MySQL集群方案
文中的【// TODO】都是待完成的任务。
1. 简介
1). 集群的好处
① 高可用性:故障检测及迁移,多节点备份。
② 可伸缩性:新增数据库节点便利,方便扩容。
③ 负载均衡:切换某服务访问某节点,分摊单个节点数据库压力。
2). 高可用架构需要考虑以下几个方面
① 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断。
② 用作备份、只读等功能的【非主节点】的数据应该和主节点的数据实时或者最终保持一致。
③ 当业务发生数据库切换时,切换前后的数据库内容应该一致,不会因为数据缺失或者数据不一致而影响业务。
2.高可用方案
主从复制架构:① 主从复制(一主多从);② MMM架构(双主多从);③ MHA架构(多主多从)。
PS:由于当前不涉及到读写分离的技术诉求,所以,目前仅考虑双主模式。
2.1双主
既然是两个主节点,那么必然存在两个节点之间的数据同步问题。
MySQL为我们提供了:异步复制、半同步复制、全同步复制。
2.1.1 MySQL主从复制原理

1).客户端在master上执行DDL、DML操作,将数据变更记录到 bin log(二进制日志);
2).从库 slave 的I/O线程连接上 master,请求读取指定位置 position 的日志内容;
3).master 收到从库 slave 请求后,将指定位置 position 之后的日志内容和主库 bin log 文件的名称以及在日志中的位置推送给从库 slave。 ① 通过 show master status 可以查看最新的 bin log 日志文件名称和位置等信息;
② 定位一个 logEvent 需要通过 binlog filename + binlog position进行定位。
4).slave 的I/O线程接收到数据后,将接收到的日志内容依次写入到 relay log(中继日志)文件的最末端,并将读取到的主库 bin log 文件名和位置 position 记录到 master info 文件中,方便下一次读取的时候能够清楚的告诉 master“我需要从某个bin log日志的某个位置开始往后的日志内容”。
5).slave 的 sql 线程检测到 relay log 中的内容更新后,读取日志并解析成可执行的 sql 语句进行重做。
2.1.2异步复制
MySQL 默认的复制使用的是异步复制,主库在执行完客户端提交的事务后会立即返回给客户端,不关心备库是否已经接收并处理。
可能存在的问题:主库宕机的时候,主库上已经提交的事务可能还没有传送到备库上。异步复制会导致节点之间数据不一致,也就是没有达到强一致性。
2.1.3半同步复制
主库在执行完客户端提交的时候后不是立即返回给客户端,而是等待至少一个从库接收到并写到 relay log 中才返回给客户端。
这种方案会对客户端造成一定的延迟,至少一个 TCP/IP 往返的时间。
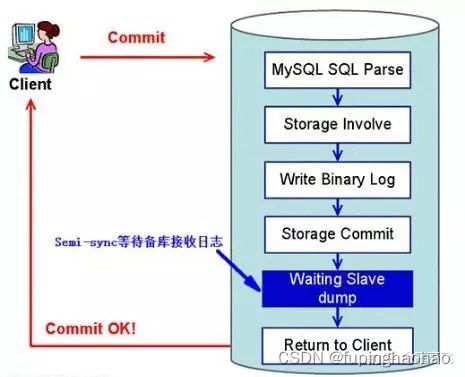
这种方案其实就是在一个事务中,将原本只提交一个库的操作变成了提交到两个库。
优点:
① 双节点,不会涉及到 master 宕机后选主的问题,直接切换即可。
② 架构较为简单,使用 MySQL 原生的半同步复制作为数据同步的依据。
缺点:没有故障自动转移和负载均衡。
2.2 MHA架构
2.2.1简介
MHA(master high availability)是一款开源的 MySQL 高可用程序,目前在 MySQL 高可用方案中是相对成熟的解决方案。
MHA 是基于标准的 MySQL 复制(异步/半同步),为 MySQL 主从复制架构提供了【自动故障转移】的功能。
MHA 由 管理节点(MHA Manager)和 数据节点(MHA Node)两部分组成。
MHA Manager 会定时探测集群中的 master 节点,当 master 节点出现故障时,它可以自动将拥有最新数据的 slave 节点提升为新的 master 节点。
MHA 还提供了 master 节点在线切换的功能,也就是说,可以按需切换 master/slave 节点。
2.2.2 MHA角色
MHA 服务有两种角色:MHA Manager(管理节点)、MHA Node(数据节点)。
MHA Manager:通常单独部署在一台机器上,用来管理多个 master/slave 集群(组),每个 master/slave 集群称作一个 application,用来管理统筹整个集群。
MHA Node:运行在每台 MySQL 服务器上(master/slave/manager),它通过监控具备解析和清理 logs 功能的脚本来加快故障转移。
2.2.3架构
目前 MHA 主要支持一主多从的架构,搭建 MHA 要求一个【复制集群】中必须【最少】有三台数据库服务器,一主二从,即一台 master,一台备用 master,另外一台从库。SO,至少需要三台服务器,再加上 MHA Manager 一台,可能就需要四台服务器。

工作流程如下:
MAH 的目的在于维护 MySQL replication 中 master 库的高可用性,其最大的特点是可以修复多个 slave 之间的差异日志,最终使所有 slave 保持数据一致。
| 1). 从宕机崩溃的 master 保存二进制日志事件(bin log events)。 2). 识别含有最新更新的 slave。 3). 应用差异的中继日志(relay log)到其他的 slave。 4). 把 master 保存的二进制日志事件(bin log events)应用到要提升为 master 节点的 slave。 5). 解除这个 slave 的只读模式,并提升为新 master。 6). 让其他的 slave 连接到新的 master 进行复制。 |
2.2.4优缺点
1).优点
① 可以监控多个集群
一个 MHA Manager 可以管理多个集群。
② 故障处理速度
在主从复制集群中,只要从库在复制上没有延迟,MHA 通常可以在数秒内实现故障切换。9-10秒内检测到 master 故障,可以在7-10秒关闭 master 以避免出现脑裂,几秒钟内,将差异中继日志(relay log)应用到新的 master 上,因此,总的宕机时间通常为 10-30 秒。恢复新的 master 后,MHA 并行恢复其余的 slave。
③ 无性能下降
MAH 适用于【异步或半同步复制】的 MySQL 复制。监控 master 时,MHA 仅仅是每隔几秒(默认是 3 秒)发送一个 ping 包,并不发送重查询,可以得到像原生 MySQL 复制一样的性能。
2).不足
① 只监控 master
MHA 只保证 master 的高可用,并没有监控 slave 的状态。加入某个 slave 出现复制中断、延迟增加等问题,都是不知道的。
② 没有集成虚拟 IP 的配置
在故障转移时,为了对外透明,需要使用虚拟 IP,MHA 没有实现 VIP,需要借助于 keepAlive。
③ 安全问题
MHA 要求所有服务器之间都配置 SSH 免登录。这样就存在一定的安全隐患,如果某台服务器出现了安全问题,那么就可能影响其他服务器。
3.MHA 搭建
3.1 数据同步
如果主从库的数据一模一样,那么这一步可以略过。因为在搭建主从复制之前需要保证主从库一致。
可以使用 Navicat 工具来保证多个MySQL服务保持一致,也可以使用其他方式,具体方法就各显神通吧。
3.2 MySQL主从搭建(异步复制)
【一主二从,异步复制】。
| 主库 |
107 |
| 从库 |
134、143 |
3.2.1 准备
3.2.1.1 主从库
【备注】:所有节点都要做如下配置(一劳永逸,目的是为了方便下面的MHA搭建)
3.2.1.1.1 配置
修改 MySQL 的配置文件(可通过命令 mysql --help | grep "my.cnf" 查看配置文件的位置)。
| # ① 开启 bin log(二进制日志) log_bin=/usr/local/mysql/logs/binlogs/mysql-bin # 一个事务刷盘一次(bin log 刷盘机制) sync_binlog=1 # bin log 的格式 binlog_format=ROW # ② 开启 relay log(中继日志) # 如果只是主从复制,仅在 slave 上配置即可;MHA 的话,就需要在所有 MySQL 节点上配置。 relay-log=/usr/local/mysql/logs/relaylogs/mysql-relay # 指定 slave 要复制主库上的哪个数据库,如果有多个的话,那就得配置多个 replicate-do_db,而不是用逗号把对应的数据库名给隔开。 replicate-do_db=ta_liquidation_sub_sh |
3.2.1.1.2 创建复制账号
| # ① 创建【复制】用户 # 如果只是主从复制,仅在 slave 上创建即可; # 如果是MHA 的话,就需要在所有 MySQL 节点上创建。 grant replication slave on *.* to repluser@"%" identified by "654321"; # ② 刷新 flush privileges; |
|
|
| # ③ 看看有没有创建成功 select host, user from mysql.user where user = 'repluser'; |
|
|

3.2.1.2主库
3.2.1.2.1 配置
1). 查看MySQL配置文件在服务器上的目录:mysql --help | grep "my.cnf"
| 107 |
# ① cluster id,一个集群中各个 MySQL 不能一样 server_id=1 |
3.2.1.2.2 设置
| # ① 重置 master reset master; # ② 查看 master 的 binlog 日志信息(当前最新的 binlog 文件名称、position 等) show master status; |
|
|

3.2.1.3从库
3.2.1.3.1 配置
| 134 |
# cluster id server_id=2 |
| 143 |
# cluster id server_id=3 |
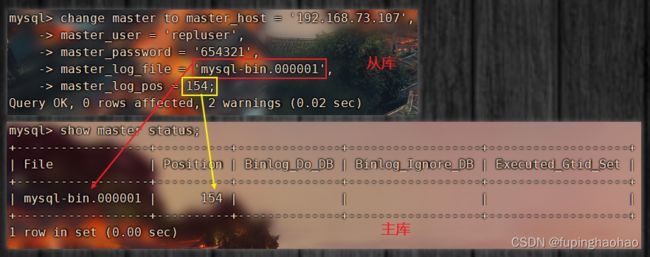
3.2.1.3.2 设置主从关系
| # ① 停止 slave 进程 stop slave; |
|
| # ② 在【从服务器】上设置主从关系 change master to master_host = '192.168.73.107', master_user = 'repluser', master_password = '654321', master_log_file = 'mysql-bin.000001', master_log_pos = 154; |
master_host:主库 ip master_user:主库授权用户名 master_password:授权用户密码 master_log_file:主库日志文件 master_log_pos:主库日志偏移量 |
|
|
|
| # ③ 启动 slave 进程 start slave; |
|
|
|
|
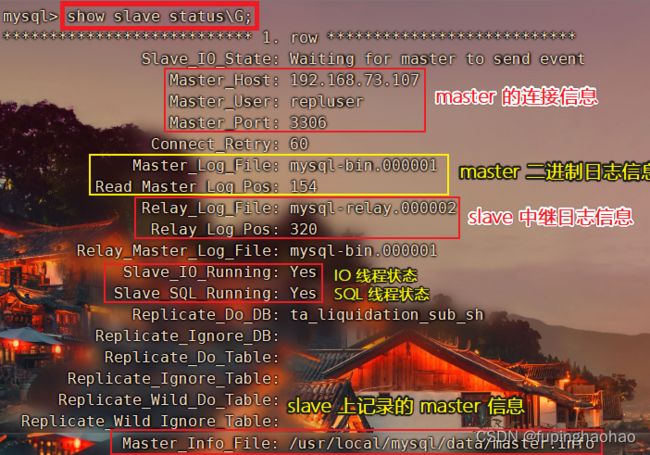
| # ④ 查看 slave 状态 show slave status\G; |
|
|
|
这里只截取了一部分 slave 的状态信息。 注意看: ① Slave_IO_Running(IO 线程状态):YES(开启)。 ② Slave_SQL_Running(SQL 线程状态):YES(开启)。 有这两个就说明主从复制搭建成功。 |

3.2.2 验证
在107主库的 ta_liquidation_sub_sh 数据库上进行 DDL、DML 操作,对应的 134、143 这两个从库上就会进行同步。

