虚拟机上Centos系统的搭建以及环境配置
(windows上需要安装)2.vmware、3.secureCRT、4.WinSCP、5、JDK、6、eclipse、7、maven(
虚拟机需要)1.centos7-minimal.iso、2、jdk-linux、3、hadoop、4、mysql、5、hive、6、ZooKeeper、7、kafka、8、flume、9、spark、10、scala、11、mysql-connector
1.Centos虚拟机的创建:
1)打开VMware workstation 15 player创建虚拟机裸机。
选择创建新虚拟机:
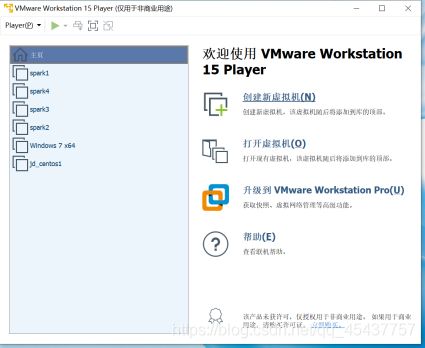
在弹出窗口中选择“稍后安装操作系统”->下一步
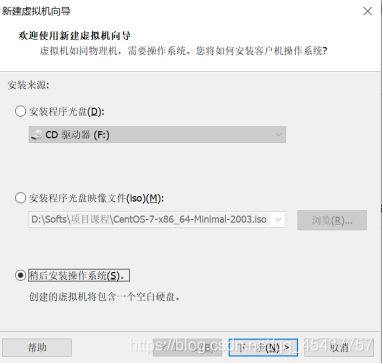
在窗口中的”客户机操作系统”选择“Linux”,然后在“版本”下拉框中选择“Centos7 64位”,最后点击“下一步”进入新的窗口。

在新窗口中,在“虚拟机名称”文本框中输入虚拟机名称,然后在“位置”文本框中输入虚拟机文件存储的位置。(注意,不要放到系统盘符下,会造成系统盘使用空间激增),最后点击“下一步”进入新的窗口。
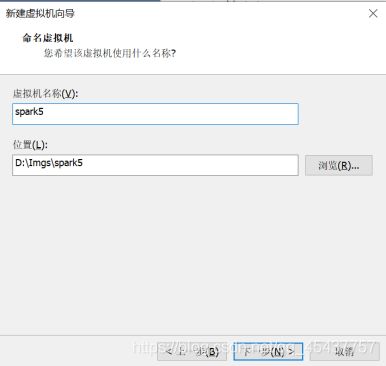
在新窗口中指定磁盘空间(此处选择20G),然后选择“将虚拟磁盘拆分成多个文件”,最后点击“下一步”进入新的对话框。
在新窗口中,点击“自定义硬件”
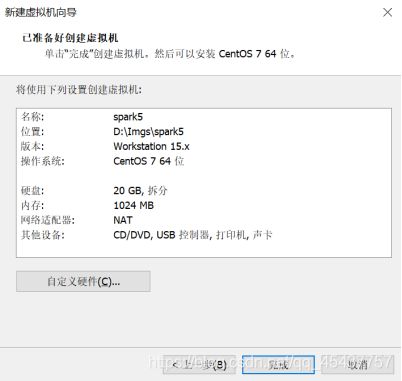
在硬件对话框中设置内存大小、“新CD/DVD(IDE)”和“网络适配器”等硬件信息。其中,内存大小设置为1024MB、“新CD/DVD(IDE)”中选择“使用ISO映像文件”并点击“浏览”按钮选择CentOS7的镜像文件,在“网络适配器”中选择“桥接模式”,最后点击“关闭”按钮。


返回上一对话框窗口后点击“完成”按钮,完成虚拟机裸机的创建。
2)虚拟机操作系统CentOS7的安装
选择新建的机器(本例为spark5),点击“播放虚拟机”来打开虚拟机。
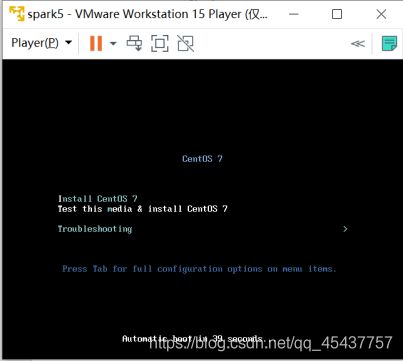
点击虚拟机区域,光标进入虚拟机,移动键盘上下键,在安装界面中选择“Install CentOS 7”后按下回车键,进入安装程序。
在欢迎窗口中,选择中文->简体中文(中国)后点击“继续”按钮进入下一个对话窗口。
