从零搭建强化学习DQN框架
利用DQN框架完成倒立摆调节
- 1、从Q-Learning到DQN
-
- Q-Learning
- DQN
- 2、PARL框架
- 3、利用Python进行PARL框架移植
-
- 依赖库
- 神经网络框架
- 经验池类的创建
- 模型Model类的创建
- DQN算法类的创建
- 智慧体agent类的创建
- 训练与评估
- 训练效果展示
- 完整代码
1、从Q-Learning到DQN
Q-Learning
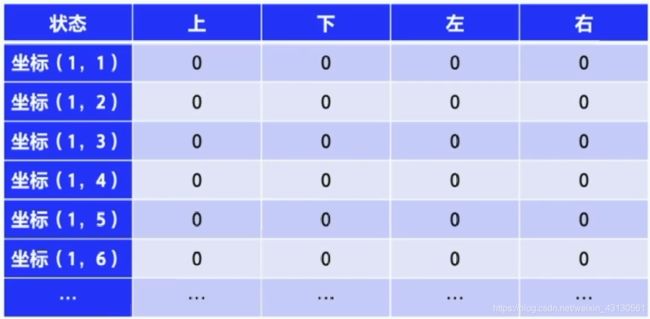
Q-Learning是一种通过Q-table来进行决策的value-based强化学习方案,Q表格中的每一个Q值通过智慧体agent与环境不停交互获得的reward进行更新,由于这是一种基于价值的学习方案,所以并不需要知道整个决策,即可对Q表格进行更新。更新公式:(由于本文主要介绍框架搭建,故公式具体内容就不深入介绍,相关内容可自行查询其他资料)![]()
DQN
DQN是在Q-Learning的基础上,使用深度学习的Q函数对Q-table进行了取代(由于大多情况下的模型都是非线性,同时状态的数量可能是无穷的,此时Q表格的初始化会很浪费资源,同时对很多模型都不能很好的适用)。
使用深度学习网络构建的Q函数需要输入模型的状态值,输出该状态下不同动作的动作价值,提供给智慧体进行决策,该框架整体使用了百度的PARL进行改写,将自己的神经网络移植进去。
2、PARL框架

(图片中为百度的PARL强化学习框架,本文只要是对model部分进行移植和修改)
3、利用Python进行PARL框架移植
依赖库
import numpy as np
import collections
import gym
import random
神经网络框架
该部分内容可以在上一期深度神经网络(Deep Learning)学习笔记中进行查看(相较于上期,在损失函数Mean中有部分修改)
class Layers:
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
self.nodes_num = nodes_num
self.inputs = inputs
self.name = name
self.is_trainable = is_trainable
self.gradients = {}
self.value = None
def __repr__(self):
return '{}'.format(self.name)
class Placeholder(Layers):
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=inputs, name=name, is_trainable=is_trainable)
self.x = self.inputs
self.outputs = []
def forward(self):
self.value = self.x
def backward(self):
for n in self.outputs:
self.gradients[self] = n.gradients[self] * 1
class Sigmoid(Layers):
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=inputs, name=name, is_trainable=is_trainable)
self.x = inputs
self.w_matrix = np.random.normal(size=[self.nodes_num, self.x.nodes_num])
self.b = np.random.randint(0, 9)
self.outputs = []
self.x.outputs.append(self)
def x_value_before_activate(self):
self.x.value = np.squeeze(self.x.value)
return np.dot(self.w_matrix, self.x.value) + self.b
def _sigmoid(self, x):
return 1. / (1 + np.exp(-1 * x))
def partial(self):
return self._sigmoid(self.x_value_before_activate()) * (1 - self._sigmoid(self.x_value_before_activate()))
def forward(self):
self.value = self._sigmoid(self.x_value_before_activate())
def backward(self):
for n in self.outputs:
x = np.array([self.x.value])
before_activate = n.gradients[self] * self.partial()
before_activate_m = np.transpose(np.array([before_activate]))
self.gradients[self.x] = np.dot(np.transpose(self.w_matrix), before_activate)
self.gradients['w_matrix'] = np.matmul(before_activate_m, x)
self.gradients['b'] = np.sum(before_activate)
class ReLU(Layers):
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=inputs, name=name, is_trainable=is_trainable)
self.x = inputs
self.w_matrix = np.random.normal(size=[self.nodes_num, self.x.nodes_num])
self.b = np.random.randint(0, 9)
self.outputs = []
self.x.outputs.append(self)
def x_value_before_activate(self):
return np.dot(self.w_matrix, self.x.value) + self.b
def partial(self):
p_vector = self.x_value_before_activate()
p_vector[p_vector <= 0] = 0
p_vector[p_vector > 0] = 1
return p_vector
def forward(self):
self.value = self.x_value_before_activate()
self.value[self.value <= 0] = 0
def backward(self):
for n in self.outputs:
before_activate = n.gradients[self] * self.partial()
x = np.array([self.x.value])
before_activate_m = np.transpose(np.array([before_activate]))
self.gradients[self.x] = np.dot(np.transpose(self.w_matrix), before_activate)
self.gradients['w_matrix'] = np.matmul(before_activate_m, x)
self.gradients['b'] = np.sum(before_activate)
class Mean(Layers):