3.3 MySQL主从搭建(半同步复制)
【一主二从,半同步复制】。
注意:该步操作是在【3.1 MySQL主从搭建(异步复制)】的基础上进行。
3.3.1 概念
这里我们再来回顾一下半同步复制。
1).异步复制的问题
在异步复制中,主库不会去验证 bin log 有没有成功复制到从库中。如果主库提交一个事务并写入 bin log 中后,当从库还没有从主库中得到 bin log 时,主库宕机了或者由于其他原因导致该事务的 bin log 丢失了,那么从库就不会得到这个事务,进而就造成了主从数据不一致。
2).半同步复制来解决
半同步复制,当主库每提交一个事务后,不会立即返回,而是等待【其中一个从库】接收到 bin log 并成功写入 relay-log 中才返回客户端。SO,这样就可以保证一个事务至少有两份日志,一份保存在主库的 bin log,另一份保存在其中一个从库的 relay-log 中,从而保证了数据的安全性和一致性。
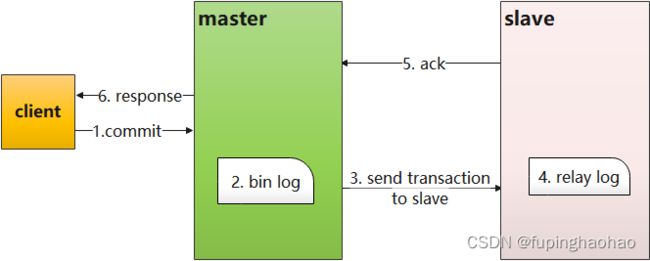
3).半同步复制的问题
① slave 超时时,就会退化为异步复制
在半同步复制时,如果主库的一个事务提交成功了,在推送到从库的过程中,如果从库宕机了或者网络故障,导致从库并没有接收到这个事务的 bin log。此时,主库会等待一段时间(这个时间由 rpl_sync_master_timeout 的毫秒数决定),如果过了这个时间后还无法推送到从库的话,那么,MySQL就会从半同步复制切换到异步复制,当从库恢复正常连接到主库后,主库又会切换回半同步复制。
SO,半同步复制很大程度上取决于主从库之间的网络情况,往返时延越小决定了从库的实时性越好。
3.3.2 配置半同步复制
3.3.2.1 确认MySQL服务器是否支持动态增加插件
主从库都查看一下。如果不支持那就直接跳过当前章节。
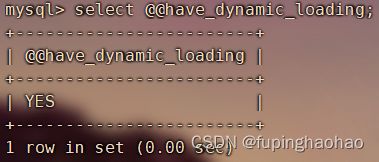
| select @@have_dynamic_loading; |
|
|
|
YES:支持。 |
3.3.2.2 在主从库上安装插件
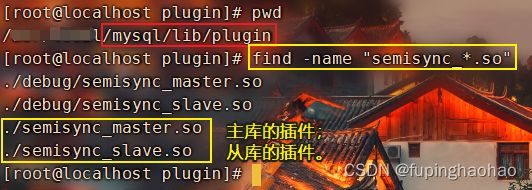
1).查看是否可以安装相应的插件
MySQL的插件一般在安装目录/bin/plugin下,先看一下能不能安装。
1).【主库】的插件是semisync_master.so。
2).【从库】的插件是semisync_slave.so。
3). ① 如果是【主从复制】的话,那么就各自安装;
② 如果是 MHA 的话,那么所有的节点都需要安装【主库和从库】的插件。
2).安装插件
| # ① 先看看是不是已经安装了 select * from mysql.plugin; |
|
|
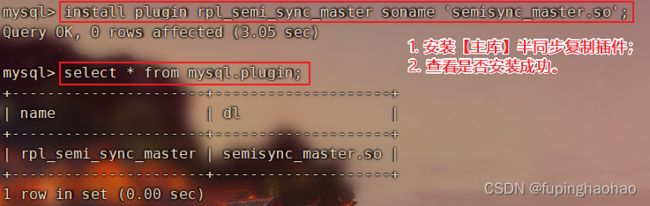
| # ② 安装 semisync_master.so 插件 install plugin rpl_semi_sync_master soname 'semisync_master.so'; |
|
|
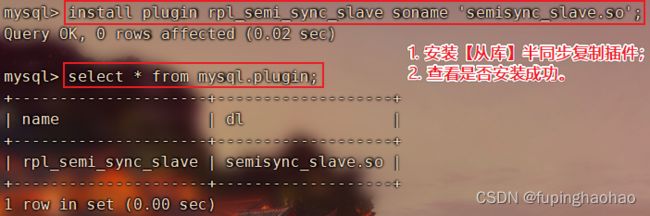
| # ③ 在所有【从库】上安装 semisync_slave.so 插件 install plugin rpl_semi_sync_slave soname 'semisync_slave.so'; |
|
|
【注】:系统重启的时候也会自动加载这些插件,SO,不必担心。
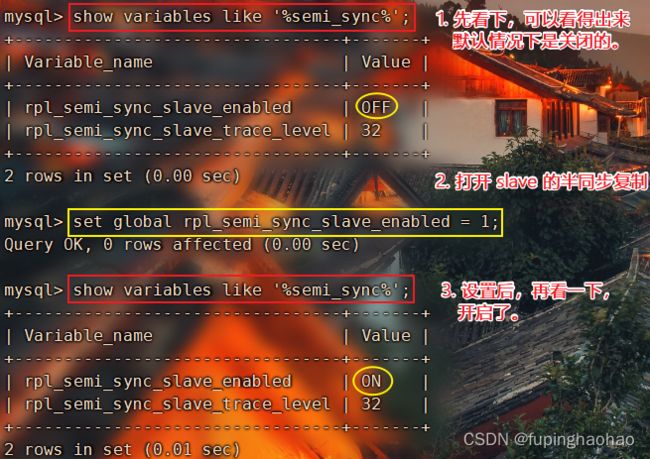
3.3.2.3 打开半同步复制semi-sync
半同步复制,默认情况下设置不打开。
| # ① 在MySQL-master上开启 master 的半同步复制 set global rpl_semi_sync_master_enabled = 1; # 查看 show variables like 'rpl_semi_sync_master_enabled'; |
|
|
| # ② 在MySQL-slave上开启 slave 的半同步复制 set global rpl_semi_sync_slave_enabled = 1; # 查看 show variables like 'rpl_semi_sync_slave_enabled'; |
|
|

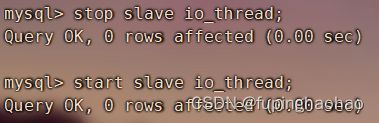
3.3.2.4 重启从库的I/O线程
如果之前配置的是异步复制,那么在这里就需要重启一下从库的I/O线程。如果是全新的半同步复制就不需要这一步。
| # 停止 I/O 线程 stop slave io_thread; # 开启 I/O 线程 start slave io_thread; |
|
|
3.3.2.5 在【主库】上查看半同步复制的状态信息
| # 在【主库】上查看半同步复制的状态信息 show status like '%semi_sync%'; |
|
|
|
我们在这里需要关注三个值: ① Rpl_semi_sync_master_status 值为 ON,表示半同步复制目前处于打开状态。 ② Rpl_semi_sync_master_no_tx 这个值表示当前主库有多少个事务不是半同步模式下从库及时响应的。 ③ Rpl_semi_sync_master_yes_tx 这个值表示当前主库上有多少个事务是通过半同步复制到从库的。 综上所知,在日常的维护中,我们可以查看这三个值来判断半同步复制是否正常。 |

3.3.3 半同步复制方式
MySQL的半同步复制方式由参数【rpl_semi_sync_master_wait_point】控制。
支持两种不同的半同步复制方式:AFTER_SYNC(默认值)和AFTER_COMMIT。
1). AFTER_SYNC
复制方式:Master上的 binlog 日志复制到 slave 之后,master 再 commit。
所有在 master 上 commit 的事务都已经复制到了 slave;但是所有已经复制到 slave 的事务在 master 上不一定 commit(比如说,master 将日志复制到 slave 之后,在 commit 之前宕机了)。
2). AFTER_COMMIT
复制方式:Master 先 commit,之后再将 binlog 日志复制到 slave 上。
所有在 master 上 commit 的事务不一定复制到了 slave(比如,master commit 之后,还未来得及将 binlog 日志复制到 slave 就宕机了);所有已经复制到 slave的事务在 master 上一定 commit 了。
该方式在 master 宕机的情况下,无法保证数据的一致性,所以,一般也不会使用该方式。

3.3.4 验证
验证方式及结果与【3.2.2验证】相同。主从复制完成后,再来在主库上看一下半同步复制的状态信息。

3.4 MHA 搭建
真正的大佬来了。
| MHA Node |
主库 |
107 |
| 从库 |
134、143 |
|
| MHA Manager |
104 |
|
3.4.1 MySQL 配置
在 MySQL 的 slave 上开启 bin log(二进制日志)。因为当发生自动故障迁移时,如果 slave 没有开启 bin log 的话,那么就无法将其提升为 master。开启方式直接参考【3.2.1.1.1主库配置】。
3.4.2 安装 MHA
3.4.2.1安装依赖
因为 MHA Manager 与 MHA Node 都是用 Perl 开发的,所以我们需要安装 Perl。所有服务器上都要安装。
1).安装 epel 源
yum install -y epel-release
2).安装 perl 模块
① 安装方式一
yum -y install perl-DBD-MySQL
yum -y install perl-Config-Tiny
yum -y install perl-Log-Dispatch
yum -y install perl-Parallel-ForkManager
yum -y install perl-ExtUtils-CBuilder
yum -y install perl-ExtUtils-MakeMaker
yum -y install perl-CPAN
② 安装方式二
CPAN网站(The Comprehensive Perl Archive Network - www.cpan.org)
MetaCPAN网站(Search the CPAN - metacpan.org)
在这两个网站上搜索。
3.4.2.2 安装MHA软件包
在 GitHub 上下载 tar.gz 包
| GitHub地址 |
版本 |
| https://github.com/yoshinorim/mha4mysql-manager/releases |
0.58 |
| https://github.com/yoshinorim/mha4mysql-node/releases |
0.58 |
3.4.2.2.1 安装 mha4mysql-node
1).安装
所有节点(一个MHA Manager,三个MHA Node[一主两从])都要安装。
| # I. 解压 tar -xzvf mha4mysql-node-v0.58.tar.gz |
| # II. 编译安装 ① perl Makefile.PL |
|
|
| ② make |
|
|
| ③ make install |
|
|



2).安装过程中遇到的问题
Q1:安装的第一步:perl Makefile.PL,可能会出现下面的错误提示。
![]()
A1:解决方案
原因:缺少 Module::Install
【注意】:下面的方法一和方法二都要执行,执行完之后还是不行的话就继续执行直至成功为止。一般情况下需要两三次执行才可成功。
方法一:简单用法:perl -MCPAN -e 'install Module::Install'
一路 yes + enter 就行。
方法二:复杂用法(用capn进行安装):perl -MCPAN -e shell
① install local::lib ② o conf init:重新配置。 ③ reload cpan:更新。 ④ exit:退出。
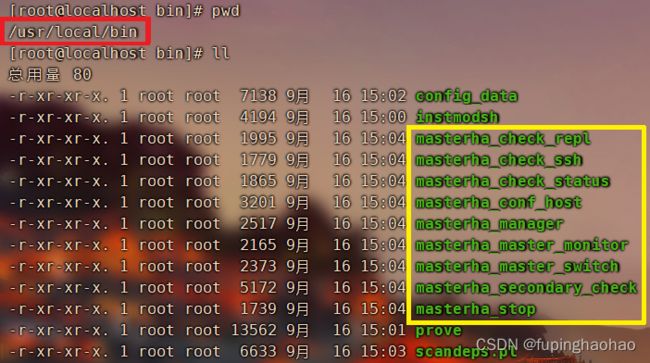
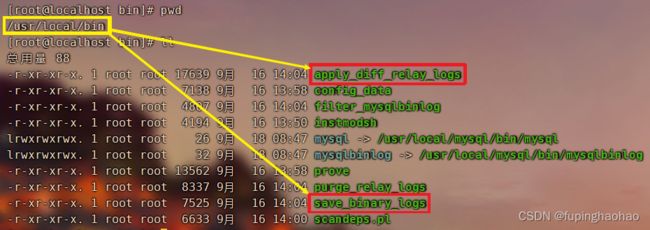
3).node组件安装成功后会在目录 /usr/local/bin 下面生成以下几个工具
这些工具通常由 MHA Manager 的脚本触发,无需人为操作。
| 工具(脚本)名称 |
作用 |
| save_binary_logs |
保存和复制 master 的二进制日志 |
| apply_diff_relay_logs |
识别差异的中继日志事件,并将其差异的事件应用于其他的 slave |
| filter_mysqlbinlog |
去除不必要的 rollback 事件(MHA 已不再使用这个工具) |
| purge_relay_logs |
清除中继日志(不会阻塞 SQL 线程) |
|
|
|

3.4.2.2.2 安装 mha4mysql-manager
只在 MHA Manager 的服务器上安装即可,具体安装过程同【3.4.1.2.1安装 mha4mysql-node】,此处不再赘述。
Manager 组件安装成功后会在 /usr/local/bin 下面会生成以下几个工具:
| 工具(脚本)名称 |
作用 |
| masterha_check_repl |
检查 MySQL 复制状况 |
| masterha_check_ssh |
检查 MHA 的 SSH 配置状况 |
| masterha_check_status |
检测当前 MHA 的运行状态 |
| masterha_conf_host |
添加或删除配置的 server 信息 |
| masterha_manager |
启动 MHA |
| masterha_master_monitor |
检测 master 是否宕机 |
| masterha_master_switch |
控制故障转移(自动or手动) |
| masterha_secondary_check |
多种线路检测 master 是否存活(当 MHA Manager 检测到 master 不可用时 ,通过该脚本来进一步确认,降低误切的风险)。 |
| masterha_stop |
停止 MHA |
|
|
|
3.4.3 免密通信
3.4.3.1 免密通信配置
服务器之间免密登录,也叫 SSH 互信配置。所有节点(manager、node)都要执行。
ssh 互信配置的原理:在各自的服务器上存放目标主机的证书,当执行登录时自动完成认证,从而不需要输入任何密码。