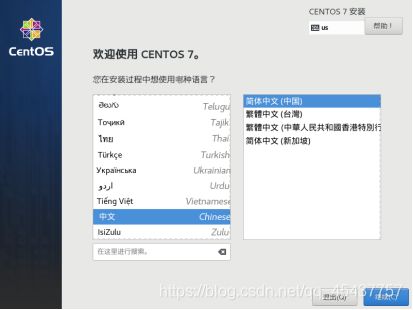
在安装信息摘要对话框中选择“安装位置”进入”安装目标位置”对话框。

在“安装目标位置”对话框中直接点击“完成”按钮。完成安装位置的设置,返回“安装信息摘要”对话框。
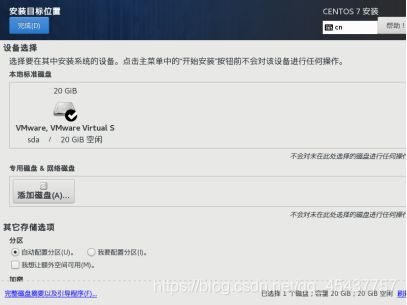
在安装信息摘要对话框中选择“网络”,进入”网络和主机名”对话框,分别设置主机名,以太网连接状态。
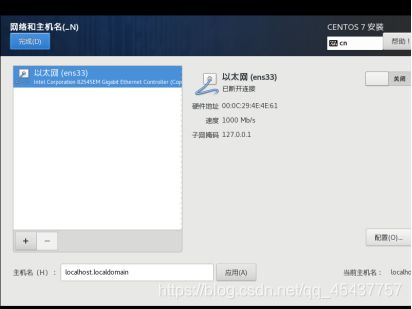
在“主机名“文本框中输入主机名,后点击“应用“按钮。
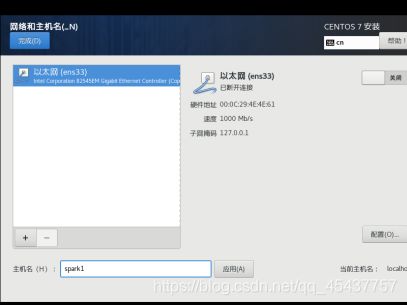
点击“关闭“按钮,使状态变为“打开“。最后点击”完成“按钮退出网络和主机名对话框窗口。
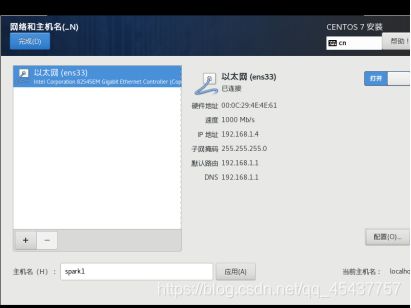
返回安装信息摘要对话框后,点击“开始安装“按钮进入系统安装。
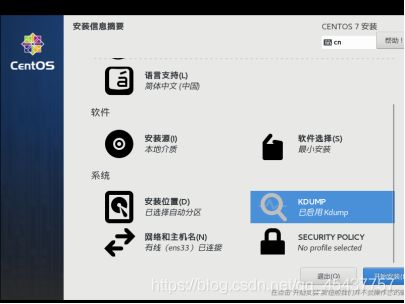
在安装对话框中,点击“ROOT密码“,进入root密码设置对话框。

为root用户设置密码,设置完成后,点击“完成“按钮完成root密码设置。
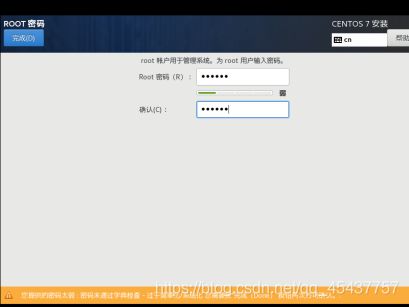
等待文件拷贝完成后,点击重启,重启进入系统。
2网络配置:
按照主机ip地址如下映射关系,依次配置三台虚拟机的网络:
192.168.1.109 spark1
192.168.1.107 spark2
192.168.1.108 spark3
此处以spark1为例
1)使用ip addr命令查看网卡的ip地址。
2)使用vi /etc/sysconfig/network-scripts/ifcfg-ens33命令编辑网络配置信息
a)添加(GATEWAY要在windows中的cmd窗口使用ipconfig /all查看)
IPADDR=“192.168.1.109”
GATEWAY=“192.168.1.1”
NETMASK=“255.255.255.0”
DNS1=“114.114.114.114”
DNS2=“192.168.1.1”#(和网关地址一致)
b)修改:
ONBOOT=“yes”
BOOTPROTO=“static”
c)输入“:wq”保存退出。
3)重启网络:service network restart
