CUDA编程学习<2>——归约算法的7种优化方法详解
该文主要是对英伟达官方提供的这个PPT中的7种优化方法进行详细剖析测试,官方PPT中只有部分归约代码,不够全,也有部分笔误。本文会复现PPT最后的测试性能表格的9个数据及其耗时,还有一些注意事项,对于不熟悉CUDA编程的同学来说复现并不容易。本人也是cuda编程菜鸟,花了三天多时间来吸收消化该优化,特此记录,供自己查阅也供来者学习
参考链接:
CUDA学习(归约算法)
Nvidia官网归约ppt (英文)
中文PPT
关于代码核函数的部分可以参阅我的博客:
CUDA编程学习——关于核函数ID获取公式
目录
- 1、概要
-
- 1.1、归约算法概要
- 1.2、样例题目介绍
- 1.3、测试硬件信息
- 2、算法图示
-
-
- 2.1、交错寻址图示
- 2.2、跨步寻址图示
- 2.3、连续寻址
-
- 3、代码部分
-
- 3.1、优化1:交错寻址(Interleaved addressing divergent branches)
-
- 3.1.1、核函数(优化1、优化2、优化3):
- 3.1.2、交错寻址函数代码:
- 3.2、优化2:跨步寻址(Interleaved addressing bank conflicts)
-
- 3.2.1、核函数
- 3.2.2、跨步寻址函数代码:
- 3.3、优化3:连续寻址(Sequential Addressing)
-
- 3.1、核函数
- 3.2、连续寻址函数代码:
- 3.4、优化4:把一次归约放在加载时进行(first add during load)
-
- 3.4.1、核函数:
- 3.4.2 算法优化部分
- 3.5、优化5:最后线程束展开(Unroll the last warp)
-
- 5.1 核函数
- 5.2 最后线束展开函数代码:
- 3.6、优化6:完全展开(completely Unrolled)
-
- 3.6.1、核函数:
- 7、优化7:每个线程有多个元素(Multiple elements per thread)
- 8、汇总以上所有测试代码,包括主函数
- 4、测试:
-
- 4.1、测试耗时结果
- 4.2、测试记录
1、概要
1.1、归约算法概要
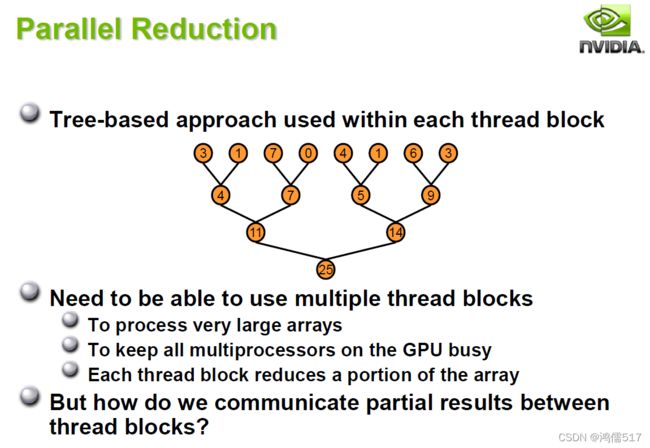
归约算法:将一个数组中的所有数项加求和的过程并行优化。