1).所有节点都执行生成密钥操作
这里以 MHA Manager 服务器节点为例进行说明,其他的三台(一主二从)机器一样的操作。
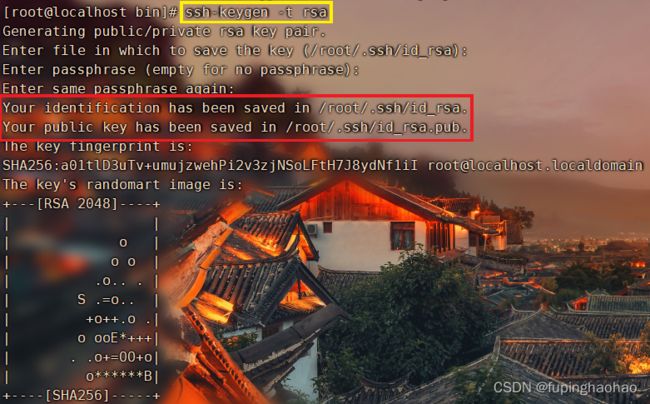
| # ① 生成 RSA 公钥 ssh-keygen -t rsa(请一直回车,直至结束) |
| 执行过程:
执行结果:
|
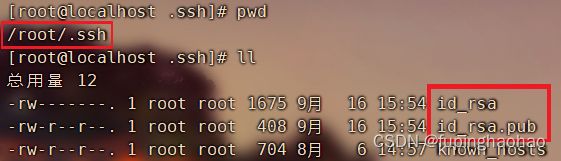
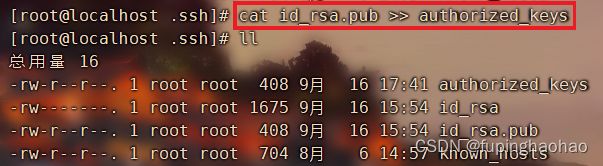
| # ② 将公钥(/root/.ssh/id_rsa.pub)文件追加到认证文件(名为 authorized_key 文件)中。 # id_rsa.pub 文件位置在上一步就可以看出来。 cat id_rsa.pub >> authorized_keys |
|
|
2).在4台机器(一个MHA Manager,三个 MHA Node [即,一主二从])中,随便挑一台执行如下操作
这里也以 MHA Manager 为例进行操作。
| # I. 在 MHA Manager 上接收 主从3台 MySQL 服务器上的密钥 # ① 将 master 上的认证文件发送到 MHA Manager scp 192.168.73.107:/root/.ssh/authorized_keys ./authorized_keys.107 # ② 将 slave1 上的认证文件发送到 MHA Manager scp 192.168.73.143:/root/.ssh/authorized_keys ./authorized_keys.143 # ③ 将 slave2 上的认证文件发送到 MHA Manager scp 192.168.73.134:/root/.ssh/authorized_keys ./authorized_keys.134 |
|
|
|
|
| # II. 在 MHA Manager 上执行合并密钥的命令 # 也就是把 master、slave1、slave2 上发送过来的三个文件合并到 MHA Manager 的认证文件中。 # ① 把 master 上的认证文件合并到 MHA Manager cat authorized_keys.107 >> authorized_keys # ② 把 slave1 上的认证文件合并到 MHA Manager cat authorized_keys.134 >> authorized_keys # ③ 把 slave2 上的认证文件合并到 MHA Manager cat authorized_keys.143 >> authorized_keys |
|
|
|
合并完成之后,可以看出来 MHA Manager 对应的认证文件【authorized_keys】的文件大小都变大了。 |
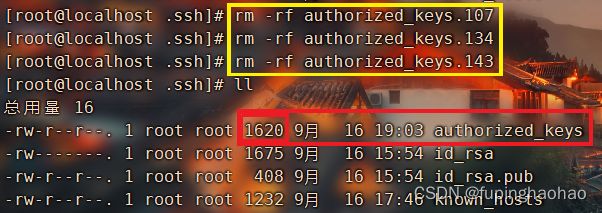
| # III. 在 MHA Manager 上将其他服务器节点的认证文件删掉 # 因为这里已经没有用了,就只留 MHA Manager 自身的一个认证文件就行了。 |
|
|
|
|
| # IV. 将 MHA Manager 上合并好的密钥文件发送给其他节点(一主二从3个节点,即 MHA Node) # ① 将 MHA Manager 上的密钥文件发送到 master scp authorized_keys 192.168.73.107:/root/.ssh/ # ② 将 MHA Manager 上的密钥文件发送到 slave1 scp authorized_keys 192.168.73.134:/root/.ssh/ # ③ 将 MHA Manager 上的密钥文件发送到 slave2 scp authorized_keys 192.168.73.143:/root/.ssh/ |
|
| 至此,四台服务器(一个 MHA Manager,三个 MHA Node[一主二从])上的密钥文件就是一模一样的了。 |
|


3.4.3.2 修改主机名
分别在四台服务器(一个 MHA Manager,三个 MHA Node[一主两从])上修改 IP 主机名:vim /etc/hosts
| 192.168.73.104 mha-manager 192.168.73.107 mha-node-master 192.168.73.143 mha-node-slave1 192.168.73.134 mha-node-slave2 |
|
|

3.4.3.3 验证
能够互相 ssh 且不要密码就算是成功了。

3.4.4 MHA Manager 配置
在 https://github.com/yoshinorim/mha4mysql-manager.git 下载源码,我们需要用到 /mha4mysql-manager/samples 下的文件。
3.4.4.1 MHA Manager 脚本
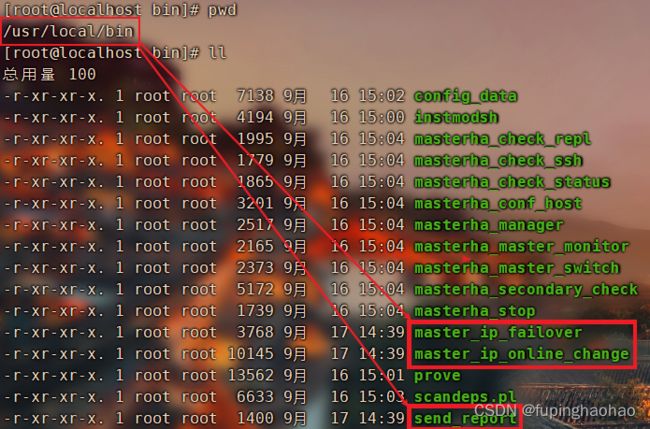
我们在【3.4.1.2.2安装 mha4mysql-manager】中可以得知,安装成功后,在/usr/local/bin下有了9个工具(脚本),除此之外,我们还需要自定义3个脚本。当然,这3个脚本可以在 /mha4mysql-manager/samples/script 下找到。
| 在 MHA Manager 节点上复制相关脚本到 /usr/local/bin 目录下,复制完后就多了下面三个文件。 |
|
|
|
|
| 工具(脚本)名称 |
作用 |
| master_ip_failover |
自动切换时VIP管理的脚本。 |
| master_ip_online_change |
在线切换时VIP管理的脚本:当 MHA Manager 检测到 master 不可用时,通过该脚本来进一步确认,降低误切的风险。 |
| send_report |
当发生故障切换时,可通过该脚本发送告警信息。 |
3.4.4.2 MHA Manager 配置文件
1).创建MHA的管理账号
| # ① 在三个节点(一主两从)上都要创建 MHA 管理的账号 grant all privileges on *.* to 'mhamanager'@'%' identified by 'mhamanager123456'; # ② 刷新 flush privileges; |
|
|
| # ③ 看看创建成功没 select host, user from mysql.user where user = 'mhamanager'; |
|
|


2).MHA Manager 配置
创建 MHA 软件目录并拷贝配置文件,这里使用 samples/app1.cnf 配置文件来管理 MySQL 节点服务器。
| # 创建配置文件目录 mkdir -p /etc/masterha cp samples/conf/app1.cnf /etc/masterha/ |
|
|
| # 对原有文件进行修改 vim app1.cnf |
|
|


修改后的 app1.cnf 文件内容如下:
| [server default] # 设置 manager 的工作目录 manager_workdir=/usr/local/mha/oth/app1 # 设置 manager 的日志 manager_log=/usr/local/mha/oth/app1/manager.log # 设置 master 默认保存 bin log 的位置,方便 MHA 可以找到 master 的日志。 # 这里的路径要与 MySQL 的 master 里配置的 bin log 位置一致。 master_binlog_dir=/usr/local/mysql/logs/binlogs # 设置 ssh 登录用户名 ssh_user=root # 设置 监控用户(即,MHA 的管理账户) user=mhamanager # 设置 监控用户的密码(即,MHA 的管理账户密码) password=mhamanager123456 # 设置 复制用户名【3.2.1.1.2创建复制用户】 repl_user=repluser # 设置 复制用户的密码 repl_password=654321 # 设置监控主库发送 ping 包的时间间隔,默认是 3 秒,尝试三次没有回应的时候会自动 failover ping_interval=1 # 设置远程 MySQL 在发生切换时 bin log 的保存位置 remote_workdir=/tmp # 设置自动 failover 时候的切换脚本(这个脚本就是【3.4.4.1 MHA Manager 脚本】章节中说明的那个脚本) master_ip_failover_script=/usr/local/bin/master_ip_failover # 设置手动切换时的切换脚本 master_ip_online_change_script=/usr/local/bin/master_ip_online_change # 设置发生切换后发送的报警脚本 report_script=/usr/local/bin/send_report # 指定检查的从服务器IP地址,即,一旦 MHA Manager 检测到 MySQL master 出了问题,MHA Manager 就会去判断其他两个 # slave 是否能建立到 master_ip 3306 端口的连接。 secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.73.143 -s 192.168.73.134 --user=root --master_host=192.168.73.107 --master_ip=192.168.73.107 --master_port=3306 shutdown_script="" [server1] hostname=192.168.73.107 port=3306 [server2] hostname=192.168.73.143 port=3306 # 设置为候选 master。如果设置该参数后,当发生主从切换时会将该从库提升为主库,即使这个从库不是集群中最新的slave candidate_master=1 check_repl_delay=0 [server3] hostname=192.168.73.134 port=3306 |
3.4.4.3 VIP 配置
MHA 是故障切换和主从提升的高可用软件,要完成故障切换,我们就需要配置 vip 功能。Vip也是为了应用透明,即当发生主从切换时对应用是无感知的。
配置VIP有两种方式:keepalived、MHA Manager 的 master_ip_failover 脚本,我们这里就采用第二种。
3.4.4.3.1 修改故障脚本代码
编辑脚本【/usr/local/bin/master_ip_failover】。
| #!/usr/bin/env perl ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => 'all'; use Getopt::Long; use MHA::DBHelper; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password ); ########## 【添加内容】 ########## # 虚拟 IP my $vip = '192.168.73.200/24'; my $key = '1'; my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; my $exit_code = 0; ################################# GetOptions( 'command=s' => \$command, 'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, 'new_master_password=s' => \$new_master_password, ); exit &main(); sub main { if ( $command eq "stop" || $command eq "stopssh" ) { # $orig_master_host, $orig_master_ip, $orig_master_port are passed. # If you manage master ip address at global catalog database, # invalidate orig_master_ip here. my $exit_code = 1; eval { # updating global catalog, etc $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { # all arguments are passed. # If you manage master ip address at global catalog database, # activate new_master_ip here. # You can also grant write access (create user, set read_only=0, etc) here. my $exit_code = 10; eval { my $new_master_handler = new MHA::DBHelper(); # args: hostname, port, user, password, raise_error_or_not $new_master_handler->connect( $new_master_ip, $new_master_port, $new_master_user, $new_master_password, 1 ); ## Set read_only=0 on the new master $new_master_handler->disable_log_bin_local(); print "Set read_only=0 on the new master.\n"; $new_master_handler->disable_read_only(); ## Creating an app user on the new master print "Creating app user on the new master..\n"; FIXME_xxx_create_user( $new_master_handler->{dbh} ); $new_master_handler->enable_log_bin_local(); $new_master_handler->disconnect(); ## Update master ip on the catalog database, etc # 把这一行注释掉,否则在【3.4.6.2检查整个集群的状态】那一步就会出错。 # FIXME_xxx; $exit_code = 0; }; if ($@) { warn $@; # If you want to continue failover, exit 10. exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { # do nothing exit 0; } else { &usage(); exit 1; } } sub usage { "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; } |
3.4.4.3.2 格式化故障脚本代码
格式化的目的是要去掉中文字符。
| # ① 先安装 dos2unix 工具 yum install dos2unix |
| # ② 格式化 master_ip_failover 脚本 dos2unix master_ip_failover |
|
|
3.4.4.3.3 给故障脚本代码增加执行权限
chmod +x /usr/local/bin/master_ip_failover
3.4.4.3.4 把脚本路径写入 MHA Manager 配置文件
| 编辑:vim /etc/masterha/app1.cnf |
| 在 [server default] 下添加内容(这部分内容在【3.4.4.2 MHA Manager 配置文件】章节已经配置,这里可以略过) # 设置自动 failover 时候的切换脚本(这个脚本就是【3.4.4.1 MHA Manager 脚本】章节中说明的那个脚本) master_ip_failover_script=/usr/local/bin/master_ip_failover |
3.4.4.3.5 master开启虚拟ip
因为这是MySQL集群中第一次开启虚拟ip,所以需要我们手动开启。
当MAH Manager启动后,如果发生了主从切换,那么MHA Manager就会帮我们自动进行虚拟ip漂移。
| 1).命令:ifconfig ens33:1 192.168.73.200/24 |
| 2).命令参数说明 ip地址 :master_ip_failover 中配置的 $vip(虚拟ip)。 ens33:1 :这里冒号后面的1取的是 master_ip_failover 中配置的 $key。 |
|
|

3.4.5 验证
3.4.5.1 MHA Manager 节点检查 SSH 无密码认证
| # 执行脚本 masterha_check_ssh(脚本在 /usr/local/bin 下) # 看到 [info] All SSH connection tests passed successfully. 提示才算通过。 masterha_check_ssh --conf=/etc/masterha/app1.cnf |
|
|

