预训练语言模型(PLMs)综述
预训练语言模型(PLMs)
内容来自AACL 2022 Tutorial:
https://d223302.github.io/AACL2022-Pretrain-Language-Model-Tutorial/
https://d223302.github.io/AACL2022-Pretrain-Language-Model-Tutorial/lecture_material/AACL_2022_tutorial_PLMs.pdf
预训练语言模型(PLMs)是在大规模语料库上以自监督方式进行预训练的语言模型。在过去的几年中,这些PLM从根本上改变了自然语言处理社区。传统的自监督预训练任务主要涉及恢复损坏的输入句子,或自回归语言建模。在对这些PLM进行预训练后,可以对下游任务进行微调。按照惯例,这些微调包括在PLM之上添加一个线性层,并在下游任务上训练整个模型;或将下游任务表述为句子补全任务,并以seq2seq的方式微调下游任务。在下游任务上对PLM进行微调通常会带来非凡的性能提升,这就是plm如此受欢迎的原因。
在本教程中,从两个角度提供广泛而全面的介绍:为什么这些PLM有效,以及如何在NLP任务中使用它们。
- 第一部分对PLM进行了一些有见地的分析,部分解释了PLM出色的下游性能。其中一些结果帮助研究人员设计更好的预训练和微调方法
- 第二部分首先关注如何将对比学习应用于PLM,以改进由PLM提取的表示,然后说明如何在不同情况下将这些PLM应用于下游任务。这些情况包括在数据稀缺的情况下对PLM进行微调,以及使用具有参数效率的PLM。
Part 1 Introduction
PLM + fine tune
Part 2 Why do PLMs work
2.1 Contextualized word respresentation

词向量表示方法,比如Word2Vec/Glove,BERT可以被视为一种先进的词向量表示方法,即上下文词向量表示(contextualized word respresentation),不仅仅包括:相似的token有相似的embedding表示(这在word2vec/Glove中已经实现了),还考虑了token的上下文信息,因此相同的词可能有不同的词向量表示。
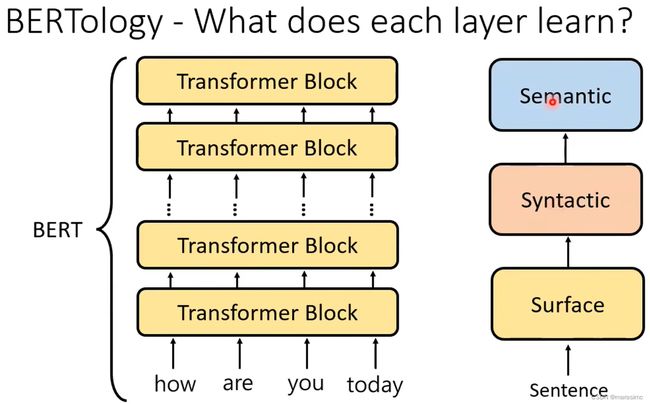
2.2 BERTology - What does each layer learn?
2.3 BERT Embryology - What BERT learned during training?
2.4 When do you need billions of words of pretraining data

2.5 cross-discipline capability(跨学科能力)
2.6 Pre-training on Artificial Data
Part 3 How to Use PLMs: Contrastive learning for Pre-trained Language Models
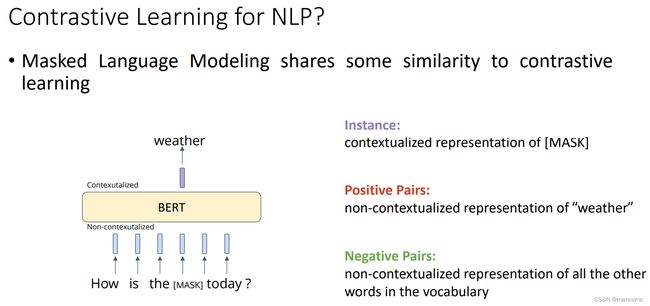
Why Contrastive?(为什么需要对比学习)
想要在以下场景对词有一个比较好的表示:
- 相似的输入有相似的表示(positive pairs)
- 不相似的输入有不相似的表示(negative pairs)