def __init__(self, nodes_num=0, y=None, x=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=[y, x], name=name, is_trainable=is_trainable)
self.x = self.inputs[1]
self.y = self.inputs[0]
self.w_matrix = np.random.normal(size=[self.nodes_num, self.x.nodes_num])
self.b = np.random.randint(0, 9)
self.x.outputs.append(self)
def y_hat_value(self):
return np.squeeze(np.dot(self.w_matrix, self.x.value) + self.b)
def forward(self):
self.value = np.mean((self.y.value - self.y_hat_value()) ** 2)
def backward(self, onehot=None, is_onehot=False):
if is_onehot:
y_hat_value = np.transpose(np.transpose(self.y_hat_value()) * onehot)
else:
y_hat_value = self.y_hat_value()
x = np.array([self.x.value])
before_activate = -2 * (self.y.value - y_hat_value)
before_activate_m = np.transpose(np.array([before_activate]))
self.gradients[self.y] = 2 * (self.y.value - y_hat_value)
self.gradients[self.x] = np.dot(np.transpose(self.w_matrix), before_activate)
self.gradients['w_matrix'] = np.matmul(before_activate_m, x)
self.gradients['b'] = np.sum(before_activate)
def forward_and_backward(order, monitor=False, predict_mode=False):
if not predict_mode:
# 整体的参数更新一次
for layer in order:
if monitor:
print("前向计算Node:{}".format(layer))
layer.forward()
for layer in order[::-1]:
if monitor:
print("后向传播Node:{}".format(layer))
layer.backward()
else:
for n in range(len(order) - 1):
if monitor:
print("前向计算Node:{}".format(order[n]))
order[n].forward()
def sgd(layers, learning_rate=1e-2):
for l in layers:
if l.is_trainable:
w_matrix = np.transpose(l.w_matrix)
w_gradients = np.transpose(l.gradients['w_matrix'])
l.w_matrix = np.transpose(w_matrix - 1 * w_gradients * learning_rate)
l.b += -1 * l.gradients['b'] * learning_rate
def predict(node, Loss, test, order, monitor=False):
Loss.y.value = 0
node.x = test
forward_and_backward(order, monitor=monitor, predict_mode=True)
return np.max(Loss.y_hat_value()), np.argmax(Loss.y_hat_value())
def onehot(num, dim):
num = int(num)
temp = np.zeros(shape=(1, dim))
temp[0][num] = 1
temp = temp[0]
return temp
经验池类的创建
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), \
np.array(reward_batch).astype('float32'), \
np.array(next_obs_batch).astype('float32'), \
np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
在PARL框架中,经验池的作用相当于深度学习中的样本,用于神经网络的训练,经验池中可以存入一定量的经验,保证训练数据充足。
模型Model类的创建
class Model:
def __init__(self, act_dim):
hid1_size = 256
self.x = Placeholder(nodes_num=4, inputs=None, name='x', is_trainable=False)
self.y = Placeholder(nodes_num=act_dim, inputs=None, name='y', is_trainable=False)
self.fc1 = Sigmoid(nodes_num=hid1_size, inputs=self.x, name='Layer1', is_trainable=True)
self.fc2 = Mean(nodes_num=act_dim, y=self.y, x=self.fc1, name='Loss', is_trainable=True)
self.order = [self.x, self.y, self.fc1, self.fc2]
def save_model(self):
temp_w = []
temp_b = []
for l in self.order:
if l.is_trainable:
temp_w.append(l.w_matrix)
temp_b.append(l.b)
return temp_w, temp_b
def load_model(self, w, b):
for l in self.order:
if l.is_trainable:
l.w_matrix = w.pop(0)
l.b = b.pop(0)
def predict(self, test, monitor=False):
self.order[0].x = test
forward_and_backward(self.order, monitor=monitor, predict_mode=True)
return np.max(self.order[-1].y_hat_value()), np.argmax(self.order[-1].y_hat_value())
def value(self, test, monitor=False):
self.order[0].x = test
forward_and_backward(self.order, monitor=monitor, predict_mode=True)
return self.order[-1].y_hat_value()
def optimizer(self, onehot, target_value_onehot, learning_rate=1e-2):
self.order[-1].y.value = target_value_onehot