如果该算法运用熟练了,求和、求积或者其他混合运算都可以应用。
1.2、样例题目介绍
样例使用1~N的等差数列作为归约题目,如:N=10,使用CUDA代码求解1+2+3+4+5+6+7+8+9+10 即可。根据PPT最后的性能介绍,分别测试了下面的9组数据。![]()
PPT里面的测试性能如下图:
(硬件:G80GPU, 最大带宽:86.4GB/s,所有测试都使用Block Size = 128线程 )

注意:这9组数据是越来越大的,可以先使用最小的131072作为测试数据进行,代码测试。在数据变大的时候会出现数据溢出情况,导致计算结果出错。所以在最后测试过程中需要更改变量类型来解决,PPT里用共享内存变量类型用int,我的测试代码共享内存里面用的都是long long int 的原因。
1.3、测试硬件信息
如果要进行时效对比,则需要关注试验机自身硬件情况(由于怎么计算宽带值不会,所以只用耗时进行对比),实验机器硬件:

通过硬件信息可以看出几个重要信息:
理论带宽(bandwidth):192GB/s
此显卡每秒渲染像素数量(Pixel Filrate):48.5GPixel/s(1GPixel = 十亿像素)
此显卡每秒渲染纹理数量(Texture Filrate):84.8GTexel/s(1GTexel = 十亿纹理元素)
显卡类型:GDDR6
2、算法图示
2.1、交错寻址图示
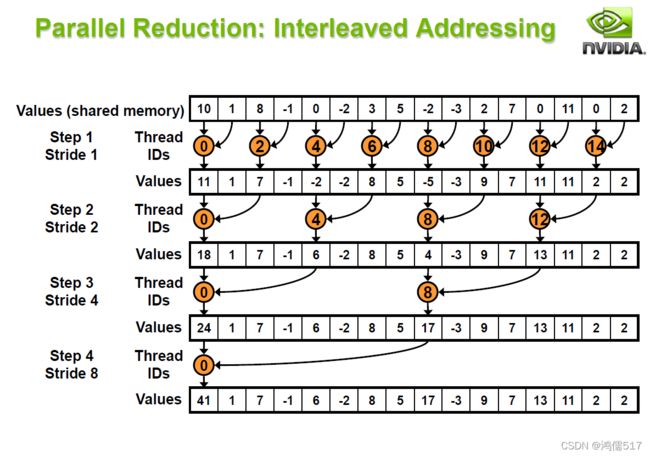
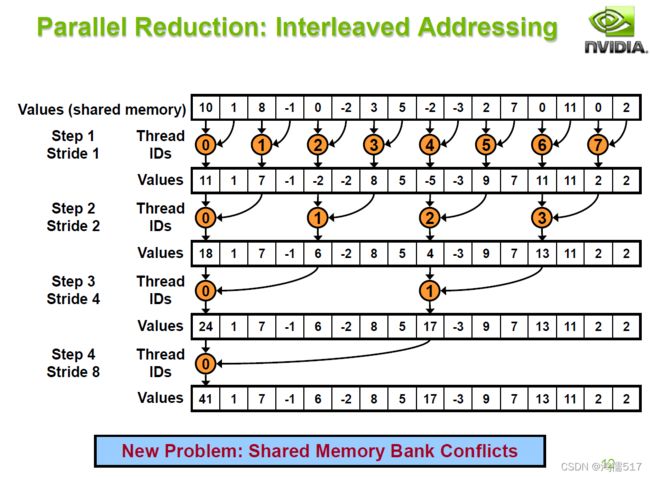
2.2、跨步寻址图示
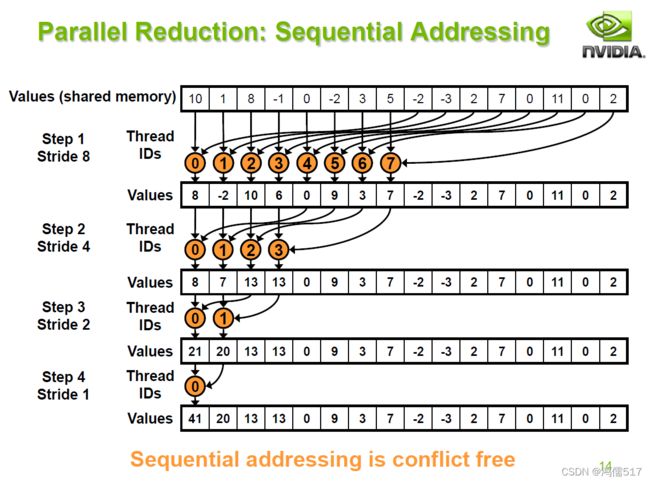
2.3、连续寻址
3、代码部分
3.1、优化1:交错寻址(Interleaved addressing divergent branches)
3.1.1、核函数(优化1、优化2、优化3):
__global__ void reduce0(unsigned int *g_idata, long long int *g_odata, int N, clock_t* time,int GuiYueWay) //
{//包含归约1、优化2、优化3的程序。
//__shared__ int sdata[threadsPerBlock];//共享内存,开辟2的指数个空间,2、4、8、32 ...