3.1 Why we need sentence-level representation?
- Provide as a backbone that can be useful on a variety of downstream sentence-level tasks(提供可用于各种下游句子级任务的主干)
- Good generalization ability on tasks without much training data e.g. even linear probing can achieve good performance(良好的泛化能力,不需要大量的训练数据。即使是线性探测也能取得良好的性能)
- Efficient sentence-level clustering or semantic search by innerproducts(基于内部产品的高效句子级聚类或语义搜索)
- Measure similarities among sentence pairs(句子对间的度量相似性)
- Unsupervised methods are more desirable in order to be applied to languages beyond English(非监督的方法是更可取的,以便应用英语以外的语言)
3.2 Pre-BERT methods


3.3 How to obtain sentence-level representations from BERTs
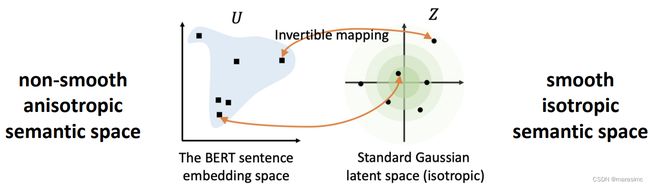
不能简单地从token-level的表示中获得。
BERT表示空间中的各向异性问题(anisotropy problem):
- 表示退化(representation degeneration):学习的嵌入在向量空间中占据一个狭窄的圆锥;
- 限制向量空间的表现力
BERT flow:
BERT-whitening

3.4 Cotrastive learning method
- Designed positives —— DeCLUTR、ConSERT
- Generating Positives
- Bootstrapping Methods —— BYOL
- Dropout Augmenttions —— SimCSE (Unsupervised)、Supervised SimCSE、mSimCSE
- Equivariant Contrastive Learning
- Prompting
- Ranking-based Methods —— RankEncoder
3.5 conlusion
- Contrastive learning should have more potential in NLP for using pre-trained language models in representation learning!
Part 4 How to Use PLMs: Parameter-efficient fine-tuning
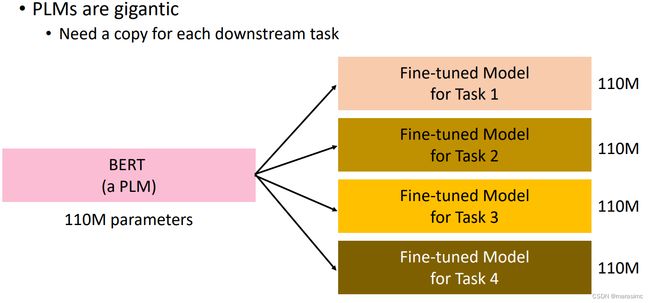
Problem: PLMs are gigantic (in terms of numbers of parameters, model size, and the storage needed to store the model)
Solution: Reduce the number of parameters by parameter-efficient fine-tuning
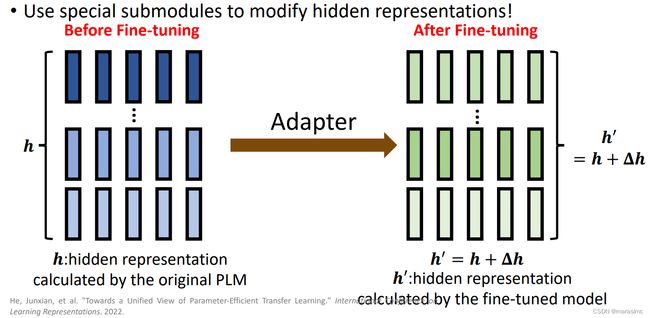
一个标准的fine-tuning实际执行的操作?-> 更改PLM的隐藏层表示以使得它能够在下游任务更好地表现。
4.1 Adapter
-
Adapter:一个被嵌入transformer的小的可训练子模块


