基于 MindStudio 的图像去噪 MindX SDK 后处理开发(ADNet模型)
ADNet图像降噪
(bilibili视频链接: https://www.bilibili.com/video/BV1te411g72h)
1 任务介绍
基于ADNet模型的图像降噪MindX SDK后处理开发,是在华为昇腾芯片的性能下对模型降噪后的图像进行保存,与原图像进行对比后计算出PSNR(峰值信噪比,是一种最普遍,最广泛使用的评鉴画质的客观量测法)。
ADNet是一种包含注意力模块的卷积神经网络,主要包括用于图像去噪的稀疏块(SB)、特征增强块(FEB)、注意力块(AB)和重建块(RB)。具体来说,SB模块通过使用扩张卷积和公共卷积来去除噪声,在性能和效率之间进行权衡。FEB模块通过长路径整合全局和局部特征信息,以增强去噪模型的表达能力。 AB模块用于精细提取隐藏在复杂背景中的噪声信息,对于复杂噪声图像,尤其是真实噪声图像非常有效。 此外,FEB模块与AB模块集成以提高效率并降低训练去噪模型的复杂度。最后,RB模块通过获得的噪声映射和给定的噪声图像来构造去噪的图像。
本方案采用ADNet模型实现图像去噪功能,整体流程与开发流程如图1所示。我们将待检测的图像输入到整体框架中,通过图像解码、图像解码、图像缩放后输入到图像去噪模型中进行推理,推理得到一个去噪后的图像矩阵。然后,我们将该图像与原始图像之间计算出PSNR值,同时完成图像的可视化结果。

图1 图像去噪流程图
本次实验在Mindstudio与服务器上进行,请先按照教程配置服务器与本地的环境,并安装MindStudio。MindStudio是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。MindStudio 除了具有工程管理、编译、调试、运行等一般普通功能外,还能进行性能分析,算子比对,可以有效提高工作人员的开发效率。除此之外,MIndStudio 具有远端环境,运行任务在远端实现,对于近端的个人设备的要求不高,用户交互体验很好,可以让我们随时随地进行使用。
2 环境搭载和配置
2.1 服务器端推理环境准备
1. 通过表1中所给的链接获取ADNet论文介绍与模型代码。
表1 ADNet模型
| 模型地址 |
https://gitee.com/ascend/ModelZoo-PyTorch/tree/master/ACL_PyTorch/contrib/cv/quality_enhancement/ADNet |
| 论文地址 |
GitHub - hellloxiaotian/ADNet: Attention-guided CNN for image denoising(Neural Networks,2020) |
| 模型概述 |
https://www.hiascend.com/zh/software/modelzoo/detail/1/d360c03430f04185a4fe1aa74250bfea |
2. 打开表1中的模型概述链接,点击推理环境准备,在服务器上安装模型所需的依赖包,如图2所示。
图2 推理环境依赖
3. 配置服务器环境变量
表2 环境变量
| MX_SDK_HOME=/home/tanwenjun0/MindX_SDK/mxVision-2.0.4 |
| LD_LIBRARY_PATH=${MX_SDK_HOME}/python:${MX_SDK_HOME}/lib:${MX_SDK_HOME}/opensource/lib:${MX_SDK_HOME}/opensource/lib64:/usr/local/Ascend/ascend-toolkit/5.0.4/acllib/lib64:/usr/local/Ascend/driver/lib64:/usr/local/Ascend/ascend-toolkit/latest/acllib/lib64 |
| PYTHONPATH=/usr/local/Ascend/ascend-toolkit/latest/pyACL/python/site-packages/acl:${MX_SDK_HOME}/python:/usr/local/Ascend/ascend-toolkit/latest/pyACL/python/site-packages/acl:${MX_SDK_HOME}/python/usr/local/Ascend/ascend-toolkit/latest/pyACL/python/site-packages/acl |
| GST_PLUGIN_SCANNER=${MX_SDK_HOME}/opensource/libexec/gstreamer-1.0/gst-plugin-scanner |
| GST_PLUGIN_PATH=${MX_SDK_HOME}/opensource/lib/gstreamer-1.0:${MX_SDK_HOME}/lib/plugins |
2.2 MindStudio 简介及安装
MindStudio 提供了 AI 开发所需的一站式开发环境,提供图形化开发界面,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。同时还支持网络移植、优化和分析等功能。依靠模型可视化、算力测试、IDE 本地仿真调试等功能,MindStudio 能够帮助用户在一个工具上就能高效便捷地完成 AI 应用发。同时,MindStudio 采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。本图文教程,将基于 Windows 平台上的 MindStudio,具体安装流程,可以参考官网如下图 3 与 4 所示。
MindStudio 软件包下载地址:
https://www.hiascend.com/software/mindstudio/download
Windows 平台下载安装流程:
https://support.huaweicloud.com/devg-mindstudio304/atlasms_02_0008.html
图3 MindStudio软件包下载

