后端java常见面试题大全
前言:本篇文章可以让你顺利通过大厂一轮面试(算法除外),大厂二轮,此篇文章展示面还是不够的,需要自信进行扩展,请仔细甄别。
一,技术面试中的几个注意点:
1 面试时,你熟悉的问题要和面试官多聊,不要为了回答问题而回答问题
2 一个问题的沟通时间最好能多聊一会儿,简单问题说3/5分钟,如果问题的规模比较大,10分钟左右也是可以的
3 回答问题时不要为了凑时间而凑时间,聊的内容一定要和问的问题相关,知识点可以连续的引入
4 了解的东西多聊,不了解的少说
5 对于知识可以有一些自己的见解,自己的想法,清晰表述出来,虽然自己的看法有时候不会特别的恰当.
6 面试时收集面试录音,面试题,可以发给我们 100元/人,多人评比,最好的400元奖金
7 答题思路 总 分 总 点 线 面
基础面试
请聊一下java的集合类,以及在实际项目中你是如何用的?
参照java集合一章
注意说出集合体系,常用类 接口 实现类
加上你所知道的高并发集合类,JUC 参照集合增强内容
在实际项目中引用,照实说就好了
Hashmap为什么要使用红黑树?
在jdk1.8版本后,java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度
红黑树虽然本质上是一棵二叉查找树,但它在二叉查找树的基础上增加了着色和相关的性质使得红黑树相对平衡,从而保证了红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。加快检索速率。
集合类是怎么解决高并发中的问题?
思路 先说一下那些是非安全
普通的安全的集合类
JUC中高并发的集合类
线程非安全的集合类 ArrayList LinkedList HashSet TreeSet HashMap TreeMap 实际开发中我们自己用这样的集合最多,因为一般我们自己写的业务代码中,不太涉及到多线程共享同一个集合的问题
线程安全的集合类 Vector HashTable 虽然效率没有JUC中的高性能集合高,但是也能够适应大部分环境
高性能线程安全的集合类
1.ConcurrentHashMap
2.ConcurrentHashMap和HashTable的区别
3.ConcurrentHashMap线程安全的具体实现方式/底层具体实现
4.说说CopyOnWriteArrayList
ConcurrentHashMap
java5.0在juc包中提供了大量支持并发的容器类,采用“锁分段”机制,Concurrentlevel分段级别,默认16,就是有16个段(segment),每个段默认又有16个哈希表(table),每个又有链表连着。