cost = 0
for n, layer in enumerate(self.order[::-1]):
if n == 0:
cost = np.mean((layer.y.value - layer.y_hat_value() * onehot) ** 2)
layer.backward(onehot=onehot, is_onehot=True)
else:
layer.backward()
sgd(self.order, learning_rate=learning_rate)
return cost
模型的创建这里使用了前面自己搭建的神经网络模型,并在Model类添加了save_model与load_model两个模块对网络之间的权重进行拷贝和移植。同时,与普通的网络训练过程不同,该网络的label是通过拷贝出来的网络进行计算得出的Q‘,带入上述公式计算出Q的label,并且只选取了当前动作下的value进行Loss计算(比如:分别有四个动作1、2、3、4,而进行了动作2通过网络的前向计算得出的y_hat_value为[1.2、3.2、4.1、2.6],此时我们需要进行一些处理得到[0、3.2、0、0],再与计算出的label进行均方差损失函数的计算,从而来更新整个神经网络)
DQN算法类的创建
class DQN:
def __init__(self, model, target_model, act_dim=None, gamma=None, lr=None):
self.model = model
self.target_model = target_model
assert isinstance(act_dim, int)
assert isinstance(gamma, float)
assert isinstance(lr, float)
self.act_dim = act_dim
self.gamma = gamma
self.lr = lr
def sync_target(self):
w, b = self.model.save_model()
self.target_model.load_model(w, b)
def predict(self, obs):
value, action = self.model.predict(obs)
return action
def learn(self, obs, action, reward, next_obs, terminal):
next_pred_value = self.target_model.value(next_obs)
best_v = np.max(next_pred_value)
terminal = float(terminal)
target = reward + (1.0 - terminal) * self.gamma * best_v
pred_value = self.model.value(obs)
action_onehot = onehot(action, self.act_dim)
target_value_onehot = target * action_onehot
cost = self.model.optimizer(action_onehot, target_value_onehot, learning_rate=self.lr)
return cost
其中,下面四行代码即为Q-label的计算公式体现:
next_pred_value = self.target_model.value(next_obs)
best_v = np.max(next_pred_value)
terminal = float(terminal)
target = reward + (1.0 - terminal) * self.gamma * best_v
智慧体agent类的创建
class Agent(object):
def __init__(self, alg, obs_dim, act_dim, e_greed=0.1, e_greed_decrement=1e-6):
self.global_step = 0
self.updata_target_steps = 200
self.alg = alg
self.act_dim = act_dim
self.e_greed = e_greed
self.e_greed_decrement = e_greed_decrement
def sample(self, obs):
sample = np.random.rand()
if sample < self.e_greed:
act = np.random.randint(self.act_dim)
else:
act = self.predict(obs)
self.e_greed = max(0.01, self.e_greed - self.e_greed_decrement)
return act
def predict(self, obs):
act = self.alg.predict(obs)
return act
def learn(self, obs, action, reward, next_obs, done):
if self.global_step % self.updata_target_steps == 0:
self.alg.sync_target()
self.global_step += 1
cost = []
for i in range(len(obs)):
temp = self.alg.learn(obs=obs[i], action=action[i], reward=reward[i], next_obs=next_obs[i], terminal=done[i])
cost.append(temp)
return cost
与其他强化学习一样,只需要注意一下learn函数部分,每进行200次,重新更新(权重拷贝)一下用来计算Q-label的网络。
训练与评估
def run_episode(env, agent, rpm):
total_reward = 0
obs = env.reset()
step = 0
memory_warmup_size = 100
batch_size = 10
while True:
step += 1
action = agent.sample(obs)
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done))
if len(rpm) > memory_warmup_size:
batch_obs, batch_action, batch_reward, batch_next_obs, batch_done = rpm.sample(batch_size)
train_loss = agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs, batch_done)
total_reward += reward
obs = next_obs
if done:
break
return total_reward
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs)
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
训练效果展示

训练一段时间之后,test_reward可以达到200分,此时倒立摆可以稳定地束起来(读者可以自行调节learning_rate,网络模型查看不同效果)
完整代码
import numpy as np
import collections
import gym
import random
class Layers:
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
self.nodes_num = nodes_num
