深入理解feature_column
此前对觉得feature_column用起来非常抽象,所以一直不想用。但是迁移到tf2 以后发现很多场景不得不用,所以深入研究了一下。
本文从tensorflow的源码入手,分析了featurecolumn的用法。
首先就是这张老生常谈的图: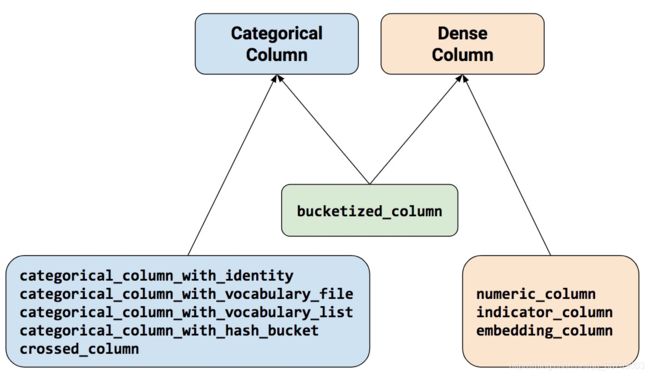
feature_coumn的根父类是FeatureColumn,从FeatureColumn 派生出两个子类categorical column 和 dense column。然后衍生出途中最下面的其他的子类。
根父类FeatureColumns有三个关键的函数
transform_feature(self, transformation_cache, state_manager) 这个函数用于把特征的tensor进行转换,例如hashbucket,indicator等等
def create_state(self, state_manager): 用于创建featurecolumn的操作中需要用到的带训练参数,例如embedding
FeatureColumns的两个子类,categorical column, dense column
其中dense column的核心函数是
get_dense_tensor(self, transformation_cache, state_manager)
用于获取densecolumn中的tensor
categorical column的核心函数是
get_sparse_tensors(self, transformation_cache, state_manager)
用于获取densecolumn中的sparsetensor
可以看到核心的几个函数都会用到transformation_cache, state_manager两个类。
我们以numericcolumn.transform_feature为例,这个column的tranform_feature非常简单,就是把feature_dcit的里面的tensor取出来,没有别的操作
return transformation_cache.get(self.key, state_manager)
可以看到featurecolumn通过调用transformation_cache.get 方法获取特征值tensor,然后才进行transform操作。
这是因为我们从tfreord中解析出来的是一个dict,key是特征名,value是特征值的tesnsor。而featurecolumn在定义的时候,只是给定了key值,即只给定了特征名,并没有给定特征值。所以feature_column可以理解成记录了特征的操作方式。
所以我们需要一个类,这个类记录了特征值tensor,然后和feture_clolumns结合后,一个记录特征值,一个记录特征值的操作方式。就可以对特征值进行操作了。说到这里,我们自然就可以猜到transformation_cache类的init函数和主要的函数了。
transformation_cache的init函数
def __init__(self, features):
"""Creates a `FeatureTransformationCache`.
Args:
features: A mapping from feature column to objects that are `Tensor` or
`SparseTensor`, or can be converted to same via
`sparse_tensor.convert_to_tensor_or_sparse_tensor`. A `string` key
signifies a base feature (not-transformed). A `FeatureColumn` key
means that this `Tensor` is the output of an existing `FeatureColumn`
which can be reused.
"""
self._features = features.copy()
self._feature_tensors = {}其中入参feature是一个从tfrecord中解析出来的map,key是特征名,value是特征值的tesnsor
定义一个属性_feature 是入参feature的拷贝。
定义一个空的map ,_feature_tensor
transformation_cache 有两个方法:
def get(self, key, state_manager):
def _get_raw_feature_as_tensor(self, key):
_get_raw_feature_as_tensor 方法就是根据key讲原始的tensor取出,其中有一些维度操作,用于处理数据没有batch的情况。
def _get_raw_feature_as_tensor(self, key):
"""Gets the raw_feature (keyed by `key`) as `tensor`.
The raw feature is converted to (sparse) tensor and maybe expand dim.
For both `Tensor` and `SparseTensor`, the rank will be expanded (to 2) if
the rank is 1. This supports dynamic rank also. For rank 0 raw feature, will
error out as it is not supported.
Args:
key: A `str` key to access the raw feature.
Returns:
A `Tensor` or `SparseTensor`.
Raises:
ValueError: if the raw feature has rank 0.
"""
raw_feature = self._features[key]
feature_tensor = sparse_tensor_lib.convert_to_tensor_or_sparse_tensor(
raw_feature)
def expand_dims(input_tensor):
# Input_tensor must have rank 1.
if isinstance(input_tensor, sparse_tensor_lib.SparseTensor):
return sparse_ops.sparse_reshape(
input_tensor, [array_ops.shape(input_tensor)[0], 1])
else:
return array_ops.expand_dims(input_tensor, -1)
rank = feature_tensor.get_shape().ndims
if rank is not None:
if rank == 0:
raise ValueError(
'Feature (key: {}) cannot have rank 0. Given: {}'.format(
key, feature_tensor))
return feature_tensor if rank != 1 else expand_dims(feature_tensor) # 当样本没有batch的时候,添加一个维度
# Handle dynamic rank.
with ops.control_dependencies([
check_ops.assert_positive(
array_ops.rank(feature_tensor),
message='Feature (key: {}) cannot have rank 0. Given: {}'.format(
key, feature_tensor))]):
return control_flow_ops.cond(
math_ops.equal(1, array_ops.rank(feature_tensor)),
lambda: expand_dims(feature_tensor),
lambda: feature_tensor)
get 中包含了和transform_feature的递归调用,最终把tensor赋给_feature_tensor
def get(self, key, state_manager):
"""Returns a `Tensor` for the given key.
A `str` key is used to access a base feature (not-transformed). When a
`FeatureColumn` is passed, the transformed feature is returned if it
already exists, otherwise the given `FeatureColumn` is asked to provide its
transformed output, which is then cached.
Args:
key: a `str` or a `FeatureColumn`.
state_manager: A StateManager object that holds the FeatureColumn state.
Returns:
The transformed `Tensor` corresponding to the `key`.
Raises:
ValueError: if key is not found or a transformed `Tensor` cannot be
computed.
"""
if key in self._feature_tensors:
# FeatureColumn is already transformed or converted.
return self._feature_tensors[key]
if key in self._features:
feature_tensor = self._get_raw_feature_as_tensor(key)
self._feature_tensors[key] = feature_tensor
return feature_tensor
if isinstance(key, six.string_types):
raise ValueError('Feature {} is not in features dictionary.'.format(key))
if not isinstance(key, FeatureColumn):
raise TypeError('"key" must be either a "str" or "FeatureColumn". '
'Provided: {}'.format(key))
column = key
logging.debug('Transforming feature_column %s.', column)
transformed = column.transform_feature(self, state_manager) # 递归调用,最后在开始的两个if的地方跳出
if transformed is None:
raise ValueError('Column {} is not supported.'.format(column.name))
self._feature_tensors[column] = transformed
return transformed