使用MindStudio进行MindX SDK财务票据OCR识别开发
一、任务介绍
1.1任务描述
在本系统中,目的是基于MindX SDK,在昇腾平台上,开发端到端财务票据OCR识别的参考设计,实现对财务票据中的文本信息进行OCR识别的功能,达到功能要求。
视频演示过程:【使用MindStudio进行MindX SDK 财务票据OCR 开发】
https://www.bilibili.com/video/BV1644y1m7Qe/?share_source=copy_web&vd_source=2a40c54eb5f208ef5b1c3cb38321c412
1.2 任务目标
样例输入:财务票据jpg图片
样例输出:框出主要文本信息并标记文本内容以及票据类型的jpg图片
1.3 环境信息
开发环境:Windows 10 + MindStudio 5.0.RC2
昇腾芯片:Ascend 310
服务器环境依赖软件和版本如下表:

二、模型介绍
本文开发选用了ResNet-50模型实现财务数据分类,通过DB模型实现端到端文本框识别、采用CRNN模型进行抠图以及框内文本内容识别。
财务数据识别流程图如下图所示: 
票据识别的SDK流程图如下图所示: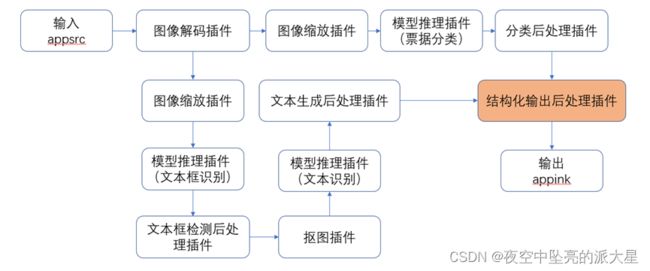
2.1 票据分类
本文开发选用了ResNet-50模型对图片进行分类。ResNet-50模型相关文件可在此处下载:
https://www.hiascend.com/zh/software/modelzoo/models/detail/C/ea8c34895d1b4697b3f1e940da1e97d2
ResNet是ImageNet竞赛中分类问题效果比较好的网络,它引入了残差学习的概念,通过增加直连通道来保护信息的完整性,解决信息丢失、梯度消失、梯度爆炸等问题,让很深的网络也得以训练。ResNet有不同的网络层数,常用的有18-layer、34-layer、50-layer、101-layer、152-layer。支持的特性包括:1、分布式并行训练;2、混合精度训练。
2.2 文本框识别
本文开发选用db模型对图片进行文本框识别。
论文连接:https://arxiv.org/pdf/1911.08947.pdf
模型相关文件链接:
https://www.hiascend.com/zh/software/modelzoo/models/detail/1/d14c7c1950824ba6a26bf9c7e3adf606
DBNet是基于分割的文本检测算法,算法将可微分二值化模块引入了分割模型,使得分割模型能够通过自适应的阈值进行二值化。经过验证,该方案不仅简化了后处理过程而且提升了文本检测的效果。相较于其他文本检测模型,DBNet在效果和性能上都有比较大的优势,是当前常用的文本检测算法。