self.inputs = inputs
self.name = name
self.is_trainable = is_trainable
self.gradients = {}
self.value = None
def __repr__(self):
return '{}'.format(self.name)
class Placeholder(Layers):
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=inputs, name=name, is_trainable=is_trainable)
self.x = self.inputs
self.outputs = []
def forward(self):
self.value = self.x
def backward(self):
for n in self.outputs:
self.gradients[self] = n.gradients[self] * 1
class Sigmoid(Layers):
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=inputs, name=name, is_trainable=is_trainable)
self.x = inputs
self.w_matrix = np.random.normal(size=[self.nodes_num, self.x.nodes_num])
self.b = np.random.randint(0, 9)
self.outputs = []
self.x.outputs.append(self)
def x_value_before_activate(self):
self.x.value = np.squeeze(self.x.value)
return np.dot(self.w_matrix, self.x.value) + self.b
def _sigmoid(self, x):
return 1. / (1 + np.exp(-1 * x))
def partial(self):
return self._sigmoid(self.x_value_before_activate()) * (1 - self._sigmoid(self.x_value_before_activate()))
def forward(self):
self.value = self._sigmoid(self.x_value_before_activate())
def backward(self):
for n in self.outputs:
x = np.array([self.x.value])
before_activate = n.gradients[self] * self.partial()
before_activate_m = np.transpose(np.array([before_activate]))
self.gradients[self.x] = np.dot(np.transpose(self.w_matrix), before_activate)
self.gradients['w_matrix'] = np.matmul(before_activate_m, x)
self.gradients['b'] = np.sum(before_activate)
class ReLU(Layers):
def __init__(self, nodes_num=0, inputs=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=inputs, name=name, is_trainable=is_trainable)
self.x = inputs
self.w_matrix = np.random.normal(size=[self.nodes_num, self.x.nodes_num])
self.b = np.random.randint(0, 9)
self.outputs = []
self.x.outputs.append(self)
def x_value_before_activate(self):
return np.dot(self.w_matrix, self.x.value) + self.b
def partial(self):
p_vector = self.x_value_before_activate()
p_vector[p_vector <= 0] = 0
p_vector[p_vector > 0] = 1
return p_vector
def forward(self):
self.value = self.x_value_before_activate()
self.value[self.value <= 0] = 0
def backward(self):
for n in self.outputs:
before_activate = n.gradients[self] * self.partial()
x = np.array([self.x.value])
before_activate_m = np.transpose(np.array([before_activate]))
self.gradients[self.x] = np.dot(np.transpose(self.w_matrix), before_activate)
self.gradients['w_matrix'] = np.matmul(before_activate_m, x)
self.gradients['b'] = np.sum(before_activate)
class Mean(Layers):
def __init__(self, nodes_num=0, y=None, x=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=[y, x], name=name, is_trainable=is_trainable)
self.x = self.inputs[1]
self.y = self.inputs[0]
self.w_matrix = np.random.normal(size=[self.nodes_num, self.x.nodes_num])
self.b = np.random.randint(0, 9)
self.x.outputs.append(self)
def y_hat_value(self):
return np.squeeze(np.dot(self.w_matrix, self.x.value) + self.b)
def forward(self):
self.value = np.mean((self.y.value - self.y_hat_value()) ** 2)
def backward(self, onehot=None, is_onehot=False):
if is_onehot:
y_hat_value = np.transpose(np.transpose(self.y_hat_value()) * onehot)
else:
y_hat_value = self.y_hat_value()
x = np.array([self.x.value])
before_activate = -2 * (self.y.value - y_hat_value)
before_activate_m = np.transpose(np.array([before_activate]))
self.gradients[self.y] = 2 * (self.y.value - y_hat_value)
self.gradients[self.x] = np.dot(np.transpose(self.w_matrix), before_activate)