图4 Windows平台安装
2.3 CANN简介及安装流程
CANN(Compute Architecture for Neural Networks)是华为公司针对 AI 场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的 AI 应用和业务。用户根据实际使用需要,下载对应的 CANN 软件包,具体安装流程可以参考官网的用户手册如下图 5 与 6 所示。
CANN 软件包下载地址:https://www.hiascend.com/software/cann/commercial
CANN 安装流程:昇腾社区-官网丨昇腾万里 让智能无所不及

图5 CANN软件包下载

图6 CANN安装流程
2.4 本地Python安装和配置
本地配置远端服务器python3.9.12为编译器,并检查编译环境。也可以手动添加本地编译环境,通过conda命令完成创建。

图7 选择python编译环境
3 创建项目工程,完成结构配置
1. 创建项目,点击菜单栏的“File->New->Project”按钮,如下图 8 所示。
图8 创建项目
2. 选择 Ascend App 项目,输入项目名,其中 CANN 版本应与远端服务器转
一致,点击 change,如下图 9 与 10 所示。

图9 配置CANN图
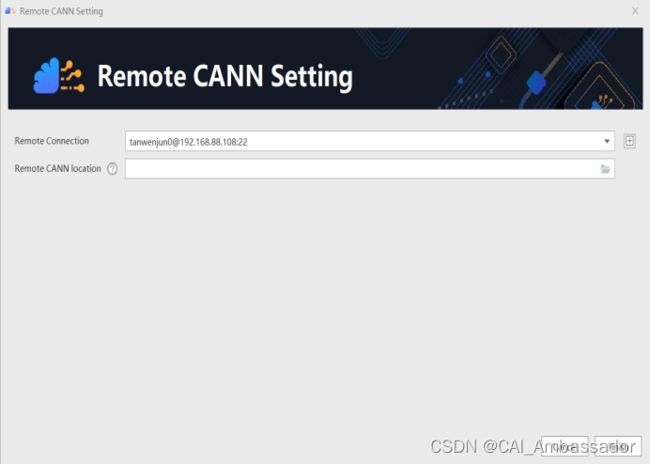
图10 连接远端服务器CANN图
3. 添加远程服务器,填写远端服务器信息,测试连接,如下图11所示。