DB文本检测模型可以分为三个部分:Backbone网络,负责提取图像的特征;
FPN网络,特征金子塔结构增强特征;Head网络,计算文本区域概率图。其模型结构如下图所示: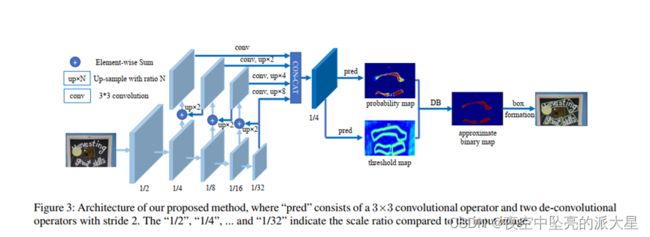
2.3 文本内容识别
本文使用CRNN模型对文本内容进行识别。CRNN模型相关文件可在此处下载:
https://www.hiascend.com/zh/software/modelzoo/models/detail/C/c4945b2fc8aa47f6af9b4f2870e41062
CRNN是一种基于图像序列识别的神经网络及其在场景文本识别中的应用,本文研究了场景文本识别问题,这是基于图像序列识别中最重要和最具挑战性的任务之一。提出了一种新的神经网络体系结构,将特征提取、序列建模和转录集成到一个统一的框架中。与以前的场景文本识别系统相比,所提出的体系结构具有四个独特的特性:
a) 它是端到端可训练的,与大多数现有算法相比,这些算法的组件是单独训练和调整的。
b) 它自然地处理任意长度的序列,不涉及字符分割或水平尺度归一化。
c) 它不局限于任何预定义的词典,在无词典和基于词典的场景文本识别任务中都取得了显著的性能。
d) 它生成了一个有效但小得多的模型,这对于现实世界的应用场景更实用。
三、MindStuido介绍与安装
MindStudio的具体安装步骤以及详细功能介绍可参考用户手册。
3.1 MindStudio简介
可提供再AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能。
MindStudio可以单独安装在Windows上。在安装MindStudio前需要在Linux服务器上安装部署好Ascend-cann-toolkit开发套件包,之后在Windows上安装MindStudio,安装完成后通过配置远程连接的方式建立MindStudio所在的Windows服务器与Ascend-cann-toolkit开发套件包所在的Linux服务器的连接,实现全流程开发功。本文开发采用的就是将MindStudio安装在Windows服务器上时,Windows服务器为本地环境,Linux服务器为远端环境。
3.2 MindStudio安装
步骤1 : 通过MindStudio下载链接,下载Windows系统的安装包,下载完成后点击下载的安装包安装MindStudio。双击下载好的软件安装包进行安装。
步骤2:双击安装包,进入安装界面,单击“Next”。
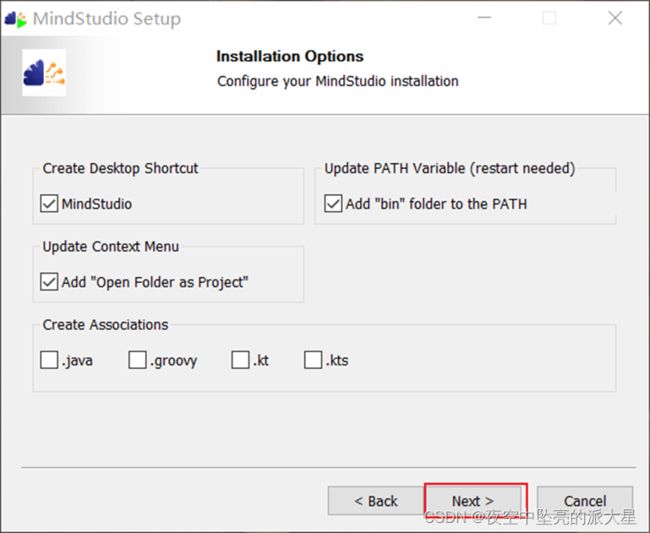
步骤3:在下图安装界面,用户根据需要勾选安装选项后,单击“Next”。
其中