self.gradients['w_matrix'] = np.matmul(before_activate_m, x)
self.gradients['b'] = np.sum(before_activate)
class SoftMax(Layers):
def __init__(self, nodes_num=0, y=None, x=None, name=None, is_trainable=False):
Layers.__init__(self, nodes_num=nodes_num, inputs=[y, x], name=name, is_trainable=is_trainable)
self.x = self.inputs[1]
self.y = self.inputs[0]
self.w_matrix = np.random.normal(size=[self.nodes_num, self.x.nodes_num])
self.b = np.random.randint(0, 9)
self.x.outputs.append(self)
def y_hat_value(self):
x_value_before_activate = np.exp(np.dot(self.w_matrix, self.x.value) + self.b)
total = np.sum(x_value_before_activate)
return x_value_before_activate / total
def forward(self):
self.value = - np.dot(self.y.value, np.log(self.y_hat_value()))
def backward(self):
x = np.array([self.x.value])
before_activate = self.y_hat_value() * np.sum(self.y.value) - self.y.value
before_activate_m = np.transpose(np.array([before_activate]))
self.gradients[self.x] = np.dot(np.transpose(self.w_matrix), before_activate)
self.gradients['w_matrix'] = np.matmul(before_activate_m, x)
self.gradients['b'] = np.sum(before_activate)
def forward_and_backward(order, monitor=False, predict_mode=False):
if not predict_mode:
# 整体的参数更新一次
for layer in order:
if monitor:
print("前向计算Node:{}".format(layer))
layer.forward()
for layer in order[::-1]:
if monitor:
print("后向传播Node:{}".format(layer))
layer.backward()
else:
for n in range(len(order) - 1):
if monitor:
print("前向计算Node:{}".format(order[n]))
order[n].forward()
def sgd(layers, learning_rate=1e-2):
for l in layers:
if l.is_trainable:
w_matrix = np.transpose(l.w_matrix)
w_gradients = np.transpose(l.gradients['w_matrix'])
l.w_matrix = np.transpose(w_matrix - 1 * w_gradients * learning_rate)
l.b += -1 * l.gradients['b'] * learning_rate
def predict(node, Loss, test, order, monitor=False):
Loss.y.value = 0
node.x = test
forward_and_backward(order, monitor=monitor, predict_mode=True)
return np.max(Loss.y_hat_value()), np.argmax(Loss.y_hat_value())
def onehot(num, dim):
num = int(num)
temp = np.zeros(shape=(1, dim))
temp[0][num] = 1
temp = temp[0]
return temp
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), \
np.array(reward_batch).astype('float32'), \
np.array(next_obs_batch).astype('float32'), \
np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
class Model:
def __init__(self, act_dim):
hid1_size = 256
self.x = Placeholder(nodes_num=4, inputs=None, name='x', is_trainable=False)
self.y = Placeholder(nodes_num=act_dim, inputs=None, name='y', is_trainable=False)
self.fc1 = Sigmoid(nodes_num=hid1_size, inputs=self.x, name='Layer1', is_trainable=True)
self.fc2 = Mean(nodes_num=act_dim, y=self.y, x=self.fc1, name='Loss', is_trainable=True)
self.order = [self.x, self.y, self.fc1, self.fc2]
def save_model(self):
temp_w = []
temp_b = []
for l in self.order:
if l.is_trainable:
temp_w.append(l.w_matrix)
temp_b.append(l.b)
return temp_w, temp_b
def load_model(self, w, b):
for l in self.order:
if l.is_trainable:
l.w_matrix = w.pop(0)
l.b = b.pop(0)
def predict(self, test, monitor=False):
self.order[0].x = test
forward_and_backward(self.order, monitor=monitor, predict_mode=True)
return np.max(self.order[-1].y_hat_value()), np.argmax(self.order[-1].y_hat_value())
def value(self, test, monitor=False):
self.order[0].x = test
forward_and_backward(self.order, monitor=monitor, predict_mode=True)
return self.order[-1].y_hat_value()
def optimizer(self, onehot, target_value_onehot, learning_rate=1e-2):