//__shared__ unsigned int sdata[threadsPerBlock];//共享内存,开辟2的指数个空间,2、4、8、32 ...
extern __shared__ long long int sdata[];//动态申请共享内存,空间大小在三个尖括号的第三个参数进行传入<<<1,2,3>>>开辟2的指数个空间,2、
clock_t start = clock();
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
//printf("tid:%d,i:%d\n",tid, i);
//方法1,要求一次性把线程数量建完,这样不确定有没有所有最大的线程限定,特点是速度快
sdata[tid] = (i < N) ? g_idata[i] : 0;
//printf("CUDA1 i:%d\n", i);
方法2,可以一个线程多次处理,但是在数据较大的时候结果容易出错
//unsigned int temp = 0;
//while (i < N)//N
//{//这种方式可以一个线程多次处理
// temp += g_idata[i];
// i += blockDim.x * gridDim.x;
// //printf("tid:%d\n", tid);
//}
设置cache中相应位置上的值
//sdata[tid] = temp;
__syncthreads();//同步共享变量
switch (GuiYueWay)
{
case 1:
GuiYue_Opt1(sdata, tid);//初始版本的归约函数
break;
case 2:
GuiYue_Opt2(sdata, tid);//优化的第2版本的归约函数
break;
case 3:
GuiYue_Opt3(sdata, tid);//优化的第3版本的归约函数
break;
default:
break;
}
// //do reduction in shared mem
//for (unsigned int s = 1; s < blockDim.x; s *= 2) {
// if (tid % (2 * s) == 0) {
// sdata[tid] += sdata[tid + s];
// }
// __syncthreads();
//}
// write result for this block to global mem
//printf("tid2:%d,i2:%d\n", tid, i);
if (tid == 0)
{
g_odata[blockIdx.x] = sdata[0];
//printf("sdata[0]:%u\n", sdata[0]);
//printf("g_odata[%d]:%u\n", blockIdx.x, sdata[0]);
}
*time = clock() - start;//计时
}
核函数说明
需要说明的是里面用到了共享内存,共享内存的开辟有两种方式,静态定义和动态开辟,可以参考如下链接:
CUDA之静态、动态共享内存分配详解
简要介绍共享内存
// __shared__ 为共享内存标识
//动态定义如下,在核函数内部定义,
extern __shared__ unsigned int sdata[];//动态申请共享内存,空间大小在核函数三个尖括号的第三个参数进行传入<<<1,2,3>>>,如需开辟20个空间,则第三个参数应该是20*sizeof(unsigned int)
//静态定义
__shared__ unsigned int sdata[20];//静态开辟20个静态空间
3.1.2、交错寻址函数代码:
__device__ void GuiYue_Opt1(long long int* sdata, unsigned int tid)
{//归约的方式1,交错寻址
for (unsigned int s = 1; s < blockDim.x; s *= 2) {
if (tid % (2 * s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
}
3.2、优化2:跨步寻址(Interleaved addressing bank conflicts)
3.2.1、核函数
核函数使用3.1交错寻址的核函数的switch语句调用
3.2.2、跨步寻址函数代码:
__device__ void GuiYue_Opt2(long long int* sdata, unsigned int tid)
{//归约的方式2,跨步寻址
for (unsigned int s = 1; s < blockDim.x; s *= 2) {
int index = 2 * s*tid;
if (index<blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
}
3.3、优化3:连续寻址(Sequential Addressing)
3.1、核函数
核函数使用3.1交错寻址的核函数的switch语句调用
3.2、连续寻址函数代码:
__device__ void GuiYue_Opt3(long long int* sdata, unsigned int tid)
{//归约的方式3,连续寻址
for (unsigned int s = blockDim.x / 2;s>0; s >>= 1) //注意:>>右移1位,假设s=5,那么二进制为0101 s>>1 右移1位,即把最右边的1位删掉,变为010 此时结果为2;如果s=5,s>>2,即右移2位,变成01,结果为1
{
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
}
3.4、优化4:把一次归约放在加载时进行(first add during load)
3.4.1、核函数:
主要还是用优化3的代码算法,更改核函数的赋值共享内存里,核函数代码如下
__global__ void reduce4( unsigned int *g_idata, long long int *g_odata, int N, clock_t* time, int GuiYueWay) //
{//在优化3的基础上进行优化4和优化5的程序。
//__shared__ int sdata[threadsPerBlock];//共享内存,开辟2的指数个空间,2、4、8、32 ...
