Python练习
python练习
- 1 基本数据类型
-
- 1.1 jmu-python-求圆面积
- 1.2 jmu-python-输入输出-计算字符串中的数
- 1.3 Py的A+B
- 1.4 计算M和N的多个结果
- 1.5 jmu-python-是否偶数
- 1.6 计算逆序的四位数
- 2 输入输出
-
- 2.1 jmu-python-输入输出-格式化输出字符串
- 2.2 删除字符
- 2.3 jmu-python-统计字符个数
- 2.4 统计字符串中指定字符的个数
- 3 列表
-
- 3.1 jmu-python-逆序输出
- 3.2 计算各对应位乘积之和
- 3.3 大于身高的平均值
- 3.4 身份证校验_python
- 3.5 列表去重
- 3.6 裁判打分
- 3.7 人民币与美元汇率兑换程序
- 4 元组字典集合
-
- 4.1 求出歌手的得分
- 4.2 输出字母在字符串中位置索引
- 4.3 字典合并
- 4.4 通过两个列表构建字典
- 4.5 jmu-python-重复元素判定
- 4.6 求集合的最大值和最小值
- 5 平时实验题目
-
- 5.1 判断一个三位数是否是水仙花数
- 5.2找出三位水仙花数
- 5.3jmu-python-凯撒密码加密算法
- 5.4凯撒加密(含汉字)
- 5.5根据用户的输入,输出课程表
- 5.6蒙特卡洛方法求圆周率
- 5.7模拟乒乓球比赛
- 5.8今天是本学期的第几周的第几天?
- 6 Python-练习6-函数
-
- 6.1 jmu-python-组合数据类型-1.计算坐标点欧氏距离
- 6.2 jmu-python-函数-找钱
- 6.3 jmu-java&python-统计字符个数
- 6.4 缩写词
- 7 函数2
-
- 7.1 凯撒加密解密
- 7.2 凯撒加密的破解
- 7.3 编写函数求短语的缩写词
- 7.4 修改句子
- 7.5 汉诺塔问题
1 基本数据类型
1.1 jmu-python-求圆面积
输入一个数值表示圆的半径,求相应圆的面积。圆周率要求使用math库中的pi常量。
输入格式:
输入数值型数据,例如:1.5
输出格式:
输出圆面积,要求小数点后保留两位,例如:7.07
输入样例:
在这里给出一组输入。例如:
1.5
输出样例:
在这里给出相应的输出。例如:
7.07
import math
r=float(input())
a=math.pi*r**2
print("{:.2f}".format(a))
1.2 jmu-python-输入输出-计算字符串中的数
将字符串中的每个数都抽取出来,然后统计所有数的个数并求和。
输入格式:
一行字符串,字符串中的数之间用1个空格或者多个空格分隔。
输出格式:
第1行:输出数的个数。
第2行:求和的结果,保留3位小数。
输入样例:
2.1234 2.1 3 4 5 6
输出样例:
6 22.223
s = input()
num = s.split()
sum=0
for i in num:
sum += float(i)
print(len(num))
print("{:.3f}".format(sum))
1.3 Py的A+B
程序会读入两行,每行都是一个数字,输出这两个数字的和
输入格式:
两行文字,每行都是一个数字
输出格式:
一行数字
输入样例:
18 21
输出样例:
39
a = int(input())
b = int(input())
sum = a + b
print(sum)
1.4 计算M和N的多个结果
用户输入两个数M和N(用两个input语句输入),其中N是整数,计算M和N的5种数学运算结果,并依次输出,结果间用空格分隔。
5种数学运算分别是:
M与N的和、M与N的乘积、M的N次幂、M除N的余数、M和N中较大的值
输入格式:
输入M和N的值
输出格式:
M与N的和 M与N的乘积 M的N次幂 M除N的余数 M和N中较大的值
输入样例:
在这里给出一组输入。例如:
10 2
输出样例:
在这里给出相应的输出。例如:
12 20 100 0 10
M=eval(input())
N=eval(input())
print(M+N,M*N,M**N,M%N,max(M,N))
1.5 jmu-python-是否偶数
输入一个整数,判断是否偶数
输入样例:
7
输出样例:
7不是偶数
输入样例:
8
输出样例:
8是偶数
num = int(input())
m = num % 2
if m == 0:
print("{}是偶数".format(num))
else:
print("{}不是偶数".format(num))
1.6 计算逆序的四位数
四位数(假设输入必定是四位数,并且最后一位不为0)。
输出格式:
输出一个四位数。