图11 测试连接图
4. 连接成功后,选择 CANN 目录,等待本地同步远端服务器 CANN 文件,如下图12所示。
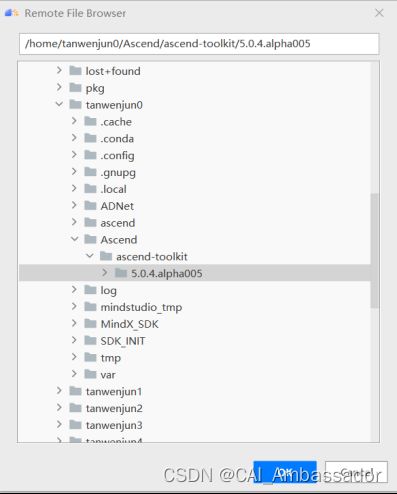
图12 同步服务器图
5. 同步成功后,选择Ascend App下的 MindX SDK Project(python)项目,完成新建项目,如下图13所示。
图13 选择项目类型图
6.选择菜单栏“File -> Settings -> Tools -> Deployment -> Mappings”,配置服务器地址与本地地址映射,如下图 14 所示。
图14 配置服务器映射地址
7.右键点击项目工程文件,选择“Deployment -> Download from -> 服务器”,将服务器文件下载到本地地址目录下,如图15所示。服务器地址与刚才设置的mappings有直接联系,我们也可以选择Upload to将本地文件上传到服务器。

图15 导入服务器文件
4 ATC模型转换
1. 菜单栏选择“Ascend -> Model Converter”,打开模型转换功能。
图16 选择模型转换功能
2. 配置好模型路径,填写模型相关信息,如图17所示。

图17 配置模型参数
ADNet模型的常规参数设置如表3所示,请根据实际情况完成正确配置,填写完毕后点击Next按钮。
表3 模型常规参数设置
| Model File |
选择要转换的ONNX模型所在地址 |
| Model Name |
填写输出模型的名称 |
| Target SoC Version |
Ascend310 |
| Input Format |
ADNet模型的输入格式要求 NCHW |
| Image Shape |
ADNet模型的输入尺寸要求 [1 1 321 481] |
| Image Type |
ADNet模型的输入数据类型要求 UINT8 |
3.选择aipp配置文件,完成了图像padding、色域转换、数据标准化等设置,如图18所示。
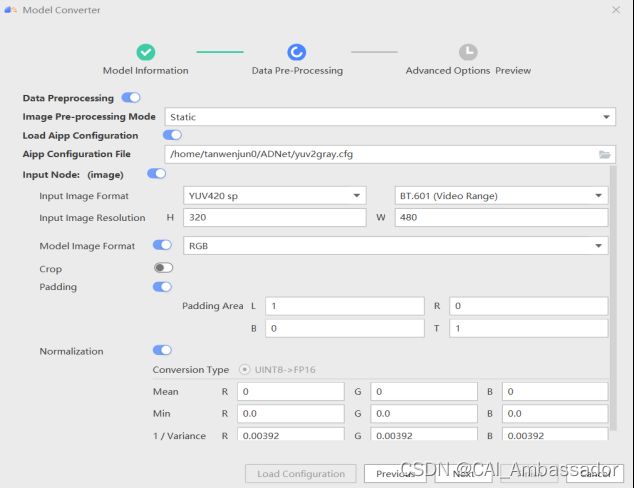
图18 配置模型aipp文件
ADNet模型的高级参数设置如表4所示,请根据实际情况完成正确配置,填写完毕后点击Next按钮。我们可以选择提前将配置信息写入config文件后点击Load Aipp Configuration直接导入,也可以在下列参数中完成手动配置。
表4 模型高级参数设置
| Load Aipp Configuration |
打开此按钮,导入模型配置文件 |
| Aipp Configuration File |
选择模型config文件 |
| Input Image Format |
YUV420 sp / BT.601(Video Range) |
| Input Image Resolution |
H 320 W 480 |
| Model Image Format |
RGB |
| Padding |
L 1 R 0 B 0 T 1 |
| Normalization |
R 0.00392 G 0.00392 B 0.00392 |
| Crop |
关闭此按钮,不需要进行裁剪 |
4. 点击按钮,配置ATC转换所需的环境变量,设置完成后点击Finish开始转换模型,转换成功后如图20所示。