3.4.5.2 检查整个集群的状态
检查整个集群的状态,也就是检查 MySQL 的复制状况,这个环节非常非常重要,等同于 MHA Manager 的启动之前的检测。
在 MHA Manager 节点上测试 MySQL 主从连接情况。
| 1). 命令:masterha_check_repl --conf=/etc/masterha/app1.cnf |
| 2). master_check_repl 检测步骤 ① 读取配置文件/etc/masterha/,文件位置参见【3.4.4.2 MHA Manager 配置文件】 ② 检测配置文件中列出的 MySQL 服务器(识别主从) ③ 检测从库配置信息 A. read_only 参数 B. relay_log_purge 参数 ④ 检测复制过滤规则 ⑤ ssh等效性验证 ⑥ 检测主库保存 bin log 脚本(save_binary_log),主要是用于在 master 死掉后从 bin log 读取日志。 ⑦ 检测各个从库能否 apply 差量的 bin log(apply_diff_relay_logs) ⑧ 检测 IP 切换,如果有部署脚本的话,参见【3.4.4.3 VIP 配置】。 |
| save_binary_log、apply_diff_relay_logs:这两个文件在三台 MySQL 服务器上都有, 文件目录:/usr/local/bin
|
3.4.5.2.1 错误一
|
|
| 1). 错误:提示我们需要在 MySQL 的 slave 节点上设置参数 read_only=1。 |
| 2). 解决:修改 MySQL-slave 的系统参数 read_only # ① 设置只读模式 set global read_only=1; # ② 看一下设置成功没 show variables like 'read_only';
|

3.4.5.2.2 错误二
| 1). 错误 [error][/usr/local/share/perl5/MHA/Server.pm, ln398] 192.168.73.143(192.168.73.143:3306): User repluser does not exist or does not have REPLICATION SLAVE privilege! Other slaves can not start replication from this host. |
|
|
| 2). 原因 192.168.73.143 主机上没有添加用户或者权限问题,重新添加即可。 |
| 3). 解决(解决方式同【3.2.1.1.2 创建复制用户】) # ① 在三个节点(一主两从)上都要创建 复制账号 grant replication slave on *.* to repluser@"%" identified by "654321"; # ② 刷新 flush privileges; |
3.4.5.2.3 错误三
| 1). 报错:[/usr/local/share/perl5/MHA/MasterMonitor.pm, ln208] Slaves settings check failed! |
| 2). 错误提示:忘截图了,在网上找的。
[root@mha_manager ~]# masterha_check_repl -conf=/etc/masterha/app1.cnf Can't exec "mysqlbinlog": 没有那个文件或目录 at /usr/local/share/perl5/MHA/BinlogManager.pm line 106. mysqlbinlog version command failed with rc 1:0, please verify PATH, LD_LIBRARY_PATH, and client options at /usr/local/bin/apply_diff_relay_logs line 493. Fri Jan 10 11:01:35 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln208] Slaves settings check failed! Fri Jan 10 11:01:35 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln416] Slave configuration failed. Fri Jan 10 11:01:35 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/local/bin/masterha_check_repl line 48. Fri Jan 10 11:01:35 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers. Fri Jan 10 11:01:35 2020 - [info] Got exit code 1 (Not master dead). MySQL Replication Health is NOT OK! |
| 3). 原因:Can’t exec “mysqlbinlog”: 没有那个文件或目录 at /usr/local/share/perl5/MHA/BinlogManager.pm line 106. |
| 4). 解决:MySQL集群中所有节点(一主两从)都创建软链接 # ① 注意查看各自服务器的 MySQL 安装目录 ln -s /usr/local/mysql/bin/mysqlbinlog /usr/local/bin/ |

3.4.5.2.4 错误四
| 1). 报错:Testing mysql connection and privileges…sh: mysql: 未找到命令 |
| 2). 错误提示:忘截图了,在网上找的。 Fri Jan 10 11:20:21 2020 - [info] Connecting to [email protected](192.168.79.135:22).. Checking slave recovery environment settings.. Opening /usr/local/mysql/data/relay-log.info ... ok. Relay log found at /usr/local/mysql/data, up to relay-log-bin.000043 Temporary relay log file is /usr/local/mysql/data/relay-log-bin.000043 Testing mysql connection and privileges..sh: mysql: 未找到命令 mysql command failed with rc 127:0! at /usr/local/bin/apply_diff_relay_logs line 375. main::check() called at /usr/local/bin/apply_diff_relay_logs line 497 eval {...} called at /usr/local/bin/apply_diff_relay_logs line 475 main::main() called at /usr/local/bin/apply_diff_relay_logs line 120 Fri Jan 10 11:20:21 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln208] Slaves settings check failed! Fri Jan 10 11:20:21 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln416] Slave configuration failed. Fri Jan 10 11:20:21 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/local/bin/masterha_check_repl line 48. Fri Jan 10 11:20:21 2020 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers. Fri Jan 10 11:20:21 2020 - [info] Got exit code 1 (Not master dead). MySQL Replication Health is NOT OK! |
| 3). 原因:没有mysql命令 |
| 4). 解决:创建mysql软链接 ln -s /usr/local/mysql/bin/mysql /usr/local/bin/
|

3.4.5.2.5 成功了
打印信息如下:
| Sat Sep 18 10:05:09 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Sat Sep 18 10:05:09 2021 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. # ① 读取配置文件 Sat Sep 18 10:05:09 2021 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Sat Sep 18 10:05:09 2021 - [info] MHA::MasterMonitor version 0.58. Sat Sep 18 10:05:10 2021 - [info] GTID failover mode = 0 # ② 开始检测配置文件中列出的 MySQL 服务器(一主两从) Sat Sep 18 10:05:10 2021 - [info] Dead Servers: Sat Sep 18 10:05:10 2021 - [info] Alive Servers: Sat Sep 18 10:05:10 2021 - [info] 192.168.73.107(192.168.73.107:3306) Sat Sep 18 10:05:10 2021 - [info] 192.168.73.143(192.168.73.143:3306) Sat Sep 18 10:05:10 2021 - [info] 192.168.73.134(192.168.73.134:3306) Sat Sep 18 10:05:10 2021 - [info] Alive Slaves: Sat Sep 18 10:05:10 2021 - [info] 192.168.73.143(192.168.73.143:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Sat Sep 18 10:05:10 2021 - [info] Replicating from 192.168.73.107(192.168.73.107:3306) Sat Sep 18 10:05:10 2021 - [info] Primary candidate for the new Master (candidate_master is set) Sat Sep 18 10:05:10 2021 - [info] 192.168.73.134(192.168.73.134:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Sat Sep 18 10:05:10 2021 - [info] Replicating from 192.168.73.107(192.168.73.107:3306) Sat Sep 18 10:05:10 2021 - [info] Current Alive Master: 192.168.73.107(192.168.73.107:3306) # ③ 检测从库配置信息 Sat Sep 18 10:05:10 2021 - [info] Checking slave configurations.. # ④ 检测复制过滤规则 Sat Sep 18 10:05:10 2021 - [info] Checking replication filtering settings.. Sat Sep 18 10:05:10 2021 - [info] binlog_do_db= , binlog_ignore_db= Sat Sep 18 10:05:10 2021 - [info] Replication filtering check ok. Sat Sep 18 10:05:10 2021 - [info] GTID (with auto-pos) is not supported # ⑤ ssh 等效性验证 Sat Sep 18 10:05:10 2021 - [info] Starting SSH connection tests.. Sat Sep 18 10:05:23 2021 - [info] All SSH connection tests passed successfully. Sat Sep 18 10:05:23 2021 - [info] Checking MHA Node version.. Sat Sep 18 10:05:24 2021 - [info] Version check ok. Sat Sep 18 10:05:24 2021 - [info] Checking SSH publickey authentication settings on the current master.. Sat Sep 18 10:05:25 2021 - [info] HealthCheck: SSH to 192.168.73.107 is reachable. Sat Sep 18 10:05:25 2021 - [info] Master MHA Node version is 0.58. Sat Sep 18 10:05:25 2021 - [info] Checking recovery script configurations on 192.168.73.107(192.168.73.107:3306).. # ⑥ 检测主库保存 bin log 脚本 Sat Sep 18 10:05:25 2021 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/usr/local/mysql/logs/binlogs --output_file=/tmp/save_binary_logs_test --manager_version=0.58 --start_file=mysql-bin.000001 Sat Sep 18 10:05:25 2021 - [info] Connecting to [email protected](192.168.73.107:22).. Creating /tmp if not exists.. ok. Checking output directory is accessible or not.. ok. Binlog found at /usr/local/mysql/logs/binlogs, up to mysql-bin.000001 Sat Sep 18 10:05:26 2021 - [info] Binlog setting check done. # ⑦ 检测各个从库能否 apply 差量 bin log Sat Sep 18 10:05:26 2021 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers.. # A. 检测第一个从库 Sat Sep 18 10:05:26 2021 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='mhamanager' --slave_host=192.168.73.143 --slave_ip=192.168.73.143 --slave_port=3306 --workdir=/tmp --target_version=5.7.33-log --manager_version=0.58 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx Sat Sep 18 10:05:26 2021 - [info] Connecting to [email protected](192.168.73.143:22).. Checking slave recovery environment settings.. Opening /usr/local/mysql/data/relay-log.info ... ok. Relay log found at /usr/local/mysql/logs/relaylogs, up to mysql-relay.000003 Temporary relay log file is /usr/local/mysql/logs/relaylogs/mysql-relay.000003 Checking if super_read_only is defined and turned on.. not present or turned off, ignoring. Testing mysql connection and privileges.. mysql: [Warning] Using a password on the command line interface can be insecure. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. # B. 检测第二个从库 Sat Sep 18 10:05:27 2021 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='mhamanager' --slave_host=192.168.73.134 --slave_ip=192.168.73.134 --slave_port=3306 --workdir=/tmp --target_version=5.7.33-log --manager_version=0.58 --relay_log_info=/usr/local/mysql/data/relay-log.info --relay_dir=/usr/local/mysql/data/ --slave_pass=xxx Sat Sep 18 10:05:27 2021 - [info] Connecting to [email protected](192.168.73.134:22).. Checking slave recovery environment settings.. Opening /usr/local/mysql/data/relay-log.info ... ok. Relay log found at /usr/local/mysql/logs/relaylogs, up to mysql-relay.000004 Temporary relay log file is /usr/local/mysql/logs/relaylogs/mysql-relay.000004 Checking if super_read_only is defined and turned on.. not present or turned off, ignoring. Testing mysql connection and privileges.. mysql: [Warning] Using a password on the command line interface can be insecure. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Sat Sep 18 10:05:27 2021 - [info] Slaves settings check done. Sat Sep 18 10:05:27 2021 - [info] 192.168.73.107(192.168.73.107:3306) (current master) +--192.168.73.143(192.168.73.143:3306) +--192.168.73.134(192.168.73.134:3306) Sat Sep 18 10:05:27 2021 - [info] Checking replication health on 192.168.73.143.. Sat Sep 18 10:05:27 2021 - [info] ok. Sat Sep 18 10:05:27 2021 - [info] Checking replication health on 192.168.73.134.. Sat Sep 18 10:05:27 2021 - [info] ok. # ⑧ 检测 IP 切换 # 如果 /etc/masterha/app1.cnf (MHA Manager)中没有配置 master_ip_failover_script,则这里就会提示 master_ip_failover_script is not defined. Sat Sep 18 14:10:23 2021 - [info] Checking master_ip_failover_script status: Sat Sep 18 14:10:23 2021 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.73.107 --orig_master_ip=192.168.73.107 --orig_master_port=3306 Sat Sep 18 14:10:23 2021 - [info] OK. Sat Sep 18 10:05:27 2021 - [warning] shutdown_script is not defined. Sat Sep 18 10:05:27 2021 - [info] Got exit code 0 (Not master dead). # 提示成功 MySQL Replication Health is OK. |
3.4.5.3 检查 MHA Manager 状态
| 命令:masterha_check_status --conf=/etc/masterha/app1.cnf |
|
|
| 备注:如果正常,会显示“PING_OK”,否则会显示“NOT_RUNNING”,这代表 MHA 监控没有开启。 |
3.4.5.4 开启 MHA Manager 监控
可以跳过下面的启动命令,直接看【3.4.5.4.1 BUG】。
| 1). 启动命令 nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /usr/local/mha/oth/app1/manager.log 2>&1 & |
| 2). 参数说明 # --remove_dead_master_conf:该参数代表当发生主从切换后,老的主库的 ip 将会从配置文件中移除 # --manger_log:日志存放位置 # --ignore_last_failover:在缺省情况下,如果 MHA 检测到连续发生宕机,且两次宕机间隔不足 8 小时的话,则不会进行 Failover, 之所以这样限制是为了避免 ping-pong 效应 # 该参数代表忽略上次 MHA 触发切换产生的文件,默认情况下,MHA 发生切换后会在日志目录,也就是上面设置的app1.cnf参数文件中的manager_workdiw中产生的app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便进行切换,启动时添加参数 --ignore_last_failover。 # 日志路径在 MHA Manager 的配置文件中有说明
|
| 3). 结果 启动完成后再看看 MHA Manager 的状态,这里显示的状态为【PING_OK】。 【注意】:注意看这里的 master 显示的是 192.168.73.107。
|
| # 也可以用 Linux 命令查看一下 MHA Manager 是不是启起来了 ps -ef | grep manager
|


3.4.5.4.1 BUG
我们开两个窗口,窗口A开启 MHA Manager,另一个窗口B动态刷新 MHA Manager 的日志(tail -F /usr/local/mha/oth/app1/manager.log)。
问题:
启动 MHA Manager 后,关闭窗口 A,在窗口B的动态日志中可以看到【Got terminate signal. Exit.】,收到一个终止信号,然后就退出了。

我们可以使用【masterha_check_status --conf=/etc/masterha/app1.cnf】检查一下 MHA Manager 的状态。
![]()
解决:
我们在启动的时候是加了 nohup 的,但是当窗口关闭的时候进程还是退出了。有人说是 xshell 工具的bug。所以,我们还是把命令写到脚本中。脚本内容与启动命令大致相同,如下:
| nohup /usr/local/bin/masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /usr/local/mha/oth/app1/manager.log 2>&1 & |

