CLIP openai多模 图形-文字匹配;文字query搜索图片;以图搜图;再训练
参考:https://github.com/openai/CLIP
安装环境
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu -f https://download.pytorch.org/whl/torch_stable.html
pip install ftfy regex tqdm

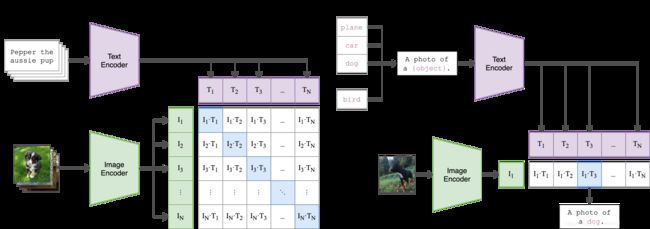
1、输入图片检索是什么内容
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
2、输入文字检索相关图片
图片分布对应;中文暂时转化成英文输入;
import torch
import clip
from PIL import Image
device = "cpu"
# device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image1 = preprocess(Image.open(r"D:\****dmx2m6lfgx.jpg")).unsqueeze(0)
image2 = preprocess(Image.open(r"D:\****hyqla0ug9.jpg")).unsqueeze(0)
image3 = preprocess(Image.open(r"D:\****uo39v1va.jpg")).unsqueeze(0)
text = clip.tokenize(["football"]).to(device)
# text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
image = torch.cat([image1, image2, image3]).to(device)
print(image)
print(text)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
print(logits_per_image, logits_per_text)
probs = logits_per_text.softmax(dim=-1).cpu().numpy()
# probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
# print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]

image_features 值和shape
向量:512大小

文字query搜索图片
参考:
https://github.com/haofanwang/natural-language-joint-query-search
1、把相关图片或文本 encode进行保存
import torch
import clip
from PIL import Image
from tqdm import tqdm
import numpy as np
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
#
# for i in tqdm(range(1000),20):
# print(i)
kkk_all = np.load(r"D:****图\媒资内容1.npy")
aids = [ i[0] for i in kkk_all.tolist()]
device = "cpu"
# device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
aidss=[]
imgs=[]
for i in tqdm(aids):
try:
# print(i)
aidss.append(i)
image1 = preprocess(Image.open(r"D:***图\图\{}.jpg".format(i))).unsqueeze(0)
with torch.no_grad():
image_features = model.encode_image(image1)
imgs.append(image_features.numpy())
print(type(image_features))
# imgs.append(image1)
except Exception as e:
print(e)
print("33333####")
aidss.pop()
pass
np.save(r"D:\***图\aidss.npy", aidss)
np.save(r"D:***图\image_features_embs.npy", imgs)
import torch
import clip
from PIL import Image
from tqdm import tqdm
import numpy as np
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
# 加载数据
kkk_dict_all = np.load(r"D:\t***1.npy", allow_pickle=True).item()
# 加载模型
device = "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 计算缩略图向量
aidss=[]
titles=[]
for i, j in kkk_dict_all.items():
try:
aidss.append(i)
title1 = j[0]
print(title1)
text1 = clip.tokenize([title1]).to(device)
print(text1.shape)
with torch.no_grad():
text_features = model.encode_text(text1)
# text_features /= text_features.norm(dim=-1, keepdim=True)
# print(text_features)
titles.append(text_features)
print(type(text_features))
except Exception as e:
print(e)
print("####")
aidss.pop()
pass
# 保存
np.save(r"D:\t**title_aidss.npy", aidss)
np.save(r"D:\***\title_features_embs.npy", titles)
2、加载测试
import torch
import clip
from PIL import Image
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
image1 = np.load(r"D:\***图\image_features_embs.npy", allow_pickle=True)
aidss = np.load(r"D:\***图\aidss.npy")
print(aidss)
device = "cpu"
# device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
text = clip.tokenize(["football"]).to(device)
print(text)
image = torch.Tensor([(item / item.norm(dim=-1, keepdim=True)).cpu().numpy() for item in image1])
print(image)
print(type(image))
with torch.no_grad():
# image_features = model.encode_image(image)
text_features = model.encode_text(text)
text_features /= text_features.norm(dim=-1, keepdim=True)
# text_features = text_features.cpu().numpy()
# print(text_features)
# print(image_features.shape)
# print(image_features)
# print(text_features.shape)
similarities = (image @ text_features.T).squeeze(1)
print(similarities[:,0])
best_photo_idx = np.argsort(similarities[:, 0].numpy())[::-1]
print(best_photo_idx)
print([aidss[i] for i in best_photo_idx[:10]])
3、flask展示(中文要翻译成英文文字)
##有道翻译
data = {
"i": query,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false"
}
response = requests.post("http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule", data=data).json()
# print(response)
# print(type(response))
bb = response["translateResult"][0][0]["tgt"]
print(bb)
建立一个检索字典,similarities相似值去获取标题和链接
with torch.no_grad():
# image_features = model.encode_image(image)
text_features = model.encode_text(text)
text_features /= text_features.norm(dim=-1, keepdim=True)
# text_features = text_features.cpu().numpy()
# print(text_features)
# print(image_features.shape)
# print(image_features)
# print(text_features.shape)
similarities = (image @ text_features.T).squeeze(1)
print(similarities[:, 0])
best_photo_idx = np.argsort(similarities[:, 0].numpy())[::-1]
print(best_photo_idx)
rank_results = [aidss[i] for i in best_photo_idx[:10]]
titles1 = []
pics1 = []
for j in rank_results:
titles1.append(kkk_dict_all[j][0])
pics1.append(kkk_dict_all[j][1])
print(titles1, pics1)
return render_template('display1.html', query=query, lis1=titles[:10], lis2=pics[:10], lis3=titles1, lis4=pics1)
以图搜图
@app.route('/findmore/', methods=['GET'])
def myinfohtml(username):
print(username)
# image to image
source_image = r"D:***图\{}.jpg".format(username)
with torch.no_grad():
image_feature = model.encode_image(preprocess(Image.open(source_image)).unsqueeze(0).to(device))
image_feature = (image_feature / image_feature.norm(dim=-1, keepdim=True)).cpu().numpy()
best_photo_ids1 = (image @ image_feature.T).squeeze(1)
best_photo_idx2 = np.argsort(best_photo_ids1[:, 0].numpy())[::-1]
rank_results2 = [aidss[i] for i in best_photo_idx2[:30]]
# 召回结果封装
titles3 = []
pics3 = []
for j in rank_results2:
titles3.append(kkk_dict_all[j][0])
pics3.append(kkk_dict_all[j][1])
print(titles3, pics3)
return render_template('display3.html', lis31=titles3, lis32=pics3)
{{ title1 }}