//__shared__ unsigned int sdata[threadsPerBlock];//全局变量定义共享内存空间,开辟2的指数个空间,2、4、8、32 ...
extern __shared__ long long int sdata[];//动态申请共享内存,空间大小在三个尖括号的第三个参数进行传入<<<1,2,3>>>开辟2的指数个空间。当数据过大容易越界,需定义大点的空间
clock_t start = clock();
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;//优化位置1
//printf("tid:%d,i:%d\n",tid, i);
//sdata[tid] = (i < N) ? g_idata[i] : 0;
sdata[tid] = (i < N) ? g_idata[i]+ g_idata[i + blockDim.x] : 0;//优化位置2,把第一次归约放在加载数据的时候进行,减少了一次CUDA内部操作
//printf("CUDA4 i:%d,2i:%d\n", i, i + blockDim.x);
__syncthreads();//同步共享变量
switch (GuiYueWay)
{
case 4:
GuiYue_Opt3(sdata, tid);//优化的第3版本的归约函数
break;
case 5:
GuiYue_Opt5(sdata, tid);//优化的第5版本的归约函数
break;
default:
break;
}
//GuiYue_Opt3(sdata, tid);//优化的第3版本的归约函数
if (tid == 0)
{
g_odata[blockIdx.x] = sdata[0];
//printf("g_odata[%d]:%u\n", blockIdx.x,sdata[0]);
}
*time = clock() - start;//计时
}
3.4.2 算法优化部分
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;//优化位置1
sdata[tid] = (i < N) ? g_idata[i]+ g_idata[i + blockDim.x] : 0;//优化位置2,把第一次归约放在加载数据的时候进行,减少了一次CUDA内部操作
如PPT

3.5、优化5:最后线程束展开(Unroll the last warp)
5.1 核函数
核函数使用3.4优化4的核函数的switch语句调用
5.2 最后线束展开函数代码:
__device__ void warpReduce(volatile long long int* sdata,int tid)
{//该函数注意volatile,如果没有这个关键字,编译器可能会将sdata变量优化掉,导致结果出错的
sdata[tid] += sdata[tid + 32];
sdata[tid] += sdata[tid + 16];
sdata[tid] += sdata[tid + 8];
sdata[tid] += sdata[tid + 4];
sdata[tid] += sdata[tid + 2];
sdata[tid] += sdata[tid + 1];
}
__device__ void GuiYue_Opt5(long long int* sdata, unsigned int tid)
{//归约的方式5,该函数在归约方式3的基础上进行优化,省去warp过程中不必要的操作
for (unsigned int s = blockDim.x / 2; s > 32; s >>= 1) //注意:>>右移1位,假设s=5,那么二进制为0101 s>>1 右移1位,即把最右边的1位删掉,变为010 此时结果为2;如果s=5,s>>2,即右移2位,变成01,结果为1
{
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid < 32)
{
warpReduce(sdata, tid);
}
}
3.6、优化6:完全展开(completely Unrolled)
3.6.1、核函数:
把核函数优化成了模板方法增加通用性,另外增加了warpReduceT模板函数
//下面函数优化程序6使用
template<unsigned int blockSize>
__device__ void warpReduceT(volatile long long int* sdata, unsigned int tid)
{//该函数注意volatile,如果没有这个关键字,编译器可能会将sdata变量优化掉,导致结果出错的
if (blockSize >= 64)sdata[tid] += sdata[tid + 32];
if (blockSize >= 32)sdata[tid] += sdata[tid + 16];
if (blockSize >= 16)sdata[tid] += sdata[tid + 8];
if (blockSize >= 8)sdata[tid] += sdata[tid + 4];
if (blockSize >= 4)sdata[tid] += sdata[tid + 2];
if (blockSize >= 2)sdata[tid] += sdata[tid + 1];
}
template <unsigned int blockSize>
__global__ void reduce6( unsigned int *g_idata, long long int *g_odata, int N, clock_t* time) //
{//优化6程序
//__shared__ int sdata[threadsPerBlock];//共享内存,开辟2的指数个空间,2、4、8、32 ...