当我们再次关闭窗口A时,窗口B的动态日志没有任何异常。
3.4.5.5 关闭 MHA Manager 监控
| 1). 停止命令 masterha_stop --conf=/etc/masterha/app1.cnf |
| 2). 结果 停止后再看看 MHA Manager 的状态,这里显示的状态为【NOT_RUNNING】。
|
| 3). 用 Linux 命令查看一下,MHA Manager没了
|

3.4.6 relay log
设置 relay log 的清除方式(在两台 slave 节点上)。
3.4.6.1说明
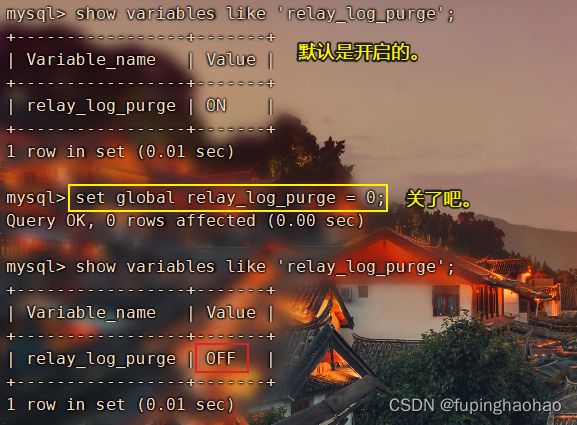
MHA 在发生切换的过程中,从库的恢复过程中依赖于 relay log 的相关信息。所以,这里需要将 relay log 的自动清除设置为 OFF,改用采取手动清除 relay log 的方式。
在默认情况下,从服务器上的中继日志会在 sql 线程执行完毕后会被自动删除。但是在 MHA 环境中,这些中继日志在恢复其他从服务器时可能会被用到。所以,需要禁用 slave 节点的中继日志的自动删除功能。
3.4.6.2执行
1).禁用两台 slave 节点的中继日志的自动删除功能
| # ① 关闭 rely log 的自动删除功能 set global relay_log_purge = 0; # ② 查看一下 show variables like 'relay_log_purge'; |
|
|
2).设置定期清理 relay 脚本
我们在【3.4.1.2.1安装 mha4mysql-node】中可以看出,安装完成后,在【/usr/local/bin】目录下有一个脚本【purge_relay_logs】。
这个脚本就是用来定期清理 relay log 的。
// TODO
3.4.7 邮件提醒
我们在【3.4.4.1 MHA Manager 脚本】中提到一个脚本【/usr/local/bin/send_report】。该脚本的作用就是:当发生故障切换时,可通过该脚本发送告警信息。
3.4.7.1 邮件脚本格式化
我们这里需要对文件进行格式化,去掉中文字符,否则在发生故障迁移时,邮件发送会报错【send_report: /usr/bin/perl^M: 坏的解释器: 没有那个文件或目录】。
这个错误的原因:send_report 这个文件是在 Windows 下编辑过的,在Windows下,每一行的结尾都是\n\r,而在Linux下文件结尾是\n。用命令【cat -A send_report】查看文件可以看到\r这个字符被显示为【^M】。
格式化命令:dos2unix send_report。
3.4.7.2 安装邮件模块
使用 perl 发送邮件需要用到 Mail::SendEasy 模块。
命令:perl -MCPAN -e shell
进入 cpan 命令界面,然后进行安装,安装命令 install Mail::SendEasy
【备注】:可以使用命令【perldoc -t perllocal | grep "Module"】查看安装了哪些perl模块。

3.4.7.3 邮件编辑
编辑:vim /usr/local/bin/send_report
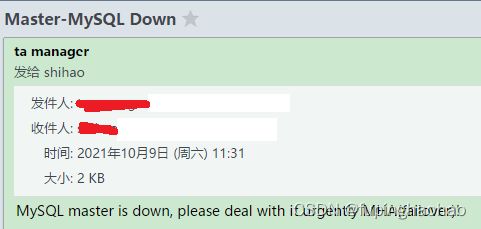
| #! /usr/bin/perl -w use strict; use warnings FATAL => 'all'; print "mail to start............\n"; use Mail::SendEasy; my $mail = new Mail::SendEasy( smtp => 'smtp.aliyun.com', user => '[email protected]', pass => "ysstech0818", ); my $status = $mail->send( from => '[email protected]', from_title => 'ta manager', to => '[email protected]', subject => "Master-MySQL Down", msg => "MySQL master is down, please deal with it urgently MHA(failover)!", ); if (!$status) { print $mail->error; } exit 0; |
3.4.7.4 测试
直接使用 perl 执行即可,命令 perl send_report

查看邮件就能看得到了
3.4.8 故障迁移测试
3.4.8.1 在MySQL-master节点上停止MySQL服务
# 107 服务
service mysqld stop
3.4.8.2 MHA 反应
3.4.8.2.1 正常自动切换一次后,MHA Manager 进程会停掉
| # 检查 MHA Manager 的状态 masterha_check_status --conf=/etc/masterha/app1.cnf |
|
|
| 可以看到 MHA Manager 停掉了。 |
3.4.8.2.2 app1.failover.complete 文件
发生自动切换后,在 /usr/local/mha/oth/app1 目录下生产 app1.failover.complete 文件。
如果再次发生切换需要删除 app1.failover.complete 文件。
当然,启动参数上配置了 --ignore_last_failover,所以也不需要删除该文件。

