【目标检测】Flask+Docker在服务器部署YOLOv5应用
前言
看到不少文章讲解用Flask部署YOLOv5的,不过基本都在本地上能够运行而戛然而止。因此,我打算再进一步,利用Docker在云服务器上部署YOLOv5,这样就能够开放给别人使用。
代码仓库:https://github.com/zstar1003/yolov5-flask
本地部署
本地项目主要参考了robmarkcole的这个项目[1],原始项目是一年前多发布的大概用的是YOLOv5较早的版本,直接download下来会出现一些问题。于是我使用YOLOv5-5.0版本进行了重构。
项目结构
整体项目结构如下图所示:

- models:存放模型构建相关程序,直接从yolov5-5.0版本中clone过来
- utils:存放绘图、数据加载等相关工具,直接从yolov5-5.0版本中clone过来
- static:存放前端渲染等静态文件
- templates:前端页面html文件
- webapp.py:入口程序
整体看来,整个项目作为一个demo还是比较简单的。当然utils和models里面存在一定的冗余,有的工具类是为训练测试提供服务,这里仅需要做推理即可。本来想着再进一步精简,不过发现各函数之间相关性挺大,遂不去修改。
快速运行
仓库里已经存放了yolov5s.pt文件,无需额外下载模型文件。
在终端运行python webapp.py,稍等片刻,即可访问 http://127.0.0.1:5000
在首页中选择文件再上传,即可返回出模型预测结果。预测后的图片会保存在static文件夹下。
代码简析
核心代码:
@app.route("/", methods=["GET", "POST"])
def predict():
if request.method == "POST":
if "file" not in request.files:
return redirect(request.url)
file = request.files["file"]
if not file:
return
img_bytes = file.read()
img = Image.open(io.BytesIO(img_bytes))
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
if img is not None:
showimg = img
with torch.no_grad():
img = letterbox(img, new_shape=imgsz)[0]
# Convert
# BGR to RGB, to 3x416x416
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half() if model.half() else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
pred = model(img)[0]
# Apply NMS
pred = non_max_suppression(pred, conf_thres, iou_thres)
# Process detections
for i, det in enumerate(pred): # detections per image
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], showimg.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
label = '%s %.2f' % (names[int(cls)], conf)
plot_one_box(
xyxy, showimg, label=label, color=colors[int(cls)], line_thickness=2)
imgFile = "static/img.jpg"
cv2.imwrite(imgFile, showimg)
return redirect(imgFile)
return render_template("index.html")
前端通过POST的方式,将图片提交到后端,首先需要判断图片是否为空,如果为空,则返回空值,即报错界面;如果不是空值,则通过file.read()来读取图片字节串,原代码是通过PIL.Image来转成图片,为了和后面的推理过程兼容,转换成OpenCV格式。
推理部分代码基本完全copy自YOLOv5的detect.py,推理之后的图片首先进行保存,然后再返回给前端进行直接显示。
云端部署
在服务器部署也有多种方案,最容易想到的就是直接在服务器搭建python环境,不过考虑到还需要安装torch这种大型库,出错概率高,因此更方便的就是使用Docker进行部署。
简单理解,Docker就像是一个自带了虚拟环境和程序的容器,只需要将其打包放在服务器,直接就可以运行。
生成requirements.txt
第一步是需要生成依赖文件列表requirements.txt,以便在Docker Image中能够配置好需要的依赖。
通常的做法是这样进行生成:
pip freeze > requirements.txt
然后就可以在新环境中,这样快速安装:
pip install -r requirements.txt
但是这样做的一个巨大问题是,它会将环境中所有的库名称和版本进行输出,有些库是在项目中没有用到的,但依然会进行输出。
为了避免这种情况,有人就开发了一个pipreqs库,它可以进行一些过滤,仅将工程中用到的库和版本进行输出。
pipreqs的安装可以有两种方式:
方式一:
pip install pipreqs
方式二:
如果pip失败,可以去Github上克隆该项目,然后运行setup.py
git clone https://github.com/bndr/pipreqs.git
python setup.py install
安装好之后,再在当前目录下运行
pipreqs . --encoding=utf8 --force
这样就能生成requirement.txt
coremltools==5.2.0
Flask==2.2.2
matplotlib==3.5.2
numpy==1.21.5
onnx==1.12.0
pafy==0.5.5
pandas==1.3.5
Pillow==9.2.0
PyYAML==6.0
requests==2.28.1
scipy==1.7.3
seaborn==0.11.2
setuptools==63.2.0
torch==1.11.0
torchvision==0.12.0
tqdm==4.64.0
opencv-python==4.6.0.66
注意生成之后需要检查一下,比如云服务器不具有GPU环境,那么就手动将torch改成CPU版本。
构建DockerFile
DockerFile是构建文件,包含了所有环境配置步骤,比如安装库。
常用指令有这些[2]:
FROM # 基础镜像,一切从这里开始构建 centos
MAINTAINER # 镜像是谁写的, 姓名+邮箱
RUN # 镜像构建的时候需要运行的命令
ADD # 步骤,tomcat镜像,这个tomcat压缩包!添加内容 添加同目录
WORKDIR # 镜像的工作目录
VOLUME # 挂载的目录
EXPOSE # 暴露端口配置 和我们的-p一样的
CMD # 指定这个容器启动的时候要运行的命令,只有最后一个会生效,可被替代。
ENTRYPOINT # 指定这个容器启动的时候要运行的命令,可以追加命令
ONBUILD # 当构建一个被继承 DockerFile 这个时候就会运行ONBUILD的指令,触发指令。
COPY # 类似ADD,将我们文件拷贝到镜像中
ENV # 构建的时候设置环境变量
构建的DockerFile内容如下:
FROM python:3.7-slim-buster
RUN apt-get update
RUN apt-get install ffmpeg libsm6 libxext6 -y
WORKDIR /app
ADD . /app
RUN pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
EXPOSE 5000
CMD ["python", "webapp.py"]
首先,从python:3.7-slim-buster这个公开镜像中,引入python环境,然后更新数据源,安装三个必要的工具。
之后,指定工作路径在/app这个文件夹下,这个路径设置很重要,后面会用到。
然后就安装requirements.txt里面所列的所有依赖,注意这里使用了阿里源,这样可以进行加速。
接着暴露出5000这个端口,因为后面要通过这个端口号进行访问。
最后CMD指定容器运行之后就执行的命令,即容器一旦运行就执行python webapp.py,将程序跑起来。
Docker打包上传
在注册之前,需要在本地安装Docker并进行注册,Windows系统可以安装Docekr的客户端,这里不做赘述。
打开客户端之后,就能在本地启动Docker服务,然后进入到项目终端,输入
docker build --tag zstar1003/yolov5-flask .
注意最后面有个点,这代表着将所有内容打包成镜像。--tag指定了镜像名称,注意前面必须是用户名,否则后面将不能够进行拉取。如果前面tag忘记添加用户名,可以在打包之后进行更名,使用docker tag 原始名 zstar1003/yolov5-flask
关于Docker的命名规则,可以看这篇文章[3],讲解得较为详细。
打包过程比较漫长,因为系统需要去联网下载前面那些依赖,打包完成之后,在终端输入docker images可以看到本地的所有镜像。

