「论文阅读」Point Transformer(ICCV_2021_paper_Zhao)
目录
背景
Point Transformer Layer
Position Encoding
Point Transformer Block
Network Architecture
Transition down
Transition up
Output head
作者提出,Transformer模型特别适合于点云处理,因为自注意力是Transformer的核心,本质上是一个集合算子:它对输入元素具有顺序不变性和数量不变性,因此,将自注意力机制用于点云是自然而然的,因为点云本质上是嵌入在3D空间的集合。
我们将这种直觉具体化,并开发了一个用于3D点云处理的自注意层。
该文章的主要贡献在于:
1.为点云处理设计了一个表达能力非常强的Point Transformer Layer。该层具有顺序不变性和数量不变性,因此天生适合点云处理。
2.在Point Transformer Layer的基础上,构建了高性能的Point Transformer networks,用于点云的分类和密集预测(dense prediction,为什么要预测密度呢?没懂)。这些网络可以作为3D场景理解的一般骨干。
3.我们在多个领域和数据集上进行了实验,并选出了模型设计中的一些最优实现,实验结果超过之前的工作。
作者说道:自注意力本质上是一个集合操作符:位置信息作为元素的属性提供,这些元素被作为集合处理。由于3D点云本质上是具有位置属性的点集,因此自注意机制似乎特别适合于这类数据。
另外,证明了位置编码在大尺度点云点云理解中的重要性。
首先,简要回顾一下Transformer和Self-Attention的一般公式;然后提出用于三维点云处理的point transformer layer;最后,我们提出了用于3D场景理解的网络架构。
背景
作者说自注意力算子可分为两类:scalar attention和vector attention,前者就是最原始的《Attention is all you need》论文中的,而后者是作者自己的论文《Exploring self-attention for image recognition》里面的;本文使用的注意力计算方式是后者的vector attention方式。
先来看一下标准的标量点积自注意力:定义X={Xi}i是特征向量的集合,标量点积注意力层可以表示为:
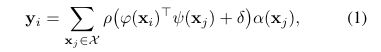
其中yi是输出特征,φ,ψ和α是点对特征变换,例如可以是Linear层或者MLP层。
δ是一个位置编码函数,而ρ是一个归一化函数,本文使用的是saftmax归一化。
标量注意层计算经过了φ和ψ变换后的特征之间的标量积(即注意力的分数图),并将其作为对α变换后的特征的注意力权重。
而在矢量注意力(即本文所使用的注意力计算方式)中,算出来的注意力权重不是一个标量而是一个向量,这个向量是可以调节单个特征通道的。
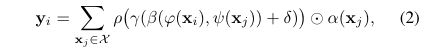
其中β是一个关系函数(如减法),γ是一个映射函数(如一个MLP),它产生用于特征聚合的注意向量。
Point Transformer Layer
自注意天然地适合点云,因为点云本质上是不规则嵌入度量空间的集合。我们的Point Transformer Layer是基于矢量自注意的。
我们利用减法关系,而且将位置编码δ既加到前面的式子,又加到后面的式子上:
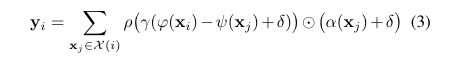
其中X(i)⊆xi是中心点xi的近邻点集(使用的是KNN搜索算法),(这里原文说的不是很清楚,但从式子中分析,可以看出是对每个邻居点xj计算与xi的注意力分数,然后将所有的输出结果相加,得到中心点xi的特征表示向量yi)。
另外,γ是一个具有两个线性层和一个ReLU层的非线性MLP。
Θ意思是哈达玛积,计算方法如下:

Position Encoding
位置编码对自注意起着重要作用,使算子能够适应数据中的局部结构。
在三维点云处理中,三维点坐标本身是位置编码的自然候选。我们通过引入可训练的参数化的位置编码。
我们的位置编码函数δ定义如下:
![]()
其中pi和pj是点i和点j的三维空间坐标,θ是一个具有两个线性层和一个ReLU层的非线性MLP。
值得注意的是,作者发现位置编码δ对于注意产生分支和特征转换分支都很重要。因此,如式3所见,在两个分支中都加入了δ。
位置编码θ是与其他子层在一起进行端到端训练出来的。
Point Transformer Block
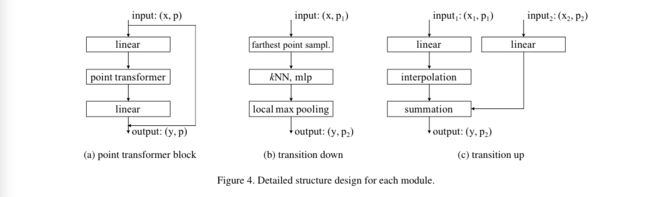
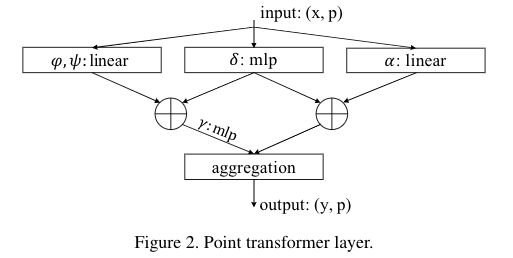
作者构造了一个以Point Transformer Layer为核心的residual point transformer block,如图4(a)所示:
该Transformer Block集成了self-attention layer、linear projections(原文说:可以降低纬度和加速处理?)、 a residual connection。
(该句原文:The transformer block integrates the self-attention layer,linear projections that can reduce dimensionality and accelerate processing, and a residual connection,没懂这两个linear是怎么个作用,降低维度已经有了transition down模块了呀?)