3.4.8.2.3 MHA Manager 配置文件app1.cnf
MHA Manager 会修改配置文件/etc/masterha/app1.cnf 的内容,将宕机的 master 节点删除了。文件内容如下:可以看到 [server1] 不见了。
| [server default] manager_log=/usr/local/mha/oth/app1/manager.log manager_workdir=/usr/local/mha/oth/app1 master_binlog_dir=/usr/local/mysql/logs/binlogs master_ip_failover_script=/usr/local/bin/master_ip_failover master_ip_online_change_script=/usr/local/bin/master_ip_online_change password=mhamanager123456 ping_interval=1 remote_workdir=/tmp repl_password=654321 repl_user=repluser report_script=/usr/local/bin/send_report secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.73.143 -s 192.168.73.134 --user=root --master_host=192.168.73.107 -- master_ip=192.168.73.107 --master_port=3306 shutdown_script="" ssh_user=root user=mhamanager [server2] candidate_master=1 check_repl_delay=0 hostname=192.168.73.143 port=3306 [server3] hostname=192.168.73.134 port=3306 |
3.4.8.2.4 MHA Manager 日志
这里的日志是基于(master-143,slave1-107,slave2-134)这样一个MySQL集群。(因为当107为master时的日志没来得及写)
| Thu Oct 14 19:41:48 2021 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away) # 1. 多种线路检测 master 是否存活(当 MHA Manager 检测到 master 不可用时,通过该脚本来进一步确认,降低误切的风险) Thu Oct 14 19:41:48 2021 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s 192.168.73.107 -s 192.168.73.134 --user=root --master_host=192.168.73.143 --master_ip=192.168.73.143 --master_port=3306 --user=root --master_host=192.168.73.143 --master_ip=192.168.73.143 --master_port=3306 --master_user=mhamanager --master_password=mhamanager123456 --ping_type=SELECT Thu Oct 14 19:41:48 2021 - [info] Executing SSH check script: save_binary_logs --command=test --start_pos=4 --binlog_dir=/usr/local/mysql/logs/binlogs --output_file=/tmp/save_binary_logs_test --manager_version=0.58 --binlog_prefix=mysql-bin Monitoring server 192.168.73.107 is reachable, Master is not reachable from 192.168.73.107. OK. Thu Oct 14 19:41:49 2021 - [info] HealthCheck: SSH to 192.168.73.143 is reachable. Thu Oct 14 19:41:49 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.73.143' (111)) Thu Oct 14 19:41:49 2021 - [warning] Connection failed 2 time(s).. Monitoring server 192.168.73.134 is reachable, Master is not reachable from 192.168.73.134. OK. Thu Oct 14 19:41:49 2021 - [info] Master is not reachable from all other monitoring servers. Failover should start. Thu Oct 14 19:41:50 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.73.143' (111)) Thu Oct 14 19:41:50 2021 - [warning] Connection failed 3 time(s).. Thu Oct 14 19:41:51 2021 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.73.143' (111)) Thu Oct 14 19:41:51 2021 - [warning] Connection failed 4 time(s).. Thu Oct 14 19:41:51 2021 - [warning] Master is not reachable from health checker! Thu Oct 14 19:41:51 2021 - [warning] Master 192.168.73.143(192.168.73.143:3306) is not reachable! Thu Oct 14 19:41:51 2021 - [warning] SSH is reachable. Thu Oct 14 19:41:51 2021 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/masterha/app1.cnf again, and trying to connect to all servers to check server status.. Thu Oct 14 19:41:51 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Oct 14 19:41:51 2021 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Thu Oct 14 19:41:51 2021 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Thu Oct 14 19:41:52 2021 - [info] GTID failover mode = 0 Thu Oct 14 19:41:52 2021 - [info] Dead Servers: Thu Oct 14 19:41:52 2021 - [info] 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:52 2021 - [info] Alive Servers: Thu Oct 14 19:41:52 2021 - [info] 192.168.73.107(192.168.73.107:3306) Thu Oct 14 19:41:52 2021 - [info] 192.168.73.134(192.168.73.134:3306) Thu Oct 14 19:41:52 2021 - [info] Alive Slaves: Thu Oct 14 19:41:52 2021 - [info] 192.168.73.107(192.168.73.107:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:52 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:52 2021 - [info] Primary candidate for the new Master (candidate_master is set) Thu Oct 14 19:41:52 2021 - [info] 192.168.73.134(192.168.73.134:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:52 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:52 2021 - [info] Checking slave configurations.. Thu Oct 14 19:41:52 2021 - [info] Checking replication filtering settings.. Thu Oct 14 19:41:52 2021 - [info] Replication filtering check ok. Thu Oct 14 19:41:52 2021 - [info] Master is down! Thu Oct 14 19:41:52 2021 - [info] Terminating monitoring script. Thu Oct 14 19:41:52 2021 - [info] Got exit code 20 (Master dead). Thu Oct 14 19:41:52 2021 - [info] MHA::MasterFailover version 0.58. # 2. 开始故障转移 Thu Oct 14 19:41:52 2021 - [info] Starting master failover. Thu Oct 14 19:41:52 2021 - [info] # 2.1 一阶段:配置文件检查,这个阶段会检查整个集群的配置 Thu Oct 14 19:41:52 2021 - [info] * Phase 1: Configuration Check Phase.. Thu Oct 14 19:41:52 2021 - [info] Thu Oct 14 19:41:53 2021 - [info] GTID failover mode = 0 Thu Oct 14 19:41:53 2021 - [info] Dead Servers: Thu Oct 14 19:41:53 2021 - [info] 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:53 2021 - [info] Checking master reachability via MySQL(double check)... Thu Oct 14 19:41:53 2021 - [info] ok. Thu Oct 14 19:41:53 2021 - [info] Alive Servers: Thu Oct 14 19:41:53 2021 - [info] 192.168.73.107(192.168.73.107:3306) Thu Oct 14 19:41:53 2021 - [info] 192.168.73.134(192.168.73.134:3306) Thu Oct 14 19:41:53 2021 - [info] Alive Slaves: Thu Oct 14 19:41:53 2021 - [info] 192.168.73.107(192.168.73.107:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:53 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:53 2021 - [info] Primary candidate for the new Master (candidate_master is set) Thu Oct 14 19:41:53 2021 - [info] 192.168.73.134(192.168.73.134:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:53 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:53 2021 - [info] Starting Non-GTID based failover. Thu Oct 14 19:41:53 2021 - [info] Thu Oct 14 19:41:53 2021 - [info] ** Phase 1: Configuration Check Phase completed. Thu Oct 14 19:41:53 2021 - [info] # 2.2 阶段二:针对宕机的 master 进行处理。这个阶段包含虚拟 ip 摘除等。 Thu Oct 14 19:41:53 2021 - [info] Thu Oct 14 19:41:53 2021 - [info] * Phase 2: Dead Master Shutdown Phase.. Thu Oct 14 19:41:53 2021 - [info] Thu Oct 14 19:41:53 2021 - [info] Forcing shutdown so that applications never connect to the current master.. Thu Oct 14 19:41:53 2021 - [info] Executing master IP deactivation script: # 这里使用到了脚本 master_ip_failover(自动切换时VIP管理的脚本) Thu Oct 14 19:41:53 2021 - [info] /usr/local/bin/master_ip_failover_sh --orig_master_host=192.168.73.143 --orig_master_ip=192.168.73.143 --orig_master_port=3306 --command=stopssh --ssh_user=root Disabling the VIP an old master: 192.168.73.143 Thu Oct 14 19:41:54 2021 - [info] done. Thu Oct 14 19:41:54 2021 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. Thu Oct 14 19:41:54 2021 - [info] * Phase 2: Dead Master Shutdown Phase completed. Thu Oct 14 19:41:54 2021 - [info] # 2.3 阶段三:master 恢复 Thu Oct 14 19:41:54 2021 - [info] * Phase 3: Master Recovery Phase.. Thu Oct 14 19:41:54 2021 - [info] # 2.3.1 获取最新的 slave Thu Oct 14 19:41:54 2021 - [info] * Phase 3.1: Getting Latest Slaves Phase.. Thu Oct 14 19:41:54 2021 - [info] Thu Oct 14 19:41:54 2021 - [info] The latest binary log file/position on all slaves is mysql-bin.000006:1322 Thu Oct 14 19:41:54 2021 - [info] Latest slaves (Slaves that received relay log files to the latest): Thu Oct 14 19:41:54 2021 - [info] 192.168.73.107(192.168.73.107:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:54 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:54 2021 - [info] Primary candidate for the new Master (candidate_master is set) Thu Oct 14 19:41:54 2021 - [info] 192.168.73.134(192.168.73.134:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:54 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:54 2021 - [info] The oldest binary log file/position on all slaves is mysql-bin.000006:1322 Thu Oct 14 19:41:54 2021 - [info] Oldest slaves: Thu Oct 14 19:41:54 2021 - [info] 192.168.73.107(192.168.73.107:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:54 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:54 2021 - [info] Primary candidate for the new Master (candidate_master is set) Thu Oct 14 19:41:54 2021 - [info] 192.168.73.134(192.168.73.134:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:54 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:54 2021 - [info] # 2.3.2 保存和复制 master 的二进制日志,这里用到了脚本 save_binary_logs Thu Oct 14 19:41:54 2021 - [info] * Phase 3.2: Saving Dead Master's Binlog Phase.. Thu Oct 14 19:41:54 2021 - [info] Thu Oct 14 19:41:55 2021 - [info] Fetching dead master's binary logs.. Thu Oct 14 19:41:55 2021 - [info] Executing command on the dead master 192.168.73.143(192.168.73.143:3306): save_binary_logs --command=save --start_file=mysql-bin.000006 --start_pos=1322 --binlog_dir=/usr/local/mysql/logs/binlogs --output_file=/tmp/saved_master_binlog_from_192.168.73.143_3306_20211014194152.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.58 Creating /tmp if not exists.. ok. Concat binary/relay logs from mysql-bin.000006 pos 1322 to mysql-bin.000006 EOF into /tmp/saved_master_binlog_from_192.168.73.143_3306_20211014194152.binlog .. Binlog Checksum enabled Dumping binlog format description event, from position 0 to 154.. ok. No need to dump effective binlog data from /usr/local/mysql/logs/binlogs/mysql-bin.000006 (pos starts 1322, filesize 1322). Skipping. Binlog Checksum enabled /tmp/saved_master_binlog_from_192.168.73.143_3306_20211014194152.binlog has no effective data events. Event not exists. Thu Oct 14 19:41:56 2021 - [info] Additional events were not found from the orig master. No need to save. Thu Oct 14 19:41:56 2021 - [info] # 2.3.3 决定新的 master Thu Oct 14 19:41:56 2021 - [info] * Phase 3.3: Determining New Master Phase.. Thu Oct 14 19:41:56 2021 - [info] Thu Oct 14 19:41:56 2021 - [info] Finding the latest slave that has all relay logs for recovering other slaves.. Thu Oct 14 19:41:56 2021 - [info] All slaves received relay logs to the same position. No need to resync each other. Thu Oct 14 19:41:56 2021 - [info] Searching new master from slaves.. Thu Oct 14 19:41:56 2021 - [info] Candidate masters from the configuration file: Thu Oct 14 19:41:56 2021 - [info] 192.168.73.107(192.168.73.107:3306) Version=5.7.33-log (oldest major version between slaves) log-bin:enabled Thu Oct 14 19:41:56 2021 - [info] Replicating from 192.168.73.143(192.168.73.143:3306) Thu Oct 14 19:41:56 2021 - [info] Primary candidate for the new Master (candidate_master is set) Thu Oct 14 19:41:56 2021 - [info] Non-candidate masters: Thu Oct 14 19:41:56 2021 - [info] Searching from candidate_master slaves which have received the latest relay log events.. Thu Oct 14 19:41:56 2021 - [info] New master is 192.168.73.107(192.168.73.107:3306) Thu Oct 14 19:41:56 2021 - [info] Starting master failover.. Thu Oct 14 19:41:56 2021 - [info] From: 192.168.73.143(192.168.73.143:3306) (current master) +--192.168.73.107(192.168.73.107:3306) +--192.168.73.134(192.168.73.134:3306) To: 192.168.73.107(192.168.73.107:3306) (new master) +--192.168.73.134(192.168.73.134:3306) Thu Oct 14 19:41:56 2021 - [info] Thu Oct 14 19:41:56 2021 - [info] * Phase 3.4: New Master Diff Log Generation Phase.. Thu Oct 14 19:41:56 2021 - [info] Thu Oct 14 19:41:56 2021 - [info] This server has all relay logs. No need to generate diff files from the latest slave. Thu Oct 14 19:41:56 2021 - [info] Thu Oct 14 19:41:56 2021 - [info] * Phase 3.5: Master Log Apply Phase.. Thu Oct 14 19:41:56 2021 - [info] Thu Oct 14 19:41:56 2021 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed. Thu Oct 14 19:41:56 2021 - [info] Starting recovery on 192.168.73.107(192.168.73.107:3306).. Thu Oct 14 19:41:56 2021 - [info] This server has all relay logs. Waiting all logs to be applied.. Thu Oct 14 19:41:56 2021 - [info] done. Thu Oct 14 19:41:56 2021 - [info] All relay logs were successfully applied. Thu Oct 14 19:41:56 2021 - [info] Getting new master's binlog name and position.. Thu Oct 14 19:41:56 2021 - [info] mysql-bin.000010:154 # 所有其他从机应从此处开始复制,这个地方【非常非常非常】重要,下面的故障修复时会用到。 # 这里说明了新master的ip、二进制日志文件名以及位置。 Thu Oct 14 19:41:56 2021 - [info]] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.73.107', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=154, MASTER_USER='repluser', MASTER_PASSWORD='xxx'; # 这里使用到了脚本 master_ip_failover(自动切换时VIP管理的脚本) Thu Oct 14 19:41:56 2021 - [info] Executing master IP activate script: Thu Oct 14 19:41:56 2021 - [info] /usr/local/bin/master_ip_failover_sh --command=start --ssh_user=root --orig_master_host=192.168.73.143 --orig_master_ip=192.168.73.143 --orig_master_port=3306 --new_master_host=192.168.73.107 --new_master_ip=192.168.73.107 --new_master_port=3306 --new_master_user='mhamanager' --new_master_password=xxx Set read_only=0 on the new master. Enabling the VIP 192.168.73.200 on the new master: 192.168.73.107 Thu Oct 14 19:41:57 2021 - [info] OK. Thu Oct 14 19:41:57 2021 - [info] ** Finished master recovery successfully. Thu Oct 14 19:41:57 2021 - [info] * Phase 3: Master Recovery Phase completed. Thu Oct 14 19:41:57 2021 - [info] Thu Oct 14 19:41:57 2021 - [info] * Phase 4: Slaves Recovery Phase.. Thu Oct 14 19:41:57 2021 - [info] Thu Oct 14 19:41:57 2021 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase.. Thu Oct 14 19:41:57 2021 - [info] Thu Oct 14 19:41:57 2021 - [info] -- Slave diff file generation on host 192.168.73.134(192.168.73.134:3306) started, pid: 86192. Check tmp log /usr/local/mha/oth/app1/192.168.73.134_3306_20211014194152.log if it takes time.. Thu Oct 14 19:41:58 2021 - [info] Thu Oct 14 19:41:58 2021 - [info] Log messages from 192.168.73.134 ... Thu Oct 14 19:41:58 2021 - [info] Thu Oct 14 19:41:57 2021 - [info] This server has all relay logs. No need to generate diff files from the latest slave. Thu Oct 14 19:41:58 2021 - [info] End of log messages from 192.168.73.134. Thu Oct 14 19:41:58 2021 - [info] -- 192.168.73.134(192.168.73.134:3306) has the latest relay log events. Thu Oct 14 19:41:58 2021 - [info] Generating relay diff files from the latest slave succeeded. Thu Oct 14 19:41:58 2021 - [info] Thu Oct 14 19:41:58 2021 - [info] * Phase 4.2: Starting Parallel Slave Log Apply Phase.. Thu Oct 14 19:41:58 2021 - [info] Thu Oct 14 19:41:58 2021 - [info] -- Slave recovery on host 192.168.73.134(192.168.73.134:3306) started, pid: 86222. Check tmp log /usr/local/mha/oth/app1/192.168.73.134_3306_20211014194152.log if it takes time.. Thu Oct 14 19:41:59 2021 - [info] Thu Oct 14 19:41:59 2021 - [info] Log messages from 192.168.73.134 ... Thu Oct 14 19:41:59 2021 - [info] Thu Oct 14 19:41:58 2021 - [info] Starting recovery on 192.168.73.134(192.168.73.134:3306).. Thu Oct 14 19:41:58 2021 - [info] This server has all relay logs. Waiting all logs to be applied.. Thu Oct 14 19:41:58 2021 - [info] done. Thu Oct 14 19:41:58 2021 - [info] All relay logs were successfully applied. Thu Oct 14 19:41:58 2021 - [info] Resetting slave 192.168.73.134(192.168.73.134:3306) and starting replication from the new master 192.168.73.107(192.168.73.107:3306).. Thu Oct 14 19:41:58 2021 - [info] Executed CHANGE MASTER. Thu Oct 14 19:41:58 2021 - [info] Slave started. Thu Oct 14 19:41:59 2021 - [info] End of log messages from 192.168.73.134. Thu Oct 14 19:41:59 2021 - [info] -- Slave recovery on host 192.168.73.134(192.168.73.134:3306) succeeded. Thu Oct 14 19:41:59 2021 - [info] All new slave servers recovered successfully. Thu Oct 14 19:41:59 2021 - [info] Thu Oct 14 19:41:59 2021 - [info] * Phase 5: New master cleanup phase.. Thu Oct 14 19:41:59 2021 - [info] Thu Oct 14 19:41:59 2021 - [info] Resetting slave info on the new master.. Thu Oct 14 19:41:59 2021 - [info] 192.168.73.107: Resetting slave info succeeded. Thu Oct 14 19:41:59 2021 - [info] Master failover to 192.168.73.107(192.168.73.107:3306) completed successfully. Thu Oct 14 19:41:59 2021 - [info] Deleted server1 entry from /etc/masterha/app1.cnf . Thu Oct 14 19:41:59 2021 - [info] ----- Failover Report ----- app1: MySQL Master failover 192.168.73.143(192.168.73.143:3306) to 192.168.73.107(192.168.73.107:3306) succeeded Master 192.168.73.143(192.168.73.143:3306) is down! Check MHA Manager logs at mha-manager:/usr/local/mha/oth/app1/manager.log for details. Started automated(non-interactive) failover. Invalidated master IP address on 192.168.73.143(192.168.73.143:3306) The latest slave 192.168.73.107(192.168.73.107:3306) has all relay logs for recovery. Selected 192.168.73.107(192.168.73.107:3306) as a new master. 192.168.73.107(192.168.73.107:3306): OK: Applying all logs succeeded. 192.168.73.107(192.168.73.107:3306): OK: Activated master IP address. 192.168.73.134(192.168.73.134:3306): This host has the latest relay log events. Generating relay diff files from the latest slave succeeded. 192.168.73.134(192.168.73.134:3306): OK: Applying all logs succeeded. Slave started, replicating from 192.168.73.107(192.168.73.107:3306) 192.168.73.107(192.168.73.107:3306): Resetting slave info succeeded. Master failover to 192.168.73.107(192.168.73.107:3306) completed successfully. Thu Oct 14 19:41:59 2021 - [info] Sending mail.. mail to start............ |
3.4.8.2.4.1 日志关键点
① 从日志【Master failover to 192.168.73.143(192.168.73.143:3306) completed successfully】可以看出来,备选 master 已经上位了。
② 从日志【mail to start............】可以看出邮件发送完成。邮件如下:

③ 日志【All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.73.143', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=154, MASTER_USER='repluser', MASTER_PASSWORD='xxx';】,这个日志信息告诉我们,等会故障恢复的时候,在进行数据同步(设置主从关系)时应该从哪个二进制日志的哪个位置开始。
④ 日志中有两处使用到了脚本【master_ip_failover_sh】,第一次是停止master上的虚拟ip,第二次是在新master上绑定虚拟ip。
3.4.8.2.4 虚拟ip漂移
1). 在自动切换完成后,MHA Manager将给新master-143绑定了虚拟ip。

2). 在自动切换完成后,MHA Manager将旧master-107上的虚拟ip给删了。

3.4.9 主从复制测试
此时,MySQL-master(107)服务器已经停掉了。新的 master 变为了 143(通常 show slave status; 可以查看)。
接下来,我们在 143 上进行新增操作,看看 134(slave)的变化。经测试,134 上的 cust_info 表会正常同步。
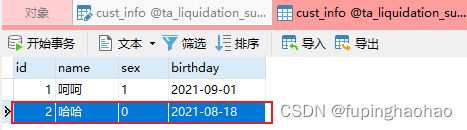
3.4.10 故障修复
3.4.10.1 修复MySQL
| # 启动刚才停掉的 MySQL-master(192.168.73.107) service mysqld restart |
|
|

3.4.10.2 修复主从
3.4.10.2.1 主库修复
| # ① 关闭【新master(143)】的 slave 半同步复制 set global rpl_semi_sync_slave_enabled = 0; show variables like 'rpl_semi_sync_slave_enabled'; |
|
|
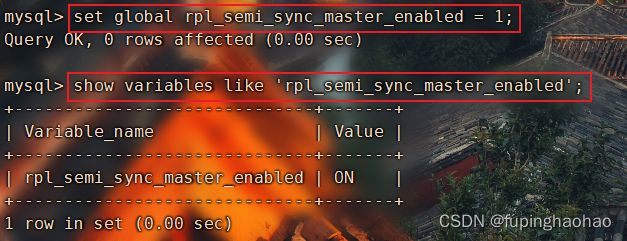
| # ② 开启【新master(143)】的 master 半同步复制 set global rpl_semi_sync_master_enabled = 1; # 查看一下 show variables like 'rpl_semi_sync_master_enabled'; |
|
|
| # 关闭只读模式 set global read_only=0; # 关不关闭 relay log 都无所谓。 |

