干货|理解attention机制本质及self-attention
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达上一篇,我们讲述了attention的知识,这篇接上篇,更加深入的理解attention的有关思想和最新的self-attention机制
一、Attention机制的本质思想
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
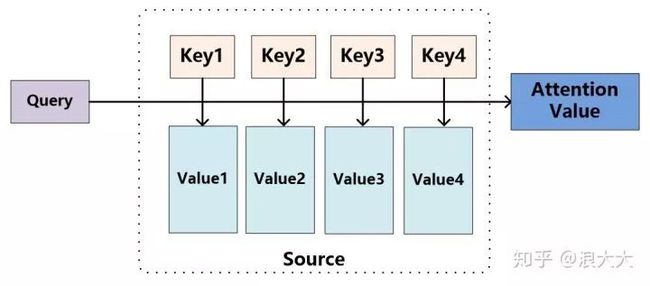 图9 Attention机制的本质思想
图9 Attention机制的本质思想
我们可以这样来看待Attention机制(参考图9):将Source中的构成元素想象成是由一系列的
其中,Lx=||Source||代表Source的长度,公式含义即如上所述。上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图10展示的三个阶段。

在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 Keyi ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
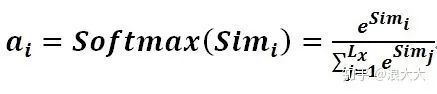
第二阶段的计算结果 ai 即为 Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
二、Self Attention模型
通过上述对Attention本质思想的梳理,我们可以更容易理解本节介绍的Self Attention模型。Self Attention也经常被称为intra Attention(内部Attention),最近一年也获得了比较广泛的使用,比如Google最新的机器翻译模型内部大量采用了Self Attention模型。
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,所以此处不再赘述其计算过程细节。
Self Attention与传统的Attention机制非常的不同:传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端的每个词与目标端每个词之间的依赖关系。但Self Attention不同,它分别在source端和target端进行,仅与source input或者target input自身相关的Self Attention,捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self Attention加入到target端得到的Attention中,捕捉source端和target端词与词之间的依赖关系。因此,self Attention比传统的Attention mechanism效果要好,主要原因之一是,传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,相对比,self Attention可以不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系,如图7所示
 图11 可视化Self Attention实例
图11 可视化Self Attention实例
 图12 可视化Self Attention实例
图12 可视化Self Attention实例
从两张图(图11、图12)可以看出,Self Attention可以捕获同一个句子中单词之间的一些句法特征(比如图11展示的有一定距离的短语结构)或者语义特征(比如图12展示的its的指代对象Law)。
很明显,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
来源:知乎,浪大大
链接:https://zhuanlan.zhihu.com/p/61816483
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

