深度学习遥感图像语义分割&目标检测
深度学习遥感图像语义分割&目标检测
代码见github:
WangZhenqing-RS/2021Tianchi_RSgithub.com
图标
- 赛题描述
本赛题基于不同地形地貌的高分辨率遥感影像资料,希望参赛者能够利用遥感影像智能解译技术识别提取土地覆盖和利用类型,实现生态资产盘点、土地利用动态监测、水环境监测与评估、耕地数量与监测等应用。结合现有的地物分类实际需求,参照地理国情监测、“三调”等既有地物分类标准,设计陆域土地覆盖与利用类目体系,包括:林地、草地、耕地、水域、道路、城镇建设用地、农村建设用地,工业用地、构筑物、裸地。
训练数据(2.83GB)
测试A榜数据(530.17MB)
测试B榜数据(766.87MB)
测试B榜密码需要输入两次:第一次:MZwwrF4R第二次:opr9o9QPH
- 解决方案
我们采用Unet++进行实验。需要的软件版本如下。
库 版本
GDAL 3.1.4
segmentation-models-pytorch 0.1.3
torch 1.7.0+cu110
pytorch-toolbelt 0.4.1
2.1. 数据预处理
2.1.1. 统计各类的像素百分比
我们需要了解一下我们的数据中每个类的像素占比情况,对我们后续处理和分析有一定的帮助,运行程序为"code\count_classes.py"。 我们可以发现,各类别非常不均衡,所以我们需要进行少类别上采样以及选择合适的损失函数。
2.1.2. 分隔训练集和验证集
最初为了更加充分利用数据,采用五折交叉验证方式对模型进行训练。在分隔训练集和验证集时,我们在连续五个数据中取其中四份做训练数据,其中一份做验证数据。我们使用dataProcess.py文件中的split_train_val_old函数进行分隔。实验发现线上分数和线下分数差别很大,推测应该是测试集和训练集不同域,光谱差异较大。
为了模拟不同域,我们使用全部数据作为训练集,全部数据作为验证集,只不过训练集和验证集的增强方式不同。
2.1.3. 少类别上采样
我们对类别像素占比很少的类别进行上采样处理,抵抗不均衡现象。若图像包含类别5、6、7则上采样2份,类别3、8、10因为得分太低,采取放弃策略,类别4几乎每张影像都有,亦采取放弃策略。
upsample_num = 2
if ((5 in label) or
(6 in label) or
(7 in label)):
for up in range(upsample_num):
train_label_paths_upsample.append(train_label_path)
train_image_paths_upsample.append(train_image_paths[i])
2.1.4. 波段选取
我们使用了比赛提供的R/G/B/Nir波段。我们实验过增加归一化植被指数NDVI作为image的第5通道输入到网络中,但是效果不佳,故舍弃这一策略。因为选取了多波段,所以使用了gdal读取图像。
def imgread(fileName, addNDVI=False):
dataset = gdal.Open(fileName)
width = dataset.RasterXSize
height = dataset.RasterYSize
data = dataset.ReadAsArray(0, 0, width, height)
# 如果是image的话,因为label是单通道
if(len(data.shape) == 3):
# 添加归一化植被指数NDVI特征
if(addNDVI):
nir, r = data[3], data[0]
ndvi = (nir - r) / (nir + r + 0.00001) * 1.0
# 和其他波段保持统一,归到0-255,后面的totensor会/255统一归一化
# 统计了所有训练集ndvi的值,最小值为0,最大值很大但是数目很少,所以我们取了98%处的25
ndvi = (ndvi - 0) / (25 - 0) * 255
ndvi = np.clip(ndvi, 0, 255)
data_add_ndvi = np.zeros((5, 256, 256), np.uint8)
data_add_ndvi[0:4] = data
data_add_ndvi[4] = np.uint8(ndvi)
data = data_add_ndvi
# (C,H,W)->(H,W,C)
data = data.swapaxes(1, 0).swapaxes(1, 2)
return data
2.1.5. 数据增强
为增强模型泛化性,我们对训练数据增强策略采用了随机水平翻转、垂直翻转、对角翻转以及0.5%百分比线性拉伸。为模拟变域,我们对验证集数据进行了随机0.8%、1%、2%线性拉伸。
线性拉伸
def truncated_linear_stretch(image, truncated_value, max_out = 255, min_out = 0):
def gray_process(gray):
truncated_down = np.percentile(gray, truncated_value)
truncated_up = np.percentile(gray, 100 - truncated_value)
gray = (gray - truncated_down) / (truncated_up - truncated_down) * (max_out - min_out) + min_out