4)测试网络环境
ping www.baidu.com
5)依次安装spark2、spark3
6)vi /etc/hosts
添加:
192.168.1.109 spark1
192.168.1.107 spark2
192.168.1.108 spark3
7)windows下修改C:\Windows\System32\drivers\etc\hosts
找到notepad.exe程序右键选择“以管理员身份运行”
从notepad中打开hosts文件,并在文件中添加ip地址到虚拟机的映射:
192.168.1.109 spark1
192.168.1.107 spark2
192.168.1.108 spark3
7)测试 ping spark1
3.使用SecureCRT远程连接虚拟机
1)在windows中安装SecureCRT,安装成功后,打开SecureCRT。
2)打开“File”->“quick connect”打开Quick Connect对话框,在Hostname文本框中输入要连接的虚拟主机名,并在Username中输入root用户名。最后点击Connect按钮远程连接虚拟机。

4)连接成功后可以在SecureCRT中远程操作虚拟机。
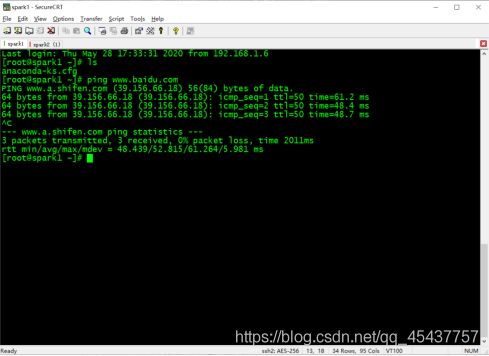
4. 安装WinSCP实现Windows和Linux虚拟机的文件互拷。
1)安装WinSCP软件后点击“新建会话”按钮,弹出登陆对话框。
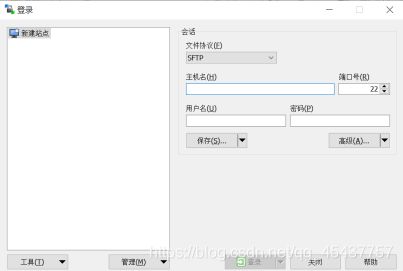
在对话框的主机名文本框中输入需要连接的虚拟主机名,然后在用户名文本框和密码文本框中分别输入root和root密码,最后点击登陆按钮,连接虚拟主机。
登陆成功后的界面如下:
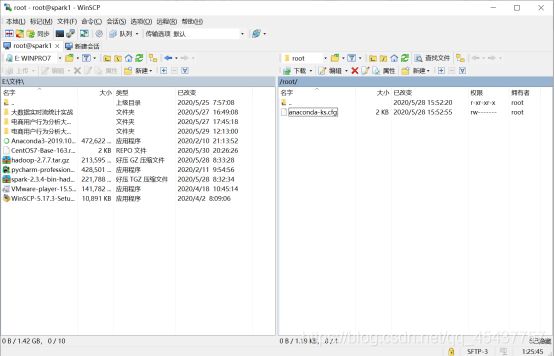
其中,左侧为Window主机的资源管理框,右侧为Linux虚拟主机的资源管理框。
从windows选择合适的文件后点击上传按钮可以将对应文件拷贝到Linux虚拟机中,类似地,在Linux中选择合适的文件后点击下载按钮可以将文件拷贝到Windows主机中。
5.更改Linux更新源
1)使用WinSCP拷贝CentOS7-Base-163.repo到虚拟机中默认为/root/目录下
2)备份并替换系统的repo文件
cd /etc/yum.repos.d/
rm -rf .
