fast-reid跑通自己的数据
目录
1.一步一步跑通自己的额数据
2.遇到的报错
2.1 fastreid The size of tensor a (3) must match the size of tensor b (4) at non-singleton dimension 0
1.一步一步跑通自己的额数据
上一篇介绍了怎样搭建FastReID的环境和FastReID的一些报错处理,接下来介绍一步一步的跑通自己的数据;
首先进入configs目录,新建了一个文件夹,命名为‘suitcase’,然后加入‘AGW_R50.yml’;

AGW_R50.yml的内容如下:
_BASE_: ../Base-AGW.yml
DATASETS:
NAMES: ("IDLabeling_machine",)
TESTS: ("IDLabeling_machine300",)
OUTPUT_DIR: logs/Labeling_machine/agw_R50然后进入‘Base-AGW.yml’中修改参数设置:
_BASE_: Base-bagtricks.yml #Base-AGW的上一级配置文件
MODEL:
BACKBONE:
WITH_NL: True #模型是否使用No_local module
HEADS:
POOL_LAYER: GeneralizedMeanPooling # HEAD POOL_LAYERS
LOSSES:
NAME: ("CrossEntropyLoss", "TripletLoss") #使用loss
CE:
EPSILON: 0.1 #CrossEntropyLoss 超参
SCALE: 1.0
TRI:
MARGIN: 0.3 #0.0 #TripletLoss 超参数
HARD_MINING: True #False
SCALE: 1.0进入'Base-bagtricks.yml'中修改参数:
MODEL:
META_ARCHITECTURE: Baseline
BACKBONE:
NAME: build_resnet_backbone
NORM: BN #模型NORM 如果是多卡需要设置syncBN 多卡同步BN
DEPTH: 50x
LAST_STRIDE: 1
FEAT_DIM: 2048 #输出特征维度
WITH_IBN: True #False
PRETRAIN: True
PRETRAIN_PATH: './model/weihai-suitcase-reid/20211203-3/model/resnest50_1203.pth'
HEADS:
NAME: EmbeddingHead
NORM: BN #模型NORM 如果是多卡需要设置syncBN 多卡同步BN
WITH_BNNECK: True
POOL_LAYER: GeneralizedMeanPooling #GlobalAvgPool
NECK_FEAT: before
CLS_LAYER: Linear
LOSSES:
NAME: ("CrossEntropyLoss", "TripletLoss",)
CE:
EPSILON: 0.1
SCALE: 1.
TRI:
MARGIN: 0.3
HARD_MINING: True
NORM_FEAT: False
SCALE: 1.
INPUT:
SIZE_TRAIN: [ 256, 256 ] #[ 256, 128 ]
SIZE_TEST: [ 256, 256 ] #[ 256, 128 ]
REA:
ENABLED: True
PROB: 0.5
FLIP:
ENABLED: True
PADDING:
ENABLED: True
DATALOADER:
SAMPLER_TRAIN: NaiveIdentitySampler
NUM_INSTANCE: 4
NUM_WORKERS: 8
SOLVER:
AMP:
ENABLED: True
OPT: Adam
MAX_EPOCH: 200 #120
BASE_LR: 0.0005 #0.00035
WEIGHT_DECAY: 0.0005
WEIGHT_DECAY_NORM: 0.0005
IMS_PER_BATCH: 128 #64 #设置batch size
SCHED: CosineAnnealingLR #MultiStepLR
STEPS: [ 40, 90 ]
GAMMA: 0.1
WARMUP_FACTOR: 0.1
WARMUP_ITERS: 2000
CHECKPOINT_PERIOD: 30
TEST:
EVAL_PERIOD: 30
IMS_PER_BATCH: 256 #128
CUDNN_BENCHMARK: True
其中目前包含的数据增强方式:
INPUT:
SIZE_TRAIN: [ 256, 256 ] #[ 256, 128 ]
SIZE_TEST: [ 256, 256 ] #[ 256, 128 ]
REA:
ENABLED: True
PROB: 0.5
FLIP:
ENABLED: True
CROP:
ENABLED: True
AFFINE:
ENABLED: True
AUTOAUG:
ENABLED: True
PROB: 0.2
CJ:
ENABLED: True
PROB:0.5
# AUGMIX:
# ENABLED: False
# PROB: 0.2
# RPT:
# ENABLED: False
# PROB: 0.2
# PADDING:
# ENABLED: False然后加入自己的数据处理代码:
同时在__init__.py中加入函数类,方便调用:
from .suitcase import IDLabeling_machine, IDLabeling_machine300
其中‘suitcase.py’代码中加入函数类:
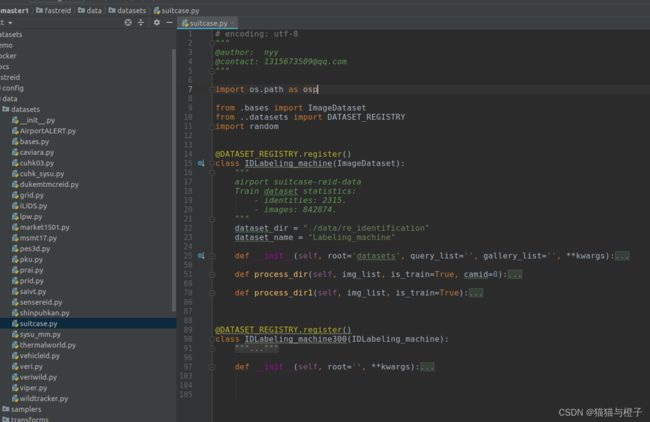
这里的具体代码可以参考同一级目录下的数据处理代码来编码;
2.遇到的报错
2.1 fastreid The size of tensor a (3) must match the size of tensor b (4) at non-singleton dimension 0
报错原因是:收集训练样本的时候混入了使用快捷键裁剪的图片(后缀有*.png);
处理方法:使用opencv读取这类图片,重新保存为后缀为*.jpg的图片;
参考:How to train Custom Dataset · Issue #220 · JDAI-CV/fast-reid · GitHub
If yes, please check that if images in your dataset had alpha channel? And then remove the alpha channel, only keep B,G,R channels.