本地有了镜像之后,再将其push到公开仓库,这样方便后续拉取,执行命令:
docker push zstar1003/yolov5-flask
上传的过程也比较长,主要取决于镜像的大小和网速,上传完之后,可以在客户端的这个位置看到。

Docker镜像拉取
下面就是在云服务器上进行操作了,推荐使用FinalShell连接云服务器。
首先需要在云服务器上安装Docker,我是用的云服务器系统是Centos 7.6。
先装一些必要的软件包
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
设置稳定的仓库
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
安装社区版的Docker
sudo yum install docker-ce docker-ce-cli containerd.io
安装好之后,启动Docker
systemctl start docker
然后就可以拉取之前上传的镜像
docker pull zstar1003/yolov5-flask
拉取好之后,输入docker image -a看看镜像是否存在,存在就说明拉取成功。
Docker创建容器并启动
拉取完镜像之后,就需要创建一个容器来挂载镜像,主要命令是docker run,有下列这些可选参数,更多命令可参考[4]
docker run [Options] image
#参数说明
--name="名字" 指定容器名字
-d 后台方式运行
-it 使用交互方式运行,进入容器查看内容
-p 指定容器的端口
-p ip:主机端口:容器端口 配置主机端口映射到容器端口
-p 主机端口:容器端口(常用)
-p 容器端口
-P 随机指定端口
-e 环境设置
-v 容器数据卷挂载
于是输入docker run -p 5000:5000 zstar1003/yolov5-flask来创建一个容器来运行这个镜像,结果报错,原因是5000端口被占用。这是因为我这台服务器上之前跑过别的项目,5000端口有其它的进程在工作。
遇到这情况,可以用lsof来查询冲突的端口存在哪个进程。
首先安装lsof
yum -y install lsof
然后输入
lsof -i :5000
如下图所示,可以看到5000端口被gunicorn这个进程正在使用,于是将其kill掉。