cp ~/CentOS7-Base-163.repo CentOS-Base.repo
3)编辑CentOS-Base.repo
vi CentOS-Base.repo
修改所有gpgcheck=1为gpgcheck=0
4)执行yum源更新命令
yum clean all
yum makecache
yum install telnet
6. 安装java(在/root/目录中操作)
1)下载jdk-8u92-linux-x64.gz包
2)tar –zxvf ~/jdk-8u162-linux-x64.tar.gz 解压包
3) 创建文件夹mkdir /usr/lib/jvm/ 和mkdir /usr/lib/jvm/jdk/
4)mv ~/jdk1.8.0_162/ /usr/lib/jvm/jdk/jdk1.8 移动压缩后的文件
5) vi ~/.bashrc 设置java环境变量
#set java enviroment
export JAVA_HOME=/usr/lib/jvm/jdk/jdk1.8
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
6)source ~/.bashrc更新
7)java –version 验证
注意:若失败可使用update-alternatives
update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk/jdk1.8/bin/java 300
update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk/jdk1.8/bin/javac 300
update-alternatives --config java
7. 安装ssh并免密码登陆ssh(多次试验尚未成功)
1)ssh-keygen –t rsa 在spark1端生成私钥和公钥
根据提示直接回车
2)复制公钥
cd /root/.ssh/
cp id_rsa.pub authorized_keys
3) 测试:
ssh spark1(第一次需要输入密码)
ssh spark (不提示输入密码表示成功)
4)和其它两台机器免密码访问
ssh-copy-id -i spark2 (免密访问spark2)
ssh-copy-id -i spark3 (免密访问spark3)
8. 开机禁用防火墙(三台机器都需要执行)
systemctl stop firewalld.service
systemctl disable firewalld.service
查看防火墙状态命令:systemctl status firewalld.service
二、Hadoop集群搭建
- Hadoop安装(在spark1机器的/root目录下)
1) tar -zxvf ~/hadoop-2.7.7.tar.gz 解压
2) mv ~/hadoop-2.7.7 /usr/local/hadoop
3)添加环境变量:
vi ~/.bashrc
添加:
#set hadoop enviroment
export HADOOP_HOME=/usr/local/hadoop
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
4)创建数据文件夹
mkdir /usr/local/data
1.环境配置:(可以用winSCP打开对应文件编辑)
1)进入hadoop配置目录
cd /usr/local/hadoop/etc/Hadoop
2)配置core-site.xml文件
vi core-site.xml
在间添加
fs.default.name
hdfs://spark1:9000
3)配置hdfs-site.xml文件
vi hdfs-site.xml
在间添加
dfs.name.dir
/usr/local/data/namenode
dfs.data.dir
/usr/local/data/datanode
dfs.tmp.dir
/usr/local/data/tmp
dfs.replication
2
4)配置mapred-site.xml
cp mapred-site.xml.temple mapred-site.xml
vi mapred-site.xml
在间添加
mapreduce.framework.name
yarn
5)配置yarn-site.xml
vi yarn-site.xml
在间添加
yarn.resourcemanager.hostname
spark1
yarn.nodemanager.aux-services
mapreduce_shuffle
6)修改slaves文件
vi slaves
文件中添加
spark2
spark3
2.将hadoop部署到spark2和spark3
scp -r /usr/local/hadoop root@spark2:/usr/local
scp -r /usr/local/hadoop root@spark3:/usr/local
3.分发.bashrc文件
scp ~/.bashrc root@spark2:~/
scp ~/.bashrc root@spark3:~/
更新.bashrc,在spark2和spark3两台机器中执行:
source ~/.bashrc
4.在spark2和spark3上创建data目录,在两台机器上分别执行以下语句
mkdir /usr/local/data
6. hdfs namenode –format 格式化文件系统HDFS
7. start-dfs.sh 启动hadoop
8. 验证是否执行
在浏览器输入http://spark1:50030 (MapReduce的web页面)
http://spark1:50070 (HDFS的web页面)
或命令:hdfs dfsadmin –report
9. 上传一个文件
创建一个文件hello
hdfs dfs -put ~/hello /
10. 启动yarn
start-yarn.sh
在浏览器中输入 http://spark1:8080
三、MySQL的安装(在/root目录下操作)