在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争。
DK1.8ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(log(N)))
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
ConcurrentSkipListMap是线程安全的有序的哈希表(相当于线程安全的TreeMap); 它继承于AbstractMap类,并且实现ConcurrentNavigableMap接口。ConcurrentSkipListMap是通过“跳表”来实现的,
ConcurrentSkipListSet是线程安全的有序的集合(相当于线程安全的TreeSet);它继承于AbstractSet,并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,它也支持并发。
CopyOnWriteArraySet addIfAbsent和 CopyOnWriteArrayList(写入并复制)也是juc里面的,它解决了并发修改异常,每当有写入的时候,就在底层重新复制一个新容器写入,最后把新容器的引用地址赋给旧的容器,在别人写入的时候,其他线程读数据,依然是旧容器的线程。这样是开销很大的,所以不适合频繁写入的操作。适合并发迭代操作多的场景。只能保证数据的最终一致性
简述一下自定义异常的应用场景?
借助异常机制,我们可以省略很多业务逻辑上的判断处理,直接借助java的异常机制可以简化业务逻辑判断代码的编写
1当你不想把你的错误直接暴露给前端或者你想让前端从业务角度判断后台的异常,这个时候自定义异常类是你的不二选择
2 虽然JAVA给我们提供了丰富的异常类型,但是在实际的业务上,还有很多情况JAVA提供的异常类型不能准确的表述出我们业务上的含义
3 控制项目的后期服务 … …
描述一下Object类中常用的方法?
参照面向对象章节toString hashCode equals clone finalized wait notify notifyAll … …
解释每个方法的作用
toString 定义一个对象的字符串表现形式 Object类中定义的规则是 类的全路径名+@+对象的哈希码 重写之后 我们可以自行决定返回的字符串中包含对象的那些属性信息 …
clone >>>返回一个对象的副本 深克隆 浅克隆 原型模式 重写时实现Cloneable
finalized GC 会调动该方法 自救
1.8的新特性有了解过吗? (注意了解其他版本新特征) +JDK更新认识
- Lambda表达式
- 函数式接口 函数式编程
- 方法引用和构造器调用
- Stream API
- 接口中的默认方法和静态方法
- 新时间日期API
新的日期类
| 属性 |
含义 |
| Instant |
代表的是时间戳 |
| LocalDate |
代表日期,比如2020-01-14 |
| LocalTime |
代表时刻,比如12:59:59 |
| LocalDateTime |
代表具体时间 2020-01-12 12:22:26 |
| ZonedDateTime |
代表一个包含时区的完整的日期时间,偏移量是以UTC/ 格林威治时间为基准的 |
| Period |
代表时间段 |
| ZoneOffset |
代表时区偏移量,比如:+8:00 |
| Clock |
代表时钟,比如获取目前美国纽约的时间 |
一、接口的默认方法
Java 8允许我们给接口添加一个非抽象的方法实现,只需要使用 default关键字即可,这个特征又叫做扩展方法,示例如下:
代码如下:
interface Formula { double calculate(int a);
default double sqrt(int a) { return Math.sqrt(a); } }
Formula接口在拥有calculate方法之外同时还定义了sqrt方法,实现了Formula接口的子类只需要实现一个calculate方法,默认方法sqrt将在子类上可以直接使用。
代码如下:
Formula formula = new Formula() { @Override public double calculate(int a) { return sqrt(a * 100); } };
formula.calculate(100); // 100.0 formula.sqrt(16); // 4.0
文中的formula被实现为一个匿名类的实例,该代码非常容易理解,6行代码实现了计算 sqrt(a * 100)。在下一节中,我们将会看到实现单方法接口的更简单的做法。
译者注: 在Java中只有单继承,如果要让一个类赋予新的特性,通常是使用接口来实现,在C++中支持多继承,允许一个子类同时具有多个父类的接口与功能,在其他语言中,让一个类同时具有其他的可复用代码的方法叫做mixin。新的Java 8 的这个特新在编译器实现的角度上来说更加接近Scala的trait。 在C#中也有名为扩展方法的概念,允许给已存在的类型扩展方法,和Java 8的这个在语义上有差别。
二、Lambda 表达式
首先看看在老版本的Java中是如何排列字符串的:
代码如下:
List names = Arrays.asList("peterF", "anna", "mike", "xenia");
Collections.sort(names, new Comparator()
{
@Override public int compare(String a, String b)
{
return b.compareTo(a); }
});
只需要给静态方法 Collections.sort 传入一个List对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给sort方法。
在Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8提供了更简洁的语法,lambda表达式:
代码如下:
Collections.sort(names, (String a, String b) -> { return b.compareTo(a); });
看到了吧,代码变得更段且更具有可读性,但是实际上还可以写得更短:
代码如下:
Collections.sort(names, (String a, String b) -> b.compareTo(a));
对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字,但是你还可以写得更短点:
代码如下:
Collections.sort(names, (a, b) -> b.compareTo(a));
Java编译器可以自动推导出参数类型,所以你可以不用再写一次类型。接下来我们看看lambda表达式还能作出什么更方便的东西来:
三、函数式接口
Lambda表达式是如何在java的类型系统中表示的呢?每一个lambda表达式都对应一个类型,通常是接口类型。而“函数式接口”是指仅仅只包含一个抽象方法的接口,每一个该类型的lambda表达式都会被匹配到这个抽象方法。因为 默认方法 不算抽象方法,所以你也可以给你的函数式接口添加默认方法。
我们可以将lambda表达式当作任意只包含一个抽象方法的接口类型,确保你的接口一定达到这个要求,你只需要给你的接口添加 @FunctionalInterface 注解,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的。
示例如下:
代码如下:
@FunctionalInterface interface Converter
需要注意如果@FunctionalInterface如果没有指定,上面的代码也是对的。
译者注 将lambda表达式映射到一个单方法的接口上,这种做法在Java 8之前就有别的语言实现,比如Rhino JavaScript解释器,如果一个函数参数接收一个单方法的接口而你传递的是一个function,Rhino 解释器会自动做一个单接口的实例到function的适配器,典型的应用场景有 org.w3c.dom.events.EventTarget 的addEventListener 第二个参数 EventListener。
四、方法与构造函数引用
前一节中的代码还可以通过静态方法引用来表示:
代码如下:
Converter
Java 8 允许你使用 :: 关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法:
代码如下:
converter = something::startsWith; String converted = converter.convert("Java"); System.out.println(converted); // "J"
接下来看看构造函数是如何使用::关键字来引用的,首先我们定义一个包含多个构造函数的简单类:
代码如下:
class Person { String firstName; String lastName;
Person() {}
Person(String firstName, String lastName) { this.firstName = firstName; this.lastName = lastName; } }
接下来我们指定一个用来创建Person对象的对象工厂接口:
代码如下:
interface PersonFactory { P create(String firstName, String lastName); }
这里我们使用构造函数引用来将他们关联起来,而不是实现一个完整的工厂:
代码如下:
PersonFactory
我们只需要使用 Person::new 来获取Person类构造函数的引用,Java编译器会自动根据PersonFactory.create方法的签名来选择合适的构造函数。
五、Lambda 作用域
在lambda表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量。
六、访问局部变量
我们可以直接在lambda表达式中访问外层的局部变量:
代码如下:
final int num = 1; Converter
stringConverter.convert(2); // 3
但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:
代码如下:
int num = 1; Converter
stringConverter.convert(2); // 3
不过这里的num必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:
代码如下:
int num = 1; Converter
在lambda表达式中试图修改num同样是不允许的。
七、访问对象字段与静态变量
和本地变量不同的是,lambda内部对于实例的字段以及静态变量是即可读又可写。该行为和匿名对象是一致的:
代码如下:
class Lambda4 { static int outerStaticNum; int outerNum;
void testScopes() { Converter
Converter
八、访问接口的默认方法
还记得第一节中的formula例子么,接口Formula定义了一个默认方法sqrt可以直接被formula的实例包括匿名对象访问到,但是在lambda表达式中这个是不行的。 Lambda表达式中是无法访问到默认方法的,以下代码将无法编译:
代码如下:
Formula formula = (a) -> sqrt( a * 100); Built-in Functional Interfaces
JDK 1.8 API包含了很多内建的函数式接口,在老Java中常用到的比如Comparator或者Runnable接口,这些接口都增加了@FunctionalInterface注解以便能用在lambda上。 Java 8 API同样还提供了很多全新的函数式接口来让工作更加方便,有一些接口是来自Google Guava库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
Predicate接口
Predicate 接口只有一个参数,返回boolean类型。该接口包含多种默认方法来将Predicate组合成其他复杂的逻辑(比如:与,或,非):
代码如下:
Predicate
predicate.test("foo"); // true predicate.negate().test("foo"); // false
Predicate
Predicate
Function 接口
Function 接口有一个参数并且返回一个结果,并附带了一些可以和其他函数组合的默认方法(compose, andThen):
代码如下:
Function
backToString.apply("123"); // "123"
Supplier 接口 Supplier 接口返回一个任意范型的值,和Function接口不同的是该接口没有任何参数
代码如下:
Supplier
Consumer 接口 Consumer 接口表示执行在单个参数上的操作。
代码如下:
Consumer
Comparator 接口 Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
代码如下:
Comparator
Person p1 = new Person("John", "Doe"); Person p2 = new Person("Alice", "Wonderland");
comparator.compare(p1, p2); // > 0 comparator.reversed().compare(p1, p2); // < 0
Optional 接口
Optional 不是函数是接口,这是个用来防止NullPointerException异常的辅助类型,这是下一届中将要用到的重要概念,现在先简单的看看这个接口能干什么:
Optional 被定义为一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是偶尔却可能返回了null,而在Java 8中,不推荐你返回null而是返回Optional。
代码如下:
Optional
optional.isPresent(); // true optional.get(); // "bam" optional.orElse("fallback"); // "bam"
optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
Stream 接口
java.util.Stream 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如 java.util.Collection的子类,List或者Set, Map不支持。Stream的操作可以串行执行或者并行执行。
首先看看Stream是怎么用,首先创建实例代码的用到的数据List:
代码如下:
List
Java 8扩展了集合类,可以通过 Collection.stream() 或者 Collection.parallelStream() 来创建一个Stream。下面几节将详细解释常用的Stream操作:
Filter 过滤
过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
代码如下:
stringCollection .stream() .filter((s) -> s.startsWith("a")) .forEach(System.out::println);
// "aaa2", "aaa1"
Sort 排序
排序是一个中间操作,返回的是排序好后的Stream。如果你不指定一个自定义的Comparator则会使用默认排序。
代码如下:
stringCollection .stream() .sorted() .filter((s) -> s.startsWith("a")) .forEach(System.out::println);
// "aaa1", "aaa2"
需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的:
代码如下:
System.out.println(stringCollection); // ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
Map 映射 中间操作map会将元素根据指定的Function接口来依次将元素转成另外的对象,下面的示例展示了将字符串转换为大写字符串。你也可以通过map来讲对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
代码如下:
stringCollection .stream() .map(String::toUpperCase) .sorted((a, b) -> b.compareTo(a)) .forEach(System.out::println);
// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"
Match 匹配
Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是最终操作,并返回一个boolean类型的值。
代码如下:
boolean anyStartsWithA = stringCollection .stream() .anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA = stringCollection .stream() .allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ = stringCollection .stream() .noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true
Count 计数 计数是一个最终操作,返回Stream中元素的个数,返回值类型是long。
代码如下:
long startsWithB = stringCollection .stream() .filter((s) -> s.startsWith("b")) .count();
System.out.println(startsWithB); // 3
Reduce 规约
这是一个最终操作,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规越后的结果是通过Optional接口表示的:
代码如下:
Optional
reduced.ifPresent(System.out::println); // "aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2"
并行Streams
前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
下面的例子展示了是如何通过并行Stream来提升性能:
首先我们创建一个没有重复元素的大表:
代码如下:
int max = 1000000; List
然后我们计算一下排序这个Stream要耗时多久, 串行排序:
代码如下:
long t0 = System.nanoTime();
long count = values.stream().sorted().count(); System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0); System.out.println(String.format("sequential sort took: %d ms", millis));
// 串行耗时: 899 ms 并行排序:
代码如下:
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count(); System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0); System.out.println(String.format("parallel sort took: %d ms", millis));
// 并行排序耗时: 472 ms 上面两个代码几乎是一样的,但是并行版的快了50%之多,唯一需要做的改动就是将stream()改为parallelStream()。
Map
前面提到过,Map类型不支持stream,不过Map提供了一些新的有用的方法来处理一些日常任务。
代码如下:
Map
for (int i = 0; i < 10; i++) { map.putIfAbsent(i, "val" + i); }
map.forEach((id, val) -> System.out.println(val)); 以上代码很容易理解, putIfAbsent 不需要我们做额外的存在性检查,而forEach则接收一个Consumer接口来对map里的每一个键值对进行操作。
下面的例子展示了map上的其他有用的函数:
代码如下:
map.computeIfPresent(3, (num, val) -> val + num); map.get(3); // val33
map.computeIfPresent(9, (num, val) -> null); map.containsKey(9); // false
map.computeIfAbsent(23, num -> "val" + num); map.containsKey(23); // true
map.computeIfAbsent(3, num -> "bam"); map.get(3); // val33
接下来展示如何在Map里删除一个键值全都匹配的项:
代码如下:
map.remove(3, "val3"); map.get(3); // val33
map.remove(3, "val33"); map.get(3); // null
另外一个有用的方法:
代码如下:
map.getOrDefault(42, "not found"); // not found
对Map的元素做合并也变得很容易了:
代码如下:
map.merge(9, "val9", (value, newValue) -> value.concat(newValue)); map.get(9); // val9
map.merge(9, "concat", (value, newValue) -> value.concat(newValue)); map.get(9); // val9concat
Merge做的事情是如果键名不存在则插入,否则则对原键对应的值做合并操作并重新插入到map中。
九、Date API
Java 8 在包java.time下包含了一组全新的时间日期API。新的日期API和开源的Joda-Time库差不多,但又不完全一样,下面的例子展示了这组新API里最重要的一些部分:
Clock 时钟
Clock类提供了访问当前日期和时间的方法,Clock是时区敏感的,可以用来取代 System.currentTimeMillis() 来获取当前的微秒数。某一个特定的时间点也可以使用Instant类来表示,Instant类也可以用来创建老的java.util.Date对象。
代码如下:
Clock clock = Clock.systemDefaultZone(); long millis = clock.millis();
Instant instant = clock.instant(); Date legacyDate = Date.from(instant); // legacy java.util.Date
Timezones 时区
在新API中时区使用ZoneId来表示。时区可以很方便的使用静态方法of来获取到。 时区定义了到UTS时间的时间差,在Instant时间点对象到本地日期对象之间转换的时候是极其重要的。
代码如下:
System.out.println(ZoneId.getAvailableZoneIds()); // prints all available timezone ids
ZoneId zone1 = ZoneId.of("Europe/Berlin"); ZoneId zone2 = ZoneId.of("Brazil/East"); System.out.println(zone1.getRules()); System.out.println(zone2.getRules());
// ZoneRules[currentStandardOffset=+01:00] // ZoneRules[currentStandardOffset=-03:00]
LocalTime 本地时间
LocalTime 定义了一个没有时区信息的时间,例如 晚上10点,或者 17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差:
代码如下:
LocalTime now1 = LocalTime.now(zone1); LocalTime now2 = LocalTime.now(zone2);
System.out.println(now1.isBefore(now2)); // false
long hoursBetween = ChronoUnit.HOURS.between(now1, now2); long minutesBetween = ChronoUnit.MINUTES.between(now1, now2);
System.out.println(hoursBetween); // -3 System.out.println(minutesBetween); // -239
LocalTime 提供了多种工厂方法来简化对象的创建,包括解析时间字符串。
代码如下:
LocalTime late = LocalTime.of(23, 59, 59); System.out.println(late); // 23:59:59
DateTimeFormatter germanFormatter = DateTimeFormatter .ofLocalizedTime(FormatStyle.SHORT) .withLocale(Locale.GERMAN);
LocalTime leetTime = LocalTime.parse("13:37", germanFormatter); System.out.println(leetTime); // 13:37
LocalDate 本地日期
LocalDate 表示了一个确切的日期,比如 2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。下面的例子展示了如何给Date对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。
代码如下:
LocalDate today = LocalDate.now(); LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS); LocalDate yesterday = tomorrow.minusDays(2);
LocalDate independenceDay = LocalDate.of(2014, Month.JULY, 4); DayOfWeek dayOfWeek = independenceDay.getDayOfWeek();
System.out.println(dayOfWeek); // FRIDAY 从字符串解析一个LocalDate类型和解析LocalTime一样简单:
代码如下:
DateTimeFormatter germanFormatter = DateTimeFormatter .ofLocalizedDate(FormatStyle.MEDIUM) .withLocale(Locale.GERMAN);
LocalDate xmas = LocalDate.parse("24.12.2014", germanFormatter); System.out.println(xmas); // 2014-12-24
LocalDateTime 本地日期时间
LocalDateTime 同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime和LocalTime还有LocalDate一样,都是不可变的。LocalDateTime提供了一些能访问具体字段的方法。
代码如下:
LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);
DayOfWeek dayOfWeek = sylvester.getDayOfWeek(); System.out.println(dayOfWeek); // WEDNESDAY
Month month = sylvester.getMonth(); System.out.println(month); // DECEMBER
long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY); System.out.println(minuteOfDay); // 1439
只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的java.util.Date。
代码如下:
Instant instant = sylvester .atZone(ZoneId.systemDefault()) .toInstant();
Date legacyDate = Date.from(instant); System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014
格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式:
代码如下:
DateTimeFormatter formatter = DateTimeFormatter .ofPattern("MMM dd, yyyy - HH:mm");
LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter); String string = formatter.format(parsed); System.out.println(string); // Nov 03, 2014 - 07:13
和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。
十、Annotation 注解
在Java 8中支持多重注解了,先看个例子来理解一下是什么意思。 首先定义一个包装类Hints注解用来放置一组具体的Hint注解:
代码如下:
@interface Hints { Hint[] value(); }
@Repeatable(Hints.class) @interface Hint { String value(); }
Java 8允许我们把同一个类型的注解使用多次,只需要给该注解标注一下@Repeatable即可。
例 1: 使用包装类当容器来存多个注解(老方法)
代码如下:
@Hints({@Hint("hint1"), @Hint("hint2")}) class Person {}
例 2:使用多重注解(新方法)
代码如下:
@Hint("hint1") @Hint("hint2") class Person {}
第二个例子里java编译器会隐性的帮你定义好@Hints注解,了解这一点有助于你用反射来获取这些信息:
代码如下:
Hint hint = Person.class.getAnnotation(Hint.class); System.out.println(hint); // null
Hints hints1 = Person.class.getAnnotation(Hints.class); System.out.println(hints1.value().length); // 2
Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class); System.out.println(hints2.length); // 2
即便我们没有在Person类上定义@Hints注解,我们还是可以通过 getAnnotation(Hints.class) 来获取 @Hints注解,更加方便的方法是使用 getAnnotationsByType 可以直接获取到所有的@Hint注解。 另外Java 8的注解还增加到两种新的target上了:
代码如下:
@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE}) @interface MyAnnotation {}
关于Java 8的新特性就写到这了,肯定还有更多的特性等待发掘。JDK 1.8里还有很多很有用的东西,比如Arrays.parallelSort, StampedLock和CompletableFuture等等。
简述一下Java面向对象的基本特征,继承、封装与多态,以及你自己的应用?
知识参照面向对象章节
注意单独解释 继承 封装 多态的概念
继承 基本概念解释 后面多态的条件
封装 基本概念解释 隐藏实现细节,公开使用方式
多态 基本概念解释 就是处理参数 提接口 打破单继承
设计模式 设计原则
Java中重写和重载的区别?
联系: 名字相似 都是多个同名方法
重载 在同一个类之中发生的
重写 继承中,子类重写父类方法
1 目的差别
2 语法差别
怎样声明一个类不会被继承,什么场景下会用?
final修饰的类不能有子类 大部分都是出于安全考虑
String举例
Java中的自增是线程安全的吗,如何实现线程安全的自增?
i++ ++i
增加synchronized进行线程同步
使用lock、unlock处理Reetrantent 锁进行锁定
AtomicInteger >>> Unsafe >>> cas >>> aba
首先说明,此处 AtomicInteger,一个提供原子操作的 Integer 的类,常见的还有AtomicBoolean、AtomicInteger、AtomicLong、AtomicReference 等,他们的实现原理相同,区别在与运算对象类型的不同。令人兴奋地,还可以通过 AtomicReference
我们知道,在多线程程序中,诸如++i 或 i++等运算不具有原子性,是不安全的线程操作之一。通常我们会使用 synchronized 将该操作变成一个原子操作,但 JVM 为此类操作特意提供了一些同步类,使得使用更方便,且使程序运行效率变得更高。通过相关资料显示,通常AtomicInteger 的性能是 ReentantLock 的好几倍。
Jdk1.8中的stream有用过吗,详述一下stream的并行操作原理?stream并行的线程池是从哪里来的?
Stream作为Java8的一大亮点,它与java.io包里的InputStream和OutputStream是完全不同的概念。它是对容器对象功能的增强,它专注于对容器对象进行各种非常便利、高效的聚合操作或者大批量数据操作。
Stream API借助于同样新出现的Lambda表达式,极大的提高编程效率和程序可读性。同时,它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用fork/join并行方式来拆分任务和加速处理过程。所以说,Java8中首次出现的 java.util.stream是一个函数式语言+多核时代综合影响的产物。
Stream有如下三个操作步骤:
一、创建Stream:从一个数据源,如集合、数组中获取流。
二、中间操作:一个操作的中间链,对数据源的数据进行操作。
三、终止操作:一个终止操作,执行中间操作链,并产生结果。


