天池零基础入门NLP竞赛实战:Task4 基于深度学习的文本分类1-FastText
Task4 基于深度学习的文本分类1-FastText
与传统机器学习不同,深度学习既提供特征提取功能,也可以完成分类的功能。
学习目标
- 学习FastText的使用和基础原理
- 学会使用验证集进行调参
文本表示方法 Part2-1
现有文本表示方法的缺陷
之前介绍的几种文本表示方法(One-hot、Bag of Words、N-gram、TF-IDF)都或多或少存在一定的问题:转换得到的向量维度很高,需要较长的训练实践;没有考虑单词与单词之间的关系,只是进行了统计。
与这些表示方法不同,深度学习也可以用于文本表示,还可以将其映射到一个低纬空间。其中比较典型的例子有:FastText、Word2Vec和Bert。
FastText
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络,输入层、隐含层和输出层。

下图是使用keras实现的FastText网络结构:
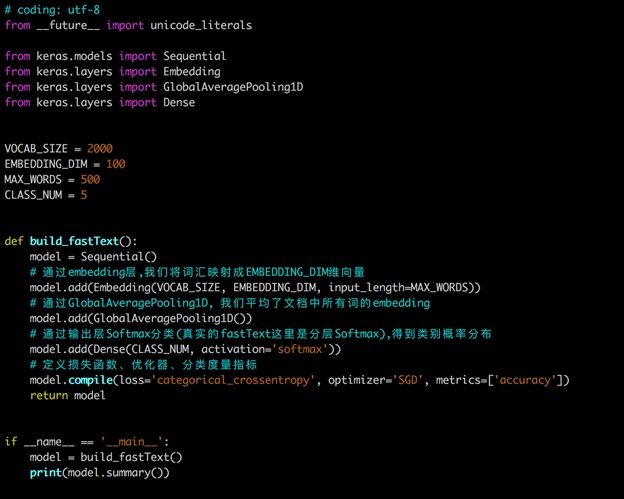
FastText在文本分类任务上,是优于TF-IDF的:
- FastText用单词的Embedding叠加获得的文档向量,将相似的句子分为一类
- FastText学习到的Embedding空间维度比较低,可以快速进行训练
参考论文:Bag of Tricks for Efficient Text Classification
基于FastText的文本分类
安装FastText
FastText可以快速的在CPU上进行训练,最好的实践方法就是官方开源的版本: https://github.com/facebookresearch/fastText/tree/master/python
这里建议在这个网站直接下载fasttext的库,然后进入下载路径,用下面的语句直接安装:
cd 文件所在路径
pip install fasttext-0.9.2-cp38-cp38-win_amd64.whl
数据加载、预处理和划分
这里的操作和之前一致,不再赘述。
#数据加载、预处理
import pandas as pd
import joblib
data_file = 'train_set.csv'
rawdata = pd.read_csv(data_file, sep='\t', encoding='UTF-8')
#用正则表达式按标点替换文本
import re
rawdata['words']=rawdata['text'].apply(lambda x: re.sub('3750|900|648',"",x))
del rawdata['text']
#数据划分
from sklearn.model_selection import train_test_split
import joblib
rawdata.reset_index(inplace=True,drop=True)
test_data=joblib.load('test_index.pkl')
train_data=joblib.load('train_index.pkl')
X=list(rawdata.index)
y=rawdata['label']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.1,stratify=y) #stratify=y表示分层抽样,根据不同类别的样本占比进行抽样
test_data={'X_test':X_test,'y_test':y_test}
joblib.dump(test_data,'test_index.pkl')
train_data={'X_train':X_train,'y_train':y_train}
joblib.dump(train_data,'train_index.pkl')
train_x=rawdata.loc[train_data['X_train']]
train_y=rawdata.loc[train_data['X_train']]['label'].values
test_x=rawdata.loc[test_data['X_test']]
test_y=rawdata.loc[test_data['X_test']]['label'].values
# test 读取测试集数据
test_data_file = 'test_a.csv'
f = pd.read_csv(test_data_file, sep='\t', encoding='UTF-8')
test_data = f['text'].apply(lambda x: re.sub('3750|900|648',"",x))
FastText训练和预测
import pandas as pd
from sklearn.metrics import f1_score
# 转换为FastText需要的格式
train_x['label_ft'] = '__label__' + train_x['label'].astype(str)
train_x[['words','label_ft']].to_csv('fasttext_need_train.csv', index=None, header=None, sep='\t')
import fasttext
model = fasttext.train_supervised('fasttext_need_train.csv', lr=1.0, wordNgrams=2, verbose=2, minCount=1, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in test_x['words']]
print(f1_score(test_y.astype(str), val_pred, average='macro'))
#验证集得分:0.9198590651705543
FastText+交叉验证+网格搜索参数
这里主要参考了博文FastText调参:GridSearch+CV
# 将各个参数的取值进行排列组合
def get_gridsearch_params(param_grid):
params_combination = [dict()] # 用于存放所有可能的参数组合
for k, v_list in param_grid.items():
tmp = [{k: v} for v in v_list]
n = len(params_combination)
# params_combination = params_combination*len(tmp) # 浅拷贝,有问题
copy_params = [copy.deepcopy(params_combination) for _ in range(len(tmp))]
params_combination = sum(copy_params, [])
_ = [params_combination[i*n+k].update(tmp[i]) for k in range(n) for i in range(len(tmp))]
return params_combination