-
在fine-tuning期间,仅更新adapters与classifier head的参数。
-
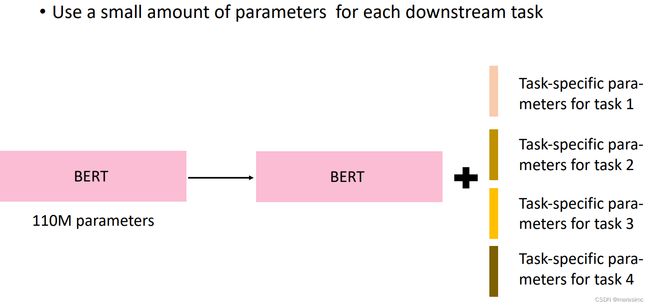
通过采用adapter结构,所有下游任务共享PLM参数,每层的adapters以及classifier heads则是特定任务的模块。
4.2 LoRA
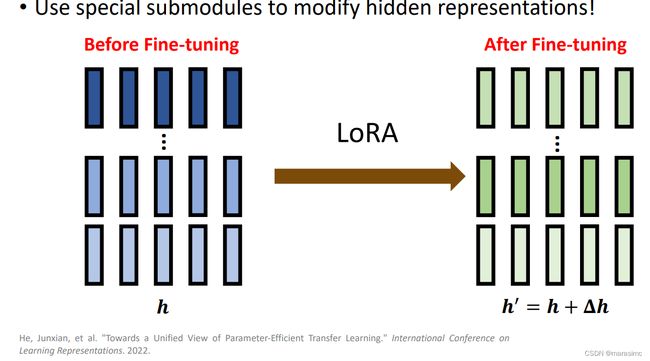
-
LoRA: Low-Rank Adaptation of Large Language Models
- 平行地插入transformer的feed-forward层,也可以插入multi-head attention层

- 考虑LoRA平行地插入feed-forward层的情况:
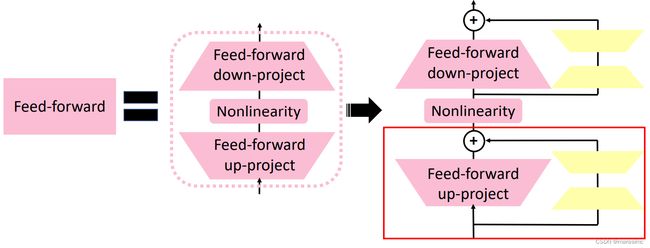

- 通过采用LoRA结构,所有下游任务共享PLM参数,每层的LoRA以及classifier heads则是特定任务的模块
4.3 Prefix tuning

- Prefix Tuning: 在每层之前插入可训练前缀

-
标准的self-attention结构:

-
加上prefix后的self-attention结构:

-
Only the prefix (key and value) are updated during finetuning
4.4 (Soft) Prompt tuning
- Soft Prompting:在输入层预先嵌入前缀
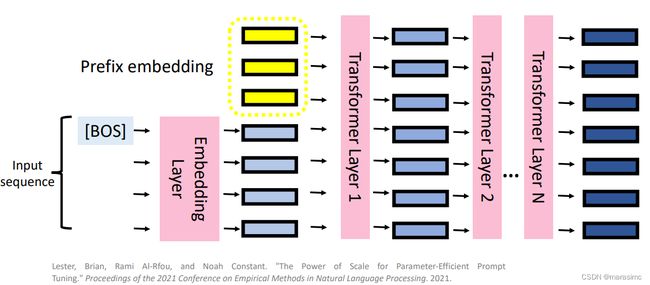
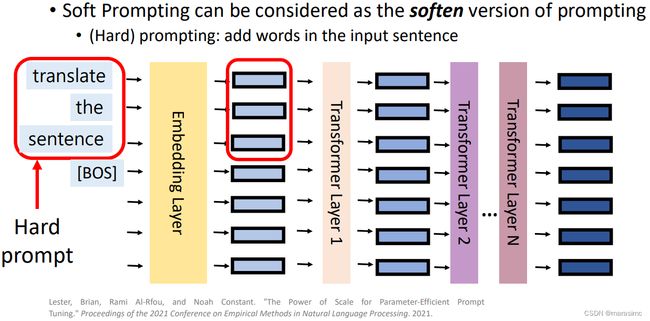
-
如何确定软提示嵌入的长度?
- 提示长度必须足够长
- 当提示长度足够长时,增加提示长度会减少性能增益
-
如何初始化软提示嵌入?
- 随机初始化
- 从前5000个高频词的词嵌入中采样
- 采用下游任务的类别标签
4.5 summary
-
优势1:大幅度减少特定任务的参数
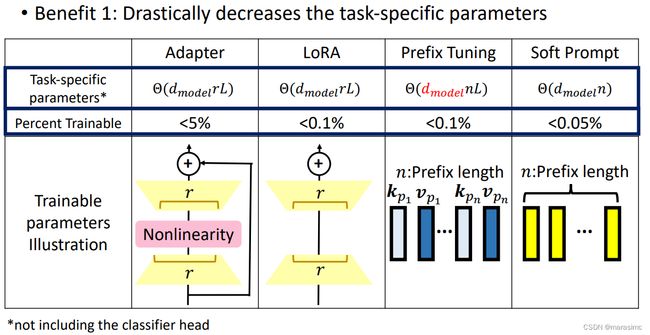
-
优势2:训练数据不容易过拟合;更好的域外性能