//__shared__ unsigned int sdata[threadsPerBlock];//共享内存,开辟2的指数个空间,2、4、8、32 ...
extern __shared__ long long int sdata[];//动态申请共享内存,空间大小在三个尖括号的第三个参数进行传入<<<1,2,3>>>开辟2的指数个空间,2、4、8、32 ...
clock_t start = clock();
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x * 2) + threadIdx.x;
//printf("tid:%d,i:%d\n",tid, i);
//sdata[tid] = (i < N) ? g_idata[i] : 0;
sdata[tid] = (i < N) ? g_idata[i] + g_idata[i + blockDim.x] : 0;//把第一次归约放在加载数据的时候进行,减少了一次CUDA内部操作
__syncthreads();//同步共享变量
//优化的第6版本的归约函数
if (blockSize >= 512)
{
if (tid < 256) { sdata[tid] += sdata[tid + 256]; }__syncthreads();
}
if (blockSize >= 256)
{
if (tid < 128) { sdata[tid] += sdata[tid + 128]; }__syncthreads();
}
if (blockSize >= 128)
{
if (tid < 64) { sdata[tid] += sdata[tid + 64]; }__syncthreads();
}
if (tid < 32)warpReduceT<blockSize>(sdata, tid);
if (tid == 0)
{
g_odata[blockIdx.x] = sdata[0];
//printf("sdata[0]:%d\n", sdata[0]);
}
*time = clock() - start;//计时
}
7、优化7:每个线程有多个元素(Multiple elements per thread)
与第6个优化版本相比,在核函数的时候就进行了合并,另外使用了优化6中的warpReduceT模板函数
template <unsigned int blockSize>
__global__ void reduce7(unsigned int *g_idata,long long int *g_odata, int N, clock_t* time) //
{//优化6程序
//__shared__ int sdata[threadsPerBlock];//共享内存,开辟2的指数个空间,2、4、8、32 ...
//__shared__ unsigned int sdata[threadsPerBlock];//共享内存,开辟2的指数个空间,2、4、8、32 ...
extern __shared__ long long int sdata[];//动态申请共享内存,空间大小在三个尖括号的第三个参数进行传入<<<1,2,3>>>开辟2的指数个空间,2、4、8、32 ...