# 使用k折交叉验证,得到最后的score,保存最佳score以及其对应的那组参数
# 输入分别是训练数据帧,要搜索的参数,用于交叉验证的KFold对象,最佳score评价指标,几分类
def get_KFold_scores(df, params, kf, metric, n_classes):
metric_score = 0.0
for train_idx, val_idx in kf.split(df['words'],df['label']):
df_train = df.iloc[train_idx]
df_val = df.iloc[val_idx]
tmpdir = tempfile.mkdtemp() #因为fasttext的训练时读入一个训练数据所在的目录或文件,所以这里用交叉验证集开一个临时目录/文件
tmp_train_file = tmpdir + '/train.txt'
df_train.to_csv(tmp_train_file, sep='\t', index=False, header=None, encoding='UTF-8') # 不要表头
fast_model = fasttext.train_supervised(tmp_train_file, label_prefix='__label__', thread=3, **params) #训练,传入参数
#用训练好的模型做评估预测
predicted = fast_model.predict(df_val['words'].tolist()) # ([label...], [probs...])
y_val_pred = [int(label[0][-1:]) for label in predicted[0]] # label[0] __label__0
y_val = df_val['label'].values
score = get_metrics(y_val, y_val_pred, n_classes)[metric]
metric_score += score #累计在不同的训练集上的score,用于计算在整个交叉验证集上平均分
shutil.rmtree(tmpdir, ignore_errors=True) #删除临时训练数据文件
print('平均分:', metric_score / kf.n_splits)
return metric_score / kf.n_splits
# 网格搜索+交叉验证
# 输入分别是训练数据帧,要搜索的参数,最佳score评价指标,交叉验证要做几折
def my_gridsearch_cv(df, param_grid, metrics, kfold=10):
n_classes = len(np.unique(df['label']))
print('n_classes', n_classes)
#kf = KFold(n_splits=kfold) # k折交叉验证
skf = StratifiedKFold(n_splits=kfold,shuffle=True,random_state=1) #k折分层采样交叉验证
params_combination = get_gridsearch_params(param_grid) # 获取参数的各种排列组合
best_score = 0.0
best_params = dict()
for params in params_combination:
avg_score = get_KFold_scores(df, params, skf, metrics, n_classes)
if avg_score > best_score:
best_score = avg_score
best_params = copy.deepcopy(params)
return best_score, best_params
import fasttext
from sklearn.model_selection import KFold, StratifiedKFold
import numpy as np
import pandas as pd
import copy
import tempfile
import shutil
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
#计算分类评价指标
def get_metrics(y_true, y_pred, n_classes):
metrics = {}
if n_classes==2:
#二分类
metrics['precision'] = precision_score(y_true, y_pred, pos_label=1)
metrics['recall'] = recall_score(y_true, y_pred, pos_label=1)
metrics['f1'] = f1_score(y_true, y_pred, pos_label=1)
else:#多分类
average = 'macro'
metrics[average+'_precision'] = precision_score(y_true, y_pred, average=average)
metrics[average+'_recall'] = recall_score(y_true, y_pred, average=average)
metrics[average+'_f1'] = f1_score(y_true, y_pred, average=average)
metrics['accuracy'] = accuracy_score(y_true, y_pred)
metrics['confusion_matrix'] = confusion_matrix(y_true, y_pred)
metrics['classification_report'] = classification_report(y_true, y_pred)
return metrics
#DATA_PATH = '../data/'
# 要调试的参数
tuned_parameters = {
'lr': [1.0, 0.85, 0.5],
'epoch': [30,50],
'dim': [ 200],
'wordNgrams': [2, 3],
}
# 这里引入上述3个方法
if __name__ == '__main__':
#filepath = DATA_PATH + 'fast/augmented/js_pd_tagged_train.txt'
#df = pd.read_csv(filepath, encoding='UTF-8', sep='\t', header=None, index_col=False, usecols=[0, 1])
print(train_x.head())
print(train_x.shape)
best_score, best_params = my_gridsearch_cv(train_x, tuned_parameters, 'accuracy', kfold=10)
print('best_score', best_score)
print('best_params', best_params)
参考资料
Datawhale零基础入门NLP赛事 - Task4 基于深度学习的文本分类1-fastText
FastText调参:GridSearch+CV