输入是一组特征向量x和对应的点坐标p,Point Transformer Block促进了这些局部特征向量之间的信息交换,为所有数据点生成新的特征向量作为输出。
信息聚合兼顾了特征向量的内容和其在3D空间中的分布。(没懂,原文是:The information aggregation adapts both to the content of the feature vectors and their layout in 3D.初步理解是图2中的aggregation实现了既使特征向量兼顾了点的特征表达和点的空间位置表示的功能?)
Network Architecture
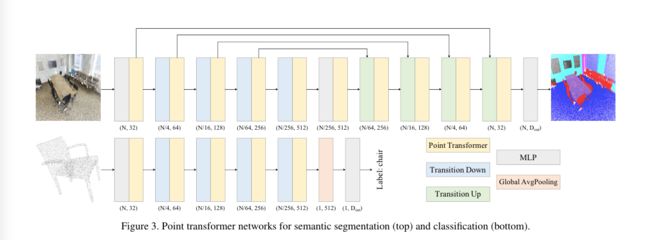
Point Transformer Networks,上边是语义分割网络,下面是分类网络。
基于 point transformer block,构建了完整的三维点云理解网络。
point transformer是整个网络的主要特征聚合算子。我们不使用卷积来进行预处理或辅助分支:网络完全基于 point transformer layers、pointwise transformations和pooling。网络架构如图3所示。
在Point Transformer Networks中,用于语义分割和分类的特征编码器(feature encoder)有五个阶段,作用于逐渐下降的采样点集。
每一阶段的下采样率为[1,4,4,4,4],因此每一阶段产生的点集为输入点集的[N, N/4, N/16, N/64, N/256],其中N为输入点个数。
过渡阶段由transition modules连接:transition down对特征进行编码,transition up对特征进行解码。
Transition down
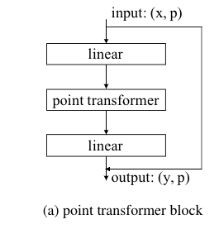
该模块的一个关键功能是根据需要从点集中减少点的数量。
用P1表示该模块的输入点集,P2为输出点集。在P1中执行最远点采样(FPS),采样出所要的数量好良好分布的子点集P2,P2⊂p1。为了将特征向量从P1集中到P2上,在P1中采用KNN算法(k始终取值为16)找出P2点集中每个点的K个邻居,对这k个邻居的每个点的特征向量经过一个线性变换,再经过batch normalization和RELU,再经过最大池化将特征汇集到他们的P2点集中对应的中心点上。如下图所示(图4b):
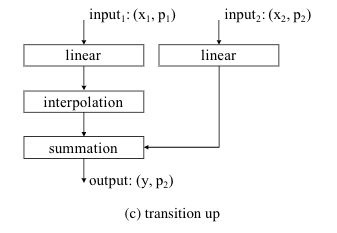
Transition up
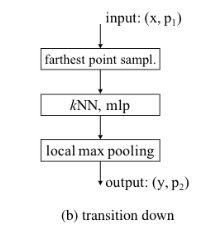
对于语义分割这类密集的预测任务,我们采用U-Net那样的设计,编码器和解码器对称相连。
解码器中的过渡模块是transition up,它的主要功能是将特征从子集P2映射回超集P1当中。为此,每个输入特征先经过一个线性层,再batch normalization,再ReLU,最后将特征通过三线性插值的方式映射到高分辨率上的P1点集上。这些由前一个解码器阶段插值来的特征对与之对应的编码器阶段的特征进行了总结(通过一个跳连接)。
如图4c:
Output head
对于语义分割,最终的解码器为输入点集合中的每个点生成一个特征向量。
对于分类,对于分类,我们对逐点特征进行全局平均池化,以得到整个点集的全局特征向量。
备注:
Point Transformer Layer的解释:
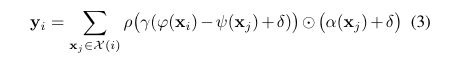
φ(xi):把中心点的特征向量xi送到Query里面。
ψ(xj):把每个邻居点的特征向量xj送到Key里面。
φ(xi)−ψ(xj):计算中心点和邻居点的关系,类比于原始自注意力中的QK的点乘,只不过这里换成了减法。将就着理解吧。
γ(φ(xi)−ψ(xj)+δ):γ()是一个MLP,将分数图经过一个MLP之后,得到中心点和邻居的权重。
ρ(γ(φ(xi)−ψ(xj)+δ)):将γ(φ(xi)−ψ(xj)+δ)权重分数图进行Softmax归一化。
α(xj):把每个邻居点的特征向量xj送到Value里面。
最后输出这个点的包含邻居关系的特征向量yi。
对点云中的每个点都做这么一套操作,即每个点都有特征向量yi,包含和邻居的关系的向量表示。
(注意xi和xj是点的特征向量,而不是坐标点xyz)