图19 配置模型转换环境变量

图20 模型转换成功
5 编写Pipeline文件
1. 菜单栏选择“Ascend -> Model SDK Pipeline”,进入pipeline编写模块。
图21 选择编写pipeline功能
2. pipeline模块分为Input,other,Output三部分,我们根据模型处理需求选择模块拖拽到右侧空白处,如图22所示。(也可以直接编写文本文件)

图22 选择pipeline模块
3.我们编写完成的pipeline如图23所示,包括以下六个插件:
- appsrc 输入
- mxpi_imagedecoder 图像解码
- mxpi_imageresize 图像缩放
- mxpi_tensorinfer 模型推理
- mxpi_dataserialize
- appsink 输出

图23 完成模型的pipeline
6 运行项目工程文件
1.后处理技术实现原理
ADNET图像去噪模型的后处理的输入是 pipeline 中 mxpi_tensorinfer0 推理结束后通过 appsink0 输出的 tensor 数据,尺寸为[1*1*321*481],将张量数据通过 pred 取出推测的结果值,将像素点组成的图片保存成result.jpg,同时通过提供的 BSD68 数据集完成模型 PSNR 的精度计算。
PSNR(Peak signal-to-noise ratio)峰值信噪比,是一个表示信号最大可能功率和影响它的表示精度的破坏性噪声功率的比值的工程术语。由于许多信号都有非常宽的动态范围,峰值信噪比常用对数分贝单位来表示。它的计算公式定义如下:

其中MSE为两个m×n单色图像I和K残差值的平方,计算公式如下:
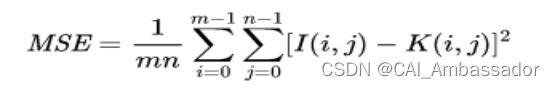
2.后处理实现流程
(1)将转换得到的模型om文件,保存在my_work/model文件夹路径下。
(2)将任意一张jpg格式的图片存到当前目录下(/my_work),命名为test.jpg。如果 pipeline 文件(或测试图片)不在当前目录下(/my_work),需要修改 main.py 的pipeline(或测试图片)路径指向到所在目录。
(3)设置好表2中MX_SDK_HOME,LD_LIBRARY_PATH,PYTHONPATH,GST_PLUGIN_SCANNER,GST_PLUGIN_PATH五个环境变量。
(4)运行main.py,在当前目录下输出result.jpg。图24为用于测试的原始图像,图25为经过模型处理去噪后的图像。

图24 测试图像

图25 去噪后的图像
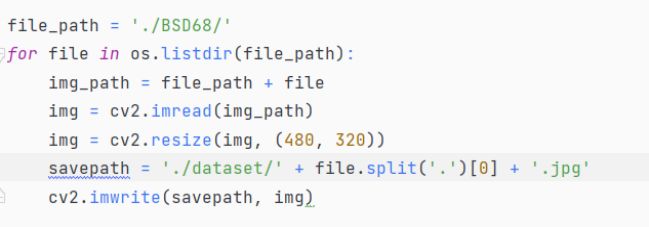
(5)安装数据集以测试精度。数据集BSD68需要下载到/my_work下,我们运行 python transform.py 对数据集进行格式与尺寸转换得到 dataset 文件。
(6) 修改 evaluate.py 中的 pipeline 路径与数据集路径与目录结构保持一致。修改完毕后运行 python evaluate.py 完成精度测试,输出模型平均 PSNR 值,如图26所示。
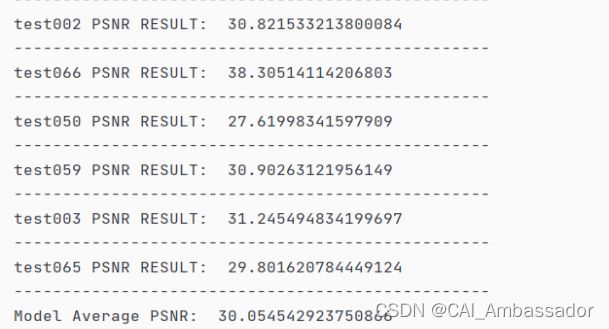
图26 后处理输出PSNR结果
7 项目工程文件详解
1. 主函数 main.py
函数功能:实现端到端的推理,输入一张待去噪的图像,输出去噪后的图像。
2. 新建一个数据流,实例化一个StreamManagerApi对象。若初始化失败,则报错并推出程序。
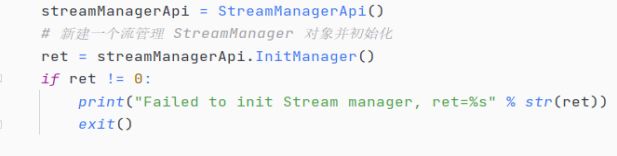
这一部分是导入外部的pipeline文件。我们将pipeline_path指向项目的pipeline文件地址,并将文件内容通过StreamManagerApi传入流中。