输入样例:
在这里给出一组输入。例如:
1234
输出样例:
在这里给出相应的输出。例如:
4321
num = int(input())
q = int(num / 1000)
b = int(num /100 % 10)
s = int(num /10 % 10 % 10)
g = int(num % 10 %10 % 10 %10)
n = g*1000+s*100+b*10+q
print(n)
2 输入输出
2.1 jmu-python-输入输出-格式化输出字符串
输入3行字符串,然后对其按照说明进行格式化输出
输入格式:
第1行:一个浮点数字符串
第2行:一个整数字符串
第3行:一个非数值型字符串
输出格式:
对浮点数字符串:
第1行: 保留2位小数输出
第2行: 分别输出浮点数的小写字母e的指数形式,大写字母e的指数形式, 百分数形式且其小数部分为2位。每个输出的元素之间以一个空格分隔。
对于整数:
第3行:在一行分别输出其二进制与小写十六进制,之间以一个空格分隔。
对非数值型字符串:
首先,去除掉字符串得左右空格。然后输出3行:
第4行,将全部字符转化为大写并输出。
第5行,将字符串右对齐输出,宽度为20。
第6行,将字符串居中输出,宽度20,两侧使用*填充。
最后:
第7行,将浮点数与整数以浮点数 + 整数 = 结果的形式输出
输入样例:
3.14159265 10 abc 123
输出样例:
3.14 3.141593e+00 3.141593E+00 314.16% 1010 a ABC 123 abc 123 ******abc 123******* 3.14159265 + 10 = 13.14159265
a = eval(input())
b = int(input())
c = input()
print("{:.2f}".format(a))
print("{:e} {:E} {:.2%}".format(a,a,a))
print("{0:b} {0:x}".format(b,b))
c = c.strip()
print(c.upper())
print("{:>20}".format(c))
print("{:*^20}".format(c))
print("{} + {} = {}".format(a,b,a+b))
2.2 删除字符
输入一个字符串 str,再输入要删除字符 c,大小写不区分,将字符串 str 中出现的所有字符 c 删除。提示:去掉两端的空格。
输入格式:
在第一行中输入一行字符
在第二行输入待删除的字符
输出格式:
在一行中输出删除后的字符串
输入样例1:
在这里给出一组输入。例如:
Bee E
输出样例1:
在这里给出相应的输出。例如:
result: B
输入样例2:
在这里给出一组输入。例如:
7!jdk*!ASyu !
输出样例2:
在这里给出相应的输出。例如:
result: 7jdk*ASyu
str = input()
c = input()
str = str.strip()
c = c.strip()
str = str.strip(c.upper()).strip(c.lower()).replace(c,'')
print("result:",str)
2.3 jmu-python-统计字符个数
输入一个字符串,统计其中数字字符及小写字符的个数
输入格式:
输入一行字符串
输出格式:
共有?个数字,?个小写字符,?填入对应数量
输入样例:
helo134ss12
输出样例:
共有5个数字,6个小写字符
s = input()
n = 0
l = 0
for c in s:
if c.islower():
l += 1
if c.isdigit():
n += 1
print("共有{}个数字,{}个小写字符".format(n,l))
2.4 统计字符串中指定字符的个数
输入一个字符串和一个字符,统计这个字符在字符串中出现的次数
输入格式:
输入2行。第1行是字符串,第2行是要查找的字符。
输出格式:
字符出现的次数
输入样例:
abcdefgabcdefg a
输出样例:
2
s = input()
c = input()
n=0
for i in s:
if i==c:
n += 1
print(n)
3 列表
3.1 jmu-python-逆序输出
输入一行字符串,然后对其进行如下处理。
输入格式:
字符串中的元素以空格或者多个空格分隔。
输出格式:
逆序输出字符串中的所有元素。
然后输出原列表。
然后逆序输出原列表每个元素,中间以1个空格分隔。注意:最后一个元素后面不能有空格。
输入样例:
a b c e f gh
输出样例:
ghfecba ['a', 'b', 'c', 'e', 'f', 'gh'] gh f e c b a
s = input().split()
t = s[:]
s.reverse()
print(''.join(s))
print(t)
print(' '.join(s))
3.2 计算各对应位乘积之和
读入两个整数a和b,输出绝对值a和绝对值b的各对应位乘积之和,如a=1234,b=608,则输出值为:“1×0+2×6+3×0+4×8“的值,即44。
输入格式:
在一行中输入两个数
输出格式:
在一行中输出对应位乘积之和
输入样例:
在这里给出一组输入。例如:
1234 608
输出样例:
在这里给出相应的输出。例如:
44
a,b = map(int,input().split())
a = abs(a)
b = abs(b)
if a != 0 and b != 0:
a1 = a // 1000
a2 = a // 100 %10
a3 = a //10 % 10 % 10
a4 = a % 10 % 10 % 10
b1 = b // 1000
b2 = b // 100 %10
b3 = b //10 % 10 % 10
b4 = b % 10 % 10 % 10
s = int(a1) * int(b1) + int(a2) * int(b2) + int(a3) * int(b3) + int(a4) * int(b4)
else:
s = 0
print(s)
3.3 大于身高的平均值
中小学生每个学期都要体检,要量身高,因为身高可以反映孩子的生长状况。现在,一个班的身高已经量好了,请输出其中超过平均身高的那些身高。程序的输入为一行数据,其中以空格分隔,每个数据都是一个正整数。程序要输出那些超过输入的正整数的平均数的输入值,每个数后面有一个空格,输出的顺序和输入的相同。
输入格式:
在一行输入中一个班的身高值,以空格分隔。
输出格式:
在一行输出超过输入的平均数的输入值,以空格分隔。
输入样例:
在这里给出一组输入。例如:
143 174 119 127 117 164 110 128
输出样例:
在这里给出相应的输出。例如:
143 174 164
h = list(map(int,input().split()))
count = len(h)
avg = int(sum(h)/count)
for i in range(len(h)):
if h[i] > avg:
print(h[i],end=' ')
3.4 身份证校验_python
中国居民身份证校验码算法如下:
将身份证号码前面的17位数分别乘以不同的系数。从第一位到第十七位的系数分别为:7-9-10-5-8-4-2-1-6-3-7-9-10-5-8-4-2。
将这17位数字和系数相乘的结果相加。用加出来和除以11,取余数。
余数只可能有0-1-2-3-4-5-6-7-8-9-10这11个数字, 其分别对应的最后一位身份证的号码为1-0-X-9-8-7-6-5-4-3-2。余数和校验码的对应关系可以用公式:m=(12-n) mod 11计算,其中mod为求余运算,m为校验码,n为之前计算出来的余数。如果之前计算出的余数是3,第18位的校验码就是9。如果余数是2那么对应的校验码就是X,X实际是罗马数字10。
例如:某男性的身份证号码为【53010219200508011x】, 我们看看这个身份证是不是合法的身份证。首先我们得出前17位的乘积和【(57)+(39)+(010)+(15)+(08)+(24)+(12)+(91)+(26)+(03)+(07)+(59)+(010)+(85)+(08)+(14)+(1*2)】是189,然后用189除以11得出的结果是189/11=17----2,也就是说其余数是2。最后通过对应规则就可以知道余数2对应的检验码是X。所以,可以判定这是一个正确的身份证号码。
请编写一个程序,输入身份证前17位后,计算并输出最后的校验码,
输入格式:
前17位的每个数字分别输入,中间用空格间隔
输出格式:
输出校验码,如果校验码是10,不必转成X
输入样例:
5 3 0 1 0 2 1 9 2 0 0 5 0 8 0 1 1
输出样例:
10
idd = list(map(int,input().split()))
iddd = [7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2]
M = ['1','0','X','9','8','7','6','5','4','3','2']
sum = 0
for i in range(0,17):
sum += idd[i]*iddd[i]
n = sum % 11
m = (12 - n) % 11
print(m)
3.5 列表去重
输入一个列表,去掉列表中重复的数字,按原来次序输出!
输入格式:
在一行中输入列表
输出格式:
在一行中输出不重复列表元素
输入样例:
在这里给出一组输入。例如:
[4,7,5,6,8,6,9,5]
输出样例:
在这里给出相应的输出。例如:
4 7 5 6 8 9
l = eval(input())
li = list(set(l))
li.sort(key = l.index)
print(*li,sep=' ')
3.6 裁判打分
体操比赛中,评委会给参赛选手打分。选手得分规则为去掉一个最高分和一个最低分,然后计算平均得分,请编程输出某选手的得分。
输入格式:
第1行包含一个整数n (2
输出格式:
输出选手的得分,结果保留2位小数。
输入样例:
4 100 99 98 97
输出样例:
98.50
n = int(input())
num = list(map(int,input().split()))
if n > 2 and n < 100:
if len(num) == n:
num.sort()
num.remove(max(num))
num.remove(min(num))
print("{:.2f}".format(sum(num)/float(len(num))))
3.7 人民币与美元汇率兑换程序
设计人民币与美元汇率兑换程序,按照1美元=7人民币的汇率 编写一个双向兑换程序。
输入格式:
输入美元或者人民币的金额,币种在前,金额在后,如:$20、¥100。每次输入一个金额。
输出格式:
输出经过汇率计算的美元或人民币的金额,格式与输入一样,结果保留两位小数。
输入样例1:
$20
输出样例1:
¥140.00
输入样例2:
¥100
输出样例2:
$14.29
输入样例3:
#120
输出样例3:
输入格式错误
m = list(input())
t = ''
if m[0] == '$':
del m[0]
for i in m:
t += i
money = float(t)
rmb = money * 7
print("{}{:.2f}".format('¥',rmb))
elif m[0] == '¥':
del m[0]
for i in m:
t += i
money = float(t)
dollar = money / 7
print("{}{:.2f}".format('$',dollar))
else:
print("输入格式错误")
4 元组字典集合
4.1 求出歌手的得分
输入一个正整数n (n>4),再输入n个实数,求出歌手的得分(保留2位小数)。设一歌唱评奖晚会上有n(n>4)个评委为歌手打分.评分规则:每个评委依次打分,再去掉2个最高分和2个最低分,计算余下的分数平均值为歌手的得分.
输入格式:
在第一行中输入n
在第二行中输入n个分数
输出格式:
在一行中输出平均分数
输入样例:
在这里给出一组输入。例如:
10 10 10 9 9 9 8 8 8 7 7
输出样例:
在这里给出相应的输出。例如:
aver=8.50
n = int(input())
s = list(map(int,input().split()))
s.sort()
s[:2] = []
s[-2:] = []
summ = sum(s)
lenn = len(s)
print("aver={:.2f}".format(summ/lenn))
4.2 输出字母在字符串中位置索引
输入一个字符串,再输入两个字符,求这两个字符在字符串中的索引。
输入格式:
第一行输入字符串
第二行输入两个字符,用空格分开。
输出格式:
从右向左输出字符和索引,即下标最大的字符最先输出。每行一个。
输入样例:
在这里给出一组输入。例如:
pmispsissippi s p
输出样例:
在这里给出相应的输出。例如:
11 p 10 p 8 s 7 s 5 s 4 p 3 s 0 p
strr = input()
a,b = map(str,input().split())
strr = strr[::-1]
for i in range(0,len(strr)):
if strr[i] == a:
print("{0} {1}".format(len(strr)-i-1,a))
if strr[i] == b:
print("{0} {1}".format(len(strr)-i-1,b))
4.3 字典合并
输入用字符串表示两个字典,输出合并后的字典。字典的键用一个字母或数字表示。注意:1和‘1’是不同的关键字!
输入格式:
在第一行中输入第一个字典字符串;
在第二行中输入第二个字典字符串。
输出格式:
在一行中输出合并的字典,输出按字典序。
“1” 的 ASCII 码为 49,大于 1,排序时 1 在前,“1” 在后。其它的字符同理。
输入样例1:
在这里给出一组输入。例如:
{1:3,2:5} {1:5,3:7}
输出样例1:
在这里给出相应的输出。例如:
{1:8,2:5,3:7}
输入样例2:
在这里给出一组输入。例如:
{"1":3,1:4} {"a":5,"1":6}
输出样例2:
在这里给出相应的输出。例如:
{1:4,"1":9,"a":5}
a=eval(input())
b=eval(input())
d={}
for i in a:
d[i]=a[i]+b.get(i,0)
for i in b:
if i not in d.keys():
d[i]=b[i]
d=str(dict(sorted(d.items(),key=lambda x:x[0] if type(x[0])==int else ord(x[0]))))
d=d.replace(' ','')
d=d.replace("'",'"')
print(d)
4.4 通过两个列表构建字典
输入两行字符串,以空格为分隔,将每行字符串存储为列表形式。将第一个列表的元素值作为键,将第二个列表中对应顺序的元素作为值,构建一个字典,按键升序排列后输出字典的所有键值对列表。
输入格式:
输入两行字符串,分别以空格为分隔存为列表。
输出格式:
按键的升序,输出字典键值对列表。
输入样例:
学校 城市 邮编 集美大学 厦门 361021
输出样例:
[('城市', '厦门'), ('学校', '集美大学'), ('邮编', '361021')]
a = input().split()
b = input().split()
d = dict(zip(a,b))
l = sorted(list(d.items()))
print(l)
4.5 jmu-python-重复元素判定
每一个列表中只要有一个元素出现两次,那么该列表即被判定为包含重复元素。
编写函数判定列表中是否包含重复元素,如果包含返回True,否则返回False。
然后使用该函数对n行字符串进行处理。最后统计包含重复元素的行数与不包含重复元素的行数。
输入格式:
输入n,代表接下来要输入n行字符串。
然后输入n行字符串,字符串之间的元素以空格相分隔。
输出格式:
True=包含重复元素的行数, False=不包含重复元素的行数
,后面有空格。
输入样例:
5 1 2 3 4 5 1 3 2 5 4 1 2 3 6 1 1 2 3 2 1 1 1 1 1 1
输出样例:
True=3, False=2
n = eval(input())
t = 0
f = 0
for i in range(n):
s = list(input().split())
if len(list(set(s))) == len(s):
f += 1
else:
t += 1
print("True={}, False={}".format(t,f))
4.6 求集合的最大值和最小值
已知集合A包含5个元素,分别是21, 234,-32,3,-55,请编程实现以下功能:
- 输出集合A
- 输出集合A中的最大值
- 输出集合A中的最小值
输入格式:
无
输出格式:
集合A
集合A的最大值
集合A的最小值
输入样例:
无
输出样例:
{-32, 3, -55, 234, 21} 234 -55
s = {-32, 3, -55, 234, 21}
print(s)
print(max(s))
print(min(s))
5 平时实验题目
5.1 判断一个三位数是否是水仙花数
输入一个整数,判断它是不是水仙花数,水仙花数是一个三位整数,其每位数字的立方和等于其本身,
例如,153是一个水仙花数,153=1×1×1+5×5×5+3×3×3
输入格式:
输入一个整数,代表判断的数字
输出格式:
如果该数是水仙花数,则输出:yes
如果该数不是水仙花数,则输出:no
如果该数不是一个三位数,输出:error
输入样例1:
153
输出样例1:
yes
输入样例2:
258
输出样例2:
no
输入样例3:
15
输出样例3:
error
num = int(input())
b = int(num / 100)
s = int(num / 10 % 10)
g = int(num % 10 % 10 % 10)
if num <= 99 or num >= 1000:
print("error")
elif b**3+s**3+g**3==num:
print("yes")
else:
print("no")
5.2找出三位水仙花数
本题要求编写程序,输出给定正整数M和N区间内的所有三位水仙花数。三位水仙花数,即其个位、十位、百位数字的立方和等于该数本身。
输入格式:
输入在一行中给出两个正整数M和N(100≤M≤N≤999)。
输出格式:
顺序输出M和N区间内所有三位水仙花数,每一行输出一个数。若该区间内没有三位水仙花数,则无输出。
如果M或者N不符合题目的要求,则输出Invalid Value.。
输入样例1:
100 400
输出样例1:
153 370 371
输入样例2:
500 600
输出样例2:
输入样例3:
990 101
输出样例3:
Invalid Value.
num = list(map(int,input().split()))
m = num[0]
n = num[1]
if m <= n and m >=100 and n <= 999:
for i in range(m,n+1):
b = int(i / 100)
s = int(i / 10 % 10)
g = int(i % 10 % 10 % 10)
if b ** 3 + s ** 3 + g ** 3 == i:
print(i)
else:
print("Invalid Value.")
5.3jmu-python-凯撒密码加密算法
编写一个凯撒密码加密程序,接收用户输入的文本和密钥k,对明文中的字母a-z和字母A-Z替换为其后第k个字母。
输入格式:
接收两行输入,第一行为待加密的明文,第二行为密钥k。
输出格式:
输出加密后的密文。
输入样例:
在这里给出一组输入。例如:
Hello World! 3
输出样例:
在这里给出相应的输出。例如:
Khoor Zruog!
s = input()
k = int(input())
f = ''
for i in s:
if ord('a') <= ord(i) <= ord('z'):
f = f + chr((ord(i) - ord('a') + k) % 26 + ord('a'))
elif ord('A') <= ord(i) <= ord('Z'):
f = f + chr((ord(i) - ord('A') + k) % 26 + ord('A'))
else:
f += i
print(f)
5.4凯撒加密(含汉字)
凯撒密码是古罗马凯撒大帝用来对军事情报进行加密的算法,它采用了替换方法对信息中的每一个字符循环替换为该字符后面第n个字符,如替换为第三个字符的对应对应关系如下:
原文:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
密文:D E F G H I J K L M N O P Q R S T U V W X Y Z A B C
请输入原文和整数n
将原文替换为为该字符后面第n个字符
如果此字符不包含在大写英文字符、小写英文字符和基本汉字字符集中,则原样输出
输入格式:
hello
4
输出格式:
ifmmp
输入样例:
在这里给出一组输入。例如:
hello 4
输出样例:
在这里给出相应的输出。例如:
lipps
s = input()
n = int(input())
f = ''
for i in s:
if ord('a') <= ord(i) <= ord('z'):
f = f + chr((ord(i) - ord('a') + n) % 26 + ord('a'))
elif ord('A') <= ord(i) <= ord('Z'):
f = f + chr((ord(i) - ord('A') + n) % 26 + ord('A'))
elif 0x4E00 <= ord(i) <= 0x9FA5:
f = f + chr((ord(i) - 0x4E00 + n) % 20902 + 0x4E00)
else:
f += i
print(f)
5.5根据用户的输入,输出课程表
请按照用户的输入,按照格式输出课程表。
输入格式:
输入周一到周五的课程,每天的课程占一行,课程名称之间用空格分隔
输出格式:
按照课程表格式输出
输入样例:
数学 语文 英语 体育 语文 数学 英语 体育 英语 语文 数学 体育 音乐 语文 英语 体育 美术 语文 英语 体育
输出样例:
周一 周二 周三 周四 周五 数学 语文 英语 音乐 美术 语文 数学 语文 语文 语文 英语 英语 数学 英语 英语 体育 体育 体育 体育 体育
clas = []
m = list(input().split())
k = 0
for i in range(5):
clas.append(m[k:(k+4)])
k = k + 4
print("周一 周二 周三 周四 周五")
for i in range(4):
for j in range(5):
print(clas[j][i],end=" ")
print()
5.6蒙特卡洛方法求圆周率
尝试使用蒙特卡罗法计算圆周率(π)的值。原理如下: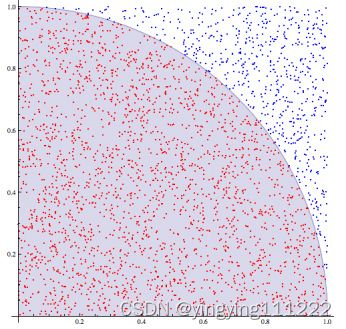
如图:边长为1的正方形内部有一个半径为1的四分之一个圆。 现往该正方形内随机投点,数量足够多的情况下,落入圆内的点m与落入整个 外切正方形的点n的数量比值大概为: m/n = (1/4)pi ,然后就可以得到π的值。 让点(x,y)投在整个矩形中,x与y的取值范围为(0≤x≤1, 0≤y≤1) 注意 1.请使用random库中的uniform来生成随机数。 2.使用运算符x*x求x的平方。 3.使用x**(1/2)求x的平方根。
输入格式:
在一行中给出种子和投点次数,中间以空格隔开。
输出格式:
对每一组输入,在一行中输出pi的值,并保留五位小数。
输入样例:
在这里给出一组输入。例如:
2 10000
输出样例:
在这里给出相应的输出。例如:
3.13560
import random
m = 0
n = 0
s,n = map(int,input().split())
random.seed(s)
for i in range(n):
x = random.uniform(0,1)
y = random.uniform(0,1)
if(y * y + x * x) ** (1/2) < 1:
m = m + 1
pi = 4 * (m /n)
print("{:.5f}".format(pi))
5.7模拟乒乓球比赛
中国选手与日本选手进行乒乓球比赛,每局先得11分者赢得此局,整个比赛5局3胜,如某队获胜达到3局,则赢得此场比赛。 假设中国选手每一分获胜的概率为m,(含m,m<1)。 请模拟比赛过程,并输出各队获胜情况。 请注意: 请使用random库中的random模拟胜率
输入格式:
请在第一行输入整数随机种子。 请在第二行输入中国队每一分获胜的概率(大于0小于1的数) 请在第三行输入要模拟的比赛次数
输出格式:
对每一组输入,根据模拟结果在一行中输出:
Chinese team:m,Japanese team:n。
输入样例:
在这里给出一组输入。例如:
3 0.6 100
输出样例:
在这里给出相应的输出。例如:
Chinese team:98,Japanese team:2
import random
seed = int(input())
odd = eval(input())
time = int(input())
cwin = 0
jwin = 0
random.seed(seed)
for i in range(time):
cgwin = 0
jgwin = 0
c = 0
j = 0
while cgwin != 3 and jgwin != 3:
count = random.random()
if(c ==11 and c - j >= 2)or(j == 11 and j - c >= 2)or (c > 11 and j > 11 and(c > j or c < j)):
if c > j:
cgwin += 1
c = 0
j = 0
else:
jgwin += 1
c = 0
j = 0
elif count <= odd:
c += 1
elif count > odd:
j +=1
if cgwin == 3:
cwin += 1
cgwin = 0
jgwin = 0
else:
jwin += 1
cgwin = 0
jgwin = 0
print("Chinese team:{},Japanese team:{}".format(cwin,jwin))
5.8今天是本学期的第几周的第几天?
根据输入的开学日期和当前的日期,判断当前日期是本学期的第几周的星期几。
输入格式:
在第一行中给出开学日期,年月日中间用‘-’隔开
在第二行中给出当前的日期,年月日中间用‘-’隔开
输出格式:
对每一组输入,在一行中输出‘今天是本学期的第m周的第n天’。
输入样例:
在这里给出一组输入。例如:
2022-2-28 2022-3-6
输出样例:
在这里给出相应的输出。例如:
今天是本学期的第1周的第7天
import time
import datetime
date = list(map(int,input().split('-')))
datenow = list(map(int,input().split('-')))
date = datetime.datetime(date[0],date[1],date[2])
datenow = datetime.datetime(datenow[0],datenow[1],datenow[2])
d = datenow - date
week = int((d.days + 7) / 7)
day = int((d.days % 7) + 1)
print("今天是本学期的第{0}周的第{1}天".format(week,day))
6 Python-练习6-函数
6.1 jmu-python-组合数据类型-1.计算坐标点欧氏距离
读取若干个点,每个点放入元组。并将所有点的点信息、点的类型、点与原点的距离打印出来。
函数接口定义:
readPoint() #从一行以,分隔的数中读取坐标,放入元组并返回 distance(point) #计算point与原点的距离并返回,要math库中的函数
裁判测试程序样例:
/* 请在这里填写答案 */ n = int(input()) for i in range(n): p = readPoint() print('Point = {}, type = {}, distance = {:.3f}'.format(p,type(p),distance(p)))
输入格式:
输入n,代表底下要输入n行点坐标。坐标全部为整数。
点坐标x,y,z以,分隔。坐标全部为整数。
注意:坐标以,分隔,相应位置可能无字符或者包含多个空格字符,读入时按照0进行处理。
输出格式:
见输出样例
输入样例:
5 1,1,1 ,, 2,,1 3,1,3 5,,
输出样例:
Point = (1, 1, 1), type =
import math
def readPoint():
coord = input().split(',')
for i in range(3):
try:
coord[i] = int(coord[i])
except:
coord[i] = 0
coord = tuple(coord)
return coord
def distance(point):
x = pow(point[0],2) + pow(point[2],2)
y = pow(point[1],2)
s = math.sqrt(x + y)
return s
6.2 jmu-python-函数-找钱
买单时,营业员要给用户找钱。营业员手里有10元、5元、1元(假设1元为最小单位)几种面额的钞票,其希望以
尽可能少(张数)的钞票将钱换给用户。比如,需要找给用户17元,那么其需要给用户1张10元,1张5元,2张1元。
而不是给用户17张1元或者3张5元与2张1元。
函数接口定义:
giveChange(money) #money为要找的钱。经过计算,应按格式"要找的钱 = x*10 + y*5 + z*1"输出。
裁判测试程序样例:
/* 请在这里填写答案 */ n = int(input()) for i in range(n): giveChange(int(input()))
输入样例:
5 109 17 10 3 0
输出样例:
109 = 10*10 + 1*5 + 4*1 17 = 1*10 + 1*5 + 2*1 10 = 1*10 + 0*5 + 0*1 3 = 0*10 + 0*5 + 3*1 0 = 0*10 + 0*5 + 0*1
def giveChange(m):
x = m // 10
y = (m - (x * 10)) // 5
z = m - (x * 10)-(y * 5)
print('{} = {}*10 + {}*5 + {}*1'.format(m,x,y,z))
6.3 jmu-java&python-统计字符个数
编写程序统计1行字符串中:
不同字符的个数。
每种字符出现的次数。
函数接口定义:
Freq(line)
函数功能:该函数统计不同字符出现的次数,并最后按照字符升序进行输出。输出格式见输出样例。
参数说明:line为需要统计的字符串。
裁判测试程序样例:
/* 请在这里填写答案 */ line = input() Freq(line)
输入样例:
abc 123 adex!!!
输出样例:
11 = 2 ! = 3 1 = 1 2 = 1 3 = 1 a = 2 b = 1 c = 1 d = 1 e = 1 x = 1
输出格式说明:
第1行输出不同字符的个数。
**=**两边应有空格。
上述输出样例中第2行的字符是空格。
输出按照字符升序排列。
def Freq(line):
arr = {}
for i in line:
arr[i] = arr.get(i, 0) + 1
arr = list(arr.items())
arr.sort(key=lambda x: x[0])
print(len(arr))
for i in range(len(arr)):
m, n = arr[i]
print("{0} = {1}" .format(m, n))
6.4 缩写词
缩写词是由一个短语中每个单词的第一个字母组成,均为大写。例如,CPU是短语“central processing unit”的缩写。
函数接口定义:
acronym(phrase); phrase是短语参数,返回短语的缩写词
裁判测试程序样例:
/* 请在这里填写答案 */ phrase=input() print(acronym(phrase))
输入样例:
central processing unit
输出样例:
CPU
def acronym(phrase):
lists=''
newPhrase=phrase.split()
for i in newPhrase:
lists += i[0]
lists = lists.upper()
return lists