当数据源中的数据上了流水线后,这个过程对数据进行的所有操作都称为“中间操作”。中间操作仍然会返回一个流对象,因此多个中间操作可以串连起来形成一个流水线。比如map (mapToInt, flatMap 等)、filter、distinct、sorted、peek、limit、skip、parallel、sequential、unordered。
当所有的中间操作完成后,若要将数据从流水线上拿下来,则需要执行终止操作。终止操作将返回一个执行结果,这就是你想要的数据。比如:forEach、forEachOrdered、toArray、reduce、collect、min、max、count、anyMatch、allMatch、noneMatch、findFirst、findAny、iterator。
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何处理!而在终止操作时一次性全部处理,称作“惰性求值”。
stream并行原理: 其实本质上就是在ForkJoin上进行了一层封装,将Stream 不断尝试分解成更小的split,然后使用fork/join 框架分而治之, parallize使用了默认的ForkJoinPool.common 默认的一个静态线程池.
什么是ForkJoin框架 适用场景
虽然目前处理器核心数已经发展到很大数目,但是按任务并发处理并不能完全充分的利用处理器资源,因为一般的应用程序没有那么多的并发处理任务。基于这种现状,考虑把一个任务拆分成多个单元,每个单元分别得到执行,最后合并每个单元的结果。
Fork/Join框架是JAVA7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干小任务,最终汇总每个小任务结果得到大任务结果的框架。


2.工作窃取算法(work-stealing)
一个大任务拆分成多个小任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列中,并且每个队列都有单独的线程来执行队列里的任务,线程和队列一一对应。
但是会出现这样一种情况:A线程处理完了自己队列的任务,B线程的队列里还有很多任务要处理。
A是一个很热情的线程,想过去帮忙,但是如果两个线程访问同一个队列,会产生竞争,所以A想了一个办法,从双端队列的尾部拿任务执行。而B线程永远是从双端队列的头部拿任务执行。