a) Create Desktop Shortcut:勾选“MindStudio”,创建桌面快捷方式。
b) Update PATH Variable(restart needed):将MindStudio的启动文件路径加入环境变量PATH中,可从系统命令行直接启动MindStudio。如果勾选此项,MindStudio安装配置完成后会重启操作系统。
c) Update Context Menu:勾选“Add “Open Folder as Project””后,右键单击文件夹,可以作为MindStudio工程打开。
d) Create Associations:默认不勾选。
步骤4:选择MindStudio默认安装路径下的启动菜单文件夹,单击“Install”在这里插入图片描述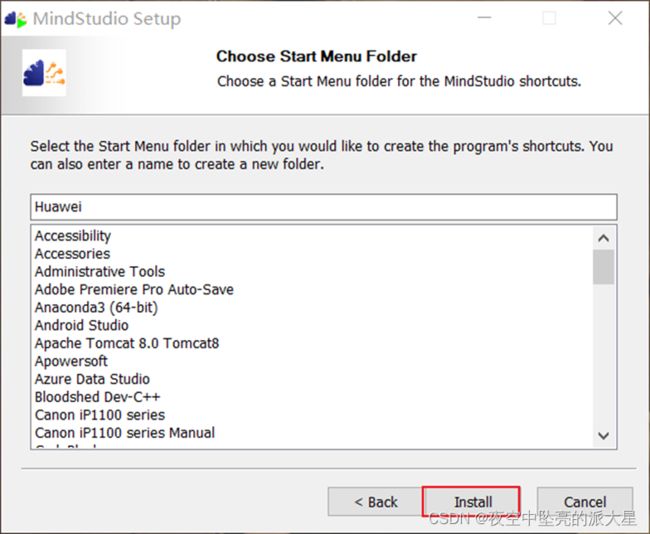
步骤5:开始安装MindStudio,完成后单击“Next”。
步骤6:完成MindStudio安装配置,单击“Finish”。
以上安装完成后,启动MindStudio,进入导入设置界面,这里选择的是Do not import settings不导入设置。选择该选项,则创建新的配置文件,默认为该选项。
以上安装完成后,启动MindStudio,进入导入设置界面,这里选择的是Do not import settings不导入设置。选择该选项,则创建新的配置文件,默认为该选项。
如果没有报错信息且能正常进入欢迎界面,则表示MindStudio安装成功。
3.3 MindStudio环境搭建
进入欢迎界面后,从欢迎界面打开Remote CANN Setting窗口的图文内容:Customize-》All Settings-》Appearance & Behavior-》System Settings-》CANN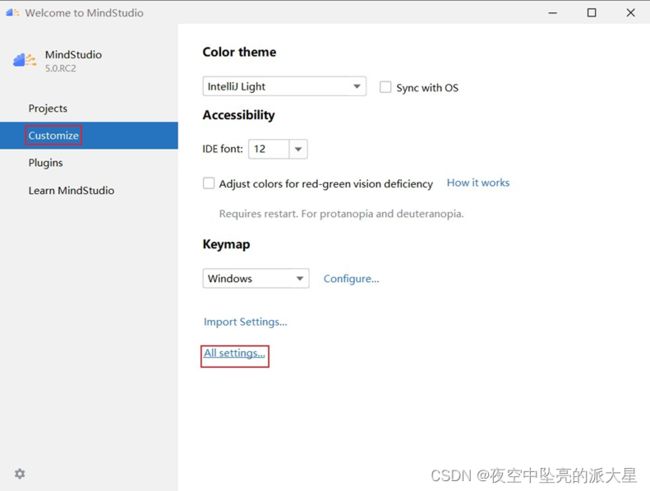
点击Remote Connection后面的添加图标
点击左上角的“➕”,然后填写服务器连接的相关信息,测试成功后点击OK。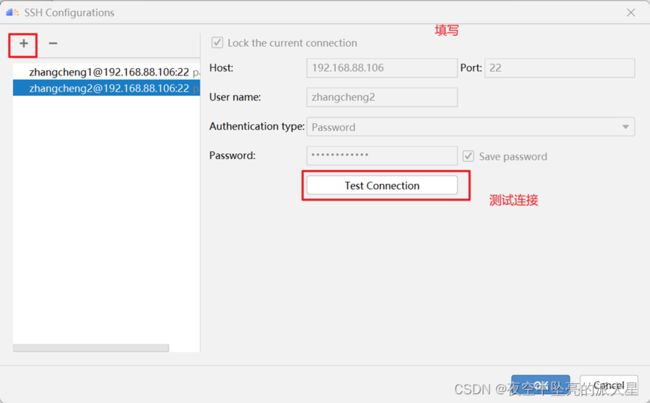
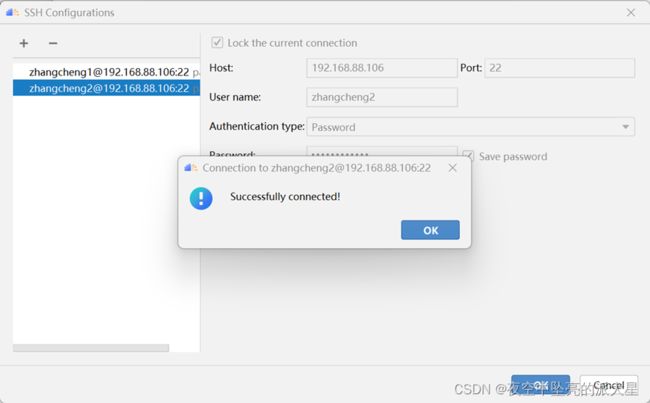
点击Remote CANN location后面的文件图标,打开远端服务器目录树,选择CANN安装路径,点击OK,点击Finish开始同步。
在欢迎界面点击Plugins,在插件市场搜索并安装如下插件工具。
Grep Console
Pylint
Python Community Edition
在欢迎界面依次点击Customize-》All Settings-》Appearance & Behavior-》System Settings-》MindX SDK打开管理界面。点击“Install SDK”,导入远程MindX SDK。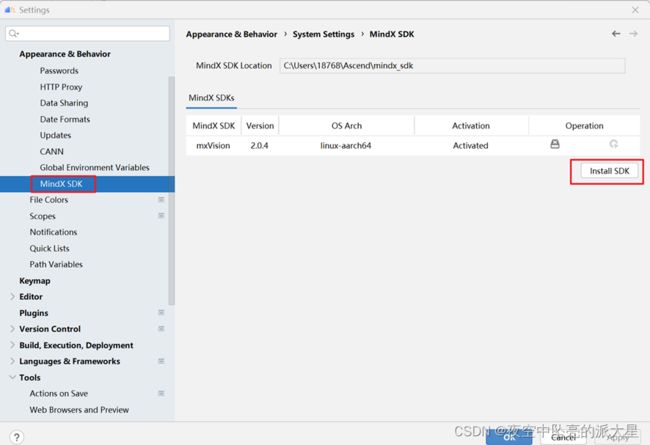