-
优势3:需要微调的参数更少,使它们在小数据集训练时更有优势
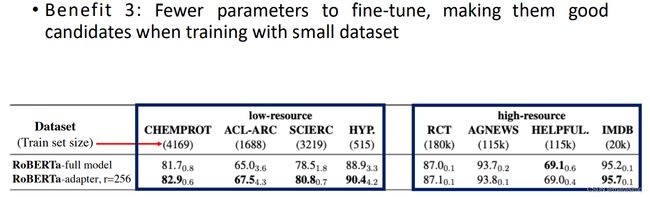
-
应该使用哪种parameter-efficient fine-tuning 策略?
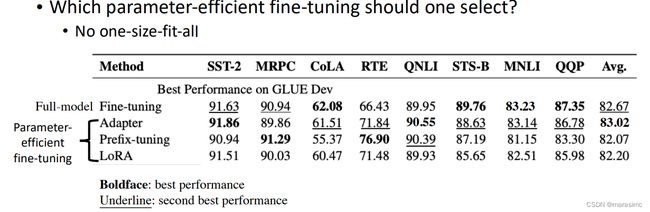
Part 5 How to Use PLMs: Using PLMs with different amounts of data
- 目标:fine-tune一个PLM以适配下游任务
- 习惯上,我们假设我们有足够的对应目标任务的有标签数据
- 有时,我们可能有额外的用于其他任务的有标签数据(是否可以用于当前任务的训练呢?)
- 有时,用于目标任务的有标签数据很稀缺
- 有时,我们只有少量用于目标任务的有标签数据,还有与当前任务有关的无标签数据
- 有时,我们没有任何用于当前任务的有标签数据
- 对于不同大小规模的数据,应该怎么使用PLM?
- Target task dataset (labeled)
- Datasets of other tasks (labeled)
- Data related to target task (Unlabeled)
5.1 Intermediate-task fine-tuning: using labeled data from other tasks
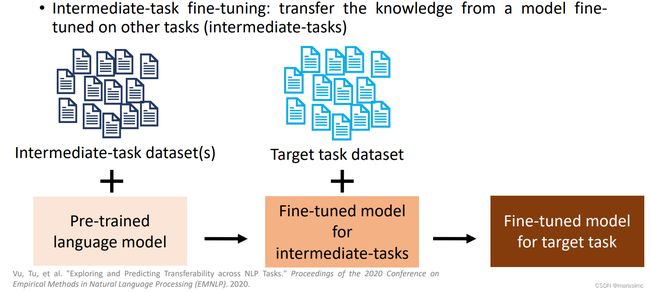
- What kind of intermediate tasks can help target task?
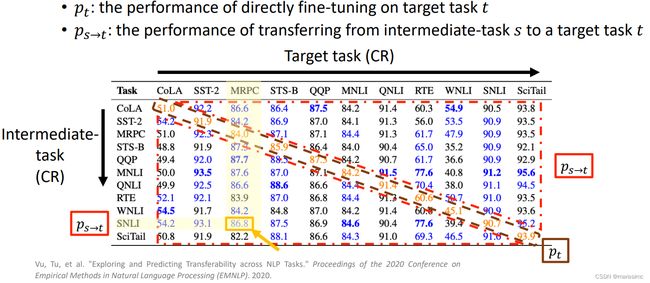