再训练
参考:https://github.com/openai/CLIP/issues/83
数据:

#https://github.com/openai/CLIP/issues/83
from torch.utils.data import Dataset, DataLoader
import torch
import clip
from torch import nn, optim
import pandas as pd
from PIL import Image
BATCH_SIZE = 5
EPOCH = 50
class image_caption_dataset(Dataset):
def __init__(self, df):
self.images = df["image"].tolist()
self.caption = df["caption"].tolist()
print(self.images,self.caption)
def __len__(self):
return len(self.caption)
def __getitem__(self, idx):
images = preprocess(Image.open(self.images[idx]))
caption = self.caption[idx]
return images, caption
df = pd.DataFrame({"image":[r"D:\openai\imgs\gyro warrior.jpg",r"D:\openai\imgs\magic gyro 2.jpg",r"D:\openai\imgs\magic gyro.jpg",r"D:\openai\imgs\most powerful magic gyro.jpg",r"D:\openai\imgs\supervariant battle gyro.jpg"], "caption":["gyro warrior","magic gyro 2","magic gyro","most powerful magic gyro","supervariant battle gyro"]})
print(df)
dataset = image_caption_dataset(df)
train_dataloader = DataLoader(dataset, batch_size=BATCH_SIZE) # Define your own dataloader
# https://github.com/openai/CLIP/issues/57
def convert_models_to_fp32(model):
for p in model.parameters():
p.data = p.data.float()
p.grad.data = p.grad.data.float()
device = "cpu" # If using GPU then use mixed precision training.
model, preprocess = clip.load("ViT-B/32", device=device, jit=False) # Must set jit=False for training
if device == "cpu":
model.float()
else:
clip.model.convert_weights(model)
loss_img = nn.CrossEntropyLoss()
loss_txt = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=5e-5, betas=(0.9, 0.98), eps=1e-6, weight_decay=0.2) # Params from paper
for epoch in range(EPOCH):
for batch in train_dataloader:
list_image, list_txt = batch # list_images is list of image in numpy array(np.uint8), or list of PIL images
# images = torch.stack([preprocess(Image.fromarray(img)) for img in list_image],
# dim=0) # omit the Image.fromarray if the images already in PIL format, change this line to images=list_image if using preprocess inside the dataset class
texts = clip.tokenize(list_txt)
images = list_image
logits_per_image, logits_per_text = model(images, texts)
print(logits_per_image, logits_per_text )
if device == "cpu":
ground_truth = torch.arange(BATCH_SIZE).long().to(device)
else:
ground_truth = torch.arange(BATCH_SIZE).half().to(device)
print("######3", ground_truth)
total_loss = (loss_img(logits_per_image, ground_truth) + loss_txt(logits_per_text, ground_truth)) / 2
optimizer.zero_grad()
total_loss.backward()
if device == "cpu":
optimizer.step()
else:
convert_models_to_fp32(model)
optimizer.step()
clip.model.convert_weights(model)
print('[%d] loss: %.3f' %
(epoch + 1, total_loss))
torch.save(model, r"D:\openai\model1.pkl")
Code to save the model :
torch.save({
'epoch': EPOCH,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': total_loss,
}, f"model_checkpoint/model_10.pt") #just change to your preferred folder/filename
Code to load the saved model :
model, preprocess = clip.load("ViT-B/32",device=device,jit=False) #Must set jit=False for training
checkpoint = torch.load("model_checkpoint/model_10.pt")
# Use these 3 lines if you use default model setting(not training setting) of the clip. For example, if you set context_length to 100 since your string is very long during training, then assign 100 to checkpoint['model_state_dict']["context_length"]
checkpoint['model_state_dict']["input_resolution"] = model.input_resolution #default is 224
checkpoint['model_state_dict']["context_length"] = model.context_length # default is 77
checkpoint['model_state_dict']["vocab_size"] = model.vocab_size
model.load_state_dict(checkpoint['model_state_dict'])