1.安装repo源
yum -y install mysql57-community-release-el7-11.noarch.rpm
2.安装mysql server
yum -y install mysql-server
3.启动mysql服务
service mysqld start
chkconfig mysqld on
4.重置root密码
1)修改my.cnf
vi /etc/my.cnf
在[mysqld]后面任意一行添加“skip-grant-tables”后保存并退出。
2)重启mysql
service mysqld restart
3)输入mysql -u root -p mysql进入mysql
提示密码时按回车键。
4)更改密码为“123456”
update user set authentication_string=password(“123456”) where user=“root”;
flush privileges;
5)修改密码为“Hadoop_123”
set password=password(“Hadoop_123”);
flush privileges;
四、Hive环境搭建
- 使用winSCP将apache-hive-2.3.7-bin.tar.gz安装包拷入/root目录
- 进入root目录并解压apache-hive-2.3.7-bin.tar.gz
cd ~
tar -zxvf apache-hive-2.3.7-bin.tar.gz - 移动到安装目录
mv ~/apache-hive-2.3.7-bin /usr/local/hive - 环境变量配置
修改.bashrc文件
vi ~/.bashrc
添加如下内容:
#set hive enviroment
export HIVE_HOME=/usr/local/hive
export PATH= P A T H : PATH: PATH:HIVE_HOME/bin - 配置hive
1)hive-site.xml
cp /usr/local/hive/conf/hive-default.xml.template /usr/local/hive/conf/hive-site.xml
修改:
javax.jdo.option.ConnectionURL
jdbc:mysql://spark1:3306/hive_metadata?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
javax.jdo.option.ConnectionUserName
hive
Username to use against metastore database
2)hive-env.sh
cp /usr/local/hive/conf/hive-env.sh.template /usr/local/hive/conf/hive-env.sh
修改:
3) hive-config.sh(bin目录中)
vi /usr/local/hive/bin/hive-config.sh
五、mysql connector安装
1. 解压缩mysql-connector-java-5.1.49.tar.gz
tar -zxvf mysql-connector-java-5.1.49.tar.gz
2. 移动到安装目录
mv ~/mysql-connector-java-5.1.49 /usr/local/connector
3. 将jar包复制到Hive
cp /usr/local/connector/mysql-connector-java-5.1.49.jar /usr/local/hive/lib/
六、mysql和hive的整合
1.登陆mysql
mysql -u root -p
2. 在mysql上创建hive元数据库,创建hive账号并授权。
create database if not exists hive_metadata;
3. 创建hive用户,并赋权:
create user ‘hive’@’%’ identified by ‘hive_123’;
grant all privileges on hive_metadata.* to ‘hive’@’%’ identified by ‘hive_123’;
grant all privileges on hive_metadata.* to ‘hive’@‘localhost’ identified by ‘hive_123’;
grant all privileges on hive_metadata.* to ‘hive’@‘spark1’ identified by ‘hive_123’;
- 测试:
create table users(id int, name string);
load data local inpath ‘/root/users.txt/’ into table users;
select * from users;
七、ZooKeeper搭建- 解压缩
tar -zxvf ~/zookeeper-3.4.14.tar.gz
- 解压缩
- 移动到安装目录
mv ~/zookeeper-3.4.14 /usr/local/zk
3.修改~/.bashrc文件
vi ~/.bashrc
#set zookeeper enviroment
export ZOOKEEPER_HOME=/usr/local/zk
export PATH= P A T H : PATH: PATH: ZOOKEEPER_HOME /bin
4.更新~/.bashrc文件
source ~/.bashrc
5.配置zoo.cfg
cp /usr/local/zk/conf/zoo_sample.cfg /usr/local/zk/conf/zoo.cfg
vi /usr/local/zk/zoo.cfg
修改:
dataDir=/usr/local/zk/data
添加:
server.0=spark1:2888:3888
server.1=spark2:2888:3888
server.2=spark3:2888:3888