-
Same type of tasks is the most beneficial
-
-
当对整个模型进行微调时,将为每个中间任务提供一个全尺寸模型
-
当使用soft prompt tuning进行微调时,只需要transfer软提示嵌入,而不是一整个模型——Soft Prompt Transfer (SPoT)
-
Soft Prompt Transfer (SPoT):任务的软提示符可以用作该任务的任务嵌入
-
Soft Prompt Transfer (SPoT):给定一个新任务,我们可以先只使用该新任务进行训练,然后找到一个任务嵌入与新任务的任务嵌入最相似的间接任务,并使用它进行转移。
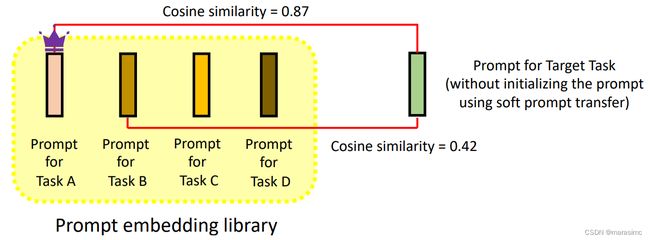

-
-
5.1.1 Multi-task fine-tuning: 5-1.1: using labeled data from other tasks
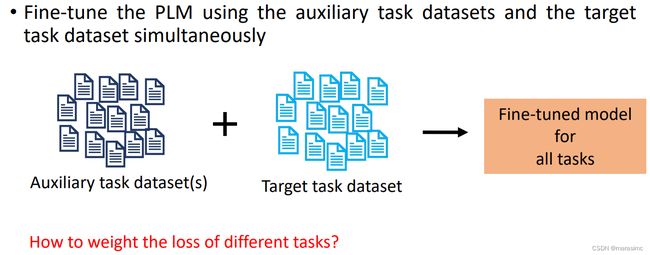
5.1.2 Prompt tuning for few-shot learning
-
标准的fine-tuning通常假设有大量的有标签训练数据
-
数据稀缺在处理下游任务时是很常见的
-
Few-shot learning:有一些(less than a hundred)有标签训练数据
-
通过将数据集中的数据点转换为自然语言提示(natural language prompts),模型可能更容易知道它应该做什么

-
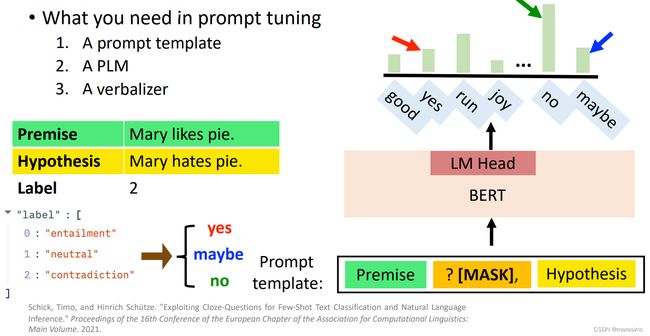
prompt tuning中需要什么?
-
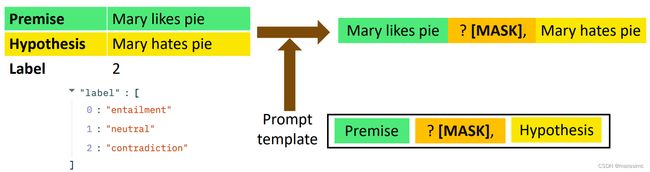
A prompt template: 将数据点转换为自然语言提示
-
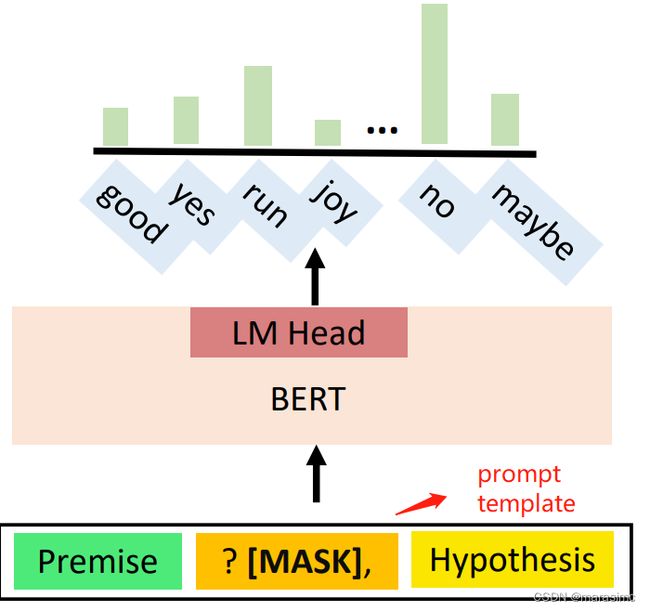
A PLM: 执行语言建模
-
A Verbalizer:标签与词汇的映射