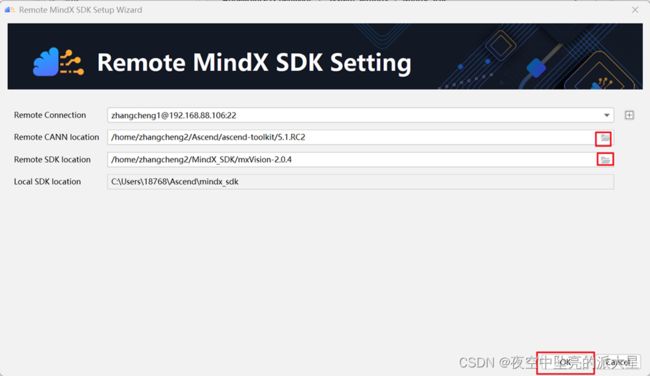

以上步骤全部完成且没有报错信息,表示MindStudio开发环境已成功搭建。
3.4 MindStudio新建工程
在 Projects 标签下点击“New Project”创建一个新的工程。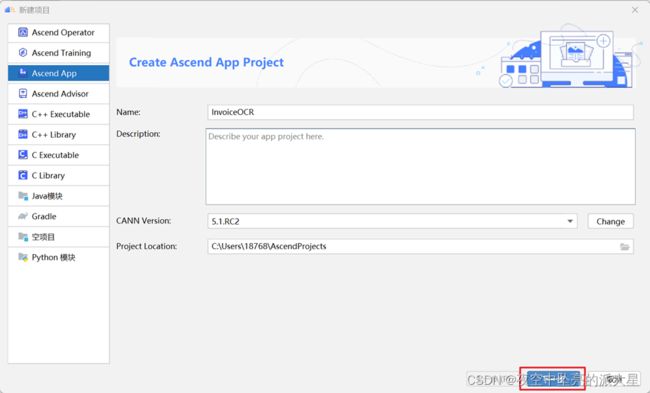
选择 MindX SDK Project (Python),点击“Finish”。
点击File->Project Structure
点击“SDKs”,点击加号,点击“Add Python SDK”
点击Interpreter后的按钮选择python版本(一般系统会自动检索,如果
有多个python版本请手动选择正确的)。填好后点击OK。
点击“Project”,选择创建的 SDK。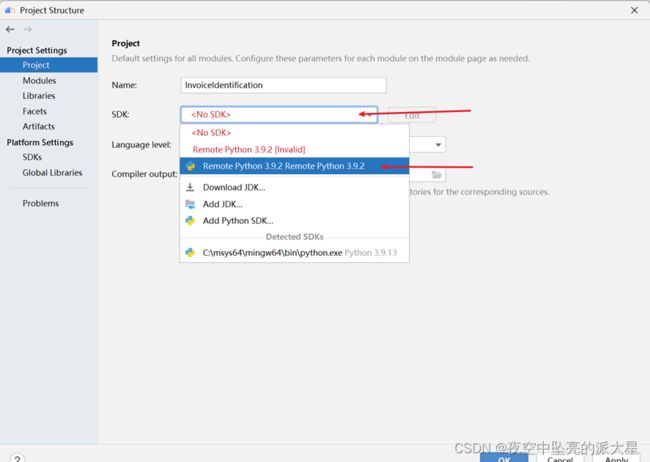
点击 “Modules”->“Dependence”,选择创建的 SDK,点击“OK”。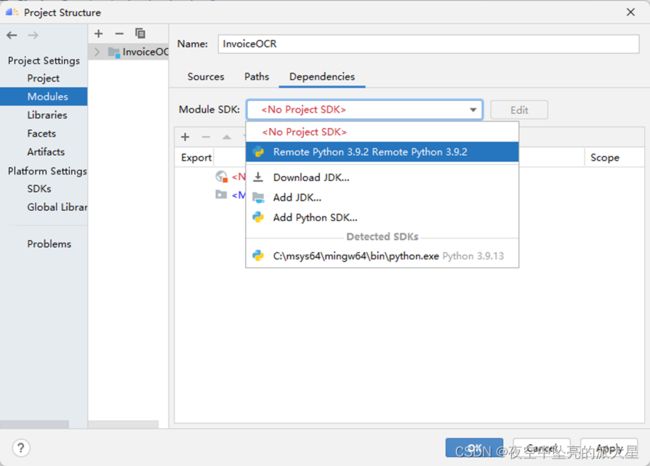
File ->Settings ->Tools ->Deployment,点击Mappings,根据下图操作顺序设置远程映射路径。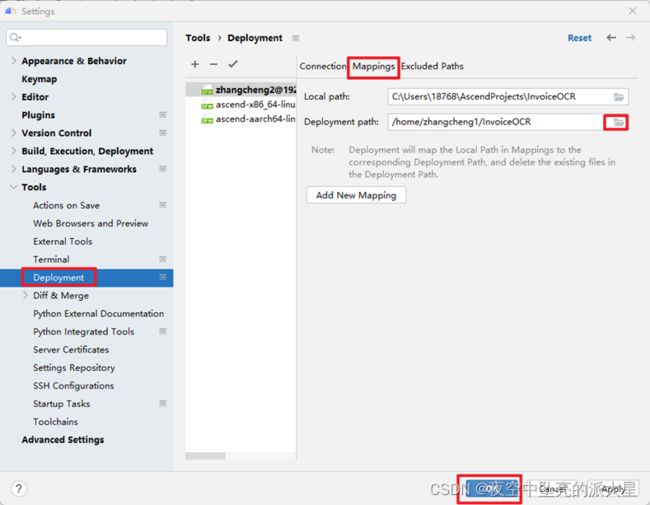
点击“Tools”-> “Deployment”->“Automatic Upload”。
进入远程服务器项目所在目录,两端文件已同步完成在这里插入图片描述
开发完成后完整的工程结构如下所示:
├── lib # 后处理插件库
│ ├── libclipper.so
│ └── libDBPostProcess.so
├── models
│ ├── crnn
│ │ ├── crnn.om
│ │ ├── crnn.onnx
│ │ ├── ppocr_keys_v1.names # 字典
│ │ ├── rec_aipp.cfg # crnn-aipp转换配置文件
│ │ └── rec.cfg # crnn后处理配置
│ ├── db
│ │ ├── db.om
│ │ ├── db.onnx
│ │ ├── det_aipp.cfg
│ │ └── det.cfg # db后处理配置
│ └── resnet50
│ ├── aipp.config
│ ├── invoice.names # 票据类别
│ ├── resnet50.air
│ ├── resnet50.cfg # resnet50配置
│ └── resnet50.om