3.4.10.2.2 从库修复
| # 1). 设置只读模式 set global read_only=1; # 2). 关闭 relay log 的自动删除功能 set global relay_log_purge = 0; # 3). 开启 slave 的半同步复制 # 【注意】:原本的master(107)上是开启了 rpl_semi_sync_master_enabled 的,在这里也是要关闭的。 set global rpl_semi_sync_slave_enabled = 1; |
| # 4). 设置主从关系(需要在主库上查看 master 的信息,show master status;) # ① 停止 slave 进程 stop slave; # ② 在【从服务器】上设置主从关系 # PS:在设置之前现在主库上查看bin log的文件名和位置信息(命令 show master status;) change master to master_host = '192.168.73.107', # 主库 ip master_user = 'repluser', master_password = '654321', master_log_file = 'mysql-bin.000001', master_log_pos = 154; # ③ 启动 slave 进程 start slave; # ④ 查看 slave 状态 show slave status\G; # 5). 重启从库的I/O线程 # ① 停止 I/O 线程 stop slave io_thread; # ② 开启 I/O 线程 start slave io_thread; |
设置主从关系方式如下
1). 在现主库服务器 slave1(192.168.73.143) 上查看二进制文件和同步点。

2). 在原主库服务器 Master(192.168.73.107)执行同步操作(设置主从关系)。
| # ① 停止 slave 进程 stop slave; |
| # ② 在【从服务器】上设置主从关系 change master to master_host = '192.168.73.143', master_user = 'repluser', master_password = '654321', master_log_file = 'mysql-bin.000002', master_log_pos = 154; |
| 重要参数取值说明 master_log_file:二进制日志文件名 master_log_pos:二进制日志位置 这两个参数的取值在【3.4.8.2.4.1 日志关键点】中有说明。 |
|
|
| # ③ 启动 slave 进程 start slave; |
|
|
| 我们在【3.4.9主从复制测试】章节时,在新master(143)上执行了新增操作。 在这一步完成后,可以看下107,143上新增的数据也会被同步过来。 |
| # ④ 查看 slave 状态 show slave status\G; |
|
|



3.4.10.2.3 在MHA Manager节点上修改配置文件app1.cnf
把重新启动起来的这个 MySQL 服务添加进去,因为在【3.4.8.2 MHA反应】章节中已经说明了,自动切换后MySQL-master就会被MHA Manager给删除。
可以看到,把143设置为了 master,107变成了一个 slave。
| [server default] secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.73.107 -s 192.168.73.134 --user=root --master_host=192.168.73.143 --master_ip=192.168.73.143 --master_port=3306 [server1] hostname=192.168.73.143 port=3306 [server2] candidate_master=1 check_repl_delay=0 hostname=192.168.73.107 port=3306 [server3] hostname=192.168.73.134 port=3306 |
3.4.10.3 在MHA Manager上检测整个集群的状态
检测步骤同【3.4.5.2 检测整个集群的状态】。
此次的检测结果如下:
| MySQL Replication Health is OK. |
3.4.10.4 在MHA Manager上启动MHA
同【3.4.5.4 开启 MHA Manager 监控】。
启动完成后,查看一下 MHA Manager 的状态如下:
![]()
可以看出来状态为 PING_OK,
master 为自动切换后选举出来的新的 master(192.168.73.143)。
3.4.11 Java应用集成MHA
Vip配置的目的是为了应用透明,即当发生主从切换时对应用是无感知的。
3.4.11.1 Java应用
yml中数据源配置:
| spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver # 这里配置的 ip 地址就是【3.4.4.3 VIP配置】中配置的虚拟ip。 url: jdbc:mysql://192.168.73.200:3306/ta_liquidation_sub_sh?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true username: xxx password: xxx |
3.4.11.2 测试
测试接口URI:/mha/test
| 测试时机 |
测试结果 |
| 项目启动后第一次正常测试接口 |
正常 |
| 将MySQL集群中的master宕机后 |
正常 |
| MHA 故障修复后 |
正常 |
1.MySQL-master宕机后,MHA 进行自动故障迁移
可以看出来地址已经从原本的master(192.168.73.143)飘到了新的master(192.168.73.107)。
2. 测试接口日志
这里只贴出了第1、第2次的测试日志,第3次的一样,没有任何变化。

3.4.12 性能测试
单点和集群的性能损耗主要在:集群时,master 到 slave 之间的数据同步(现在为半同步复制)。
3.4.12.1 第一次测试
| 线程数 |
1000 |
| 循环次数 |
10 |
| 总请求数 |
线程数 * 循环次数 = 1000 * 10 = 10000 |
| 准备时长 |
20秒内启动1000个线程数(即,每秒启动50个线程)。 |

1).单点
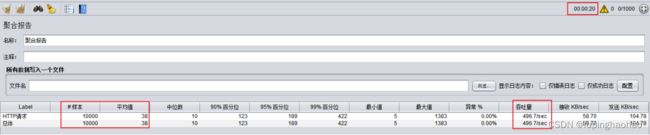
样本:请求数(本次测试总共发了多少个请求)。
平均值:平均响应时间(单个 request 的平均响应时间)。
吞吐量:每秒完成的请求数。
2).集群

3.4.12.2 第二次测试

1).单点
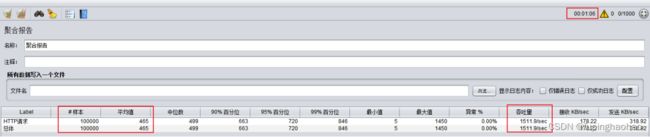
2).集群
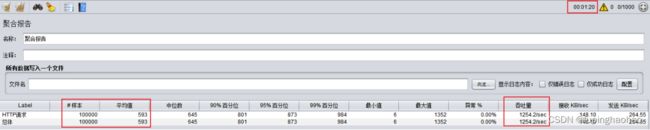
3.4.12.3 第三次测试

1).单点

2).集群
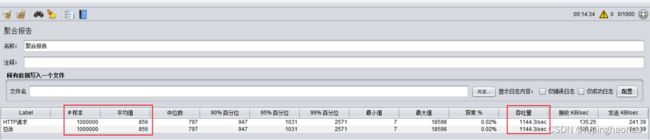
3.4.12.4 总结
从上面三次结果大致得出
① 数据量在10万以下的时候,单点和集群几乎没有差距。
② 数据量达到 100 万的时候,单点和集群的吞吐量相差400/sec左右,耗时相差4分钟。
| 数据量 |
吞吐量(每秒完成的请求数) |
耗时 |
||
| 单点 |
集群 |
单点 |
集群 |
|
| 10,000 |
496.7/sec |
496.2/sec |
20秒 |
21秒 |
| 100,000 |
1511.9/sec |
1254.2/sec |
1分01秒 |
1分20秒 |
| 1,000,000 |
1542.5/sec |
1144.3/sec |
10分48秒 |
14分34秒 |
3.4.13 注意事项
3.4.13.1 MySQL重启后要做的事
同【3.4.9.2 修复主从】。
3.5 MHA 问题及方案
3.5.1 故障修复
1). 目前的修复方案
当 MySQL 集群中【主库】发生故障后
① MHA 会自动进行故障迁移,重新选举 master。
② 邮件提醒相关人员(多个人员,防止单点问题)。
③ 需要以线下的方式,人为干预进行故障修复,主要修复的内容包含两个内容:MySQL 服务 以及 MHA Manager 服务。
2). 存在的问题
当 MHA 进行故障迁移后,MHA Manager 服务会挂掉(具目前查找的所有资料显示在这一步 MHA Manger 确实会挂掉)。
所以,这一步到底是不是问题还有待商榷,这一步我会先继续跟踪看是否有补充方案。
3.5.2 master 宕机后,十分钟后重启后数据如何恢复?
具体查看章节【3.4.8.2.4查看MHA Manager日志】、【3.4.9主从复制测试】、【3.4.10故障修复】。
最重要的就是在【3.4.10.2.2从库修复】这一章节中的数据同步阶段。
3.5.3 数据同步
1).问题描述
① 假如说,我们系统现阶段的MySQL部署方案是单点的。然后,出于安全或其他方面的考虑需要部署MySQL集群。那么,问题来了,我们新加入的MySQL节点的数据如何与现有MySQL节点的数据保持一致呢?也就是说,我们如何对MySQL中的存量数据进行同步。
② 假如说,我们系统现阶段的MySQL部署方案为一主两从的集群模式。然后想在MySQL集群中再加一台MySQL节点,那么同样的问题,我们该如何把MySQL集群中master节点的存量数据同步至新加入的MySQL节点呢?
举例说明:
假设现有部署方案为MySQL集群(一主两从,master-107、slave1-134、slave2-143),现在要加一台slave3-104。那么,我们要面对的问题就是在正式将slave3加入MySQL集群之前,需要将master-107上面的数据同步至slave3-104。
2).解决方案
使用binlog、mysqldump、mysqlpump,这里推荐 mysqlpump。
3.5.3.1 binlog同步
1.方案描述:让slave3从master的第一个binlog文件开始重放。也就是我们上面用了很多次的设置主从关系的命令。
| # MySQL-master 的 ip change master to master_host = '192.168.73.107', # MySQL-master 上创建的 复制账号 master_user = 'repluser', master_password = '654321', # MySQL-master 上第一个 binlog 文件名 master_log_file = 'mysql-bin.000001', # MySQL-master 上第一个 binlog 文件的第一个位置 master_log_pos = 0; |
2.优缺点:① 好处是不用对主库进行停用或者重启操作,不影响主库。② 弊端就是如果主库的数据量异常庞大,那么从库需要同步完成所需要的时间就会越久。
3.问题:如何确定 MySQL-master 上第一个 binlog 的文件名?
前提:从来没有删除过二进制日志(不管是手动删除还是MySQL配置了expire_logs_days)
① 查看 mysql 的二进制索引文件位置
登录MySQL后,使用命令 show variables like 'log_bin_index'; 进行查看

② 查看 MySQL 二进制索引文件内容(看第一行就行)

3.5.3.2 mysqldump同步
1.方案描述:把主库的数据通过 MySQL 提供的 mysqldump 工具 dump 出来;然后将其导入到从库中。
| 主库操作 |
| # 1).停止主库的数据更新操作(关闭所有打开的表,同时对所有数据库的表加上全局只读锁。此时,DML语句会夯住,直到显示的使用unlock tables释放锁) mysql> flush tables with read lock;
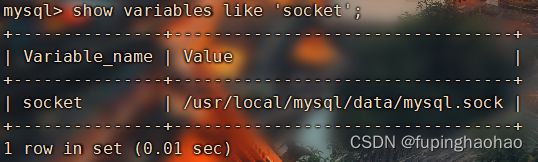
# 2).新开一个窗口,使用 mysqldump 将指定库和指定表导出至指定sql文件中 # 在这里只导出建表语句和insert语句。 mysqldump --host=${HOSTNAME} --port=${PORT} -u$USERNAME -p$PASSWORD --socket=$SOCKET -E $database $tables>$sqlname.sql # ① 参数说明: # --host:MySQL的ip;--port(-P[大写]):MySQL的端口;-u:MySQL用户名;-p:MySQL密码。 # --socket:登录MySQL后用命令“show variables like 'socket';”查看下。 # -E:即 --extended-insert。使用多行insert语法。 # $database:数据库名;$tables: 表名(多个之间用【空格】隔开)。 # $sqlname:sql脚本名,也就是把导出的数据存放到指定sql文件中。 # ② 示例:mysqldump --host=127.0.0.1 --port=3306 -uroot -proot --socket=/usr/local/mysql/data/mysql.sock -E ta_liquidation_sub_sh biz_cfm divid_detail > ta_liquidation_sub_sh_2021101302.sql
# ③ 看图说话,mysqldump 执行。执行完之后会生成一个sql文件,文件内容就是指定库、指定表的建表语句和insert语句。
# 3). 记录日志和偏移量 mysql> show master status;
# 4). 主库解锁 mysql> unlock tables;
|
| 从库操作 |
| # 1).导入数据(将主库上导出的sql文件导入进来) mysql -h${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} -D$database < $sqlname.sql # ① 参数说明: # -h:MySQL的ip;-P[大写]:MySQL的端口;-u:MySQL用户名;-p:MySQL密码。 # $database:数据库名(从库的数据库名,需要与master保持一致); # $sqlname:sql脚本名,也就是在【主库操作】阶段生成的sql文件。 # ② 示例:mysql -h192.168.73.104 -P3306 -uroot -proot -Dta_liquidation_sub_sh < ta_liquidation_sub_sh_2021101302.sql
|