-
-
提示微调(prompt tuning)与标准微调(standard fine-tuning)的区别
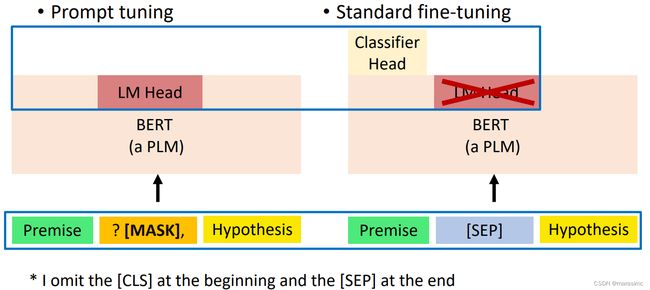
-
input format不同:
prompt tuning: natural language prompt with a mask token to fill in.
standard fine-tuning: simply combining sentences with a separator token
-
prompt tuning: simply use the language model head and the verbalizer to predict the class of the downstream task.
standard fine-tuning: initialize a new classifier head for fine-tuning
在数据稀缺的情况下prompt tuning表现更好:<
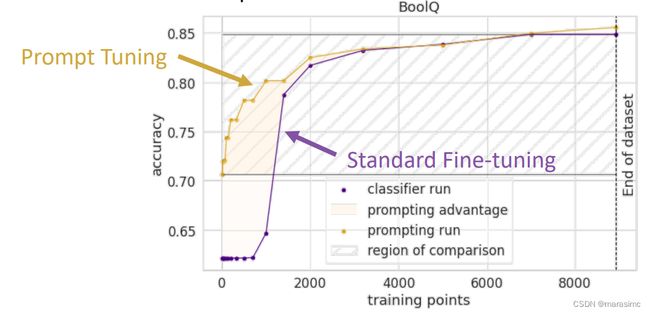
- 引入了人类知识,且没有引入额外的参数。
-
-
如何选择verbalizer?
- 人工设计:需要特定任务的知识

-
Prototypical verbalizer:使用可学习的原型向量去表示一个类,而不是使用词汇表中的词汇
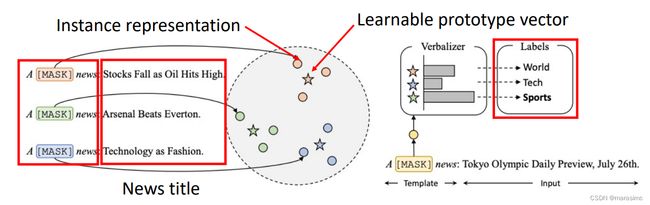
- I. 获得instance representation
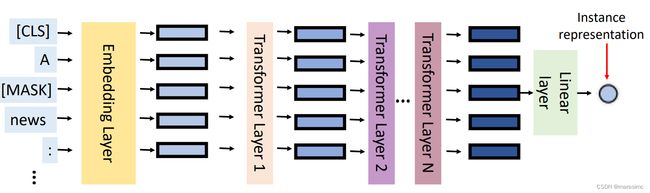
-
II. 通过对比学习(contrastive learning)获得learnable prototypr vector
-
①instance-instance contrastive

