【jieba分词】中文分词工具jieba
本文介绍了中文分词原理以及分词工具jieba,最后利用它进行词性标注以及关键词提取
首先,我们要理解为什么要中文分词?
因为我们要通过词量化文本,让计算机能够理解文本。
那么,什么是中文分词呢?
中文分词就是在中文句子中的词与词之间加上边界标记。
文章目录
1.中文分词原理
1.1语言模型
1.2机械切分
1.3机械切分结合模型
2.使用jieba分词
2.1切分模式
2.2词典管理
3.词性标注和关键词提取
3.1使用jieba进行词性标注
3.2关键词提取
1.中文分词原理
1.1语言模型
在统计语言模型中,自然语言看作一个随机过程,其中每一个语言单位包括字、词、句子、段落和篇章等都看作有一定概率分布的的随机变量。判断一个句子是否合理,就看它的概率大小如何。
假定S表示一个句子,由词![]() 组成,n是句子长度。句子概率
组成,n是句子长度。句子概率![]() 可以表示为:
可以表示为:![]() 。句子的概率被表示成n个词的联合概率。在有n个变量的情况下,有
。句子的概率被表示成n个词的联合概率。在有n个变量的情况下,有![]()
![]()
因为语料有限,分子分母难以统计,算出来概率不准确;且条件里的词较多,需要计算的数量指数增长,文件会非常大。所以,马尔科夫提出假设:假设任意一个词 ;出现的频率只同它前面的词
;出现的频率只同它前面的词![]() 有关。于是,
有关。于是,![]() 可以被写为:
可以被写为:![]()
![]() (这就是二元语言模型(Bigram Model))
(这就是二元语言模型(Bigram Model))
那么,如果所有的词之间相互独立,就产生一元语言模型(Unigram Model) :![]()
同理,假设一个词由前面的N-1个词决定,就产生N元语言模型(N-gram Model)
1.2机械切分
机械切分,又称词库切分,是一种比较经典的分词方法,背后的原理就是语言模型。
机械切分整体思路是: 1.基于词库构建词图;
2.基于语料,统计每条边的条件概率;
3.计算所有可能路径的概率,得到概率最高的那条路径(即切分结果)
机械切分的优点:
1.基于词库,相对于序列标注模型,速度非常快 2.通过调整词频,快速解决badcase
3.支持导入领域词库,让分词器快速适配新的领域;
机械切分的缺点:
1.太依赖词库,词库里没有的新词无法切分
2.决定切分时,基本只考虑了上一个切分的影响
1.3机械切分结合模型
使用基于序列标注的模型(序列标注模型输出的是一个标签序列)进行分词效果较好,在遇到词库里面没有的词时有很不错的识别能力;但是相对于纯词库切分,速度相对较慢,而且浪费资源。
实践中常用机械切分结合模型的方法。jieba的结合策略是:将机械切分结果中的连续单个字,使用序列标注模型进行切分。
比如“结合成分子”这句话由机械切分得到结合/成/分/子,因为词库没有分子这个词,所以连续的单字 成 /分 /子被送入序列标注模型,在模型训练的好的情况下,可以返回正确的切分,把它切分为分子。最后我们可以得到“结合成分子”。
2.使用jieba分词
2.1切分模式
普通切分和纯词库切分对比
#导入库
print(list(jieba.cut('他来到了网易杭研大厦')))# 普通切分,结果转换为list
print(list(jieba.cut('他来到了网易杭研大厦')))
# 纯词库切分
print(list(jieba.cut('他来到了网易杭研大厦', HMM=False)))普通切分结果转换为列表输出,这里杭研是我们的HMM模型切分出的,其余是词库里的词或单字。可以设置HMM=False,来实现纯粹的词库切分,即不使用任何序列标注模型,可以看到杭、研被切分为单字。
全模式切分
设置cut_all=True,来启用全模式切分,把句子中所有的词语都扫描出来
# 全模式切分
print(list(jieba.cut("今天心情很糟糕", cut_all=True)))![]()
搜索引擎模式
可以使用cut_for_search方法,实现搜索引擎需要的多粒度分词,它会将长词再次切分。
# 使用搜索引擎模式
print(list(jieba.cut_for_search('他上个月来到了郑州大学')))可以看到,这句话切分出大粒度长词郑州大学,郑州大学再次被切分为小粒度词郑州/大学,都返回了结果
![]()
2.2词典管理
实践中常常使用机械切分和序列标注模型相结合的方法,机械切分最需要的就是词库。
jieba内置了通用词库,这些词是基于通用的语料统计出来的,但是在面对一个全新的领域时,比如金融领域,由于领域有一些专业术语,词库没有,可能导致分词效果不理想。所以我们可以添加自定义词典来提升分词效果。
比如,切分一个金融语料
# 切分金融语料
raw_cut_words = jieba.cut('白天A股抱团股跌,晚上比特币也闪崩,美股开盘后,外国的抱团科技股也崩了!')