2.优缺点:致命弊端就是得先把master的更新操作给停止,这会直接影响线上服务;如果数据量太大的话,导出还是不够快。
3.5.3.3 mysqlpump同步
1.方案描述:把主库的数据通过 MySQL 提供的 mysqlpump 工具 dump 出来;然后将其导入到从库中。
mysqlpump 相较于 mysqldump 的优势在于可以并行备份。
mysqlpump 的并行是基于表级别的,也就是说,如果只导出一张表的话,是无法体现mysqlpump与mysqldump的差异的。
| 主库操作 |
| # 1).停止主库的数据更新操作、# 3). 记录日志和偏移量、# 4). 主库解锁 这三步操作同【3.5.3.2 mysqldump同步】,这里与方案二的唯一区别就在第2)步的备份阶段。 # 2).新开一个窗口,使用 mysqldump 将指定库和指定表导出至指定sql文件中 mysqlpump --host=${HOSTNAME} --port=${PORT} -u$USERNAME -p$PASSWORD --socket=$SOCKET --no-create-db --skip-routines --skip-definer --max-allowed-packet=$packet --default-parallelism=4 -B $database --include-tables=$tables > $sqlname.sql # ① 参数说明: # --host:MySQL的ip;--port(-P[大写]):MySQL的端口;-u:MySQL用户名;-p:MySQL密码。 # --socket:登录MySQL后用命令“show variables like 'socket';”查看下。 # --no-create-db:备份不写 create database 语句。 # --skip-routines:忽略存储过程和函数。 # --skip-definer:忽略创建视图和存储过程中用到的 definer 和 sql security 语句。 # --max-allowed-packet:备份时用于 client/server 直接通信时的最大 buffer 包的大小,单位为字节(1G = 1024 M = 1024^2 K = 1024^3 B)。 # --default-parallelism:指定并发线程数。每个线程的备份步骤:先 create table 但不创建二级索引(主键会在 create table 时建立),再写入数据,最后建立二级索引。 # --include-tables:指定要备份的表名(多个之间用【逗号】隔开)。 # $database:数据库名;$tables: 表名。 # $sqlname:sql脚本名,也就是把导出的数据存放到指定sql文件中。 # ② 示例:mysqlpump --host=127.0.0.1 --port=3306 -uroot -proot --socket=/usr/local/mysql/data/mysql.sock --no-create-db --skip-routines --skip-definer --max-allowed-packet=2147483648 --default-parallelism=2 -B ta_liquidation_sub_sh --include-tables=biz_cfm,divid_detail > ta_liquidation_sub_sh_2021101303.sql # ③ 看图说话,mysqlpump 执行。执行完之后会生成一个sql文件,文件内容就是指定库、指定表的建表语句和insert语句。
|
| 从库操作 |
| 同【3.5.3.2 mysqldump同步】
|

3.5.4 MHA中MySQL节点的增减
3.5.4.1 增加一个MySQL节点
现有部署方案为MySQL集群(一主两从,master-107、slave1-134、slave2-143),现在要加一台slave3-142。
步骤如下:
① 先执行【3.5.3数据同步】,将master-107上的数据同步至slave-142;
② 构建MySQL集群(将slave-142加入MySQL集群);
③ 将slave-142加入MHA环境(这里就是执行【3.4 MHA搭建】了)。
3.5.4.1.1 数据同步
执行逻辑同【3.5.3数据同步】。
将master-107上的数据同步至slave-142上。
![]()
3.5.4.1.2 构建MySQL集群
1). 先构建异步复制MySQL集群,执行【3.2.1.1主从库】和【3.2.1.3从库】。
【注意】:在从库上设置主从关系时需要注意binlog的文件名和位置。
在【3.5.3.2 mysqldump同步】中的【主库操作】中的第三步【3). 记录日志和偏移量】,这里就是我们需要的binlog的文件名和位置。
2). 再构建半自动同步复制MySQL集群,执行【3.3.2 配置半同步复制】。
3.5.4.1.3 将slave-142加入MHA环境
1). 在 slave-142上执行如下操作
| # ① 设置只读模式 set global read_only=1; # ② 关闭 relay log 的自动删除功能 set global relay_log_purge = 0; |
2). 执行【3.4.3免密通信】,将slave-142这台服务器也加入到免密通信。
3). 在slave-142上安装mha-node,安装方式参见【3.4.2.1 安装依赖】和【3.4.2.2.1 安装 mha4mysql-node】。
4). 在 MHA Manager 节点上修改配置文件(参见【3.4.4.2 MHA Manager 配置文件】),将slave-142加入mha环境。
配置完成后,依次执行【3.4.5.2 检查整个集群的状态】、【3.4.5.4 开启 MHA Manager 监控】、【3.4.5.3 检查 MHA Manager 状态】。
5). 执行【3.4.8故障迁移测试】、【3.4.10故障修复】。
3.5.4.2 减少一个MySQL节点
刚刚增加了一个slave-142,现在将这个节点从集群中删除,并在MHA Manager中删除。
步骤如下:
① 停止 MHA Manger 服务,参见【3.4.5.5 关闭 MHA Manager 监控】;
② 在集群中卸载 slave-142;
③ 在 MHA Manager 中剔除 slave-142。
3.5.4.2.1 在MySQL集群中卸载 slave-142
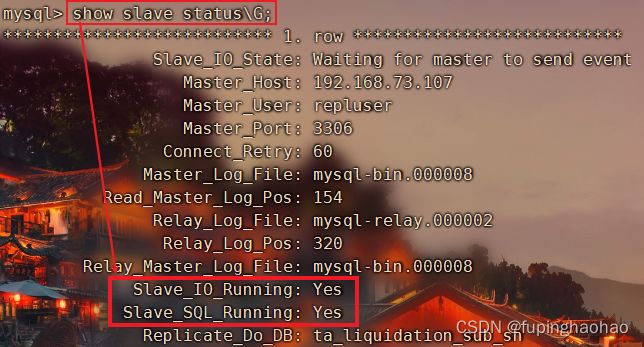
1). 停止 slave-142 上的slave进程
| # ① 先查看 slave 的状态 show slave status\G; |
|
|
| # ② 停止 slave 进程 stop slave; |
|
|
| # ③ 再次查看 slave 进程 show slave status\G; |
|
|


2). 主从复制验证
在master-107上的表中插入一条数据,查看slave-143、slave-134上数据是否同步成功,slave-142上数据不再同步。
3.5.4.2.2 在 MHA Manager 中剔除 slave-142
1). 修改 MHA Manger 的配置文件,并重启。
3.5.5 MHA挂了咋办?
1). 问题
从上面MAH的搭建来看,MHA Manager是单点的。既然是单点的,那就有问题喽,万一异常宕机了就无法保证故障切换了。
2). 解决方案
方案一:shell脚本定时检测 MHA Manger 是否存活。
方案二:
使用分布式 agent,在 MySQL 数据库集群中每个节点都部署 agent。当发生故障时,每个 agent 都会参与选举投票,选举出合适的 slave 作为新的 master,以此方式防止只通过 MHA Manager 来切换。
3.5.5.1 shell脚本定时检测
3.5.5.1.1安装mailx
1). 安装
命令:yum install -y mailx
2). 安装完后看下安装目录
命令:which mailx
![]()

3). 修改配置文件
vim /etc/mail.rc,添加如下内容
| # smtp服务器认证的用户名 # smtp服务器的地址 set smtp=smtp.aliyun.com # 邮件认证的方式 set smtp-auth=login # smtp服务器认证的用户名 # smtp服务器认证的用户密码(授权码) set smtp-auth-password=password |
4). 验证
![]()
3.5.5.1.2 shell脚本
listener_manager.sh
[email protected] 是你要发送给谁
| #!/bin/bash case "`uname`" in Linux) bin_abs_path=$(readlink -f $(dirname $0)) ;; *) bin_abs_path=`cd $(dirname $0); pwd` ;; esac echo "current path:: $bin_abs_path" while(true); do mhastatus=`$bin_abs_path/masterha_check_status --conf=/etc/masterha/app1.cnf | grep "PING_OK" | awk '{print $2}' | awk -F: '{print $2}' | awk -F')' '{print $1}'` if [ "$mhastatus" == "" ]; then echo "mha manager down, please deal with it urgently MHA!!!" echo "mha manager down, please deal with it urgently MHA!!!" | mail -s "MHA Manager DOWN" [email protected] break; fi done echo "mha listener end, please exec current shell script after mha manager started!!!" |
listener_manager_launcher.sh(用这个脚本启动)
| #!/bin/bash current_path=`pwd` case "`uname`" in Linux) bin_abs_path=$(readlink -f $(dirname $0)) ;; *) bin_abs_path=`cd $(dirname $0); pwd` ;; esac nohup $bin_abs_path/listener_manager.sh>listener_manager.out 2>&1 & |
3.5.5.1.3 验证
1). 启动 mha manager
![]()
看下是不是启动成功
![]()
2). 启动监控脚本并查看监控日志

3). 停止 mha manager
![]()
查看监控日志

看有没有收到邮件提醒

3.5.5.2 agent方式
// TODO
3.5.6 MySQL集群中主从数据不一致咋办?
1). 主从数据不一致情况
① 我们在上面搭建MySQL集群时,主从复制之间的复制最终使用的是半同步复制。但正如上文中所述,半同步复制在 slave 超时时会退化为异步复制,而异步复制就有可能会导致主从数据不一致。
② 当 master 发生故障或者不能 ssh 时,从库就可能会丢失部分数据导致数据不一致。
2). 方案
MHA 之 Binlog Server。
Binlog Server 模拟 slave 接受 binlog 日志,主库每次的数据写入都需要接收到 Binlog Server 的 ACK 应答才认为写入成功。Binlog Server 可以部署在就近的物理节点上,从而保证数据写入都能快速的落地到 Binlog Server。当master 宕机后,其他从库就可以从 Binlog Server 中恢复数据了。
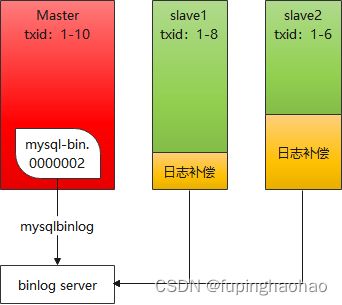
// TODO 待实现。
99.引用
99.1网站
CPAN网站(The Comprehensive Perl Archive Network - www.cpan.org)
MetaCPAN网站(Search the CPAN - metacpan.org)
镜像网站(The Comprehensive Perl Archive Network - www.cpan.org)
99.2 perl模块安装
[Linux/Unix系统 Perl模块安装](Linux/Unix系统 Perl模块安装 - 简书)
99.3 MHA安装部署
[MHA高可用配置(故障切换)](MHA 高可用配置(故障切换)(理论详解+实验步骤)_Xucf1的博客-CSDN博客_mha高可用)
[MySQL5.7 CentOS 7 安装 MHA](Mysql 5.7 CentOS 7 安装MHA - halberd.lee - 博客园)
[MySQL高可用方案MHA的部署和原理](MySQL高可用方案MHA的部署和原理 - iVictor - 博客园)
[MySQL高可用方案--MHA部署及故障转移](MySQL高可用方案--MHA部署及故障转移 - Brian_Zhu - 博客园)
[MHA 安装配置](MHA安装配置_zhangjikuan的博客-CSDN博客_mha配置)
[mysql MHA高可用](mysql MHA高可用 – 技术杂谈)
99.4 MHA VIP配置
[MHA配置VIP漂移-05](mysql高可用架构 -> MHA配置VIP漂移-05 - 少校的小木屋 - 博客园)
[高可用架构MHA的vip配置](高可用架构MHA的vip配置 - linuxTang - 博客园)
99.5 MHA检测原理
[MHA masterha_check_repl检测过程](MHA masterha_check_repl 检测过程_weixin_34162401的博客-CSDN博客)
99.6 MHA安装问题及方案
[MHA安装过程中遇到的问题记录-重要涉及使用CPAN模块安装Perl模块](MHA安装过程中遇到的问题记录-重要涉及使用CPAN模块安装Perl模块 - wonchaofan - 博客园)
[MHA常见报错以及解决方法](MHA常见报错以及解决方法_张俊的技术博客_51CTO博客)
[MHA搭建中的各种报错与解决](MHA搭建中的各种报错与解决_汤姆*先生的博客-CSDN博客)
[排错集锦:在MHA的配置失败](排错集锦:在MHA 的配置过程中masterha_check_repl -conf=/etc/masterha/app1.cnf 失败_遙遙背影暖暖流星的博客-CSDN博客)
[MHA原master宕机后的恢复](MHA原master宕机后的恢复_黄如果的博客-CSDN博客_mha宕机)
99.7邮件提醒
[Linux下查找perl是否安装及卸载](Linux下查找perl是否安装及卸载_weixin_44256848的博客-CSDN博客_卸载perl)
[Linux检查是否安装perl模块及列出所有已安装的perl模块](Linux 检查是否安装perl模块及列出所有已安装的perl模块(安装路径、版本号)_博主是个懒蛋的博客-CSDN博客_查看perl安装的模块)
[perl安装模块的三种方法](perl安装模块的三种方法 - 简书)
[Linux下安装Perl](【Perl】Linux下安装Perl_Alen_Liu_SZ的博客-CSDN博客_ubantu 安装perl,Linux安装perl_superbeyone的博客-CSDN博客_linux安装perl)
[perl如何运行执行脚本](perl如何运行执行脚本_张小凡vip的博客-CSDN博客_perl脚本怎么运行)
[邮件提醒](MHA 邮件告警、故障提醒_ 清欢渡.的博客-CSDN博客_mha邮件提醒,MHA切换时邮件报警_zd2931516196的博客-CSDN博客_mha邮件提醒,
perl Mail::Sender模块发送邮件 - Perl6 - 博客园,使用perl的Mail::SendEasy模块来发送邮件_oudemen的技术博客_51CTO博客)
99.8 半同步复制
MySQL半同步复制(https://www.jb51.net/article/108154.htm)
99.9 MHA之binlog server
MHA之binlog_server(四十六、MHA之binlog_server - 努力吧阿团 - 博客园,MySQL binlog-server搭建_DB-Engineer的博客-CSDN博客_binlog server)
99.10 其他
[踩坑无数,美团点评高可用数据库架构演进](踩坑无数,美团点评高可用数据库架构演进-51CTO.COM)
[使用supervisor监控mha masterha_manager进](使用supervisor监控mha masterha_manager进程_一直在路上的技术博客_51CTO博客)