-
②instance-prototype contrastive
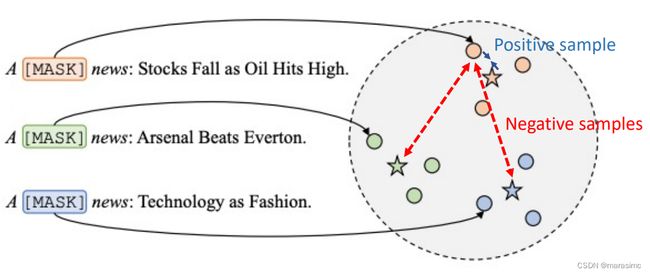
-
-
III. 执行推断:找出与测试数据的instance representation 最相近的prototype

-
方法对比:
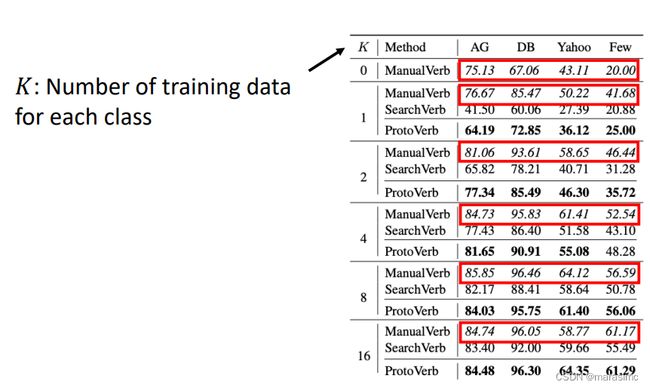
- 人工设计verbalizer在大多数情况下是最优的,但是这依赖于特定任务领域的知识
- Prototypical verbalizer 不依赖于特定任务领域的知识,但是即使在一个类别仅有一个label的情况下也有较好的表现
-
LM-BFF: better few-shot fine-tuning of language models
-
核心:prompt + demonstration
-
standard prompt tuning:
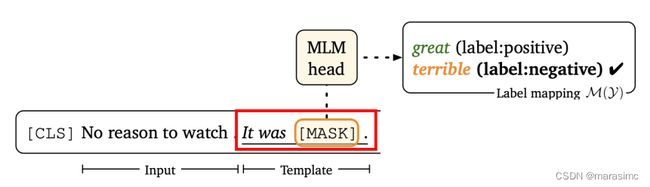
-
prompt + demonstration:

-
-
Demonstrations can improve the performance of prompt tuning and makes the variance smaller

-
-
prompting vs. probing
- “提示”的概念在最近的NLP社区中首次用于探究(probing)PLM的事实知识
- probing是探索PLM中编码了哪些知识的过程,PLMs通常在probing期间被固定
- Prompting通常使用自然语言去询问PLM,PLM在prompting期间可以被微调
- prompting与probing的目的不同
5.2 Semi-supervised learning with PLMs
-
Semi-Supervised learning(半监督学习):有少量的带标签数据以及大量的无标签数据
-
核心思想:使用带标签数据训练一个好的模型,然后使用训练后的模型为无标签数据打标签(pseudo-label)。
-
方法1:Pattern-Exploiting Training (PET) ,步骤:
-
Use different prompts and verbalizer to prompt-tune different PLMs on the labeled dataset
-
Predict the unlabeled dataset and combine the predictions from different models