注意:线程池中的每个线程都有自己的工作队列(PS,这一点和ThreadPoolExecutor不同,ThreadPoolExecutor是所有线程公用一个工作队列,所有线程都从这个工作队列中取任务),当自己队列中
的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。
工作窃取算法的优点:
利用了线程进行并行计算,减少了线程间的竞争。
工作窃取算法的缺点:
任务争夺问题
Java种的代理有几种实现方式?
动态代理
JDK >>> Proxy
1 面向接口的动态代理 代理一个对象去增强面向某个接口中定义的方法
2 没有接口不可用
3 只能读取到接口上的一些注解
MyBatis
DeptMapper dm=sqlSession.getMapper(DeptMapper.class)
第三方 CGlib
1 面向父类的动态代理
2 有没有接口都可以使用
3 可以读取类上的注解
AOP 日志 性能检测 事务
MyBatis 源码 spring源码
硬核技能
1、倒排索引深入骨髓
-
倒排索引的原理以及它是用来解决哪些问题(谈谈你对倒排索引的理解)
-
倒排索引底层数据结构(倒排索引的数据结构)
-
倒排表的压缩算法(底层算法)
-
Trie字典树(Prefix Trees)原理(类似题目:B-Trees/B+Trees/红黑树等)
-
FST原理(FST的构建过程以及FST在Lucene中的应用原理)
-
索引文件的内部结构(.tip和.tim文件内部数据结构)
-
FST在Lucene的读写过程(Lucene源码实现)
2、Elasticsearch的写入原理
3、读写性能调优
写入性能调优:
-
增加flush时间间隔,目的是减小数据写入磁盘的频率,减小磁盘IO
-
增加refresh_interval的参数值,目的是减少segment文件的创建,减少segment的merge次数,merge是发生在jvm中的,有可能导致full GC,增加refresh会降低搜索的实时性。
-
增加Buffer大小,本质也是减小refresh的时间间隔,因为导致segment文件创建的原因不仅有时间阈值,还有buffer空间大小,写满了也会创建。 默认最小值 48MB< 默认值 堆空间的10% < 默认最大无限制
-
大批量的数据写入尽量控制在低检索请求的时间段,大批量的写入请求越集中越好。
-
第一是减小读写之间的资源抢占,读写分离
-
第二,当检索请求数量很少的时候,可以减少甚至完全删除副本分片,关闭segment的自动创建以达到高效利用内存的目的,因为副本的存在会导致主从之间频繁的进行数据同步,大大增加服务器的资源占用。
-
-
Lucene的数据的fsync是发生在OS cache的,要给OS cache预留足够的内从大小,详见JVM调优。
-
通用最小化算法,能用更小的字段类型就用更小的,keyword类型比int更快,
-
ignore_above:字段保留的长度,越小越好
-
调整_source字段,通过include和exclude过滤
-
store:开辟另一块存储空间,可以节省带宽
*注意:_**sourse**:**设置为false**,**则不存储元数据**,**可以节省磁盘**,**并且不影响搜索**。但是禁用_**source必须三思而后行**:*
\1. update,update_by_query和reindex不可用。
\2. 高亮失效
\3. reindex失效,原本可以修改的mapping部分参数将无法修改,并且无法升级索引
\4. 无法查看元数据和聚合搜索
影响索引的容灾能力
-
禁用all字段:all字段的包含所有字段分词后的Term,作用是可以在搜索时不指定特定字段,从所有字段中检索,ES 6.0之前需要手动关闭
-
关闭Norms字段:计算评分用的,如果你确定当前字段将来不需要计算评分,设置false可以节省大量的磁盘空间,有助于提升性能。常见的比如filter和agg字段,都可以设为关闭。
-
关闭index_options(谨慎使用,高端操作):词设置用于在index time过程中哪些内容会被添加到倒排索引的文件中,例如TF,docCount、postion、offsets等,减少option的选项可以减少在创建索引时的CPU占用率,不过在实际场景中很难确定业务是否会用到这些信息,除非是在一开始就非常确定用不到,否则不建议删除
搜索速度调优
-
禁用swap
-
使用filter代替query
-
避免深度分页,避免单页数据过大,可以参考百度或者淘宝的做法。es提供两种解决方案scroll search和search after
-
注意关于index type的使用
-
避免使用稀疏数据
-
避免单索引业务重耦合
-
命名规范
-
冷热分离的架构设计
-
fielddata:搜索时正排索引,doc_value为index time正排索引。
-
enabled:是否创建倒排索引
-
doc_values:正排索引,对于不需要聚合的字段,关闭正排索引可节省资源,提高查询速度
-
开启自适应副本选择(ARS),6.1版本支持,7.0默认开启,
4、ES的节点类型
-
master:候选节点
-
data:数据节点
-
data_content:数据内容节点
-
data_hot:热节点
-
data_warm:索引不再定期更新,但仍可查询
-
data_code:冷节点,只读索引
-
Ingest:预处理节点,作用类似于Logstash中的Filter
-
ml:机器学习节点
-
remote_cluster_client:候选客户端节点
-
transform:转换节点
-
voting_only:仅投票节点
5、Mater选举过程
-
设计思路:所有分布式系统都需要解决数据的一致性问题,处理这类问题一般采取两种策略:
-
避免数据不一致情况的发生
-
定义数据不一致后的处理策略
-
-
主从模式和无主模式
-
ES为什么使用主从模式?
-
在相对稳定的对等网络中节,点的数量远小于单个节点可以维护的节点数,并且网络环境不必经常处理节点的加入和离开。
-
-
-
ES的选举算法
-
Bully和Paxos
-
-
脑裂是什么以及如何避免
6、Elasticsearch调优
-
通用法则
-
通用最小化算法:对于搜索引擎级的大数据检索,每个bit尤为珍贵。
-
业务分离:聚合和搜索分离
-
-
数据结构 学员案例
-
硬件优化
es的默认配置是一个非常合理的默认配置,绝大多数情况下是不需要修改的,如果不理解某项配置的含义,没有经过验证就贸然修改默认配置,可能造成严重的后果。比如max_result_window这个设置,默认值是1W,这个设置是分页数据每页最大返回的数据量,冒然修改为较大值会导致OOM。ES没有银弹,不可能通过修改某个配置从而大幅提升ES的性能,通常出厂配置里大部分设置已经是最优配置,只有少数和具体的业务相关的设置,事先无法给出最好的默认配置,这些可能是需要我们手动去设置的。关于配置文件,如果你做不到彻底明白配置的含义,不要随意修改。
jvm heap分配:7.6版本默认1GB,这个值太小,很容易导致OOM。Jvm heap大小不要超过物理内存的50%,最大也不要超过32GB(compressed oop),它可用于其内部缓存的内存就越多,但可供操作系统用于文件系统缓存的内存就越少,heap过大会导致GC时间过长
-
节点:
根据业务量不同,内存的需求也不同,一般生产建议不要少于16G。ES是比较依赖内存的,并且对内存的消耗也很大,内存对ES的重要性甚至是高于CPU的,所以即使是数据量不大的业务,为了保证服务的稳定性,在满足业务需求的前提下,我们仍需考虑留有不少于20%的冗余性能。一般来说,按照百万级、千万级、亿级数据的索引,我们为每个节点分配的内存为16G/32G/64G就足够了,太大的内存,性价比就不是那么高了。
-
内存:
根据业务量不同,内存的需求也不同,一般生产建议不要少于16G。ES是比较依赖内存的,并且对内存的消耗也很大,内存对ES的重要性甚至是高于CPU的,所以即使是数据量不大的业务,为了保证服务的稳定性,在满足业务需求的前提下,我们仍需考虑留有不少于20%的冗余性能。一般来说,按照百万级、千万级、亿级数据的索引,我们为每个节点分配的内存为16G/32G/64G就足够了,太大的内存,性价比就不是那么高了。
-
磁盘:
对于ES来说,磁盘可能是最重要的了,因为数据都是存储在磁盘上的,当然这里说的磁盘指的是磁盘的性能。磁盘性能往往是硬件性能的瓶颈,木桶效应中的最短板。ES应用可能要面临不间断的大量的数据读取和写入。生产环境可以考虑把节点冷热分离,“热节点”使用SSD做存储,可以大幅提高系统性能;冷数据存储在机械硬盘中,降低成本。另外,关于磁盘阵列,可以使用raid 0。
-
CPU:
CPU对计算机而言可谓是最重要的硬件,但对于ES来说,可能不是他最依赖的配置,因为提升CPU配置可能不会像提升磁盘或者内存配置带来的性能收益更直接、显著。当然也不是说CPU的性能就不重要,只不过是说,在硬件成本预算一定的前提下,应该把更多的预算花在磁盘以及内存上面。通常来说单节点cpu 4核起步,不同角色的节点对CPU的要求也不同。服务器的CPU不需要太高的单核性能,更多的核心数和线程数意味着更高的并发处理能力。现在PC的配置8核都已经普及了,更不用说服务器了。
-
网络:
ES是天生自带分布式属性的,并且ES的分布式系统是基于对等网络的,节点与节点之间的通信十分的频繁,延迟对于ES的用户体验是致命的,所以对于ES来说,低延迟的网络是非常有必要的。因此,使用扩地域的多个数据中心的方案是非常不可取的,ES可以容忍集群夸多个机房,可以有多个内网环境,支持跨AZ部署,但是不能接受多个机房跨地域构建集群,一旦发生了网络故障,集群可能直接GG,即使能够保证服务正常运行,维护这样(跨地域单个集群)的集群带来的额外成本可能远小于它带来的额外收益。
-
集群规划:没有最好的配置,只有最合适的配置。
-
在集群搭建之前,首先你要搞清楚,你ES cluster的使用目的是什么?主要应用于哪些场景,比如是用来存储事务日志,或者是站内搜索,或者是用于数据的聚合分析。针对不同的应用场景,应该指定不同的优化方案。
-
集群需要多少种配置(内存型/IO型/运算型),每种配置需要多少数量,通常需要和产品运营和运维测试商定,是业务量和服务器的承载能力而定,并留有一定的余量。
-
一个合理的ES集群配置应不少于5台服务器,避免脑裂时无法选举出新的Master节点的情况,另外可能还需要一些其他的单独的节点,比如ELK系统中的Kibana、Logstash等。
-
-
架构优化:
-
合理的分配角色和每个节点的配置,在部署集群的时候,应该根据多方面的情况去评估集群需要多大规模去支撑业务。这个是需要根据在你当前的硬件环境下测试数据的写入和搜索性能,然后根据你目前的业务参数来动态评估的,比如:
-
业务数据的总量、每天的增量
-
查询的并发以及QPS
-
峰值的请求量
-
-
节点并非越多越好,会增加主节点的压力
-
分片并非越多越好,从deep pageing 的角度来说,分片越多,JVM开销越大,负载均衡(协调)节点的转发压力也越大,查询速度也越慢。单个分片也并非越大越好,一般来说单个分片大小控制在30-50GB。
-
-
Mpping优化:
-
优化字段的类型,关闭对业务无用的字段
-
尽量不要使用dynamic mapping分片大小
-
-
Developer调优:修炼内功,提升修养
7、索引备份还原
snapshot,
8、数据同步方案
-
数据一致性问题
-
基于Canal+binlog同步MySql
-
基于packetbeat监听9200端口
9、搜索引擎和ES(搜索引擎的原理、ES的认识或理解)
-
概念:大数据检索(区分搜索)、大数据分析、大数据存储
-
性能:PB级数据秒查(NRT Near Real Time)
-
高效的压缩算法
-
快速的编码和解码算法
-
合理的数据结构
-
通用最小化算法
-
-
场景:搜索引擎、垂直搜索、BI、GIthub、ELKB
谈谈Spring IOC的理解,原理与实现
答题技巧:
总:当前问题回答的是那些具体的点
分:以1,2,3,4,5的方式分细节取描述相关的知识点,如果有哪些点不清楚,直接忽略过去
突出一些技术名词(核心概念,接口,类,关键方法)
避重就轻:没有重点
一个问题能占用面试官多少时间?问的越多可能露馅越多
当面试官问到一个你熟悉的点的时候,一定要尽量拖时间
1.谈谈Spring IOC的理解,原理与实现?
总:
控制反转:理论思想,原来的对象是由使用者来进行控制,有了spring之后,可以把整个对象交给spring来帮我们进行管理
DI:依赖注入,把对应的属性的值注入到具体的对象中,@Autowired,populateBean完成属性值的注入
容器:存储对象,使用map结构来存储,在spring中一般存在三级缓存,singletonObjects存放完整的bean对象,
整个bean的生命周期,从创建到使用到销毁的过程全部都是由容器来管理(bean的生命周期)
分:
1、一般聊ioc容器的时候要涉及到容器的创建过程(beanFactory,DefaultListableBeanFactory),向bean工厂中设置一些参数(BeanPostProcessor,Aware接口的子类)等等属性
2、加载解析bean对象,准备要创建的bean对象的定义对象beanDefinition,(xml或者注解的解析过程)
3、beanFactoryPostProcessor的处理,此处是扩展点,PlaceHolderConfigurSupport,ConfigurationClassPostProcessor
4、BeanPostProcessor的注册功能,方便后续对bean对象完成具体的扩展功能
5、通过反射的方式讲BeanDefinition对象实例化成具体的bean对象,
6、bean对象的初始化过程(填充属性,调用aware子类的方法,调用BeanPostProcessor前置处理方法,调用init-mehtod方法,调用BeanPostProcessor的后置处理方法)
7、生成完整的bean对象,通过getBean方法可以直接获取
8、销毁过程
面试官,这是我对ioc的整体理解,包含了一些详细的处理过程,您看一下有什么问题,可以指点我一下(允许你把整个流程说完)
您有什么想问的?
博主,我没看过源码怎么办?
具体的细节我记不太清了,但是spring中的bean都是通过反射的方式生成的,同时其中包含了很多的扩展点,比如最常用的对BeanFactory的扩展,对bean的扩展(对占位符的处理),我们在公司对这方面的使用是比较多的,除此之外,ioc中最核心的也就是填充具体bean的属性,和生命周期(背一下)。
2.谈一下spring IOC的底层实现
底层实现:工作原理,过程,数据结构,流程,设计模式,设计思想
你对他的理解和你了解过的实现过程
反射,工厂,设计模式(会的说,不会的不说),关键的几个方法
createBeanFactory,getBean,doGetBean,createBean,doCreateBean,createBeanInstance(getDeclaredConstructor,newinstance),populateBean,initializingBean
1、先通过createBeanFactory创建出一个Bean工厂(DefaultListableBeanFactory)
2、开始循环创建对象,因为容器中的bean默认都是单例的,所以优先通过getBean,doGetBean从容器中查找,找不到的话,
3、通过createBean,doCreateBean方法,以反射的方式创建对象,一般情况下使用的是无参的构造方法(getDeclaredConstructor,newInstance)
4、进行对象的属性填充populateBean
5、进行其他的初始化操作(initializingBean)
3.描述一下bean的生命周期 ?
背图:记住图中的流程
在表述的时候不要只说图中有的关键点,要学会扩展描述
1、实例化bean:反射的方式生成对象
2、填充bean的属性:populateBean(),循环依赖的问题(三级缓存)
3、调用aware接口相关的方法:invokeAwareMethod(完成BeanName,BeanFactory,BeanClassLoader对象的属性设置)
4、调用BeanPostProcessor中的前置处理方法:使用比较多的有(ApplicationContextPostProcessor,设置ApplicationContext,Environment,ResourceLoader,EmbeddValueResolver等对象)
5、调用initmethod方法:invokeInitmethod(),判断是否实现了initializingBean接口,如果有,调用afterPropertiesSet方法,没有就不调用
6、调用BeanPostProcessor的后置处理方法:spring的aop就是在此处实现的,AbstractAutoProxyCreator
注册Destuction相关的回调接口:钩子函数
7、获取到完整的对象,可以通过getBean的方式来进行对象的获取
8、销毁流程,1;判断是否实现了DispoableBean接口,2,调用destroyMethod方法
4.Spring 是如何解决循环依赖的问题的?
三级缓存,提前暴露对象,aop
总:什么是循环依赖问题,A依赖B,B依赖A
分:先说明bean的创建过程:实例化,初始化(填充属性)
1、先创建A对象,实例化A对象,此时A对象中的b属性为空,填充属性b
2、从容器中查找B对象,如果找到了,直接赋值不存在循环依赖问题(不通),找不到直接创建B对象
3、实例化B对象,此时B对象中的a属性为空,填充属性a
4、从容器中查找A对象,找不到,直接创建
形成闭环的原因
此时,如果仔细琢磨的话,会发现A对象是存在的,只不过此时的A对象不是一个完整的状态,只完成了实例化但是未完成初始化,如果在程序调用过程中,拥有了某个对象的引用,能否在后期给他完成赋值操作,可以优先把非完整状态的对象优先赋值,等待后续操作来完成赋值,相当于提前暴露了某个不完整对象的引用,所以解决问题的核心在于实例化和初始化分开操作,这也是解决循环依赖问题的关键,
当所有的对象都完成实例化和初始化操作之后,还要把完整对象放到容器中,此时在容器中存在对象的几个状态,完成实例化=但未完成初始化,完整状态,因为都在容器中,所以要使用不同的map结构来进行存储,此时就有了一级缓存和二级缓存,如果一级缓存中有了,那么二级缓存中就不会存在同名的对象,因为他们的查找顺序是1,2,3这样的方式来查找的。一级缓存中放的是完整对象,二级缓存中放的是非完整对象
为什么需要三级缓存?三级缓存的value类型是ObjectFactory,是一个函数式接口,存在的意义是保证在整个容器的运行过程中同名的bean对象只能有一个。
如果一个对象需要被代理,或者说需要生成代理对象,那么要不要优先生成一个普通对象?要
普通对象和代理对象是不能同时出现在容器中的,因此当一个对象需要被代理的时候,就要使用代理对象覆盖掉之前的普通对象,在实际的调用过程中,是没有办法确定什么时候对象被使用,所以就要求当某个对象被调用的时候,优先判断此对象是否需要被代理,类似于一种回调机制的实现,因此传入lambda表达式的时候,可以通过lambda表达式来执行对象的覆盖过程,getEarlyBeanReference()
因此,所有的bean对象在创建的时候都要优先放到三级缓存中,在后续的使用过程中,如果需要被代理则返回代理对象,如果不需要被代理,则直接返回普通对象
4.1缓存的放置时间和删除时间
三级缓存:createBeanInstance之后:addSingletonFactory
二级缓存:第一次从三级缓存确定对象是代理对象还是普通对象的时候,同时删除三级缓存 getSingleton
一级缓存:生成完整对象之后放到一级缓存,删除二三级缓存:addSingleton
5.Bean Factory与FactoryBean有什么区别?
相同点:都是用来创建bean对象的
不同点:使用BeanFactory创建对象的时候,必须要遵循严格的生命周期流程,太复杂了,,如果想要简单的自定义某个对象的创建,同时创建完成的对象想交给spring来管理,那么就需要实现FactroyBean接口了
isSingleton:是否是单例对象
getObjectType:获取返回对象的类型
getObject:自定义创建对象的过程(new,反射,动态代理)
6.Spring中用到的设计模式?
单例模式:bean默认都是单例的
原型模式:指定作用域为prototype
工厂模式:BeanFactory
模板方法:postProcessBeanFactory,onRefresh,initPropertyValue