gray = np.clip(gray, min_out, max_out)
gray = np.uint8(gray)
return gray
image_stretch = []
for i in range(image.shape[2]):
# 只拉伸RGB
if(i<3):
gray = gray_process(image[:,:,i])
else:
gray = image[:,:,i]
image_stretch.append(gray)
image_stretch = np.array(image_stretch)
image_stretch = image_stretch.swapaxes(1, 0).swapaxes(1, 2)
return image_stretch
随机数据增强
image 图像
label 标签
def DataAugmentation(image, label, mode):
if(mode == "train"):
hor = random.choice([True, False])
if(hor):
# 图像水平翻转
image = np.flip(image, axis = 1)
label = np.flip(label, axis = 1)
ver = random.choice([True, False])
if(ver):
# 图像垂直翻转
image = np.flip(image, axis = 0)
label = np.flip(label, axis = 0)
stretch = random.choice([True, False])
if(stretch):
image = truncated_linear_stretch(image, 0.5)
if(mode == "val"):
stretch = random.choice([0.8, 1, 2])
# if(stretch == 'yes'):
# 0.5%线性拉伸
image = truncated_linear_stretch(image, stretch)
return image, label
2.2. 训练
2.2.1. 优化器
我们选择Adamw优化器,初始学习率lr=1e-4,权重衰减weight_decay=1e-3。
optimizer = torch.optim.AdamW(model.parameters(),
lr=1e-4, weight_decay=1e-3)
2.2.2. 学习率调整
在训练时梯度下降算法可能陷入局部最小值,此时可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。所以我们采用余弦退火策略调整学习率。T_0=2,T_mult=2,eta_min=1e-5。
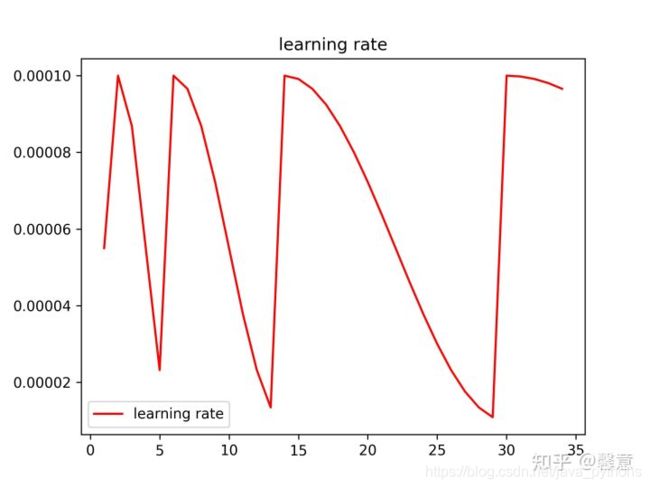
余弦退火调整学习率
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer,
T_0=2, # T_0就是初始restart的epoch数目
T_mult=2, # T_mult就是重启之后因子,即每个restart后,T_0 = T_0 * T_mult
eta_min=1e-5 # 最低学习率
)
2.2.3. 损失函数
软交叉熵函数是对标签值进行标签平滑之后再与预测值做交叉熵计算,可以在一定程度上提高泛化性。diceloss在一定程度上可以缓解类别不平衡,但是训练容易不稳定。我们采用软交叉熵函数和diceloss的联合函数作为实验的损失函数。
损失函数采用SoftCrossEntropyLoss+DiceLoss
diceloss在一定程度上可以缓解类别不平衡,但是训练容易不稳定
DiceLoss_fn=DiceLoss(mode='multiclass')
软交叉熵,即使用了标签平滑的交叉熵,会增加泛化性
SoftCrossEntropy_fn=SoftCrossEntropyLoss(smooth_factor=0.1)
loss_fn = L.JointLoss(first=DiceLoss_fn, second=SoftCrossEntropy_fn,
first_weight=0.5, second_weight=0.5).cuda()
我们测试了用LovaszLoss进行fine tune,但是最终结果变差了,故放弃。
2.2.4. SWA随机权重平均
我们测试了SWA随机权重平均策略来增强模型泛化性,pytorch官方的SWA学习率调整策略会导致模型精度不升反降,改为余弦退火策略,会使精度略微上升。
2.2.5. attention模块scSE
scSE是综合了通道维度和空间维度的注意力模块,可以增强有意义的特征,抑制无用特征,从而导致精度提升。
2.3. 预测
2.3.1. TTA测试增强
测试时对原图像、水平翻转图像、垂直翻转图像以及百分比截断增强图像的预测结果进行平均,得到TTA结果。
2.3.2. 模型融合
我们训练了不同backbone的unet++,对预测结果取平均,得到最终结果。
2.3.3. 后处理
我们试验了孔洞填充和小物体剔除,结果没有提升,故放弃。 我们NDVI修正结果,结果没有提升,故放弃。
- 参考
阿水233
引自https://zhuanlan.zhihu.com/p/354193558