-
Use a PLM with classifier head to train on the soft-labeled data set
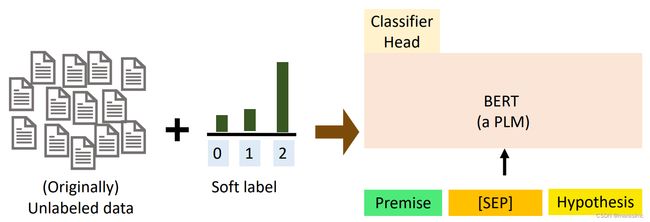
-
-
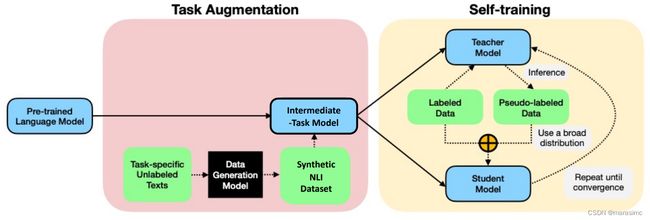
方法2:Self-Training with Task Augmentation (STraTA)
- Self-training:使用模型在无标签数据集上的预测作为伪标签
- 如何初始化模型对于最终性能是至关重要的

teacher model:为无标签数据打标签的模型
student model:使用带标签数据与伪标签数据训练得到的模型
-
Task augmentation:使用无标签数据生成一个NLI数据集,然后将NLI数据集作为intermediate task进行微调,获得基础模型。

步骤:
-
Train an NLI data generator using another labeled NLI dataset using a generative language model (训练一个NLI数据生成器)
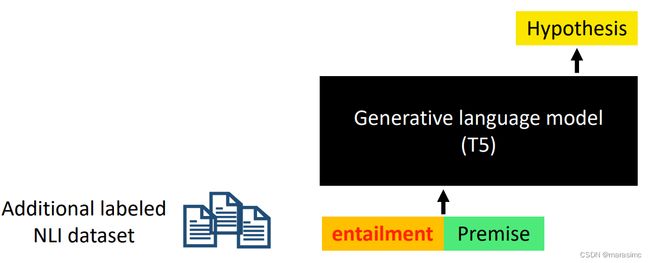
-
Use the trained data generator to generate NLI dataset using the in-domain unlabeled data (使用训练得到的数据生成器,结合无标签数据生成NLI数据集)

-
Use the generated in-domain NLI dataset to fine-tune an NLI model. The finetuned model is used to initialize the teacher model and student model in self-training (使用生成的NLI数据集去微调NLI模型,微调得到的模型用于初始化teacher模型与student模型)
5.3 Zero-shot learning
- Zero-shot inference:不使用任何训练数据去推断下游任务。
- GPT-3 shows that zero-shot (with task description) is possible
- zero-shot的能力从何而来?
- 假设:在预训练期间,训练数据集隐含地包含不同任务的混合
- 假设:多任务训练实现了zero-shot泛化
Conclusion and Future work
6.1 Conclusion
- Researchers have studied why PLMs are useful from many aspects
- Contrastive learning is a powerful method to obtain high quality sentence embedding in an unsupervised way
- Parameter-efficient fine-tuning can achieve comparable performance to full-model fine-tuning
- PLMs can be used in with different amount of labeled and unlabeled datasets, and incorporating human knowledge is very critical the performance
6.2 Future work
- Why PLMs work is not completely answered yet, including the mathematical theory / learning theory behind the PLMs (为什么PLMs的工作还没有完全地解决,包括其背后的数学理论/学习理论)
- How can we create better negative and positive samples for contrastive learning in an unsupervised way (我们如何在无监督的情况下为对比学习创造更好的负样本和正样本)
- How can we combine parameter-efficient fine-tuning methods with other methods (pruning, compression, quantization) to further reduce the parameters?(我们如何将参数高效微调方法与其他方法(剪枝、压缩、量化)结合起来进一步减少参数?)
- How does those few-shot learning methods perform domain-specific datasets? (那些few-shot学习方法怎么在特定领域的数据集上执行)
- How trust-worthy are the prediction of PLMs, especially in few-shot and zero-shot? (PLMs的预测可行度如何,尤其在few-shot和zero-shot领域)
- Why is the variance between different prompts very large for certain tasks? Does this imply the PLM fail to understand human language?(为什么在某些任务中不同提示之间的差异非常大?这是否意味着PLM无法理解人类语言?)
- How do we continuously adapt PLMs to different domain and datasets from different time? (我们如何不断地使PLMs适应不同时间的不同领域和数据集?)