深度学习-图像分类篇 P3.1AlexNet网络-pytorch
哔哩哔哩视频链接
up主附的代码链接
(一)AlexNet网络介绍
1.1 简介
1、该网络的亮点:
 (1)使用传统的Sigmoid激活函数求导比较麻烦,而且在较深的网络中容易导致梯度消失现象,而ReLu函数能解决这两个问题。
(1)使用传统的Sigmoid激活函数求导比较麻烦,而且在较深的网络中容易导致梯度消失现象,而ReLu函数能解决这两个问题。
(2)过拟合是指特征维度过多或模型设计过于复杂时训练的拟合函数,它能完美的预测几乎所有训练集,但对新数据的泛化能力差。
而该作者提出的Dropout能在网络正向传播过程中随机失活一部分神经元,相当于随机放弃了一部分参数,从而达到过拟合的状态。
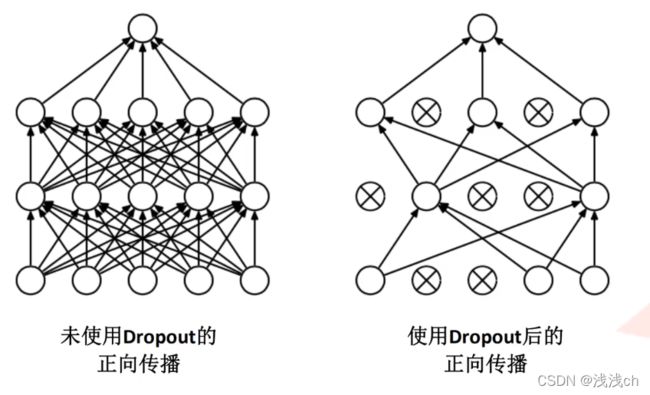 (3)回顾公式:
(3)回顾公式:

1.2 网络结构介绍
1、下图是AlexNet网络这篇论文原文提出的网络结构,分成上下两个部分用GPU并行处理的。两层结构一样,我们以其中一层为例。
 从图中分析可得:
从图中分析可得:
(1)原始图片的大小为224 X 224(channel=3),其中卷积核的大小为11 X 11,步距为4,卷积核的个数为48(由下一层可以看到)。计算N=(224-11+(1+2))/4+1=55。(padding为(1,2)就是左边加1层,右边加2层,上边加1层,下边加2层padding)
因此,输出特征层大小为55,channel=482=96。
 (2)接下来是下采样层Max pooling,下采样层的卷积核大小和padding我们并不能从图中看出,是从其他途径了解的。
(2)接下来是下采样层Max pooling,下采样层的卷积核大小和padding我们并不能从图中看出,是从其他途径了解的。
输入是上一层的输出【55,55,96】,因此计算的N=(55-3+0)/2+1=27,因为max pooling只会改变特征层的宽度和高度,不会改变深度channel,所以输出是【27,27,96】。
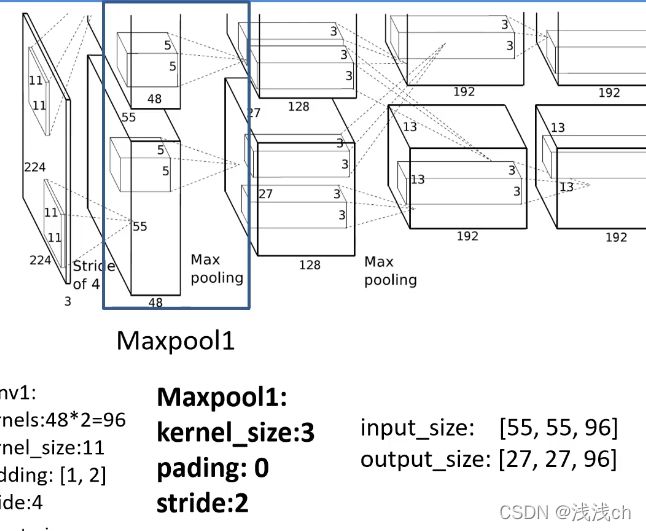 (3)进入下一个卷积层,可以看出卷积核大小为5,其中padding和stride都不能直接看出,从资料上找的。N=(27-5+(2+2))/1+1=27。
(3)进入下一个卷积层,可以看出卷积核大小为5,其中padding和stride都不能直接看出,从资料上找的。N=(27-5+(2+2))/1+1=27。
所以输出特征层大小为27,channel=1282=256(从下一层看出)。
 (4)同理,通过Maxpool2后的特征层N=(27-3+0)/2+1=13,但不改变channel,output就是【13,13,256】。
(4)同理,通过Maxpool2后的特征层N=(27-3+0)/2+1=13,但不改变channel,output就是【13,13,256】。
(5)接下来进入Conv3第三个卷积层,可以看出卷积核的大小为3 X 3,所以N=(13-3+(1+1))/1+1=13,输出为【13,13,384】。
 (6)接下来进入Conv4:
(6)接下来进入Conv4:
 接下来是Conv5:
接下来是Conv5:
 然后是Max pooling层:
然后是Max pooling层:
 接下来就是3个全连接层,最后一层我们放了1000个节点,因为数据集的种类是1000类。
接下来就是3个全连接层,最后一层我们放了1000个节点,因为数据集的种类是1000类。
1.3 项目预备–下载花朵分类的数据集
1、在该链接上的(2)下载花朵数据集压缩包,并放在data_set文件夹下新建的flower_data文件夹下。
 解压这个压缩包后,现在文件位置是这样:
解压这个压缩包后,现在文件位置是这样:

2、在上面那个链接中把split_data.py文件拷贝下来,放到data_set文件夹下。这个脚本会自动按照9:1将数据集分为测试集和验证集。
鼠标放在“data_set”文件夹下的某个位置,按住shift,同时鼠标点击右键,选择“在此处打开PowerShell窗口”:
 输入:python .\split.py 开始执行文件代码。
输入:python .\split.py 开始执行文件代码。
 处理成功!
处理成功!
1.4 各层参数总结

(二)代码–AlexNet分类花朵数据集
2.1 构建模型model.py
1、定义类AlexNet的初始化函数init()
定义一个类AlexNet继承了nn.Module的父类,然后在其中定义一个初始化函数init(),来定义网络正向传播中需要的一些层结构。
这里我们使用Sequential()模块,能将一系列的层结构打包,组合成一个新的结构,我们将之命名为features,用于提取图像特征。
下面的classifier则是使用Sequential()模块将后面的三个全连接层打包。
class AlexNet(nn.Module):
#定义一个初始化函数init(),来定义网络正向传播中需要的一些层结构。
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
#我们将这个打包的层结构命名为features,用于提取图像特征
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
(1)第一行的Conv2d()函数对应图表中的Conv1,为了训练方便,我们只训练一半,将卷积核个数减半了=48,卷积核大小仍=11,步距stride=4,因为是RGB图像所以channel=3。
另外,padding=i(整数)代表在上下左右分别补 i 行 0。如果使用tuple:(1,2),其中1代表上下方各补一行零,2代表左右两侧各补两列零;如果想用更精细化的nn.ZeroPad2d((1,2,1,2)),代表左侧补1列,右侧补2列,上方补1行,下方补2行。
因为这里计算N的时候有小数会自动舍弃,所以我们用padding=2的结果跟上面精细化处理的效果一致。
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
(2)然后使用ReLU()激活函数后再用MaxPool2d()函数定义一个最大池化下采样层,该层的卷积核大小=3,步距=2。
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2), # output[48, 27, 27]
后面的代码定义类似。但是上一层卷积层的卷积核个数直接=这一层卷积层的channel。
(3)定义分类器classifier,我们在下采样层到全连接层之前要进行展平操作,然后我们在展平操作之前使用dropout函数按某个比例将一部分神经元失活。
这里我们调整的失活比例是0.5,因为下采样层后的特征层是【6,6,256】,因为这里我们只采用了一半,所以传入128X6X6,而由参数表可知FC1的卷积核大小=2048,所以第一个展平函数Linear(128X6X6,2048)。
然后上一个Linear()函数第二维的2048作为第二个展平函数的输入,而FC2=2048,所以第二个展平函数Linear(2048,2048)。
同理,第三个展平函数的第一个值就是2048,第二个值就是种类数num_classes。
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
如果在搭建网络过程中传入了初始化权重,就是init_weights为true了,就会执行初始化权重方法_initialize_weights()。
if init_weights:
self._initialize_weights()
2、定义初始化权重方法initialize_weights()
(1)遍历每个层结构m是属于哪个类别的module,例如用isinstance()函数判断m层结构是否属于卷积层nn.Conv2d。如果是的话,就用kaiming_normal()变量初始化方法对权重w进行初始化,如果偏置bias不为空的话,就用0对其进行初始化。
如果m是属于全连接层nn.Linear,那么就使用normal()方法正态分布给权值赋值,这里指定正态分布的均值=0,方差=0.01。同样,将偏置bias初始化为0。
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
3、定义正向传播过程forward()
(1)首先将训练样本x输入features中,也就是init()函数中定义的打包结构。然后将其进行展平处理flatten(),是使用第1维channel的(因为【batch,channel,width,height】,所以channel是第1维)。
展平之后我们将其丢进分类器classifier(),也就是3层全连接层中,输出的x就是最终的预测标签。
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
2.2 训练模型train.py
1、数据预处理+文件路径
(1)如果有GPU设备的话就选择第一块GPU,如果没有的话就用CPU。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
(2)数据预处理函数data_transform,RandomResizedCrop()函数为随机裁剪函数,将其裁剪到224 X 224的像素大小;RandomHorizontalFlip()函数表示在水平方向随机翻转;然后将其转换成Tensor张量;再进行Normalize()随机标准化处理。
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
(3)接下来data_root用来获取数据集的根目录,其中os.getcwd()表示当前目录,join拼接字符串,"…“表示返回上一层目录,”…/…"表示返回上上层目录。

然后train_dataset的目录位置就是image_path中的train文件夹,并按照这个标签使用transform()函数进行预处理。
data_root = os.path.abspath(os.path.join(os.getcwd(), "..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)

