【推荐算法】MMoE模型:Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
1、MMoE背景
MMoE是谷歌在2018年发表在KDD上的一篇基于多任务学习的经典论文,其使用场景是对不相关任务的多任务学习。在推荐系统中,这些不相关的任务可以示例为:视频流推荐中的CTR、时长、点赞、分享、收藏、评论等相关性不强的多个任务。
2、MMoE模型概述
MMoE模型的基础结构是“Shared-Bottom multi-task DNN”结构,Shared-Bottom model(网络结构如下图)。
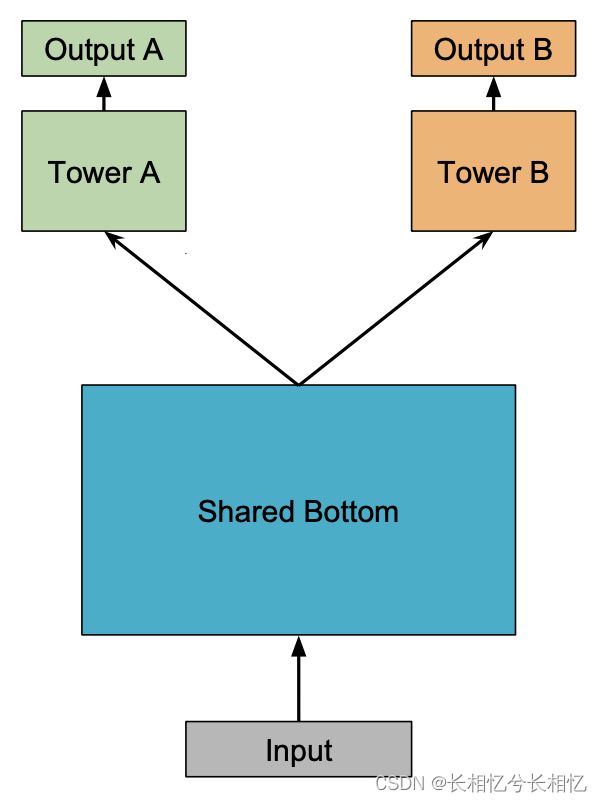
Shared-Bottom model在输入层后接入几个bottom层作为多任务的共享网络结构,然后每个任务有一个独立的网络“塔”。
假设当前有K个任务,Shared-bottom Multi-task Model由一个shared-bottom的网络组成,这个shared-bottom网络可表示为函数f,将K个tower networks表示为![]() ,其中k=1,2,...,K为任务数。Shared-Bottom model的shared-bottom网络接入的是输入层,每个tower networks建立在shared-bottom网络的输出上,每个tower networks的输出就是对每个独立任务的网络输出,可表示为
,其中k=1,2,...,K为任务数。Shared-Bottom model的shared-bottom网络接入的是输入层,每个tower networks建立在shared-bottom网络的输出上,每个tower networks的输出就是对每个独立任务的网络输出,可表示为 。这样,对于子任务k,Shared-Bottom model的网络输出为:
。这样,对于子任务k,Shared-Bottom model的网络输出为:

与所有任务共享底层网络不同的是,MMoE模型使用一组底层网络,Bottom网络中的每个网络都是一个Expert专家网络(Expert专家网络采用的是前馈神经网络)。MMoE结构为每一个任务设置一个“门网络Gate”,Gate网络的输入是输入特征,输出是每一个专家网络的权重,也就是说Gate网络用来选择每个Expert网络的权重,即每个Gate网络都可以根据不同任务来选择专家网络的子集。

3、RELATED WORK
多目标模型能够学习不同任务间的共性和差异。对于每个任务来说,多任务模型不仅能够提升效率还能够提升模型质量。当前使用广泛的多任务学习模型采用的是shared-bottom的模型结构,这种结构的底层网络被所有目标共享。这种模型结构虽然能够一定程度上减少过拟合的风险,但是因为所有的任务共享底层网络参数及目标间的差异性会导致网络难于最优化。
4、MMoE
4.1、Mixture-of-Experts
原始的MoE模型结构:

与Shared-bottom网络不同的是,One-gate MoE网络结构是将隐藏层划分为三个专家(expert)子网,同时接入一个Gate网络将各个子网的输出和输入信息进行组合,并将得到的结果进行相加。
MoE模型可公式化表示为:
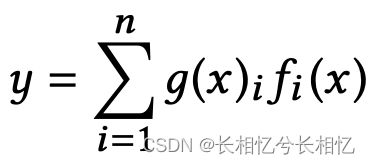
其中,  表示第i个专家网络,i=1,2,...,n,
表示第i个专家网络,i=1,2,...,n, 是用来组合所有专家网络的结果的一个门网络。
是用来组合所有专家网络的结果的一个门网络。
 ,
,![]() 是g(x)的第i个logit输出,表示专家网络的概率值。Gate网络输出每个 Expert被选择的概率,然后将三个Expert 的输出加权求和。也就是说,Gate网络产生n个experts上的概率分布,最终的输出是所有experts的带权加和。
是g(x)的第i个logit输出,表示专家网络的概率值。Gate网络输出每个 Expert被选择的概率,然后将三个Expert 的输出加权求和。也就是说,Gate网络产生n个experts上的概率分布,最终的输出是所有experts的带权加和。
4.2、Multi-gate Mixture-of-Experts
MMoE模型的核心思想:使用一个MoE层代替shared bottom network。
MMoE模型为每个任务k添加一个独立的门网络![]() ,任务k的输出是:
,任务k的输出是:

MMoE模型由使用ReLU激活单元的相同多层感知机组成,门网络是输入经过softmax层的一个线性变换:

其中,![]() 是训练矩阵,n是专家网络数,d是特征的维度。
是训练矩阵,n是专家网络数,d是特征的维度。

4.3、三种结构对比

图a中的模型是最常用也是最基础的shared-bottom模型,这个模型不同任务共享底层的tower,然后每个任务各自学习一个上层的tower。
由于多个任务共享底层的tower,可以使底层的信息学习的非常充分,同样的,如歌不同任务间相关性不强,在学习过程中可以发生参数冲突(即同个特征在不同任务中可能是相反的作用)
为了底层的共享网络对不同任务也能做到个性化,图b中的MoE结构将共享网络由多个专家网络组成,并用了一个gate模型去学习不同专家网络的权重,最后每个任务是不同专家网络的加权和。底层共享网络由多个专家网络组成,增加了底层网络的个性化,可以减少参数参数冲突。
图c中的MMoE网络,和图b中的网络对比,每个任务学习了单独的一个gate。
其优点就是对共享的底部网络增加了个性化,对于相关性比较差的任务也能表现的很好;缺点就是增加了模型的复杂度,而且每个任务都学了一个gate网络,最优解非常多,难以学好。
5、参考资料
- MMoE论文
- DeepCTR/mmoe.py at master · shenweichen/DeepCTR · GitHub
- 推荐系统 - MMoE模型 - 简书