├── pipeline
│ └── InvoiceOCR.pipeline # pipeline文件
├── inputs # 输入图片
│ └── xxx.jpg
├── outputs # 输出图片
│ └── xxxx.jpg
├── main.py # 推理脚本
├── eval.py # 测试精度脚本
└── set_env.sh # 环境变量设置脚本
四、模型转换
MindStudio模型转换工具的详细使用和参数说明可参考MindStudio用户手册–模型转换。
4.1 Resnet模型转换
可以通过在菜单栏选择“Ascend > Model Converter” 进入模型转换界面。
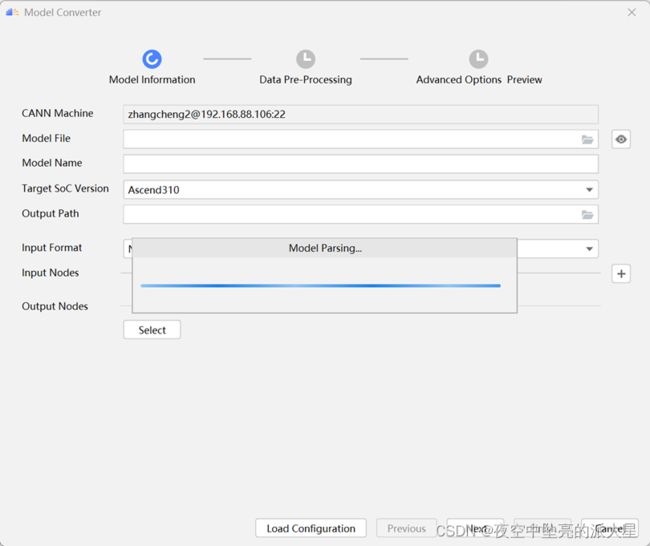
打开模型转换页面,在“Model Information”页签中配置Model File,可以选择远端或本地的模型文件,点击“OK”以后会自动解析模型并自动填充如图相关信息。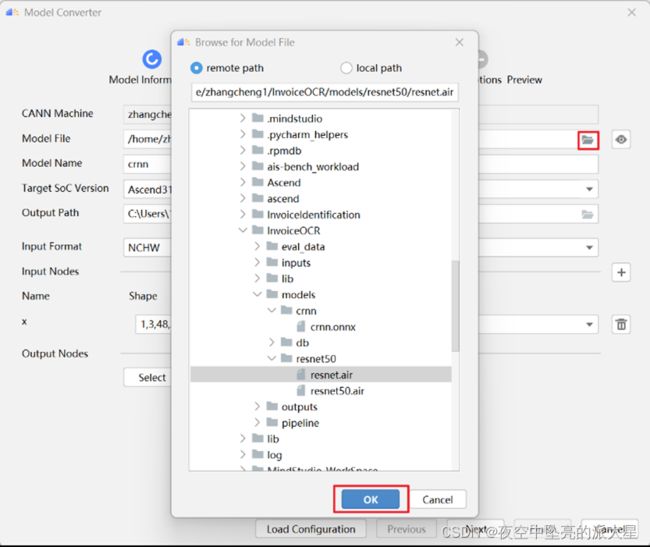
添加input Node, 参数值为“1,3,224,224”,TYPE选择UINT8。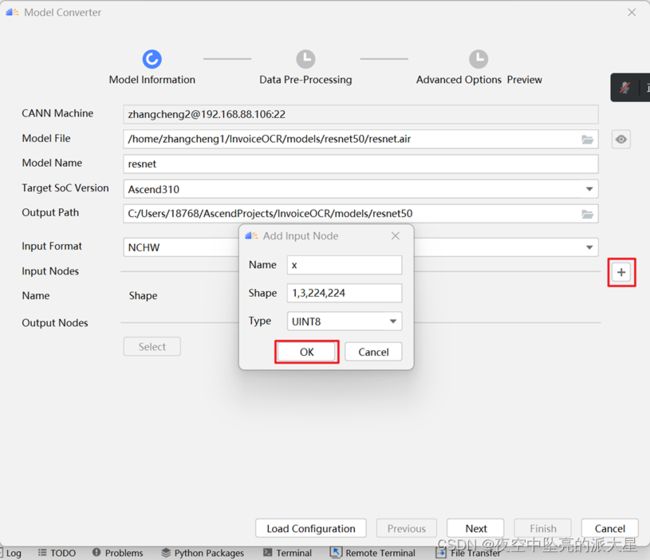
设置模型名称、om 模型生成目录、点击“Next”。
进入“Data Preprocessing”数据预处理的配置页,开启Load Aipp Configuration,选择对应的配置文件。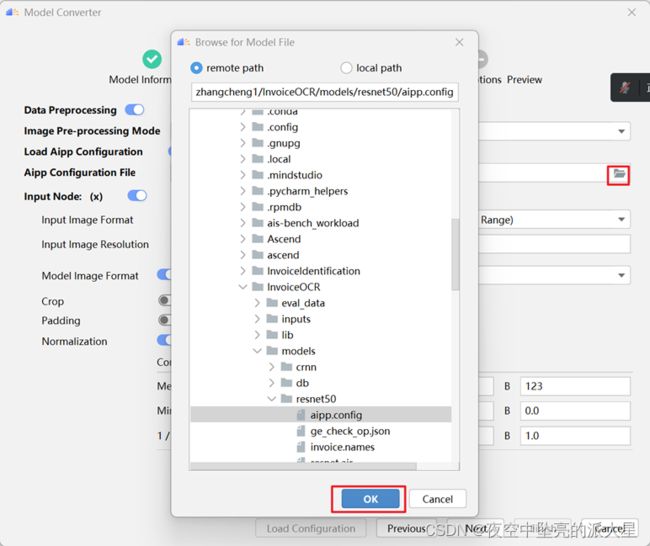
配置文件如下所示:
最终的数据预处理参数如下,点击“Next”。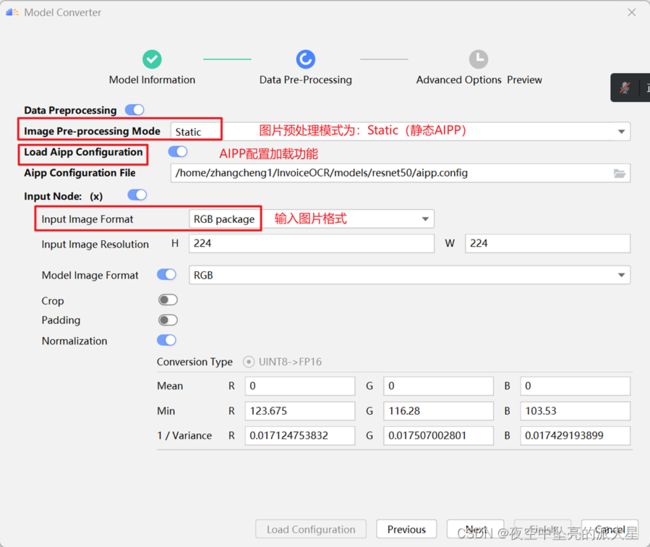
检查生成的atc命令,确认无误后点击“Finish”。
模型转换成功后,如下图所示: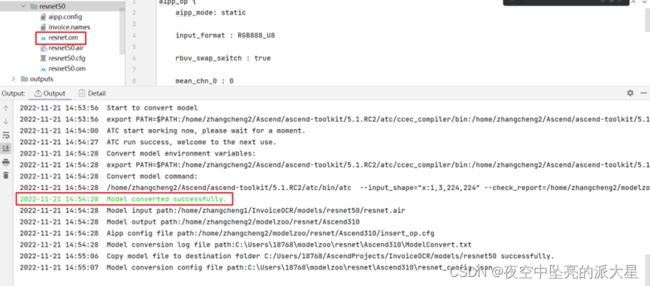
4.2 DB模型转换
可以通过在菜单栏选择“Ascend > Model Converter” 进入模型转换界面。
打开模型转换页面,在“Model Information”页签中配置Model File,可以选择远端或本地的模型文件,点击“OK”以后会自动解析模型并自动填充如图相关信息。
添加input Node, --input_shape=“x:1,3,-1,-1”,TYPE选择FP32。dynamic_image_size=“1216,1280;1280,1216;1120,1280;1280,1120;1024,1280;1280,1024;928,1280;1280,928;832,1280;1280,832;736,1280;1280,736;704,1280;1280,704;672,1280;1280,672;640,1280;1280,640;608,1280;1280,608;576,1280;1280,576;544,1280;1280,544;512,1280;1280,512;480,1280;1280,480;448,1280;1280,448”。点击Next。 