策略模式:XmlBeanDefinitionReader,PropertiesBeanDefinitionReader
观察者模式:listener,event,multicast
适配器模式:Adapter
装饰者模式:BeanWrapper
责任链模式:使用aop的时候会先生成一个拦截器链
代理模式:动态代理
委托者模式:delegate
。。。。。。。。。
7.Spring的AOP的底层实现原理?
动态代理
aop是ioc的一个扩展功能,先有的ioc,再有的aop,只是在ioc的整个流程中新增的一个扩展点而已:BeanPostProcessor
总:aop概念,应用场景,动态代理
分:
bean的创建过程中有一个步骤可以对bean进行扩展实现,aop本身就是一个扩展功能,所以在BeanPostProcessor的后置处理方法中来进行实现
1、代理对象的创建过程(advice,切面,切点)
2、通过jdk或者cglib的方式来生成代理对象
3、在执行方法调用的时候,会调用到生成的字节码文件中,直接回找到DynamicAdvisoredInterceptor类中的intercept方法,从此方法开始执行
4、根据之前定义好的通知来生成拦截器链
5、从拦截器链中依次获取每一个通知开始进行执行,在执行过程中,为了方便找到下一个通知是哪个,会有一个CglibMethodInvocation的对象,找的时候是从-1的位置一次开始查找并且执行的。
8.Spring的事务是如何回滚的?
spring的事务管理是如何实现的?
总:spring的事务是由aop来实现的,首先要生成具体的代理对象,然后按照aop的整套流程来执行具体的操作逻辑,正常情况下要通过通知来完成核心功能,但是事务不是通过通知来实现的,而是通过一个TransactionInterceptor来实现的,然后调用invoke来实现具体的逻辑
分:1、先做准备工作,解析各个方法上事务相关的属性,根据具体的属性来判断是否开始新事务
2、当需要开启的时候,获取数据库连接,关闭自动提交功能,开起事务
3、执行具体的sql逻辑操作
4、在操作过程中,如果执行失败了,那么会通过completeTransactionAfterThrowing看来完成事务的回滚操作,回滚的具体逻辑是通过doRollBack方法来实现的,实现的时候也是要先获取连接对象,通过连接对象来回滚
5、如果执行过程中,没有任何意外情况的发生,那么通过commitTransactionAfterReturning来完成事务的提交操作,提交的具体逻辑是通过doCommit方法来实现的,实现的时候也是要获取连接,通过连接对象来提交
6、当事务执行完毕之后需要清除相关的事务信息cleanupTransactionInfo
如果想要聊的更加细致的话,需要知道TransactionInfo,TransactionStatus,
9.谈一下spring事务传播?
传播特性有几种?7种
Required,Requires_new,nested,Support,Not_Support,Never,Mandatory
某一个事务嵌套另一个事务的时候怎么办?
A方法调用B方法,AB方法都有事务,并且传播特性不同,那么A如果有异常,B怎么办,B如果有异常,A怎么办?
总:事务的传播特性指的是不同方法的嵌套调用过程中,事务应该如何进行处理,是用同一个事务还是不同的事务,当出现异常的时候会回滚还是提交,两个方法之间的相关影响,在日常工作中,使用比较多的是required,Requires_new,nested
分:1、先说事务的不同分类,可以分为三类:支持当前事务,不支持当前事务,嵌套事务
2、如果外层方法是required,内层方法是,required,requires_new,nested
3、如果外层方法是requires_new,内层方法是,required,requires_new,nested
4、如果外层方法是nested,内层方法是,required,requires_new,nested
REDIS常见面试题解析:
-
说一下你在项目中的redis的应用场景?
1,5大value类型:string,list,set,sortedset,hash。 2,基本上就是缓存~! 3,为的是服务无状态,延申思考,看你的项目有哪些数据结构或对象,在单机里需要单机锁,在多机需要分布式锁,抽出来放入redis中; 4,无锁化
-
redis是单线程还是多线程?
1,无论什么版本,工作线程就是一个 2,6.x高版本出现了IO多线程 3,使用上来说,没有变化 ------ 3,[去学一下系统IO课],你要真正的理解面向IO模型编程的时候,有内核的事,从内核把数据搬运到程序里这是第一步,然后,搬运回来的数据做的计算式第二步,netty 4,单线程,满足redis的串行原子,只不过IO多线程后,把输入/输出放到更多的线程里去并行,好处如下:1,执行时间缩短,更快;2,更好的压榨系统及硬件的资源(网卡能够高效的使用); *,客户端被读取的顺序不能被保障 那个顺序时可以被保障的:在一个连接里,socket里
-
redis存在线程安全的问题吗?为什么?
重复2中的单线程串行 redis可以保障内部串行 外界使用的时候要保障,业务上要自行保障顺序~!
-
遇到过缓存穿透吗?详细描述一下。
-
遇到过缓存击穿吗?详细描述一下。
-
如何避免缓存雪崩?
以上问题,核心就是避免DB无效/重复请求,结合图去理解 涉及一些架构思想上的提升
-
Redis是怎么删除过期key的?
-
缓存如何回收的?
1,后台在轮询,分段分批的删除哪些过期的key 2,请求的时候判断时候已经过期了 尽量的把内存无用空间回收回来~!
-
缓存是如何淘汰的
0,内存空间不足的情况下: 1,淘汰机制里有不允许淘汰 2,lru/lfu/random/TTL 3,全空间 4,设置过过期的key的集合中
-
如何进行缓存预热?
1,提前把数据塞入redis,(你知道那些是热数据吗?肯定不知道,会造成上线很多数据没有缓存命中) 2,开发逻辑上也要规避差集(你没缓存的),会造成击穿,穿透,雪崩,实施456中的锁方案 3,一劳永逸,未来也不怕了 *,结合4,5,6点去看,看图理解
-
数据库与缓存不一致如何解决?
1,恶心点的,我们可以使用分布式事务来解决,(意义不大),顶多读多,写稀有情况下 结合图去思考 1,redis是缓存,更倾向于稍微的有时差 2,还是减少DB的操作 3,真的要落地,咱就canal吧
-
简述一下主从不一致的问题?
1,redis的确默认是弱一致性,异步的同步 2,锁不能用主从(单实例/分片集群/redlock)==>redisson 3,在配置中提供了必须有多少个Client连接能同步,你可以配置同步因子,趋向于强制一性 4,wait 2 0 小心 5,34点就有点违背redis的初衷了
-
描述一下redis持久化原理?
当前线程阻塞服务 不聊 异步后台进程完成持久 fork + cow
-
Redis有哪些持久化方式?
1,RDB,AOF;主从同步也算持久化; 2,高版本:开启AOF,AOF是可以通过执行日志得到全部内存数据的方式,但是追求性能: 2.1,体积变大,重复无效指令 重写,后台用线程把内存的kv生成指令写个新的aof 2.2,4.x 新增更有性能模式:把重写方式换成直接RDB放到aof文件的头部,比2.1的方法快了,再追加日志
-
Redis也打不住了,万级流量会打到DB上,该怎么处理?
略
-
redis中的事务三条指令式什么,第三条指令到达后执行失败了,怎么处理
略
-
redis实现分布式锁的指令
-
为什么使用setnx?
1,好东西,原子(不存在的情况下完成创建) 2,如果要做分布式锁,就要用set k v nx ex (不存在,过期时间,避免死锁)
-
分布式锁实现,理论:
硬核技能
1、倒排索引深入骨髓
-
倒排索引的原理以及它是用来解决哪些问题(谈谈你对倒排索引的理解)
-
倒排索引底层数据结构(倒排索引的数据结构)
-
倒排表的压缩算法(底层算法)
-
Trie字典树(Prefix Trees)原理(类似题目:B-Trees/B+Trees/红黑树等)
-
FST原理(FST的构建过程以及FST在Lucene中的应用原理)
-
索引文件的内部结构(.tip和.tim文件内部数据结构)
-
FST在Lucene的读写过程(Lucene源码实现)
2、Elasticsearch的写入原理
3、读写性能调优
写入性能调优:
-
增加flush时间间隔,目的是减小数据写入磁盘的频率,减小磁盘IO
-
增加refresh_interval的参数值,目的是减少segment文件的创建,减少segment的merge次数,merge是发生在jvm中的,有可能导致full GC,增加refresh会降低搜索的实时性。
-
增加Buffer大小,本质也是减小refresh的时间间隔,因为导致segment文件创建的原因不仅有时间阈值,还有buffer空间大小,写满了也会创建。 默认最小值 48MB< 默认值 堆空间的10% < 默认最大无限制
-
大批量的数据写入尽量控制在低检索请求的时间段,大批量的写入请求越集中越好。
-
第一是减小读写之间的资源抢占,读写分离
-
第二,当检索请求数量很少的时候,可以减少甚至完全删除副本分片,关闭segment的自动创建以达到高效利用内存的目的,因为副本的存在会导致主从之间频繁的进行数据同步,大大增加服务器的资源占用。
-
-
Lucene的数据的fsync是发生在OS cache的,要给OS cache预留足够的内从大小,详见JVM调优。
-
通用最小化算法,能用更小的字段类型就用更小的,keyword类型比int更快,
-
ignore_above:字段保留的长度,越小越好
-
调整_source字段,通过include和exclude过滤
-
store:开辟另一块存储空间,可以节省带宽
*注意:_**sourse**:**设置为false**,**则不存储元数据**,**可以节省磁盘**,**并且不影响搜索**。但是禁用_**source必须三思而后行**:*
\1. update,update_by_query和reindex不可用。
\2. 高亮失效
\3. reindex失效,原本可以修改的mapping部分参数将无法修改,并且无法升级索引
\4. 无法查看元数据和聚合搜索
影响索引的容灾能力
-
禁用all字段:all字段的包含所有字段分词后的Term,作用是可以在搜索时不指定特定字段,从所有字段中检索,ES 6.0之前需要手动关闭
-
关闭Norms字段:计算评分用的,如果你确定当前字段将来不需要计算评分,设置false可以节省大量的磁盘空间,有助于提升性能。常见的比如filter和agg字段,都可以设为关闭。
-
关闭index_options(谨慎使用,高端操作):词设置用于在index time过程中哪些内容会被添加到倒排索引的文件中,例如TF,docCount、postion、offsets等,减少option的选项可以减少在创建索引时的CPU占用率,不过在实际场景中很难确定业务是否会用到这些信息,除非是在一开始就非常确定用不到,否则不建议删除
搜索速度调优
-
禁用swap
-
使用filter代替query
-
避免深度分页,避免单页数据过大,可以参考百度或者淘宝的做法。es提供两种解决方案scroll search和search after
-
注意关于index type的使用
-
避免使用稀疏数据
-
避免单索引业务重耦合
-
命名规范
-
冷热分离的架构设计
-
fielddata:搜索时正排索引,doc_value为index time正排索引。
-
enabled:是否创建倒排索引
-
doc_values:正排索引,对于不需要聚合的字段,关闭正排索引可节省资源,提高查询速度
-
开启自适应副本选择(ARS),6.1版本支持,7.0默认开启,
4、ES的节点类型
-
master:候选节点
-
data:数据节点
-
data_content:数据内容节点
-
data_hot:热节点
-
data_warm:索引不再定期更新,但仍可查询
-
data_code:冷节点,只读索引
-
Ingest:预处理节点,作用类似于Logstash中的Filter
-
ml:机器学习节点
-
remote_cluster_client:候选客户端节点
-
transform:转换节点
-
voting_only:仅投票节点
5、Mater选举过程
-
设计思路:所有分布式系统都需要解决数据的一致性问题,处理这类问题一般采取两种策略:
-
避免数据不一致情况的发生
-
定义数据不一致后的处理策略
-
-
主从模式和无主模式
-
ES为什么使用主从模式?
-
在相对稳定的对等网络中节,点的数量远小于单个节点可以维护的节点数,并且网络环境不必经常处理节点的加入和离开。
-
-
-
ES的选举算法
-
Bully和Paxos
-
-
脑裂是什么以及如何避免
6、Elasticsearch调优
-
通用法则
-
通用最小化算法:对于搜索引擎级的大数据检索,每个bit尤为珍贵。
-
业务分离:聚合和搜索分离
-
-
数据结构 学员案例
-
硬件优化
es的默认配置是一个非常合理的默认配置,绝大多数情况下是不需要修改的,如果不理解某项配置的含义,没有经过验证就贸然修改默认配置,可能造成严重的后果。比如max_result_window这个设置,默认值是1W,这个设置是分页数据每页最大返回的数据量,冒然修改为较大值会导致OOM。ES没有银弹,不可能通过修改某个配置从而大幅提升ES的性能,通常出厂配置里大部分设置已经是最优配置,只有少数和具体的业务相关的设置,事先无法给出最好的默认配置,这些可能是需要我们手动去设置的。关于配置文件,如果你做不到彻底明白配置的含义,不要随意修改。
jvm heap分配:7.6版本默认1GB,这个值太小,很容易导致OOM。Jvm heap大小不要超过物理内存的50%,最大也不要超过32GB(compressed oop),它可用于其内部缓存的内存就越多,但可供操作系统用于文件系统缓存的内存就越少,heap过大会导致GC时间过长
-
节点:
根据业务量不同,内存的需求也不同,一般生产建议不要少于16G。ES是比较依赖内存的,并且对内存的消耗也很大,内存对ES的重要性甚至是高于CPU的,所以即使是数据量不大的业务,为了保证服务的稳定性,在满足业务需求的前提下,我们仍需考虑留有不少于20%的冗余性能。一般来说,按照百万级、千万级、亿级数据的索引,我们为每个节点分配的内存为16G/32G/64G就足够了,太大的内存,性价比就不是那么高了。
-
内存:
根据业务量不同,内存的需求也不同,一般生产建议不要少于16G。ES是比较依赖内存的,并且对内存的消耗也很大,内存对ES的重要性甚至是高于CPU的,所以即使是数据量不大的业务,为了保证服务的稳定性,在满足业务需求的前提下,我们仍需考虑留有不少于20%的冗余性能。一般来说,按照百万级、千万级、亿级数据的索引,我们为每个节点分配的内存为16G/32G/64G就足够了,太大的内存,性价比就不是那么高了。
-
磁盘:
对于ES来说,磁盘可能是最重要的了,因为数据都是存储在磁盘上的,当然这里说的磁盘指的是磁盘的性能。磁盘性能往往是硬件性能的瓶颈,木桶效应中的最短板。ES应用可能要面临不间断的大量的数据读取和写入。生产环境可以考虑把节点冷热分离,“热节点”使用SSD做存储,可以大幅提高系统性能;冷数据存储在机械硬盘中,降低成本。另外,关于磁盘阵列,可以使用raid 0。
-
CPU:
CPU对计算机而言可谓是最重要的硬件,但对于ES来说,可能不是他最依赖的配置,因为提升CPU配置可能不会像提升磁盘或者内存配置带来的性能收益更直接、显著。当然也不是说CPU的性能就不重要,只不过是说,在硬件成本预算一定的前提下,应该把更多的预算花在磁盘以及内存上面。通常来说单节点cpu 4核起步,不同角色的节点对CPU的要求也不同。服务器的CPU不需要太高的单核性能,更多的核心数和线程数意味着更高的并发处理能力。现在PC的配置8核都已经普及了,更不用说服务器了。
-
网络:
ES是天生自带分布式属性的,并且ES的分布式系统是基于对等网络的,节点与节点之间的通信十分的频繁,延迟对于ES的用户体验是致命的,所以对于ES来说,低延迟的网络是非常有必要的。因此,使用扩地域的多个数据中心的方案是非常不可取的,ES可以容忍集群夸多个机房,可以有多个内网环境,支持跨AZ部署,但是不能接受多个机房跨地域构建集群,一旦发生了网络故障,集群可能直接GG,即使能够保证服务正常运行,维护这样(跨地域单个集群)的集群带来的额外成本可能远小于它带来的额外收益。
-
集群规划:没有最好的配置,只有最合适的配置。
-
在集群搭建之前,首先你要搞清楚,你ES cluster的使用目的是什么?主要应用于哪些场景,比如是用来存储事务日志,或者是站内搜索,或者是用于数据的聚合分析。针对不同的应用场景,应该指定不同的优化方案。
-
集群需要多少种配置(内存型/IO型/运算型),每种配置需要多少数量,通常需要和产品运营和运维测试商定,是业务量和服务器的承载能力而定,并留有一定的余量。
-
一个合理的ES集群配置应不少于5台服务器,避免脑裂时无法选举出新的Master节点的情况,另外可能还需要一些其他的单独的节点,比如ELK系统中的Kibana、Logstash等。
-
-
架构优化:
-
合理的分配角色和每个节点的配置,在部署集群的时候,应该根据多方面的情况去评估集群需要多大规模去支撑业务。这个是需要根据在你当前的硬件环境下测试数据的写入和搜索性能,然后根据你目前的业务参数来动态评估的,比如:
-
业务数据的总量、每天的增量
-
查询的并发以及QPS
-
峰值的请求量
-
-
节点并非越多越好,会增加主节点的压力
-
分片并非越多越好,从deep pageing 的角度来说,分片越多,JVM开销越大,负载均衡(协调)节点的转发压力也越大,查询速度也越慢。单个分片也并非越大越好,一般来说单个分片大小控制在30-50GB。
-
-
Mpping优化:
-
优化字段的类型,关闭对业务无用的字段
-
尽量不要使用dynamic mapping分片大小
-
-
Developer调优:修炼内功,提升修养
7、索引备份还原
snapshot,
8、数据同步方案
-
数据一致性问题
-
基于Canal+binlog同步MySql
-
基于packetbeat监听9200端口
9、搜索引擎和ES(搜索引擎的原理、ES的认识或理解)
-
概念:大数据检索(区分搜索)、大数据分析、大数据存储
-
性能:PB级数据秒查(NRT Near Real Time)
-
高效的压缩算法
-
快速的编码和解码算法
-
合理的数据结构
-
通用最小化算法
-
-
场景:搜索引擎、垂直搜索、BI、GIthub、ELKB
-
大厂:JD、百度、阿里、腾讯、滴滴、字节、美团、Github(如果记不住,就把你能想到的大厂有几个说几个)。
基础再补充
equals()和==区别。为什么重写equal要重写hashcode?
== 是运算符 equals来自于Object类定义的一个方法
== 可以用于基本数据类型和引用类型
equals只能用于引用类型
== 两端如果是基本数据类型,就是判断值是否相同
equals在重写之后,判断两个对象的属性值是否相同
equals如果不重写,其实就是 ==
重写equals可以让我们自己定义判断两个对象是否相同的条件
Object中定义的hashcode方法生成的哈希码能保证同一个类的对象的哈希码一定是不同的
当equals 返回为true,我们在逻辑上可以认为是同一个对象,但是查看哈希码,发现哈希码不同,和equals方法的返回结果违背
Object中定义的hashcode方法生成的哈希码跟对象的本身属性值是无关的
重写hashcode之后,我们可以自定义哈希码的生成规则,可以通过对象的属性值计算出哈希码
HashMap中,借助equals和hashcode方法来完成数据的存储
将根据对象的内容查询转换为根据索引查询
hashmap在1.8中做了哪些优化?
数据结构
在Java1.7中,HashMap的数据结构为数组+单向链表。Java1.8中变成了数组+单向链表+红黑树
链表插入节点的方式
在Java1.7中,插入链表节点使用头插法。Java1.8中变成了尾插法。
hash函数
Java1.8的hash()中,将hash值高位(前16位)参与到取模的运算中,使得计算结果的不确定性增强,降低发生哈希碰撞的概率
扩容优化:
扩容以后,1.7对元素进行rehash算法,计算原来每个元素在扩容之后的哈希表中的位置,1.8借助2倍扩容机制,元素不需要进行重新计算位置
JDK 1.8 在扩容时并没有像 JDK 1.7 那样,重新计算每个元素的哈希值,而是通过高位运算(e.hash & oldCap)来确定元素是否需要移动,比如 key1 的信息如下:

使用 e.hash & oldCap 得到的结果,高一位为 0,当结果为 0 时表示元素在扩容时位置不会发生任何变化,而 key 2 信息如下


高一位为 1,当结果为 1 时,表示元素在扩容时位置发生了变化,新的下标位置等于原下标位置 + 原数组长度hashmap,不必像1.7一样全部重新计算位置
hashmap线程安全的方式?
HashMap不是线程安全的,往往在写程序时需要通过一些方法来回避.其实JDK原生的提供了2种方法让HashMap支持线程安全.
方法一:通过Collections.synchronizedMap()返回一个新的Map,这个新的map就是线程安全的. 这个要求大家习惯基于接口编程,因为返回的并不是HashMap,而是一个Map的实现.
方法二:重新改写了HashMap,具体的可以查看java.util.concurrent.ConcurrentHashMap. 这个方法比方法一有了很大的改进.
下面对这2中实现方法从各个角度进行分析和比较.
方法一特点:
通过Collections.synchronizedMap()来封装所有不安全的HashMap的方法,就连toString, hashCode都进行了封装. 封装的关键点有2处,1)使用了经典的synchronized来进行互斥, 2)使用了代理模式new了一个新的类,这个类同样实现了Map接口.在Hashmap上面,synchronized锁住的是对象,所以第一个申请的得到锁,其他线程将进入阻塞,等待唤醒. 优点:代码实现十分简单,一看就懂.缺点:从锁的角度来看,方法一直接使用了锁住方法,基本上是锁住了尽可能大的代码块.性能会比较差.
方法二特点:
重新写了HashMap,比较大的改变有如下几点.使用了新的锁机制,把HashMap进行了拆分,拆分成了多个独立的块,这样在高并发的情况下减少了锁冲突的可能,使用的是NonfairSync. 这个特性调用CAS指令来确保原子性与互斥性.当如果多个线程恰好操作到同一个segment上面,那么只会有一个线程得到运行.
优点:需要互斥的代码段比较少,性能会比较好. ConcurrentHashMap把整个Map切分成了多个块,发生锁碰撞的几率大大降低,性能会比较好. 缺点:代码繁琐
为什么hashmap扩容的时候是两倍?
查看源代码
在存入元素时,放入元素位置有一个 (n-1)&hash 的一个算法,和hash&(newCap-1),这里用到了一个&位运算符


当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111,与hash值得计算结果如下

下面就来看一下HashMap的容量不是2的n次幂的情况,当容量为10时,二进制为01010,(n-1)的二进制是01001,向里面添加同样的元素,结果为

可以看出,有三个不同的元素进过&运算得出了同样的结果,严重的hash碰撞了
解决hash冲突的方式有哪些?
1开放定址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
2再哈希法:
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
3链地址法
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向 链表连接起来
4建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
Tomcat为什么要重写类加载器?
这里简单解释类加载器双亲委派:
无法实现隔离性:如果使用默认的类加载器机制,那么是无法加载两个相同类库的不同版本的,默认的类加器是不管你是什么版本的,只在乎你的全限定类名,并且只有一份。一个web容器可能要部署两个或者多个应用程序,不同的应用程序,可能会依赖同一个第三方类库的不同版本,因此要保证每一个应用程序的类库都是独立、相互隔离的。部署在同一个web容器中的相同类库的相同版本可以共享,否则,会有重复的类库被加载进JVM, web容器也有自己的类库,不能和应用程序的类库混淆,需要相互隔离
无法实现热替换:jsp 文件其实也就是class文件,那么如果修改了,但类名还是一样,类加载器会直接取方法区中已经存在的,修改后的jsp是不会重新加载的。
打破双亲委派机制(参照JVM中的内容)OSGI是基于Java语言的动态模块化规范,类加载器之间是网状结构,更加灵活,但是也更复杂,JNDI服务,使用线程上线文类加载器,父类加载器去使用子类加载器

2. tomcat自己定义的类加载器:
CommonClassLoader:tomcat最基本的类加载器,加载路径中的class可以被tomcat和各个webapp访问
CatalinaClassLoader:tomcat私有的类加载器,webapp不能访问其加载路径下的class,即对webapp不可见
SharedClassLoader:各个webapp共享的类加载器,对tomcat不可见
WebappClassLoader:webapp私有的类加载器,只对当前webapp可见
3. 每一个web应用程序对应一个WebappClassLoader,每一个jsp文件对应一个JspClassLoader,所以这两个类加载器有多个实例
4. 工作原理:
a. CommonClassLoader能加载的类都可以被Catalina ClassLoader和SharedClassLoader使用,从而实现了公有类库的共用
b. CatalinaClassLoader和SharedClassLoader自己能加载的类则与对方相互隔离
c. WebAppClassLoader可以使用SharedClassLoader加载到的类,但各个WebAppClassLoader实例之间相互隔离,多个WebAppClassLoader是同级关系
d. 而JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件,它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的Jsp类加载器来实现JSP文件的HotSwap功能
5. tomcat目录结构,与上面的类加载器对应
/common/*
/server/*
/shared/*
/WEB-INF/*
6. 默认情况下,conf目录下的catalina.properties文件,没有指定server.loader以及shared.loader,所以tomcat没有建立CatalinaClassLoader和SharedClassLoader的实例,这两个都会使用CommonClassLoader来代替。Tomcat6之后,把common、shared、server目录合成了一个lib目录。所以在我们的服务器里看不到common、shared、server目录。
简述一下Java运行时数据区?

Java虚拟机栈
与程序计数器一样,Java 虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。
虚拟机栈描述的是 Java 方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame,是方法运行时的基础数据结构
程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。
由于 Java 虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器内核都只会执行一条线程中的指令。
本地方法栈
本地方法栈(Native Method Stack)与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。Sun HotSpot 虚拟机直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出 StackOverflowError 和 OutOfMemoryError 异常
Java堆
对于大多数应用来说,Java 堆(Java Heap)是 Java 虚拟机所管理的内存中最大的一块。Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
方法区
方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
说一下反射,反射会影响性能吗?
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。反射这种运行时动态的功能可以说是非常重要的,可以说无反射不框架!!!,反射方式实例化对象和,属性赋值和调用方法肯定比直接的慢,但是程序运行的快慢原因有很多,不能主要归于反射,如果你只是偶尔调用一下反射,反射的影响可以忽略不计,如果你需要大量调用反射,会产生一些影响,适当考虑减少使用或者使用缓存,你的编程的思想才是限制你程序性能的最主要的因素
hashmap为什么用红黑树不用普通的AVL树?

AVL树
一般用平衡因子判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,AVL树是高度平衡的二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而的由于旋转比较耗时,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况
在计算机科学中,AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树
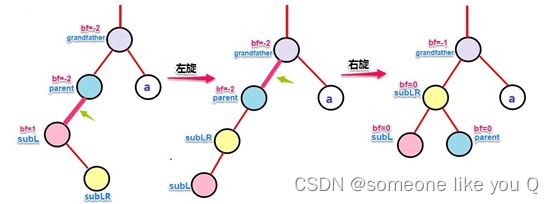
红黑树:
也是一种平衡二叉树,但每个节点有一个存储位表示节点的颜色,可以是红或黑。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树红黑树从根到叶子的最长路径不会超过最短路径的2倍(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度<=红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,用红黑树