clock_t start = clock();
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockSize * 2) + threadIdx.x;//更改位置1
unsigned int gridSize = blockSize * 2 * gridDim.x;
sdata[tid] = 0;
//printf("tid:%d,i:%d\n",tid, i);
//sdata[tid] = (i < N) ? g_idata[i] : 0;
//sdata[tid] = (i < N) ? g_idata[i] + g_idata[i + blockDim.x] : 0;//把第一次归约放在加载数据的时候进行,减少了一次CUDA内部操作
while (i<N)
{
sdata[tid] += g_idata[i] + g_idata[i + blockSize];
i += gridSize;
}
__syncthreads();//同步共享变量
//优化的第6版本的归约函数
if (blockSize >= 512)
{
if (tid < 256) { sdata[tid] += sdata[tid + 256]; }__syncthreads();
}
if (blockSize >= 256)
{
if (tid < 128) { sdata[tid] += sdata[tid + 128]; }__syncthreads();
}
if (blockSize >= 128)
{
if (tid < 64) { sdata[tid] += sdata[tid + 64]; }__syncthreads();
}
if (tid < 32)warpReduceT<blockSize>(sdata, tid);//
if (tid == 0)
{
g_odata[blockIdx.x] = sdata[0];
//printf("sdata[0]:%d\n", sdata[0]);
}
*time = clock() - start;//计时
}
英文pdf上有几处错误和需要注意的地方:
优化7最后的这个代码,因为是调用模板方法,所以需要增加模板值

8、汇总以上所有测试代码,包括主函数
/*
归约样例,增加时间统计,关注宽带占用情况