点击“Next”。
进入“Advanced Options Preview”高级选项配置页,在Additional Arguments添加转换参数。Command Preview展示了模型转换使用的atc参数预览数。
配置文件如下所示:
模型转换成功后,如下图所示:
4.3 CRNN模型转换
可以通过在菜单栏选择“Ascend > Model Converter” 进入模型转换界面。
打开模型转换页面,在“Model Information”页签中配置Model File,可
以选择远端或本地的模型文件,点击“OK”以后会自动解析模型并自动填充如图相关信息。
input Node参数值为input_shape=“x:1,3,48,320”,Type选择UINT8。点击“Next”。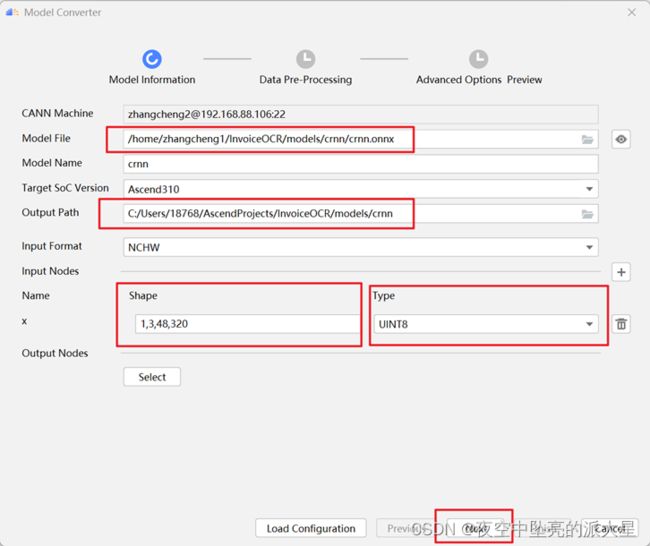
进入“Data Preprocessing”数据预处理的配置页,开启Load Aipp Configuration,选择对应的配置文件。
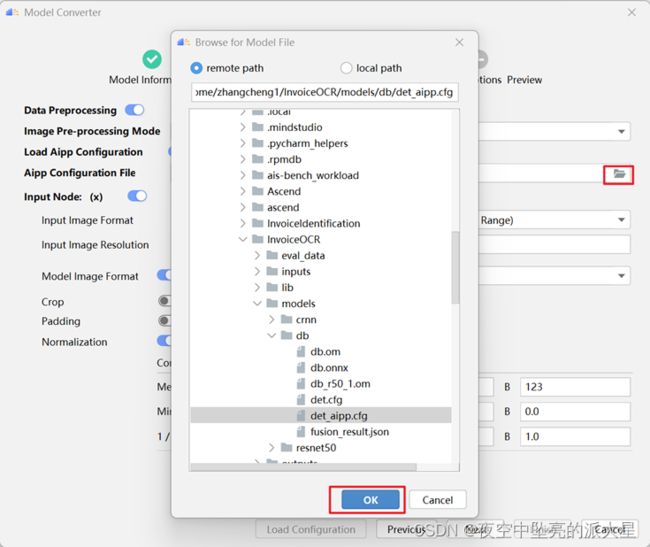
配置文件如下所示:
最终的数据预处理参数如下,点击“Next”。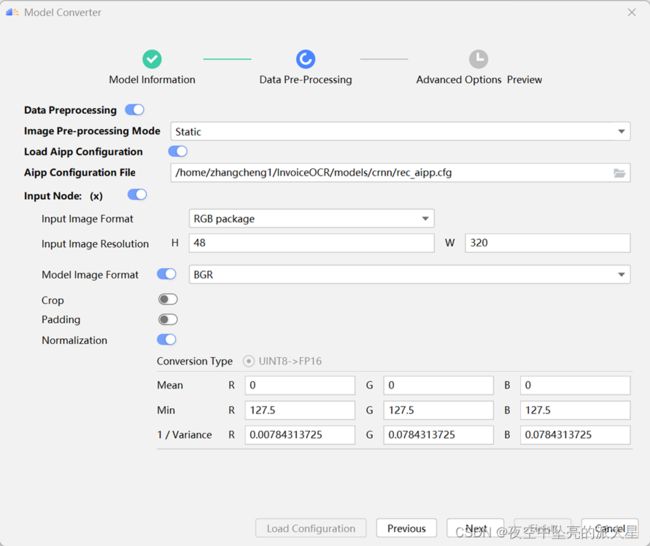
进入“Advanced Options Preview”高级选项配置页, 其中Command
Preview展示了模型转换使用的atc参数预览数。确认无误后点击“Finish”。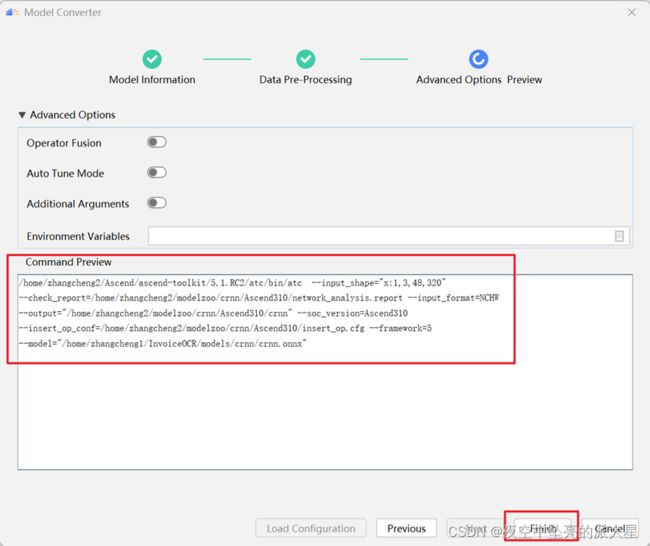
模型转换成功后,如下图所示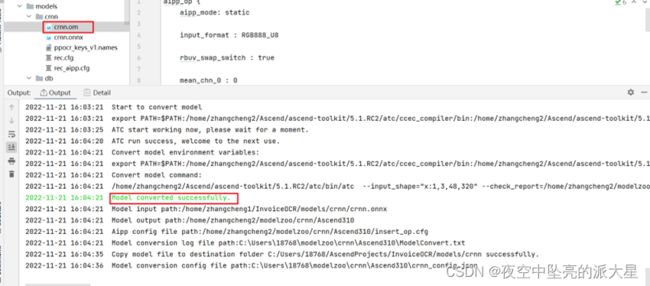
五、项目开发
5.1 pipeline流程编排
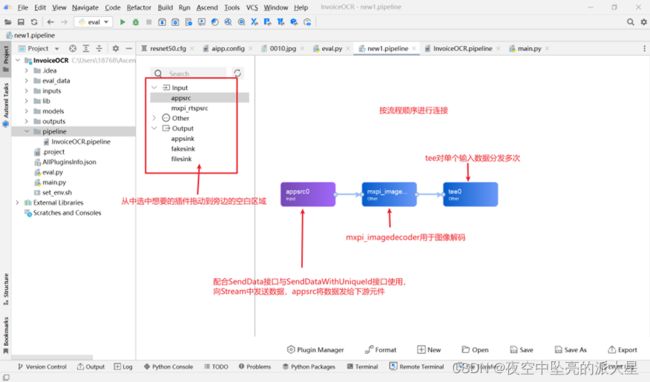
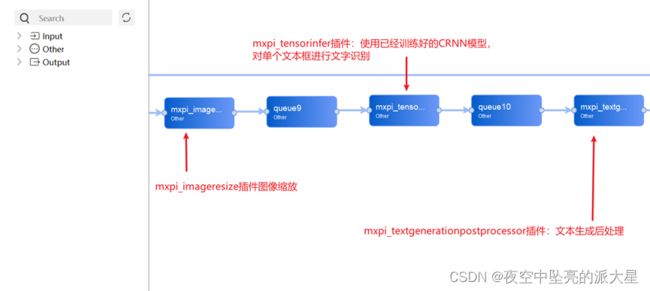
MindX SDK实现功能的最小粒度是插件,每一个插件实现特定的功能,如图片解码、图片缩放等。将这些插件按照合理的顺序编排,实现相应的功能。
这个配置文件叫做pipeline,以JSON格式编写,用户必须指定业务流名称、元件名称和插件名称,并根据需要,补充元件属性和下游元件名称信息。
本文实现所使用的插件和工作流程如下:
(1)输入类型可以是图片数据(jpg图片序列)
