目标检测算法实现(四)——yolov5第一次训练
训练模型虽然内容不多 但是还是很重要的 所以单列一篇出来啦~
目录
训练模型
1. 在data文件夹下人为构造images、ImageSets、labels三个文件夹
2.修改并添加部分.yaml
3.修改models文件夹下yolov5s.yaml
4.修改train.py的配置参数
训练模型
1. 在data文件夹下人为构造images、ImageSets、labels三个文件夹
1.其中images用于存放所有的jpg图片,labels用于存放所有的标签txt文件,ImageSets为空(注意大小写不能改变)
2.把rw_txt.py放到程序文件夹(yolov5-master)下 (非必要),运行该程序。
这是一个批量操作txt文档的程序,因为我们标注时,如果是分开两次标注,标注不同类别的物体,那他们的类别序号都是0,按理说应该一个类别序号为0,一个为1,所以我们统一把某个文件夹下的一类目标的txt标签文档中类别序号修改一下,这个是批量操作txt文档的程序。(待理解)
3.把make_txt.py放到程序文件夹(yolov5-master)下,运行该程序。
该程序根据labels中txt文件名进行随机划分数据集,生成的txt文件在Imagesets中,运行后可以查看。
4.再把make_data.py放到程序文件夹(yolov5-master)下,运行该程序。
该程序将images中的图片按照上面的划分(train test val)分配到images下面新建的三个文件夹中,将labels中的标签按照上面的划分分配到labels下面新建的三个文件夹中。
执行顺序为:rw_txt.py——make_txt.py——make_data.py——train.py
2.修改并添加部分.yaml
yaml如下图其中这5个.yaml(argoverse.coco.coco128.visdrone.voc)可以不保留,我个人操作的时候保留了的。(hyp.f hyp.s)这两个必须保留。

修改自己的yaml!命名yaml为fire.yaml(后面对应配置到train.py-data-default中),修改yaml中的参数(数据集txt的文件地址、类数量、类名)eg,三类,分别为 ['candle', 'fire', 'smoke']

3.修改models文件夹下yolov5s.yaml
修改第二行nc的80为种类数,将种类数量改为N。(N个类别)

4.修改train.py的配置参数
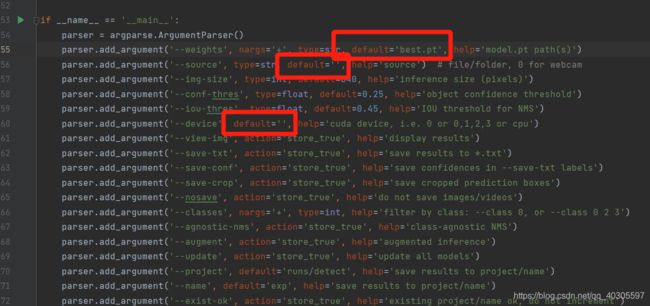
1.修改--data那里,后面那个default='data/fire.yaml'(对应第二条修改)
2.修改--epochs(训练轮数)那里,default设为200,默认为200
3.修改--batch-size(每一批样本量)那里,default设为1(电脑性能不行 不断修改)
4.修改--device(设备)那里,default设为0(device设为0说明采用gpu进行检测,cpu写cpu)
5.训练完会出来模型文件:best.pt,放到程序文件夹,然后detect.py去调用这个best.py就行了。
在runs/train/exp找最大序号那个,找到best.pt,把best.pt复制到yolov5-master程序文件夹下
调用best.pt这个文件是指把detect.py里面main下面weights的default后面名字改为best.pt(source device——default设为0)
RUN !! 结束!!!DONE!!!!!!
ps小常识:
1.只要相对地址就行了,跟你的程序文件(detect.py)同一级的话就直接写文件名,在下一级,就要加上上一级文件夹名。
2..pt是训练生成的模型文件,不需要解压,直接放到程序下面,detect.py里面main下面--weights那一行,default后面的变量名换成这个pt的,就是直接调用别人训练好的这个模型(.pt)
目前是80个种类的常规物体检测,后续我需要做的是烟雾检测,后续工作主要是找烟雾数据集,打标签,训练网络,得到的模型就能识别特定种类的目标了。