print(' '.join(raw_cut_words))从切分结果来看,金融专业术语比特币和抱团股都没有被切分正确
 自定义添加专业新词看下
自定义添加专业新词看下
# 添加专业新词到jieba
jieba.add_word('抱团股')
jieba.add_word('比特币')
cut_words = jieba.cut('白天A股抱团股跌,晚上比特币也闪崩,美股开盘后,外国的抱团科技股也崩了!')
print(' '.join(cut_words))看到切分结果,专业术语抱团股和比特币都被切分出来
![]()
词典的初始化导入
实践中应用于某一领域时,拥有一个词典来初始化分词器能够达到更好的分词效果
我们需要将词库整理成jieba需要的标准格式
<词> <词频> <词性>(比如抱团股 50 n),(词频和词性可以忽略),然后保存为文件;
没有导入自定义词典时
# 打印原始分词结果
cut_words = jieba.cut('张三是创新办的负责人,擅于云计算方面的研究')
print(' '.join(cut_words))可以看到人名和专业名词都没有被切分出来
![]()
加载用户自定义词典再次打印切分结果
jieba.load_userdict('data/user_dict.txt')
cut_words = jieba.cut('张三是创新办的负责人,擅于云计算方面的研究')
print(' '.join(cut_words)) 可以看到人名和专业名词都被正确切分
使用jieba提供的接口动态调整词典和直接加载词典都可以提高分词准确率
两者的应用场景:
- 如果你现在已经有一个大的词典文件了,你应该使用
load_userdict进行初始化词典;- 如果你拿到的词是源源不断、动态变化的,你应该使用
add_word(添加词)、del_word(删除词)接口;
3.词性标注和关键词提取
3.1使用jieba进行词性标注
词性标注具体实现:
- 对原始文本进行机械切分,获得一个词序列;
- 根据词库中给出的词性,为每个词赋上相应的词性;
- 如果启用了HMM模型切分,对连续单字进行切分,并同时给出词性;
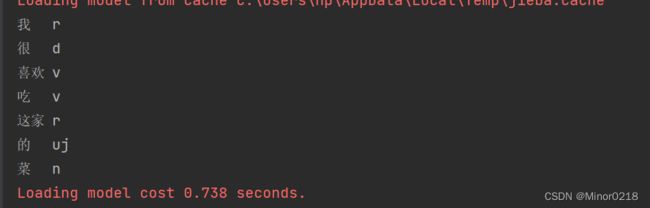
import jieba.posseg as pseg
items = pseg.cut("我很喜欢吃这家的菜")
for word, flag in items:
print('{}\t{}'.format(word, flag))词性标注会在分好词的基础上,针对每个词,给出其对应的词性
3.2关键词提取
关键词提取是NLP领域一个较为常见的任务,它主要是在一段文本中,提取出重要的一些词。传统的关键词提取算法主要是:tf-idf 和 text-rank。
1.tf-idf算法:
如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
# 使用tfidf进行关键词提取
from jieba.analyse import TFIDF
text = "在国家发展改革委7月14日召开的经济吹风会上,国家发展改革委经贸司有关负责人表示,当前我国粮食安全形势较好,有能力、有底气、有条件应对外部冲击,端稳端牢“中国饭碗"""
tfidf = TFIDF()
print(tfidf.extract_tags(text)) # 默认参数提取关键词
# 仅保留名词相关的词性
print(tfidf.extract_tags(text, allowPOS=('n', 'nr', 'ns', 'nt', 'nw', 'nz', 'vn'), withFlag=True))

2.text-rank算法: textrank也是一种常见的关键词提取方法,原理基于pagerank。通过把文本分割成若干单词、句子,然后建立关键候选词图,迭代计算各节点权重,根据权重排序得到关键候选词
# 使用textrank提取关键词
from jieba.analyse import TextRank
text_rank = TextRank()
print(text_rank.extract_tags(text, allowPOS=('n', 'nr', 'ns', 'nt', 'nw', 'nz', 'vn'), withFlag=True))
对比tf-idf 和 text-rank:
- 速度上,由于text-rank在运行过程中,需要不断的迭代计算,所以tfidf提取速度高于text-rank
- 效果上,由于tfidf计算时还考虑到了整个语料库的信息,但textrank计算时仅考虑当前文档,所以tfidf一般要比textrank要好一些。