(2)调用MindX SDK提供的图像解码接口mxpi_imagedecoder,解码后获取图像数据
(3)进行图像尺寸大小变换,调用MindX SDK提供的图像尺寸大小变换接口mxpi_imageresize插件
(4)首先进行票据类别识别,调用MindX_SDK的mxpi_tensorinfer接口,将尺寸变换后的图像数据输入Resnet训练模型,完成图片所属票据类别的识别
(5)根据所属票据类别,结合DBNet模型方法进行文本框识别,并进行文本框缺失判断
(6)检测后处理,调用MindX SDK提供的模型推理插件mxpi_tensorinfer,然后调用MindX SDK提供的插件mxpi_objectpostprocessor,将结果组装成json字符串传给下一个插件
(7)抠图,调用MindX_SDK的mxpi_imagecrop插件,将各个文本框分别抠出并标记
(8)对框内文本进行识别,然后将结构化信息写入文本文件中。文本文件与图片名保持一致。
序号 插件 功能描述



点击Save As进行保存。保存之后可以通过代码进行修改。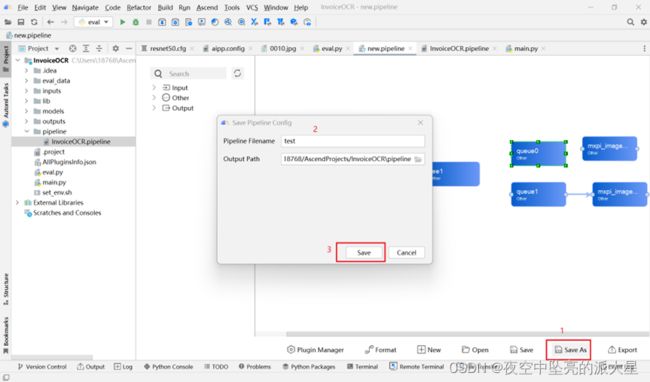
可在test.pipeline文件中配置所需的模型路径与模型后处理插件路径。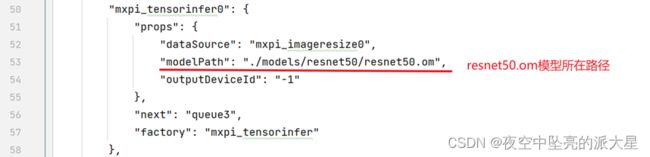


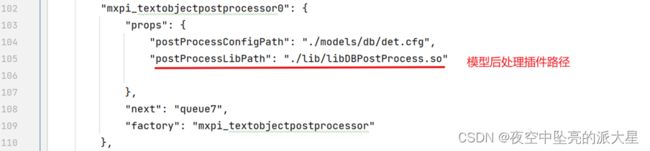
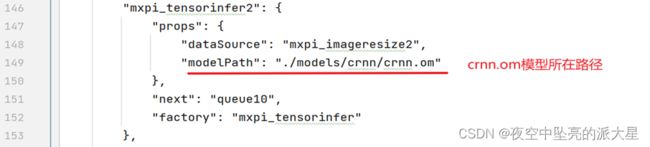

next和dataSource制定了各个元件之间的连接关系,om模型地址需要放在推理插件里面,推理插件输出结果不一定可以可视化,所以需要后处理元件对推理插件进行处理输出。最终pipeline可视化如下:

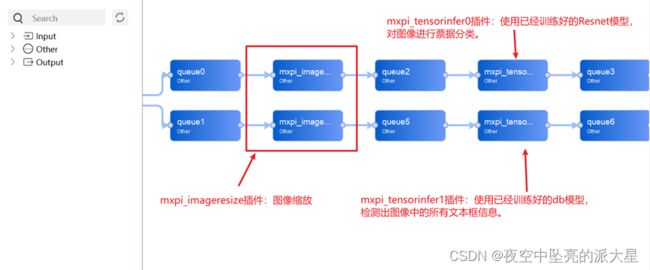


5.2 主程序开发
由于目前MindStudio连接远程python服务器的功能正在开发中,目前仅支持使用MindStudio实现python项目两端代码同步,项目运行依然需要在服务器上实现。pipeline在脚本main.py内部。
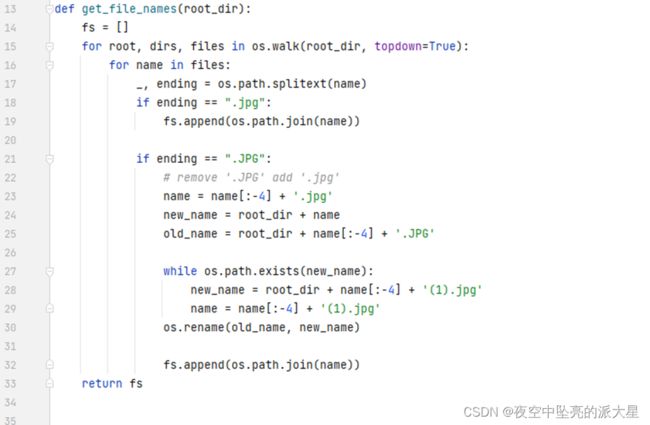
获取输入图片文件名与路径
将识别的文本内容添加到方框左上方。

创建并初始化流管理对象;读取pipeline文件。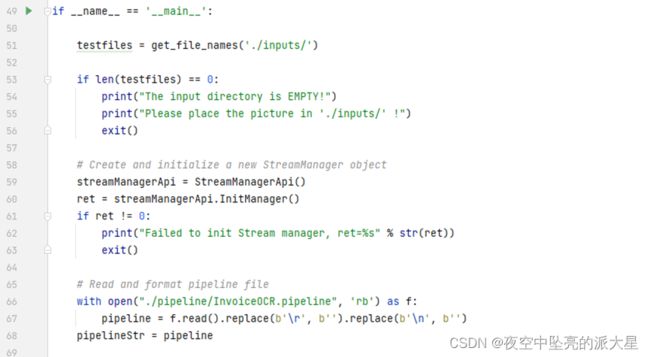
创建流以及输入对象,输入类型为图片数据(jpg图片序列)。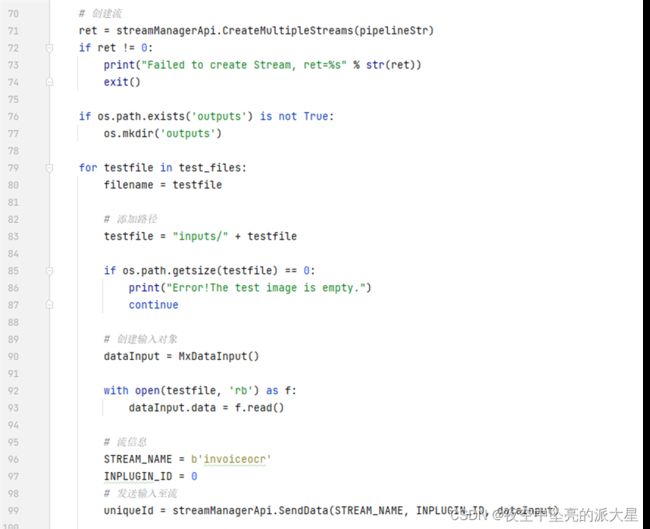
获取输出,并打印结果。
判断并标记输入票据的类型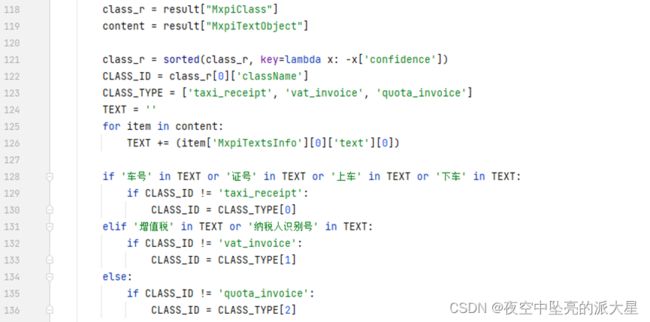