sleep 与 wait 区别
- 对于 sleep()方法,我们首先要知道该方法是属于 Thread 类中的。而 wait()方法,则是属于 Object 类中的。
- sleep()方法导致了程序暂停执行指定的时间,让出 cpu,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。在调用 sleep()方法的过程中,线程不会释放对象锁。
- 而当调用 wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用 notify()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
- sleep用Thread调用,在非同步状态下就可以调用, wait用同步监视器调用,必须在同名代码中调用
synchronized 和 ReentrantLock 的区别
两者的共同点:
- 都是用来协调多线程对共享对象、变量的访问
- 都是可重入锁,同一线程可以多次获得同一个锁
- 都保证了可见性和互斥性
两者的不同点:
- ReentrantLock 显示的获得、释放锁,synchronized 隐式获得释放锁
- ReentrantLock 可响应中断、可轮回,synchronized 是不可以响应中断的,为处理锁的不可用性提供了更高的灵活性
- ReentrantLock 是 API 级别的,synchronized 是 JVM 级别的
- ReentrantLock 可以实现公平锁
- ReentrantLock 通过 Condition 可以绑定多个条件
- 底层实现不一样, synchronized 是同步阻塞,使用的是悲观并发策略,lock 是同步非阻塞,采用的是乐观并发策略
- Lock 是一个接口,而 synchronized 是 Java 中的关键字,synchronized 是内置的语言实现。
- synchronized 在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而 Lock 在发生异常时,如果没有主动通过 unLock()去释放锁,则很可能造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁。
- Lock 可以让等待锁的线程响应中断,而 synchronized 却不行,使用 synchronized 时,等待的线程会一直等待下去,不能够响应中断。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
- Lock 可以提高多个线程进行读操作的效率,既就是实现读写锁等。多个读取线程使用共享锁,写线程使用排它锁/独占
Condition 类和Object 类锁方法区别
- Condition 类的 awiat 方法和 Object 类的 wait 方法等效
- Condition 类的 signal 方法和 Object 类的 notify 方法等效
- Condition 类的 signalAll 方法和 Object 类的 notifyAll 方法等效
- ReentrantLock 类可以唤醒指定条件的线程,而 object 的唤醒是随机的
tryLock和Lock和lockInterruptibly 的区别
- tryLock 能获得锁就返回 true,不能就立即返回 false,tryLock(long timeout,TimeUnit unit),可以增加时间限制,如果超过该时间段还没获得锁,返回 false
- lock 能获得锁就返回 true,不能的话一直等待获得锁
- lock 和 lockInterruptibly,如果两个线程分别执行这两个方法,但此时中断这两个线程, lock 不会抛出异常,而 lockInterruptibly 会抛出异常。
单例模式有哪些实现方式,有什么优缺点
一个教室里面有很多同学,每个同学都要有自己的一个水杯.教室里还有一个饮水机,一个饮水机可以为教室内所有的同学提供用水,没有必要每个同学都准备一个饮水机.程序中往往一个类只需要一个对象就可以为整个系统服务,如果产生多个对象,消耗更多的资源.单例模式就是为了实现如何控制一个类只能产生一个对象. 单例模式控制控制对象不要反复创建,提高我们工作的效率.减少资源的占用
单例模式下类的组成部分
1私有的构造方法
2私有的当前类对象作为静态属性
3公有的向外界提供当前类对象的静态方法
但凡是控制一个类只能产生一个对象的模式都叫做单例模式,常见的有饿汉式,懒汉式,内部类式(接口/抽象类),静态内部类式 ... ...
饿汉式代码实现
/*
多例
只要调用了构造方法 就会在内存上产生一个独立的空间
1将构造方法私有化
构造方法私有化了,外界不能new对象了?对象怎么产生?
2组合当前类本身作为私有静态属性并调用构造方法实例化
如何让外界获取属性值呢?
3在当前类中准备一个共有的静态方法向外界提供当前类对象
*/
public class SingleTon {
private static SingleTon singleTon =new SingleTon();
private SingleTon(){
}
public static SingleTon getSingleTon(){
return singleTon;
}
}
class Test{
public static void main(String[] args) {
SingleTon st =SingleTon.getSingleTon();
SingleTon st2=SingleTon.getSingleTon();
System.out.println(st==st2);
System.out.println(st);
System.out.println(st2);
}
}
好处: 饿汉式单例模式在类加载进入内存初始化static变量是会初始化当前类对象,此时也不会涉及多个线程对象访问该对象的问题。虚拟机保证只会装载一次该类,肯定不会发生并发访问的问题。因此,可以省略synchronized关键字。
问题:如果只是加载本类,而不是要调用getInstance(),甚至永远没有调用,则会造成资源浪费,不能延迟加载!
懒汉式单例模式
/*
多例
只要调用了构造方法 就会在内存上产生一个独立的空间
1将构造方法私有化
构造方法私有化了,外界不能new对象了?对象怎么产生?
2组合当前类本身作为私有静态属性并调用构造方法实例化
如何让外界获取属性值呢?
3在当前类中准备一个共有的静态方法向外界提供当前类对象
*/
public class SingleTon {
private static SingleTon singleTon;
private SingleTon(){
}
public static SingleTon getSingleTon(){
if(null == singleTon){
singleTon=new SingleTon();
}
return singleTon;
}
}
class Test{
public static void main(String[] args) {
SingleTon st =SingleTon.getSingleTon();
SingleTon st2=SingleTon.getSingleTon();
System.out.println(st==st2);
System.out.println(st);
System.out.println(st2);
}
}
延迟加载,也叫作懒加载,等到真正用的时候才加载.
懒汉式代理模式在多线程并发情况下仍然是有可能创建多次,是线程非安全的
public class Test1 {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
SingleTon.getSingleTon();
}
}).start();
}
}
}
class SingleTon {
private static SingleTon singleTon;
private SingleTon(){
System.out.println(Thread.currentThread().getName()+"创建了对象");
}
public static SingleTon getSingleTon(){
if(null == singleTon){
singleTon=new SingleTon();
}
return singleTon;
}
}

双重检测式单例模式
为了解决线程并发问题我们需要对其进行优化,作为一个双重检测式的单例模式,就是我们说的DCL单例模式
package com.msb.singleTon;
public class Test1 {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
new Thread(new Runnable() {
@Override
public void run() {
SingleTon.getSingleTon();
}
}).start();
}
}
}
class SingleTon {
private volatile static SingleTon singleTon;
private SingleTon(){
System.out.println(Thread.currentThread().getName()+"创建了对象");
}
public static SingleTon getSingleTon(){
if(null ==singleTon){
synchronized (SingleTon.class){
if(null == singleTon){
singleTon=new SingleTon();
/**
* 1分配空间
* 2执行构造方法
* 3将创建对象的引用地址赋值值singleTon变量
* 为了避免多线程下的指令重拍问题和多线程缓存造成的数据更新不及时问题
* 我们应该在加上volatile处理
*/
}
}
}
return singleTon;
}
}
静态内部类单例模式
除此之外,我们还可以使用内部类实现单例模式的控制
class Single{
/*
* 私有构造方法
* */
private Single(){
}
/*
* 范围内部类的属性
* */
public static Single getSingle(){
return InnerClass.single;
}
/*
* 静态内部类
* */
public static class InnerClass{
/*
* 组合外部类对象作为属性
* */
private static final Single single=new Single();
}
}
外部类没有static属性,则不会像饿汉式那样立即加载对象,只有真正调用getInstance(),才会加载静态内部类。加载类时是线程安全的。 instance是static final 类型,保证了内存中只有这样一个实例存在,而且只能被赋值一次,从而保证了线程安全性.兼备了并发高效调用和延迟加载的优势
枚举式单例模式
public class Test3 {
public static void main(String[] args) {
SingleTon1 s1=SingleTon1.INSTANCE;
SingleTon1 s2=SingleTon1.INSTANCE;
s1.singleTonOperation();
System.out.println(s1==s2);
}
}
enum SingleTon1{
INSTANCE;
public void singleTonOperation(){
System.out.println("operation");
}
}
优点:实现简单,枚举本身就是单例模式。由JVM从根本上提供保障!避免通过反射和反序列化的漏洞!
缺点:无延迟加载
单例模式总结:
单例模式主要的两种实现方式
饿汉式 线程安全,调用效率高,不能延时加载
懒汉式 线程安全,调用效率不高,可以延时加载
其他方式
双重检测锁式 极端情况下偶尔会出现问题,不建议使用
静态内部类式 线程安全,调用效率高,可以延时加载
枚举式 线程安全,调用效率高,不能延时加载

数据库
(详情请参照MySQL面经_someone like you Q的博客-CSDN博客_mysql面经)
ACID:
原子性:undo log(MVCC)
一致性: 最核心和最本质的要求
隔离性:锁,mvcc(多版本并发控制)
持久性:redo log
数据库的事务隔离级别有四种,分别是读未提交、读已提交、可重复读、序列化,不同的隔离级别下会产生脏读、幻读、不可重复读等相关问题,因此在选择隔离级别的时候要根据应用场景来决定,使用合适的隔离级别。
各种隔离级别和数据库异常情况对应情况如下:

SQL 标准定义了四个隔离级别:
-
READ-UNCOMMITTED(读取未提交): 事务的修改,即使没有提交,对其他事务也都是可见的。事务能够读取未提交的数据,这种情况称为脏读。
-
READ-COMMITTED(读取已提交): 事务读取已提交的数据,大多数数据库的默认隔离级别。当一个事务在执行过程中,数据被另外一个事务修改,造成本次事务前后读取的信息不一样,这种情况称为不可重复读。
-
REPEATABLE-READ(可重复读): 这个级别是MySQL的默认隔离级别,它解决了脏读的问题,同时也保证了同一个事务多次读取同样的记录是一致的,但这个级别还是会出现幻读的情况。幻读是指当一个事务A读取某一个范围的数据时,另一个事务B在这个范围插入行,A事务再次读取这个范围的数据时,会产生幻读
-
SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 REPEATABLE-READ(可重读)并不会有任何性能损失。
2、MVCC的实现原理
详见骨灰级SSM 和spring boot大全_someone like you Q的博客-CSDN博客文档
3、mysql幻读怎么解决的
事务A按照一定条件进行数据读取,期间事务B插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B新插入的数据称之为幻读。
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB ;
INSERT into user VALUES (1,'1',20),(5,'5',20),(15,'15',30),(20,'20',30);假设有如下业务场景:

执行流程如下:
1、T1时刻读取年龄为20 的数据,事务1拿到了2条记录
2、T2时刻另一个事务插入一条新的记录,年龄也是20
3、T3时刻,事务1再次读取年龄为20的数据,发现还是2条记录,事务2插入的数据并没有影响到事务1的事务读取
4、T4时刻,事务1修改年龄为20的数据,发现结果变成了三条,修改了三条数据
5、T5时刻,事务1再次读取年龄为20的数据,发现结果有三条,第三条数据就是事务2插入的数据,此时就产生了幻读情况
此时大家需要思考一个问题,在当下场景里,为什么没有解决幻读问题?
其实通过前面的分析,大家应该知道了快照读和当前读,一般情况下select * from ....where ...是快照读,不会加锁,而 for update,lock in share mode,update,delete都属于当前读,如果事务中都是用快照读,那么不会产生幻读的问题,但是快照读和当前读一起使用的时候就会产生幻读。
如果都是当前读的话,如何解决幻读问题呢?
truncate table user;
INSERT into user VALUES (1,'1',20),(5,'5',20),(15,'15',30),(20,'20',30);
此时,可以看到事务2被阻塞了,需要等待事务1提交事务之后才能完成,其实本质上来说采用的是间隙锁的机制解决幻读问题。
4、sql join原理?
MySQL是只支持一种Join算法Nested-Loop Join(嵌套循环连接),并不支持哈希连接和合并连接,不过在mysql中包含了多种变种,能够帮助MySQL提高join执行的效率。
1、Simple Nested-Loop Join
这个算法相对来说就是很简单了,从驱动表中取出R1匹配S表所有列,然后R2,R3,直到将R表中的所有数据匹配完,然后合并数据,可以看到这种算法要对S表进行RN次访问,虽然简单,但是相对来说开销还是太大了。
2、Index Nested-Loop Join
索引嵌套联系由于非驱动表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。这也就是平时我们在做关联查询的时候必须要求关联字段有索引的一个主要原因。
这种算法在链接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表。至于驱动表的选择,MySQL优化器一般情况下是会选择记录数少的作为驱动表,但是当SQL特别复杂的时候不排除会出现错误选择。
在索引嵌套链接的方式下,如果非驱动表的关联键是主键的话,这样来说性能就会非常的高,如果不是主键的话,关联起来如果返回的行数很多的话,效率就会特别的低,因为要多次的回表操作。先关联索引,然后根据二级索引的主键ID进行回表的操作。这样来说的话性能相对就会很差。
3、Block Nested-Loop Join
在有索引的情况下,MySQL会尝试去使用Index Nested-Loop Join算法,在有些情况下,可能Join的列就是没有索引,那么这时MySQL的选择绝对不会是最先介绍的Simple Nested-Loop Join算法,而是会优先使用Block Nested-Loop Join的算法。
Block Nested-Loop Join对比Simple Nested-Loop Join多了一个中间处理的过程,也就是join buffer,使用join buffer将驱动表的查询JOIN相关列都给缓冲到了JOIN BUFFER当中,然后批量与非驱动表进行比较,这也来实现的话,可以将多次比较合并到一次,降低了非驱动表的访问频率。也就是只需要访问一次S表。这样来说的话,就不会出现多次访问非驱动表的情况了,也只有这种情况下才会访问join buffer。
在MySQL当中,我们可以通过参数join_buffer_size来设置join buffer的值,然后再进行操作。默认情况下join_buffer_size=256K,在查找的时候MySQL会将所有的需要的列缓存到join buffer当中,包括select的列,而不是仅仅只缓存关联列。在一个有N个JOIN关联的SQL当中会在执行时候分配N-1个join buffer。
5、说明一下数据库索引原理、底层索引数据结构,叶子节点存储的是什么,索引失效的情况?
索引的实现原理,底层数据结构,叶子节点存储数据需要看视频了解。
索引失效的情况:
1、组合索引不遵循最左匹配原则
2、组合索引的前面索引列使用范围查询(<,>,like),会导致后续的索引失效
3、不要在索引上做任何操作(计算,函数,类型转换)
4、is null和is not null无法使用索引
5、尽量少使用or操作符,否则连接时索引会失效
6、字符串不添加引号会导致索引失效
7、两表关联使用的条件字段中字段的长度、编码不一致会导致索引失效
8、like语句中,以%开头的模糊查询
9、如果mysql中使用全表扫描比使用索引快,也会导致索引失效
6、mysql如何做分库分表的?
使用mycat或者shardingsphere中间件做分库分表,选择合适的中间件,水平分库,水平分表,垂直分库,垂直分表
在进行分库分表的时候要尽量遵循以下原则:
1、能不切分尽量不要切分;
2、如果要切分一定要选择合适的切分规则,提前规划好;
3、数据切分尽量通过数据冗余或表分组来降低跨库 Join 的可能;
4、由于数据库中间件对数据 Join 实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表 Join。
7、数据存储引擎有哪些?
大家可以通过show engines的方式查看对应的数据库支持的存储引擎。
8、描述一下InnoDB和MyISAM的区别?