这一部分是传入待去噪的图像数据。我们将image_path指向目标图像地址,实例化一个MxDataInput对象,并将图像数据通过MxDataInput.data传入数据流中,同时将原始图像的height、width保存下来,方便我们后期对图像进行resize。

这一部分是根据流名将数据通过SendData函数传入流中,并设置想要获取的插件输出放置到变量keys中(可以放置多个插件),我们将 mxpi_tensorinfer通过 StringVector.push_back 函数完成插入。

这一部分从流中取出对应插件的输出数据,与上一部分的插件选择直接相关。
我们通过appsink输出插件拿到上面的mxpi_tensorinfer插件的结果。若取出的结果为空,则报错后退出程序。

我们将得到的result存储在MxpiTensorPackageList中,并通过numpy的frombuffer函数将pred以流的形式读入转化成array对象,并设置数据类型为float32。

这一部分为数据后处理阶段。我们将 pred 的尺寸resize为(320,480),变成与模型输出相对应的矩阵维度。同时,我们设置了一个类似于torch.clamp的函数:将 pred 每个元素的范围限制到区间 [0,1],若 pred 值小于0,则赋值为0;若 pred 值大于1,则赋值为1;其他的值保持不变。最后,我们需要去除归一化,将数据还原到正常像素范围(0,255)上。

这一部分为图像保存。我们将矩阵向量通过cv2.resize函数转为与输入一致的尺寸,并选择了合适的缩放方式,并通过cv2.imwrite函数将图像保存到指定目录下。最后通过 DestroyAllSreams 完成流的销毁与内存释放。

2. 精度测试函数 evaluate.py
函数功能:导入指定的BSD68数据集,完成我们的精度测试。由于整体部分与main.py相近,因此我们只介绍精度计算部分。
我们通过双层for循环控制原始图像与去噪后图像的像素访问,根据PSNR的计算方法完成每一张图像的PSNR计算并输出保存。最后完成所有68张图像的计算后,输出平均PSNR值作为最终的精度测试结果。

3. 格式转换函数 transform.py
函数功能:对测试图像进行格式转换以及精度测试前的尺寸调整。
执行evaluate.py前,由于模型的输出维度为 320 * 480,我们需要将原始图像的大小resize为320 * 480才能进行PSNR值的计算。
执行main.py前,由于需要将图像的原始尺寸信息记录,因此不需要将原始图像的大小进行resize,只进行格式转换即可。我们pipeline中的图像缩放插件会针对模型输入需要完成缩放功能。
8 遇到的问题
1.在执行样例时报错“No module named 'StreamManagerApi'”如下图27 所示。

图27 未找到StreamManagerApi模块图
解决方法:正确导入如表2中的环境变量。
2.模型转换过程中无法选择我们需要的模型输入大小(321 * 481),如下图28所示。

图28 未得到模型所需的tensor尺寸
解决方法:模型的输入分辨率值(W与H)不能为奇数。转换模型时未导入aipp_config文件,需要配置resize之后在图像左侧和上侧设置padding值为1,从而满足模型的输入。