保存框出票据的主要文本信息并标记文本内容以及票据类型的jpg图片在./ouput文件夹下。以及最后销毁流。
将测试图片放在inputs文件夹中,运行main.py等待运行成功后,MindStudio会自动同步远程项目,但是若是自动同步失败或者没有运行,可以点击菜单栏中的Tools>Deployment>Download,下载服务器里的项目,应当包含模型的输出。



待执行完毕可在./outputs目录下查看结果
六、模型精度验证
测试数据可在此处下载,将下载的数据解压到eval_data目录下。
定义获取测试数据的文件名、标签如下: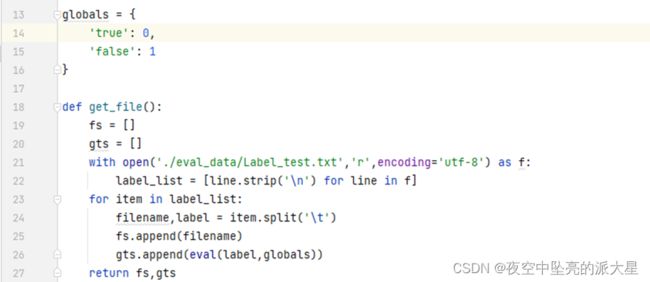
定义计算iou函数以及字符串计数函数如下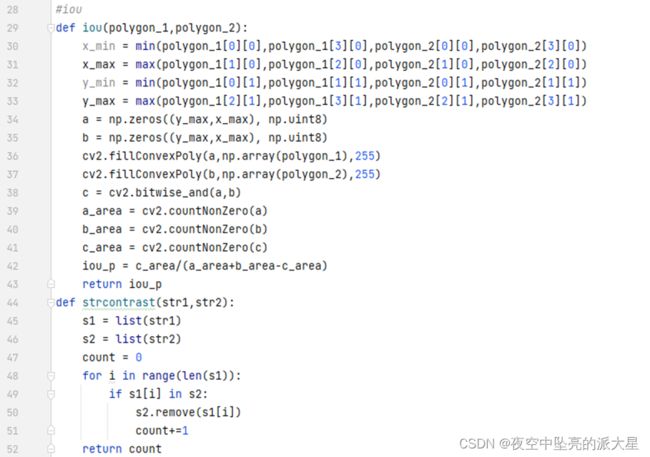
定义精度函数如下:
创建并初始化流管理对象, 读取pipeline。创建流。
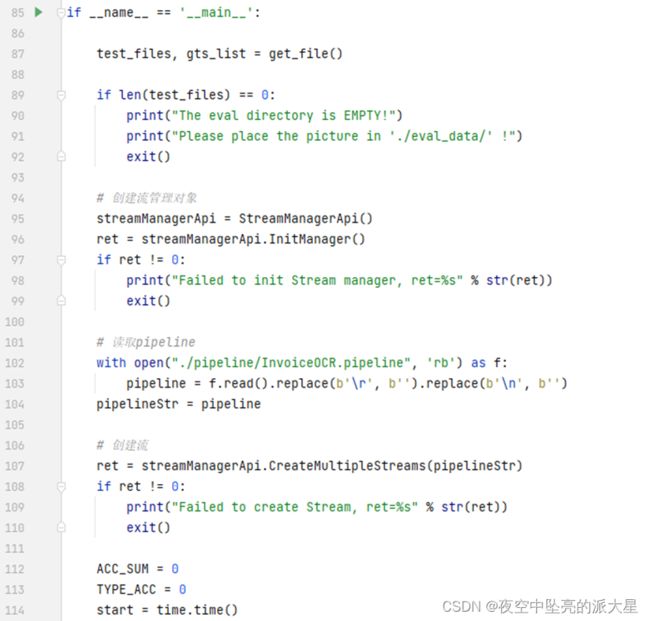
其中type_acc为分类精度,acc为识别端到端精度。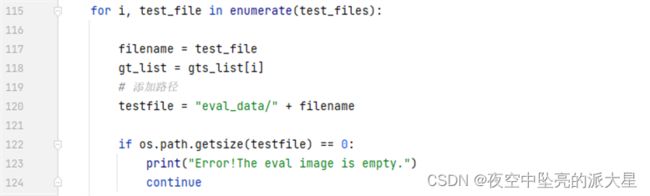
在远程项目目录下执行python3 eval.py

可得精度结果如下所示,其中acc为db+crnn端到端精度,type_acc为
resnet50精度。
七、总结
本文主要介绍使用 MindStudio 全流程开发工具链,在昇腾平台上,开发端到端财务票据OCR识别的参考设计,实现对财务票据中的文本信息进行OCR识别的功能,达到功能要求。在开发过程中碰到了很多问题,除了参考 MindStudio用户手册,社区帖子也提供了很多解决问题的思路。建议在开发过程中遇到问题可查看社区相关经验分享。社区地址如下:https://bbs.huaweicloud.com/forum/forum-945-1.html
实现参考链接https://github.com/AstarLight/CPS-OCR-Engine。
参考文档:https://bbs.huaweicloud.com/forum/thread-0211102567915971019-1-1.html
八、FAQ
CANN配置失败:Permission denied
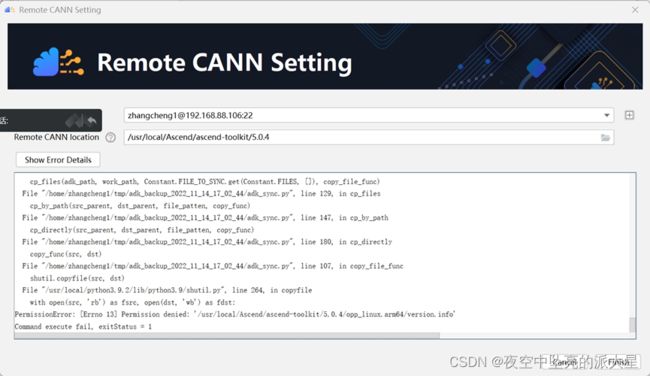
报错原因与解决方法:原先的CANN安装再root权限的用户下,普通用户没有权限。我们需要重新下载普通用户下,然后导入普通用户的路径。
模型转换时,无法导入python module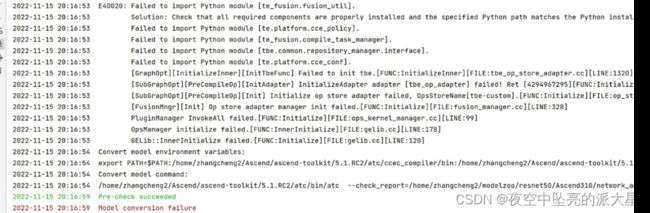
报错原因与解决方法:未配置python的环境变量。打开~/.bashrc文件,添加环境变量。