如何选择?
1、是否需要支持事务,如果需要选择innodb,如果不需要选择myisam
2、如果表的大部分请求都是读请求,可以考虑myisam,如果既有读也有写,使用innodb
现在mysql的默认存储引擎已经变成了Innodb,推荐使用innodb
9、描述一下聚簇索引和非聚簇索引的区别?
innodb存储引擎在进行数据插入的时候必须要绑定到一个索引列上,默认是主键,如果没有主键,会选择唯一键,如果没有唯一键,那么会选择生成6字节的rowid,跟数据绑定在一起的索引我们称之为聚簇索引,没有跟数据绑定在一起的索引我们称之为非聚簇索引。
innodb存储引擎中既有聚簇索引也有费聚簇索引,而myisam存储引擎中只有非聚簇索引。
10、事务有哪些隔离级别,分别解决了什么问题?
参考问题1
11、描述一下mysql主从复制的机制的原理?mysql主从复制主要有几种模式?
参考mysql主从复制原理文档
12、如何优化sql,查询计划的结果中看哪些些关键数据?
参考执行计划文档
13、MySQL为什么选择B+树作为它的存储结构,为什么不选择Hash、二叉、红黑树?
参考问题5
14、描述一下mysql的乐观锁和悲观锁,锁的种类?
乐观锁并不是数据库自带的,如果需要使用乐观锁,那么需要自己去实现,一般情况下,我们会在表中新增一个version字段,每次更新数据version+1,在进行提交之前会判断version是否一致。
mysql中的绝大部分锁都是悲观锁,按照粒度可以分为行锁和表锁:
行锁:
共享锁:当读取一行记录的时候,为了防止别人修改,则需要添加S锁
排它锁:当修改一行记录的时候,为了防止别人同时进行修改,则需要添加X锁

记录锁:添加在行索引上的锁
间隙锁:锁定范围是索引记录之间的间隙,针对可重复读以上隔离级别
临键锁:记录锁+间隙锁
表锁:
意向锁:在获取某行的锁之前,必须要获取表的锁,分为意向共享锁,意向排它锁
自增锁:对自增字段所采用的特殊表级锁
锁模式的含义:
IX:意向排它锁
X:锁定记录本身和记录之前的间隙
S:锁定记录本身和记录之前的间隙
X,REC_NOT_GAP:只锁定记录本身
S,REC_NOT_GAP:只锁定记录本身
X,GAP:间隙锁,不锁定记录本身
S,GAP:间隙锁,不锁定记录本身
X,GAP,INSERT_INTENTION:插入意向锁
15、mysql原子性和持久性是怎么保证的?
原子性通过undolog来实现,持久性通过redo log来实现
总结
-
简历要简洁美观、突出重点,HR是你的第一关。
-
实事求是
-
工作年限
-
技能水平
-
项目经验
-
-
自信、大胆、勇敢!
-
面试当成是聊天,不要当做考试。
-
要薪资不要怂,给自己加价保底30%,切忌自降身价。
-
-
特别想去的公司
如果有特别想去的公司,很多朋友就因为他别想去,而过于担心如果进不去怎么办,反而自乱阵脚。
首先如果有目标特别明确的,特别想进的公司,首先根据提供的JD,做足准备,可以先去其他公司找找多试试,如果成了,那就是给自己多留了几个后手,最后再去想去的公司,第一是短时间内的多次面试已经给自己发现了很多问题,也为自己补充了很多面试经验。第二是自己在自己手里已经有offer的时候,再去面试目标公司,那心里就会更加有底,就算进不去也不至于没有公司去,当然后手准备的越多越好,手里offer越多,面试就越不慌,心态就越平和,越容易正常发挥不会被紧张左右情绪
-
如何面对不会的问题
- 有不懂的很正常,面试官问的,也许只是他擅长的。
-
不正面回答,这时聊一些相关性的知识点,劲儿把话题引导到自己会的知识上去,但是不要天马行空,说话完全不着边际
-
学会如何绕开话题,把话题带到自己会的知识上来。
-
遇到真的完全没遇到过的问题,先别着急说不知道,面试官有时候只是想听听你是如何思考和解决问题的,不一定要你现场就得解决问题,如果确实完全无从下手,大大方方的承认,任何人不可能面面俱到,有没接触过的东西很正常,但是说话要注意方式,不要直接说这个我不会。当然这是在前面几点没办法解决的前提下,如果问什么都是无从下手,那还是得从提升自身技能着手了。
-
-
注意自己的形象和言语谈吐
你和面试官是初次见面,言语要稳重些,不要过于轻浮,能不开玩笑就不要开玩笑。面试面的不仅仅是你的技术实力,还有你的领导力、人品、和颜值(我们尽量不要以貌取人,但是不排除别人会以貌取人),吗,因此发型要干净得体,不要穿的过于正式或随便,不要发型搞的太夸张,比如男生扎小辫、披肩发,就算你技术非常牛逼,技术面试官非常青睐你,你有可能栽在HR手里。我这里没有对弄这些发型的同志们有成见的意思,就是一个提醒,如果是真的喜欢,可以入职以后,想怎么搞怎么搞。我说一下我的亲身经历某友,某捷通。
-
真正的智者,知进退,懂隐忍。
面试是一个展示自身技能的过程,但是对于目前岗位够用就行,不要过于发挥,着急的表现自己的技术,你比面试官强的那部分能力是要留着给老板或者更高的领导看的,可以等入职之后再去展示。凡事留三分余地,做人留一面,来日好相见。你现在生杀大权在面试官手里,如果你表现的压他一头,好像要夺她饭碗似的,他岂能留你?不可能每个面试官都是胸襟宽广的,害人之心不可有,防人之心不可无。想想曹冲怎么死的。莫让英雄无用武之地,凉了你的赤胆雄心,负了你满腔抱负,惜了一身的才华,英雄无用武之地。
-
夯实基础,修炼内功,把功夫用在平时。
是金子总会发光,我们不能总是指望遇到瞎子。面试就像相亲,即是老板选你,也是你选老板。都是双发对彼此有个初步的认识。试用期就是在谈恋爱,都是在彼此发现问题以及解决问题的过程,谈得来就谈,谈不来就散,能不能转正,基本还是要看你自己。但是如果谈不来,损失更大的是你自己,因为公司可以在招一个,而你的经历就会被写在履历里,想改也改不掉。
-
切勿好高骛远,好大喜功。
-
最好有大厂履历,大厂经历是一张不错的名片。
-
勿频繁跳槽。
-
如何看待加班问题
如果面试官问到,你如何看待加班问题,千万别把话说的过于绝对,比如有加班费就行,或者直说拒绝加班,说法律上说的怎样怎样,首先如果你还想在一家公司待下去。guojia在面对一些问题的态度上仍尽量采取和平手段,你觉得你会比guojia更加明智吗?凡是寻求稳妥。
当然我也不是说让你无底线的接受加班,说我可以随时加班,加班到随时,加班使我快乐,我爱加班。如果面试官问你何为高强度,以自身感觉是否会熬坏身体为理由,别回答的太绝对,比比如回答 996就是高强度或者一天超过X小时就是高强度,记住一点,任何问题,除了期望薪资,都别回答那么绝对,别给面试官一种过了这条线就不行那种感觉,相亲的时候,如果你想找个肤白貌美的,170的。100斤的,月入2W的,本科学历的,独生子的,假如身高165矮了5厘米,或者体重105重了五斤,但是美的不可方物,你就坚决不要么?所以不要给面试官这种感觉,低于170的坚决不要,就是不要给他一个明确的界限,只要不在某一方面过于偏科就行),但是接受高强度的紧急加班。那些说只要工作效率低的人才会加班,效率高的都会在8小时工时之内完成任务的人话说的可能也有些片面了。首先除了部分国企或外企之外互联网公司多多少少都是存在加班现象的,这是你没得选择的,合理的加班也是可以理解的,公司养一个员工确实成本也挺大的,要为你缴纳高额的社保还有企业所得税等,作为决策者他不得不为成本去考虑,为人者知谦卑、懂感恩、有胸怀。说心里话,我们之中相当一部分人得到其实是大于其为公司带来的价值的,所以其实有时候不仅人与人之间要学会换位思考,人与企业之间也要学会换位思考,你事事为公司着想,老板不会看不到的。所以面对加班,正确的答案应该是,对于平日里的一定量加班,我们也应与理解,不要老是死磕那一二十块钱的加班费,不仅显得你格局小,而且有那个时间,不如去提升一下自己的硬实力,提高自己的价值。其次面对如项目上线、突发状况的加班,即便是可能是需要通宵,比较辛苦,也是可以接受的,不要除了抱怨还是抱怨。
最后就是面对高强度的日常加班,我说过,员工和企业要学会换位思考,既要有为公司奉献的觉悟,也不能被公司过分压榨。因为我们作为员工如果事实为公司考虑,比如牺牲了自己爱人、子女的时间换来的是无休止的压榨,如007(一天12小时,一周工作七天成为了日常),那可能最终熬坏了身体还不落好,这种情况不用想,绝不接受,身体是革命的本钱。赚再多的钱,也需要得有命花。
总结一下加班的正确答复:原则上是拒绝无休止的高强度日常加班(何为被问高强度我刚才已经教你怎么说了),但是如果公司有突发状况如项目上线,需要高强度加班是完全可以理解的,这也是我觉得一个合格的开发应该有的觉悟吧(这里注意说话的语气和言辞以及方式)。
PS:不针对面试,就说说咱们自己应该如何看待加班。不要把加班看成一种吃亏,对于没对象的朋友,仔细想想,你下班回去可能无非就是处理一些杂事儿、或者玩游戏、追剧。如果你是想追求更高目标的,可能公司也许有更好的学习环境和氛围,即便你完成了领导要求的任务,不如多思考一下哪些东西可以做的更好或者哪些东西是将来有可能需要的,即便现在可能用不到,你也可以借此来尝试一些自己想要学习的技术,比如之前的方案采用的是基于MySql的方案,思考一下是否采用ES效果更好,有了想法就是学,就去做。一般来说公司也都会愿意为你提供一些资源,比如你的测试机应该完全够你部署一些你学习过程中需要的服务。就算没有也可以想方设法的搞一些环境,比如阿里云有提供学习用的低配ECS,每年只需要100块钱。是在不行在你的PC上也可以搞,搞几台虚拟机搭个集群自己随便搞有啥不好,只要你想学,什么都拦不住你。等你的实验项目落实了,完全可以做个测试拿出个方案出来,比如你测试了使用MySql和ES两种的搜索方案的性能对比出来,如果有理有据,并且愿意分享成果,相信你的领导也愿意支持你,即便这东西现在用不上,但是如果哪天突然领导提出了这样的需求,你高速领导,这事儿我已经做好了,你看。你觉得公司会不喜欢这样处处为公司着想的员工么。你不但学到了东西,而且还把握住了机会,如果将来有晋升的名额,你你也许就有机会。但是要记住一点就是有任何功劳都要记得与别人分享,尤其是你的直系领导,这是在某领导的英明决策和指挥以及全力支持下,有你去落实的。不然就算你的能力是货真价实的,可能也会被埋没,其实看起来是你的功劳被别人占了便宜,其实是你占便宜了。因为你只有把利益和别人扯上关系,别人才会主动帮你推这件事儿。并且你懂得分享功劳,领导如果升迁,难道它的位置第一个想举荐的不肯定就是你吗?这其实也是良性循环,你想得到的得到了,你为公司带来了价值,公司给你了更大的施展空间。即便事情没有这么理想,你在公司没有遇到这样的机会,你至少也是学到了东西,你做的东西在以后的面试中、工作中可能都用得到。换个角度,你会发现一大片天空。