6.mkdir /usr/local/zk/data
vi /usr/local/zk/data/myid
添加:
0
7.将zk目录拷贝到其它机器:
scp -r /usr/local/zk root@spark2:/usr/local
scp -r /usr/local/zk root@spark3:/usr/local
并修改spark2和spark3中/usr/local/zk/data/myid中内容为1,2
8.拷贝.bashrc到其它机器并更新
scp ~/.bashrc root@spark2:~/
scp ~/.bashrc root@spark3:~/
到对应机器上运行:
source ~/.bashrc
9.验证
在各个机器上分别执行
1)启动ZooKeeper:zkServer.sh start
2)检测ZooKeeper状态:zkServer.sh status
3)jps:检查三个节点是否都有QuromPeerMain进程。
八、scala的安装
- 对scala
tar -zxvf ~/scala-2.11.12.tgz
mv ~/scala-2.11.12 /usr/local/scala
2.配置环境变量
vi ~/.bashrc
添加
#set scala enviroment
export SCALA_HOME=/usr/local/scala
export PATH= P A T H : PATH: PATH: SCALA_HOME/bin
source ~/.bashrc
scala -version
3.scala目录考到其它机器
scp -r /usr/local/scala/ root@spark2:/usr/local
scp -r /usr/local/scala/ root@spark3:/usr/local
scp ~/.bashrc root@spark2:~/
scp ~/.bashrc root@spark3:~/
在各机器上source ~/.bashrc
最后测试:scala -version
九、kafka集群的搭建
- 解压缩
tar -zxvf ~/kafka_2.11-0.10.2.2.tgz
mv ~/kafka_2.11-0.10.2.2 /usr/local/kafka
2.配置环境变量
vi /usr/local/kafka/config/server.properties
修改
brokerid依次修改为0,1,2
zookeeper.connect=192.168.1.107:2181,192.168.1.108:2181,192.168.1.109:2181- 安装slf4j
slf4j-nop-1.7.6.jar复制到/usr/local/kafka/libs
cp ~/slf4j-nop-1.7.6.jar /usr/local/kafka/libs
- 安装slf4j
- kafka目录考到其它机器
scp -r /usr/local/kafka/ root@spark2:/usr/local
scp -r /usr/local/kafka/ root@spark3:/usr/local
修改两台机器上机器上的erver.properties
vi /usr/local/kafka/config/server.properties
修改
brokerid依次修改为1,2- 在机器上验证,分别在三台机器上执行
cd /usr/local/kafka/
nohup bin/kafka-server-start.sh config/server.properties &
6.集群测试
/usr/local/kafka/bin/kafka-topics.sh --zookeeper 192.168.0.34:2181,192.168.0.45:2181,192.168.0.66:2181 --topic TestTopic --replication-factor 1 --partitions 1 –create
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list 192.168.0.34:2181,192.168.0.45:2181,192.168.0.66:2181 --topic TestTopic
然后克隆一个spark1,执行如下命令:
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper 192.168.0.34:2181,192.168.0.45:2181,192.168.0.66:2181 --topic TestTopic --from-beginning
十、flume集群的搭建
1.解压缩
tar -zxvf apache-flume-1.8.0-bin.tar.gz
mv ~/apache-flume-1.8.0-bin /usr/local/flume
2.配置环境变量
1)配置.bashrc
vi ~/.bashrc
添加
#set flume enviroment
export FLUME_HOME=/usr/local/flume
export FLUME_CONF_DIR= F L U M E H O M E / c o n f e x p o r t P A T H = FLUME_HOME/conf export PATH= FLUMEHOME/confexportPATH=PATH:$ FLUME_HOME/bin
source ~/.bashrc
2)配置flume-conf.properties
mv /usr/local/flume/conf/flume-conf.properties.template /usr/local/flume/conf/flume-conf.properties
用以下内容覆盖:
#agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/logs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/logs_tmp_cp