参考链接:
中文:https://wenku.baidu.com/link?url=LOvDSVU9fyqQko7h4rIWEuxwmKCgCOzrFSGoE1saaNWpGlmfl2wR9Qu--IcdwM9D0H1cIT_0mUFLrUazYPFuUrc57O_RbD8_IbS27MjFmtS
英文原版:https://developer.download.nvidia.cn/assets/cuda/files/reduction.pdf
优化方式:
归约的方式1,交错寻址
归约的方式2,跨步寻址
归约的方式3,连续寻址
归约的方式4,在连续寻址基础上进行改进。由于第一次循环迭代中,一半线程处于空闲状态,太浪费了,所以优化。比前三种优化,每个共享内存中的数值大约是
归约的方式5,在最后进行了swarp展开,实测速度不如第四次快
归约的方式6,完全展开,把核函数写成模板方法进行调用,在优化部分进行了模板方法的完全展开。模板方法会在编译的时候进行评估计算
归约的方式7,把第4种方法和第6种方法结合。
*/
///*
#include "device_launch_parameters.h"
#include "cuda_runtime.h"
#include "device_functions.h"
#include 4、测试:
4.1、测试耗时结果
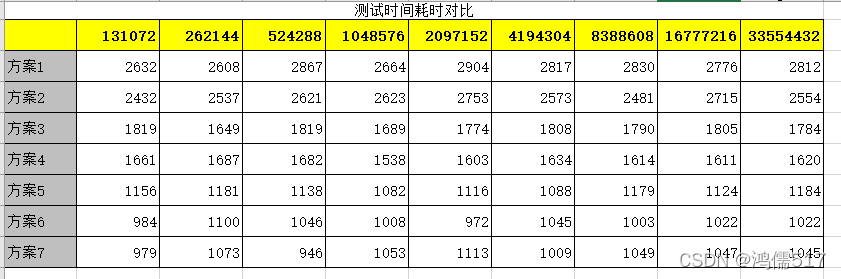
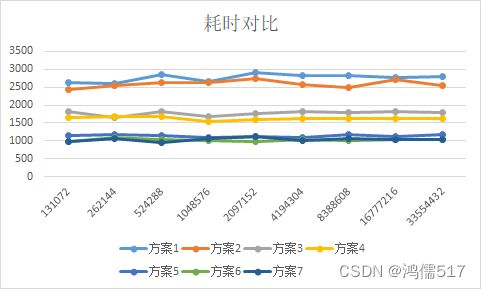
通过上面测试可以发现一些规律:
1、优化有三个台阶;
2、并不是第7种优化耗时总优于第6种,要根据实际情况优化。
4.2、测试记录
代码编译后,可以通过外部传参,设置总任务数、使用优化的方法、threadsPerBlock数量,PPT上默认设置128,所以此次对比该值不变,如果有兴趣想测试自己的GPU的计算能力,自己在后面追加一个threadsPerBlock进行测试即可,接口已经留了的,但必须是2的指数倍。
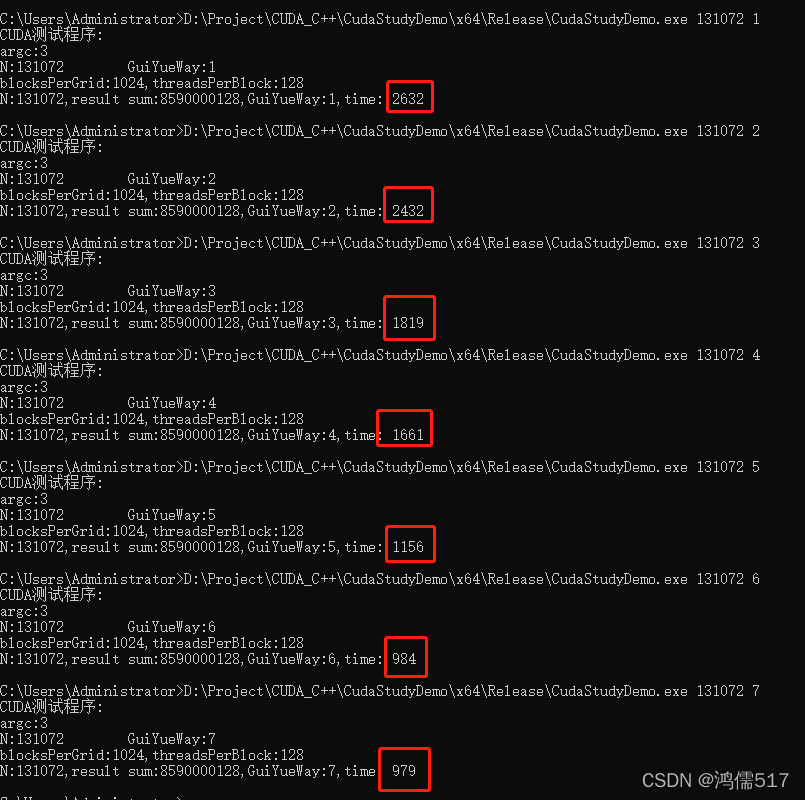
完整的传参测试记录:

最小值131072测试记录:
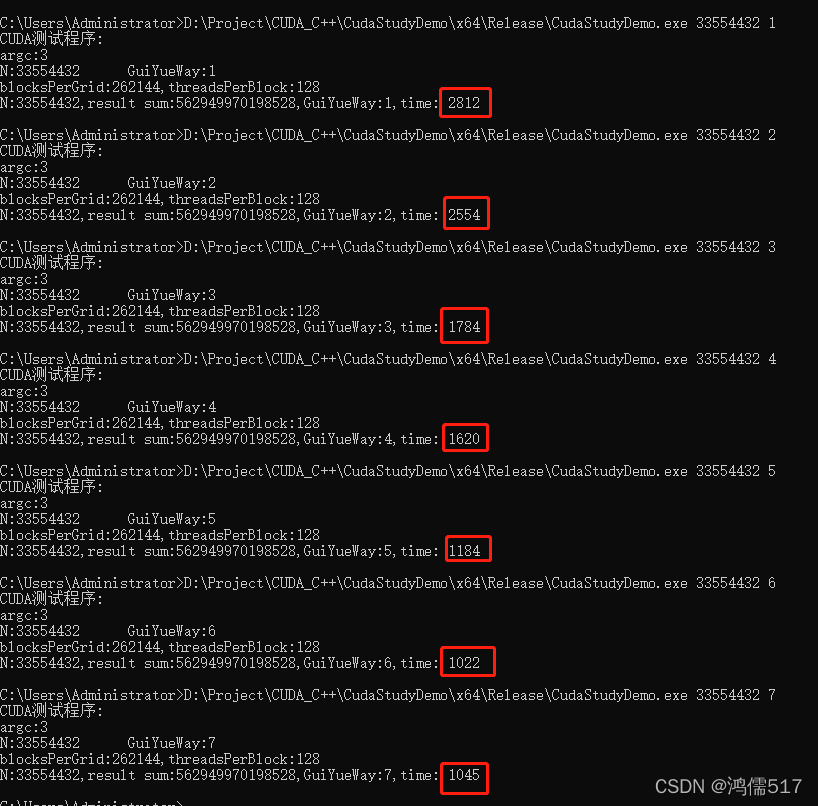
最大值33554432测试记录:
至此。2022.2.16