P[s] + emit_P[s].get(obs[0],MIN_FLOAT)
#record this path
path[s] = [s]
#poseess the other chars
for i in range(1,len(obs)):
char = obs[i]
V.append({})
newPath = {}
#check every state it can be
for s in States:
#assume that in this case and calculate what the possibility is
emit = emit_P[s].get(char, MIN_FLOAT) #emit it
prob_max = MIN_FLOAT
state_max = PrevStatus[s][0]
for preState in PrevStatus[s]:
#calculate the previous state
prob = V[i-1][preState] + trans_P[preState][s] + emit
if(prob>prob_max):
prob_max = prob
state_max = preState
V[i][s] = prob_max
newPath[s] = path[state_max] + [s]
path = newPath
finalProb = MIN_FLOAT
finalState = ""
for fs in ('E','S'):
p = V[len(obs)-1][fs]
if(p>finalProb):
finalProb = p
finalState = fs
return (finalProb,path[finalState])
#judge if the char is a digit or a english char or a punctuation
def isDigitOrEng(char):
return char in string.ascii_letters or char in string.digits or char in string.punctuation
#this is to find the indexes of non-Chinese chars of this sentence
def findEngAndDigits(sentence):
ind_start = []
ind_end = []
for i in range(len(sentence)):
if(i==0 and isDigitOrEng(sentence[i])):
ind_start.append(i)
if(not isDigitOrEng(sentence[i+1])):
ind_end.append(i)
elif(i==len(sentence)-1 and isDigitOrEng(sentence[i])):
ind_end.append(i)
if(not isDigitOrEng(sentence[i-1])):
ind_start.append(i)
else:
if(isDigitOrEng(sentence[i]) and (not isDigitOrEng(sentence[i-1]))):
ind_start.append(i)
if(isDigitOrEng(sentence[i]) and (not isDigitOrEng(sentence[i+1]))):
ind_end.append(i)
return ind_start,ind_end
(5)对于词组进行切分的主函数
#对于词组进行切分
def segmentWord(oriSentence,useRules=True):
#用规则进行处理
sentence = preprocess(oriSentence)
if(not isInitialized):
initialize()
#构造无向图
DAG = getDAG(sentence)
route = {}
#动态规划查找最大概率路径,计算每个开始字符的最可能路线
calculateRoute(DAG,route,sentence)
words = []
cur = 0
buf = ""
N = len(sentence)
#cur is the current curse of state
#cur 是当前状态的几率
while(cur
word = sentence[cur:next_cur+1]
#如果单词只是一个字符,那么它可能是未登录的单词
#buf 是临时部分。
if(len(word)==1):
buf+=word
else:
#until we have next word which is not single.
if(len(buf)!=0):
#we have buf
#if this word is in dictionary, usually not
#or if it is a single word
if(buf in Possibility or len(buf)==1):
words.append(buf)
else:
#if not , it is an un-login word.
#we must use HMM to cut them
#if not ,它是一个未登录词。
#我们必须使用 HMM 来切割它们,采用的HMM模型了,中文词汇按照BEMS四个状态来标记.
#在这个函数中,就是使用HMM的方法,对这些未识别成功的词进行标注
words += HMM.cutUnrecognized(buf)
#clear the buf
buf=""
words.append(word)
cur = next_cur+1
if(buf):
words += HMM.cutUnrecognized(buf)
return words