1.triton镜像使用
1.tritonserver镜像使用
1)拉取镜像
# 为Triton的版本
docker pull nvcr.io/nvidia/tritonserver:22.06-py3
2)启动容器
指定模型仓库时可以执行server下的./fetch_model.sh,见2.2部分
GPU版本的启动
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v /home/zhouquanwei/workspace/triton/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:22.06-py3 tritonserver --model-repository=/modelsCPU版本的启动
docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v /home/zhouquanwei/workspace/triton/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:22.06-py3 tritonserver --model-repository=/models
区别只在于--gpus=1这个参数
注意:docker19.03之前的版本使用gpu要指定显卡硬件名,docker19.03之后的需要安装
nvidia-container-toolkit或nvidia-container-runtime
我的服务器是centos系统,我安装nvidia-container-toolkit,方式如下:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
sudo yum install -y nvidia-container-toolkit
安装之后要重启docker
systemctl restart docker
查看gpus参数是否安装成功
docker run --help | grep -i gpus
--gpus gpu-request GPU devices to add to the container ('all' to pass all GPUs)
重新执行我遇到了如下错误
![]()
先使用非GPU版本的
nvidia-docker2.0是一个简单的包,它主要通过修改docker的配置文件“/etc/docker/daemon.json”来让docker使用NVIDIA Container runtime。
执行成功之后

进入该容器的方式为
docker exec -it 8f89d733ff41 /opt/nvidia/nvidia_entrypoint.sh
3)验证是否启动成功
curl -v localhost:8000/v2/health/ready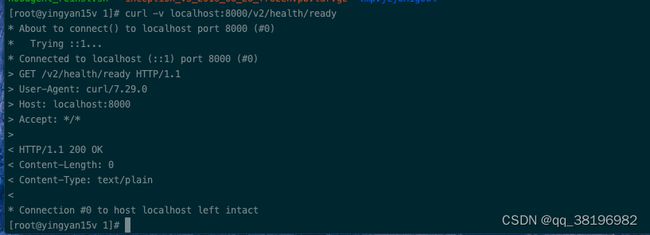
4)继续验证,发送一个请求
##拉取镜像
docker pull nvcr.io/nvidia/tritonserver:22.06-py3-sdk
##启动服务
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:22.06-py3-sdk
##发送请求
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.346230 (504) = COFFEE MUG
13.224326 (968) = CUP
10.422965 (505) = COFFEEPOT
注意
1)对于nvcr.io/nvidia/tritonserver:22.06-py3镜像,其容器内的/opt/tritonserver/bin目录下保存tritonserver的启动程序,使用
tritonserver --model-repository=/models
2)/opt/tritonserver目录下各个文件的含义
/opt/tritonserver/bin:tritonserver可执行文件
/opt/tritonserver/lib:存放共享库
/opt/tritonserver/backends:存放backends
/opt/tritonserver/repoagents:存放repoagents
2.编译tritonserver
Triton inference server 支持源码编译和容器编译两种方式
2.1源码编译
2.2容器编译
1)克隆triton inference server
cd /workspace/triton
git clone --recursive [email protected]:triton-inference-server/server.git
2)创建模型仓库
cd /workspace/triton/server/docs/examples
./fetch_models.sh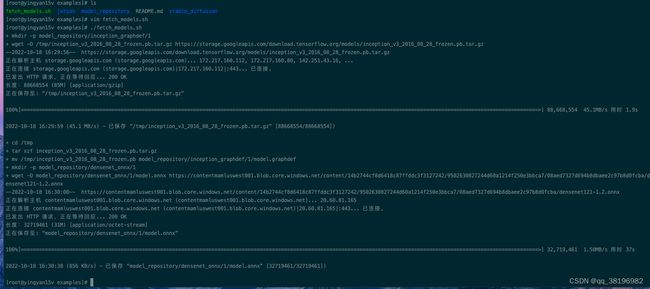
执行./fetch_models.sh脚本之后发现/workspace/triton/server/docs/examples/model_repository/densenet_onnx目录下多了一个1目录。
/tmp目录下多了一个inception_v3_2016_08_28_frozen.pb.tar.gz
3)编译,容器编译和源码编译
cd server
./build.py -v --enable-all