self.order[-1].y.value = target_value_onehot
cost = 0
for n, layer in enumerate(self.order[::-1]):
if n == 0:
cost = np.mean((layer.y.value - layer.y_hat_value() * onehot) ** 2)
layer.backward(onehot=onehot, is_onehot=True)
else:
layer.backward()
sgd(self.order, learning_rate=learning_rate)
return cost
class DQN:
def __init__(self, model, target_model, act_dim=None, gamma=None, lr=None):
self.model = model
self.target_model = target_model
assert isinstance(act_dim, int)
assert isinstance(gamma, float)
assert isinstance(lr, float)
self.act_dim = act_dim
self.gamma = gamma
self.lr = lr
def sync_target(self):
w, b = self.model.save_model()
self.target_model.load_model(w, b)
def predict(self, obs):
value, action = self.model.predict(obs)
return action
def learn(self, obs, action, reward, next_obs, terminal):
next_pred_value = self.target_model.value(next_obs)
best_v = np.max(next_pred_value)
terminal = float(terminal)
target = reward + (1.0 - terminal) * self.gamma * best_v
pred_value = self.model.value(obs)
action_onehot = onehot(action, self.act_dim)
target_value_onehot = target * action_onehot
cost = self.model.optimizer(action_onehot, target_value_onehot, learning_rate=self.lr)
return cost
class Agent(object):
def __init__(self, alg, obs_dim, act_dim, e_greed=0.1, e_greed_decrement=1e-6):
self.global_step = 0
self.updata_target_steps = 200
self.alg = alg
self.act_dim = act_dim
self.e_greed = e_greed
self.e_greed_decrement = e_greed_decrement
def sample(self, obs):
sample = np.random.rand()
if sample < self.e_greed:
act = np.random.randint(self.act_dim)
else:
act = self.predict(obs)
self.e_greed = max(0.01, self.e_greed - self.e_greed_decrement)
return act
def predict(self, obs):
act = self.alg.predict(obs)
return act
def learn(self, obs, action, reward, next_obs, done):
if self.global_step % self.updata_target_steps == 0:
self.alg.sync_target()
self.global_step += 1
cost = []
for i in range(len(obs)):
temp = self.alg.learn(obs=obs[i], action=action[i], reward=reward[i], next_obs=next_obs[i], terminal=done[i])
cost.append(temp)
return cost
def run_episode(env, agent, rpm):
total_reward = 0
obs = env.reset()
step = 0
memory_warmup_size = 100
batch_size = 10
while True:
step += 1
action = agent.sample(obs)
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done))
if len(rpm) > memory_warmup_size:
batch_obs, batch_action, batch_reward, batch_next_obs, batch_done = rpm.sample(batch_size)
train_loss = agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs, batch_done)
total_reward += reward
obs = next_obs
if done:
break
return total_reward
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs)
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
def main():
env = gym.make('CartPole-v0')
action_dim = env.action_space.n
obs_shape = env.observation_space.shape
memory_size = 200
gamma = 0.9
max_episode = 2000
learning_rate = 0.0001
rpm = ReplayMemory(memory_size)
model = Model(act_dim=action_dim)
target_model = Model(act_dim=action_dim)
algorithm = DQN(model=model, target_model=target_model, act_dim=action_dim, gamma=gamma, lr=learning_rate)
agent = Agent(
alg=algorithm,
obs_dim=obs_shape[0],
act_dim=action_dim,
e_greed=0.1,
e_greed_decrement=1e-6)
episode = 0
while episode < max_episode:
for i in range(0, 50):
total_reward = run_episode(env, agent, rpm)
episode += 1
eval_reward = evaluate(env, agent, render=True)
print('episode:{}, e_greed:{}, test_reward:{}'.format(episode, agent.e_greed, eval_reward))
if __name__ == '__main__':
main()