agent1.channels.channel1.dataDirs=/usr/local/logs_tmp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://spark1:9000/logs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
3)创建相应的文件夹
虚拟机创建本地文件夹:
mkdir /usr/local/logs
创建hdfs文件夹
hdfs dfs -mkdir /logs
4.启动flume
flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console
然后克隆一个spark1,执行如下命令:
vi ids1
mv ~/ids1 /usr/local/logs
十一、spark集群的搭建
1.解压缩
tar -zxvf ~/spark-2.3.4-bin-hadoop2.7.tgz
mv ~/spark-2.3.4-bin-hadoop2.7 /usr/local/spark
2.配置环境变量
1)配置.bashrc
vi ~/.bashrc
添加
#set spark enviroment
export SPARK_HOME=/usr/local/spark
export CLASSPATH= C L A S S P A T H : CLASSPATH: CLASSPATH:JAVA_HOME/lib: J A V A H O M E / j r e / l i b e x p o r t P A T H = JAVA_HOME/jre/lib export PATH= JAVAHOME/jre/libexportPATH=PATH:$ SPARK_HOME E/bin
source ~/.bashrc
2)配置spark-env.sh
mv /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
添加如下内容:
export JAVA_HOME=/usr/lib/jvm/jdk/jdk1.8
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
3)配置slave
mv /usr/local/spark/conf/slaves.template /usr/local/spark/conf/slaves
注释掉localhost,然后添加如下内容:
spark2
spark3
- 在机器上验证,分别在三台机器上执行
- spark目录考到其它机器
scp -r /usr/local/spark/ root@spark2:/usr/local
scp -r /usr/local/spark/ root@spark3:/usr/local
scp ~/.bashrc root@spark2:~/
scp ~/.bashrc root@spark3:~/
在各机器上source ~/.bashrc
4.启动spark
start-yarn.sh
/usr/local/spark/sbin/start-all.sh
浏览器查看spark: http://spark1:8080/
浏览器查看yarn: http://spark1:8088/
浏览器查看Hadoop: http://spark1:50070/
5.测试
/usr/local/spark/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master yarn-cluster --num-executors 2 --driver-memory 1024m --executor-memory 1024m --executor-cores 1 /usr/local/spark/examples/jars/spark-examples_2.11-2.3.4.jar
Eclipse的安装:
1.下载 JDK和Eclipse安装包;
2.JDK的安装
1)解压缩JDK安装包,并拷贝解压缩后的文件夹到安装目录(以下安装目录都以D:\programs\java为例)
2)右键“此电脑”或“我的电脑”选择“属性”;

进入系统对话框,然后选择高级系统设置。

进入系统属性对话框,然后选择高级->环境变量
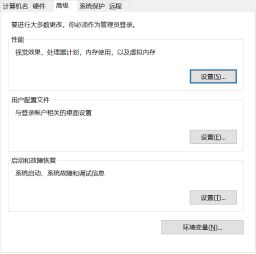
进入环境变量对话框,设置系统变量,选择新建…

进入新建系统变量对话框,添加变量名:JAVA_HOME,变量值:D:\programs\java\jdk-14.0.1,然后点击确定。
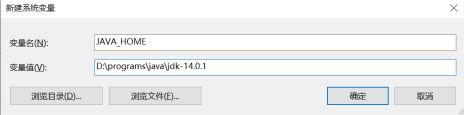
同样的方法添加变量名:CLASSPATH,变量值:%JAVA_HOME%\lib; %JAVA_HOME%\lib\tools.jar。
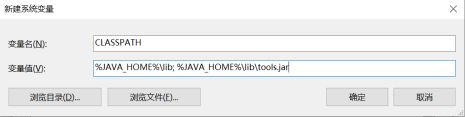
JAVA_HOME和CLASSPATH环境变量添加完后,需要在Path环境变量中添加:%JAVA_HOME%\bin。
在系统变量中找到Path,然后点击编辑按钮。
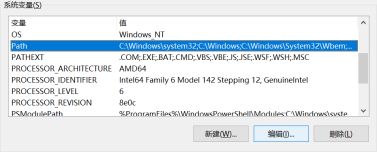
进入编辑环境变量对话框,然后点击新建后添加%JAVA_HOME%\bin到新行中。
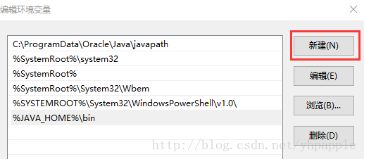
添加完成后,点击确定,完成环境变量添加。
3.Eclipse的安装
1)解压缩Eclipse安装包,后移动到安装目录下(以下安装目录都以D:\programs为例)
2)进入eclipse目录,然后找到eclipse执行文件,创建快捷方式到桌面。
3)点击eclipse快捷方式,打开eclipse。
4.maven安装
1)解压缩maven安装包,后移动大安装目录下(以下安装目录都以D:\programs为例)
2)使用Java安装的方法添加MAVEN_HOME变量:

3)添加%MAWEN_HOME%/bin到Path环境变量中。
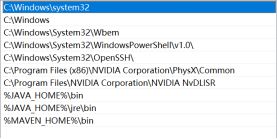
5. Eclipse和Maven的整合