杀完之后,再重启容器,首先输入docker ps -a,查看刚刚创建的容器ID

可以看到它的ID是34960ff95951,然后将其启动
docker start 34960ff95951
启动之后,看到终端输入下列内容,表示程序正常运行。

这时候访问服务器公网IP:5000端口,可以看到前端界面已经显示出来。

错误排除
然而,当我上传图片,点击按钮时,突然报错:
RuntimeError: “slow_conv2d_cpu” not implemented for ‘Half’
我在Github的issue[5]中找到了这个问题的答案,原回答如下:
Q: Error “slow_conv2d_cpu” not implemented for ‘Half’
A: In order to save GPU memory consumption and speed up inference, Real-ESRGAN uses half precision (fp16) during inference by default. However, some operators for half inference are not implemented in CPU mode. You need to add --fp32 option for the commands. For example, python inference_realesrgan.py -n RealESRGAN_x4plus.pth -i inputs --fp32
翻译一下,就是本机上为了加速推理,使用了model.half()半精度(fp16)进行转换,然后,这只能在GPU版本的Pytorch中使用,在CPU版本的Pytorch中会报错。
于是,就得想办法把docker中的文件进行修改,将half的操作进行移除。
还记得之前DockerFile中指定的路径吗?在之前,指定了Docker工作路径在app文件夹下,因此,可以使用下面的命令,将其拷贝出来。
docker cp 34960ff95951:/app/webapp.py /home/torch/
如下图所示,在两个half()的地方进行修改,图片直接使用float()类型。

修改之后,再把文件拷贝回去,这样会覆盖原文件,达到修改的目的。
docker cp /home/torch/webapp.py 34960ff95951:/app/
修改好之后,重启容器:
docker restart 34960ff95951
然而在此运行时,我又遇到了下面这个报错
AttributeError: ‘Upsample’ object has no attribute ‘recompute_scale_factor’
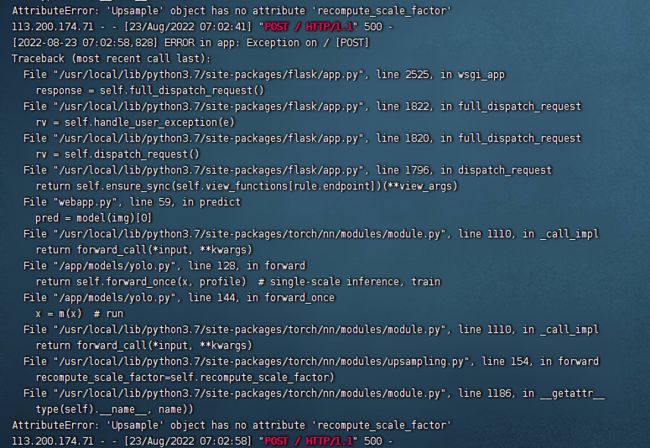
查阅相关资料,这个时pytorch版本的一个Bug,upsampling.py文件中,存在了recompute_scale_factor参数冗余。
和上面操作类似,把该文件拷贝出来,进行修改,再拷贝回去即可。注意该文件属于依赖文件,拷贝出来需要先修改文件的读写权限。
运行效果
排除完这两个错误之后,再次重启容器,上传图片,可以看到推理结果已经正确得呈现出来!
总结
本次利用Docker部署遇到许多阻碍。下次部署时,如果服务器是CPU环境,最好先在本地利用CPU运行一下,如果跑通再进行镜像打包。
References
[1]https://github.com/robmarkcole/yolov5-flask
[2]https://liuhuanhuan.blog.csdn.net/article/details/123256877
[3]https://www.zsythink.net/archives/4302
[4]https://blog.csdn.net/weixin_45698637/article/details/124213429
[5]https://github.com/xinntao/Real-ESRGAN/blob/master/docs/FAQ.md