(4)根据train_dataset.class_to_idx可以根据分类的名字获得索引,即{‘daisy’:0, ‘dandelion’:1, ‘roses’:2, ‘sunflower’:3, ‘tulips’:4}。接下来将获取到的flower_list中的key和val反过来,放到cla_dict中。
然后使用json.dumps()方法将cla_dict字典进行编码,编码成json格式;接着打开class_indices.json文件,将上述类别及对应的index以json格式写入。
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
2、测试代码,查看数据
(5)使用DataLoader()函数进行加载后,我们跟之前一样,调用下面这段代码查看一下:
test_data_iter = iter(validate_loader)
test_image, test_label = test_data_iter.next()
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
imshow(utils.make_grid(test_image))
注意:将validate_loader中的batchsize改为4,shuffle改为True。
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=True,
num_workers=nw)
运行效果:
 3、训练准备
3、训练准备
(6)将(5)的代码注释,接下来使用Model.py中的AlexNet定义网络net,分类5种,初始化权重为True。使用net.to()方法加载GPU或CPU设备,然后定义损失函数及优化器,优化网络中所有参数,学习率lr=0.0002。
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
4、开始训练
将训练好的路径保存到’./AlexNet.pth’,将准确率保存在全局变量best_acc中。
在train训练过程中我们需要使用Dropout来随机失活一部分神经元,所以调用的是net.triain()方法;但在验证过程中我们不需要Dropout(),就用net.eval()关闭Dropout()方法。
save_path = './AlexNet.pth'
best_acc = 0.0
for epoch in range(10):
# train
net.train()
running_loss = 0.0
t1 = time.perf_counter()
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
print(time.perf_counter()-t1)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
(1)先讲train:
running_loss是用来统计训练过程的平均损失,time.perf_counter()-t1用来记录训练一个epoch需要的时间;在遍历过程中的步骤和之前的类似,然后增加了一个打印训练进度的代码。
# train
net.train() #在训练过程中需要Dropout方法 train()会开启它
running_loss = 0.0
t1 = time.perf_counter()
for step, data in enumerate(train_loader, start=0):
images, labels = data #将data中的图像和label分别取出来
optimizer.zero_grad() #将历史梯度清零
outputs = net(images.to(device)) #将图像(可以是用GPU处理后的)传入网络后得到的预测标签放到outputs中
loss = loss_function(outputs, labels.to(device)) #将实际标签与预测标签作为参数传入,统计损失
loss.backward() #将loss反向传播
optimizer.step() #更新每个节点的参数
# print statistics
running_loss += loss.item()
# print train process 打印训练进度
rate = (step + 1) / len(train_loader) #train_loader是训练一轮所需要的步数,step表示当前是第几步
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
print(time.perf_counter()-t1)#用来统计训练过程的平均损失
(2)再讲validate验证
将验证集的数据按图像、label放好,然后放到net()中得到预测标签,计算一下准确率,将最高准确率的路径存在save_path中。
# validate
net.eval() #在验证过程中不需要Dropout方法 eval()会关闭它
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data #将数据分别按照图像、label取出
outputs = net(val_images.to(device)) #将图像放到net中去,然后获得预测标签
predict_y = torch.max(outputs, dim=1)[1] #取出预测标签中最大的那个标签
acc += (predict_y == val_labels.to(device)).sum().item() #验证正确的样本个数
val_accurate = acc / val_num #acc是预测正确的样本个数,val_num表示样本总数
if val_accurate > best_acc:#更新准确率并保存该模型参数到save_path路径
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
开始训练,训练完成的结果:


2.2 预测图片predict.py
1、预测代码
(1)预处理函数data_transform: 改变图片大小为224*224,然后转为张量Tensor,再使用Normalize正则化。
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
(2)用PIL库载入这张要预测的图片,然后扩展batch这个维度;读取json文件。
img = Image.open("../tulip.jpg")
plt.imshow(img) #展示一下这张图片
img = data_transform(img) #将图片传入预处理函数转为Tensor [N, C, H, W]
# expand batch dimension
img = torch.unsqueeze(img, dim=0)#扩充batch这个维度 放到第0维
#读取json文件,也就是索引及类别对应的名称
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
(3)创建模型,下载模型权重后,将传入模型的图像用softmax()变成概率分布,然后argmax()获取概率最大处对应的索引值,打印其类别名称及预测概率。
# create model
model = AlexNet(num_classes=5)
# load model weights 下载模型权重
model_weight_path = "./AlexNet.pth"
model.load_state_dict(torch.load(model_weight_path)) #载入模型权重
model.eval() #关闭Dropout
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) #将已传入图像的模型压缩,将batch压缩掉
predict = torch.softmax(output, dim=0) #用softmax处理后变成一个概率分布
predict_cla = torch.argmax(predict).numpy() #argmax()获取概率最大处对应的索引值
print(class_indict[str(predict_cla)], predict[predict_cla].item()) #打印类别名称及预测概率
plt.show()
(4)下载好一张郁金香的图片,命名为tulip.jpg后存在Test02的平行目录下。右键运行predict.py文件:
