python处理DataFrame类型数据常用方法
全文中pandas简写为pd,data和df都是DataFrame类型。
数据预处理常用方法汇总
数据操作
- 读取不同格式的数据
#默认情况下第一行数据为表头,设置参数header=None时,encoding可设置为"utf-8"或者"gbk",
data = pd.read_csv("文件路径")
data = pd.read.excel("文件路径",sheet_name='写入页名或者编号(第一页为0)')
data = pd.read_table("文件路径")
- 获取表头的列名
data.columns
- 以二维列表的形式返回所有数据
data.values
- 显示数据信息
data.info()
- 列索引和行索引
frame = pd.DataFrame(np.arange(9).reshape((3,3)),index=['a','c','d'],columns=['Ohio','Texas','California'])
# 修改行索引
frame.reindex(['a','b','c','d']) # 索引为b的行全为NaN
#修改列索引
frame.reindex(columns=['Texas','Utah','California']) # 索引为Utah的列全为NaN
# 修改列名
frame.columns=['Texas','Utah','California']
head()读取开头几行数据,默认为前5行,传入的参数为读取的行数。
tail()读取结尾几行数据,方法类似head()
describe()统计描述数据集,显示各列的总数,平均值,标准差,最小值,最大值。
获取指定数据
loc是轴标签、iloc是整数标签
- 获取列
data['列名']
data.列名 # 以上两句等价,获取指定列。
#直接用切片取行
data[:2] # 取前两行。
df.ix[0]#取第0行
df.ix[0:1]#取第0行
df.ix['one':'two']#取one、two行
df.ix[0:2,0]#取第0、1行,第0列
df.ix[0:1,'a']#取第0行,a列
df.ix[0:2,'a':'c']#取第0、1行,abc列
df.ix['one':'two','a':'c']#取one、two行,abc列
df.ix[0:2,0:1]#取第0、1行,第0列
df.ix[0:2,0:2]#取第0、1行,第0、1列
#loc只能通过index和columns来取,不能用数字
df.loc['one','a']#one行,a列
df.loc['one':'two','a']#one到two行,a列
df.loc['one':'two','a':'c']#one到two行,a到c列
df.loc['one':'two',['a','c']]#one到two行,ac列
#iloc只能用数字索引,不能用索引名
df.iloc[0:2]#前2行
df.iloc[0]#第0行
df.iloc[0:2,0:2]#0、1行,0、1列
df.iloc[[0,2],[1,2,3]]#第0、2行,1、2、3列
#iat取某个单值,只能数字索引
df.iat[1,1]#第1行,1列
#at取某个单值,只能index和columns索引
df.at['one','a']#one行,a列
- 获取行
选取等于某些值的行记录 用 ==
df.loc[df[‘column_name’] == some_value]
选取某列是否是某一类型的数值 用 isin
df.loc[df[‘column_name’].isin(some_values)]
多种条件的选取 用 &,且每个条件都要使用括号,不能省略()
df.loc[(df[‘column’] == some_value) & (df[‘other_column’].isin(some_values))]
选取不等于某些值的行记录 用 !=
df.loc[df[‘column_name’] != some_value]
isin返回一系列的数值,如果要选择不符合这个条件的数值使用~
df.loc[~df[‘column_name’].isin(some_values)]
- 获取列中不同的值
data['列名'].unique()
data['列名'].value_counts()# 查看该列有几种数据,以及每种数据出现的频次
添加行,列
# 添加行
df = pd.DataFrame(columns=list("ABC"))
# df = pd.DataFrame(columns=["A", "B", "C"]) # 等价于上一句,创建一个拥有三列属性的空DataFrame
df.loc[len(df)] = [1,2,3]
# 添加列
df[column_name] = list(数据)
查看数据集中缺失值的情况
data.isnull() # 每一行每一列有缺失值返回True,无缺失值返回False
data.isnull().sum() #统计每一列缺失值的总数
data.notnull() # 返回值结果与isnull相反。有缺失值返回False,无缺失值返回True
处理缺失值
df1.dropna() # 返回值为删除包含nan行的dataframe对象
# 注意的一点,如果想对df1产生修改的话,要使用inplace=True,才能对df1产生修改。
df1.fillna(value=100) #效果即为将列表中所有值为nan的内容,都填充为100。
科学计算

- 求和
#无参数时,默认按列求和
data.sum(axis=0) # 按列求和
data.sum(axis=1) # 按行求和
- 求平均值
data.mean()# 默认按列求平均
data.mean(axis=1) # 按行求平均,参数为0时按列求平均
用列表或数组给DataFrame中的某一个列赋值时,值的长度必须和DataFrame的长度相匹配。如果将Series赋值给一列时,Series的索引将会按照DataFrame的索引重新排列,并在空缺的地方填充缺失值。
groupby分组
data.groupby('列名') #按照指定列内的值进行分组,每个分组为一个元组类型。返回多个元组
打印数据
pd.set_option('display.max_columns',1000) # 设置最大显示列数的多少
pd.set_option('display.width',1000) # 设置宽度,就是说不换行,比较好看数据
pd.set_option('display.max_rows',500) # 设置行数的多少
删除数据
参考链接
- drop方法
drop()方法如果不设置参数inplace=True,则只能在生成的新数据块中实现删除效果,而不能删除原有数据块的相应行。
![]()
index用于指定要删除的行;columns用于指定要删除的列;inplace默认为False,表示该删除操作不改变原表格,而是返回一个执行删除操作后的新表格,如果设置inplace为True,则会直接在原表格中执行删除操作。
- 删除行
data.drop([16,17]) # 删除行索引为16和17的两行
drop(data.index[[16,17]],inplace=True) # 原有数据块的相应行被删除
- 删除列
data.drop(['column_name'],axis=1) # 删除新生成的数据块中列名为column_name的列
data.drop(['column_name'],axis=1,inplace=True) # 执行内部删除,不返回任何值,原数据发生改变
pop方法可以将所选列从原数据块中弹出,原数据块不再保留该列
one = data.pop('column_name') # 从原数据块中删除列名为column_name的列,并返回该列。
- 删除重复值

DataFrame的duplicated方法返回的是一个布尔值Series,这个Series反映的是每一行是否存在重复(与之前出现过的行相同)情况

drop_duplicates返回的是DataFrame,内容是duplicated返回数组中为False的部分

这些方法默认都是对列进行操作。你可以指定数据的任何子集来检测是否有重复。假设我们有一个额外的列,并想基于’k1’列去除重复值。

duplicated和drop_duplicates默认都是保留第一个观测到的值。传入参数keep='last’将会返回最后一个

print(data[data.duplicated()]) #打印重复的数据行
data.duplicated().sum() # 统计重复行的数量
data = data.drop_duplicates() # 删除重复行
注意,drop_duplicates()函数并不改变原表格结构,所以需要进行重新赋值,或者在其中设置inplace参数为True。
shape的用法
矩阵(ndarray)的shape属性可以获取矩阵的形状(例如二维数组的行列),获取的结果是一个元组
import numpy as np
x = np.array([[1,2,5],[2,3,5],[3,4,5],[2,3,6]])
#输出数组的行和列数
print x.shape #结果: (4, 3)
#只输出行数
print x.shape[0] #结果: 4
#只输出列数
print x.shape[1] #结果: 3
随机抽样
使用numpy.random.permutation对DataFrame中的Series或行进行置换(随机重排序)。在调用permutation时根据你想要的轴长度可以产生一个表示新顺序的整数数组:

整数数组可以用在基于iloc的索引或等价的take函数中:

要选出一个不含有替代值的随机子集,你可以使用Series和DataFrame的sample方法:

要生成一个带有替代值的样本(允许有重复选择),将replace=True传入sample方法:

数据排序
- values值排序
使用sort_values()函数可以对表格按列排序。例如,按c2列进行降序排序的代码如下
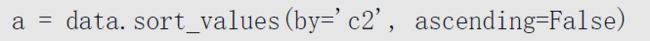
a = data.sort_values(by='c2',ascending=False)# 按照c2列的数据进行降序,
data.sort_values(by='c2',ascending=False,inplace=True) # inplace为true则排序后的新索引代替原来的索引
by参数用于指定按哪一列来排序;ascending参数默认为True,表示升序排序,若设置为False则表示降序排序
- index索引排序
使用sort_index()函数可以按照索引进行排序。
a = data.sort_index(ascending=True)
data.sort_index(ascending=True, inplace=True) # 当inplace为True时,原来的索引会被新的索引取代。
重新设置索引
data.reset_index(drop=True, inplace=True)# 删除掉原来的索引,并用新的索引替代。
数据转换
get_dummies()实现one——hot编码功能
factorize()实现将Series中的标称型数据映射称为一组数字
存储DataFrame数据至csv
# index的值为False表示不将列索引存储进csv文件中,默认是打印列索引到csv文件中
data.to_csv("文件名.csv", index=False,encoding="UTF-8")