使用MindStudio进行开发基于MindX SDK的AnimeGAN风格迁移模型
本文的视频教程可点击下面链接:
https://www.bilibili.com/video/BV1h84y1q7Db
1. 任务介绍
1.1 任务场景
MindX SDK应用开发
1.2 任务描述
基于Atlas 200DK平台,使用MindX SDK,实现从真实世界图片到动漫风格图片的风格转换,在Ascend 310上对输入图片进行图像风格转换并将转换结果保存,支持动态分辨率输入。
1.3 任务目标
在Ascend 310上的推理精度与原模型精度相差小于1%。
1.4 环境信息
开发环境:Windows 11 + MindStudio 5.0.RC2
昇腾设备:Atlas 200DK
昇腾芯片:Ascend 310
操作系统:Ubuntu 18.04
环境依赖软件和版本如下表:
| 软件名称 | 版本 |
|---|---|
| cmake | 3.10.2 |
| mxVision | 3.0.RC2 |
| Python | 3.9.12 |
| CANN | 5.1.RC2 |
| GCC | 7.5.0 |
Python第三方库依赖如下表:
| 软件名称 | 版本 | 说明 |
|---|---|---|
| opencv-python | 4.6.0.66 | |
| protobuf | 3.19.0 | |
| scikit-image | 0.19.3 | 仅在eval.py中依赖,可选 |
2. 模型介绍
AnimeGAN是在2019年提出的用于图像风格迁移的模型,该模型基于GAN模型,可以快速地将真实世界的图像转换成高质量的动漫风格的图像,具体可参看论文:
https://link.springer.com/chapter/10.1007/978-981-15-5577-0_18
Tensorflow版本的代码:
https://github.com/TachibanaYoshino/AnimeGAN
我们也提供了已经转换好的模型以及一些测试数据集的OBS地址:
PB模型:
https://animegan-mxsdk.obs.cn-north-4.myhuaweicloud.com/models/AnimeGAN.pb
OM模型:
https://animegan-mxsdk.obs.cn-north-4.myhuaweicloud.com/models/AnimeGAN_FD.om
数据集:
https://animegan-mxsdk.obs.cn-north-4.myhuaweicloud.com/dataset/dataset.zip
3. 开发前准备
3.1 环境准备
首先安装好CANN和MindX SDK,具体可参考如下链接:
CANN安装指导:
https://www.hiascend.com/document/detail/zh/canncommercial/51RC2/overview/index.html
MindX SDK安装指导:
https://www.hiascend.com/document/detail/zh/mind-sdk/30rc2/overview/index.html
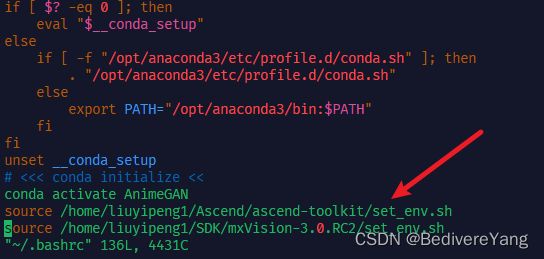
然后开始设置环境变量,在Ascend的安装目录和MindX SDK的安装目录可以分别找到set_env.sh,它们包含了MindX SDK App所需的大部分环境变量。我们可以打开它们查看内容并且运行脚本,也可以将它们加入~/.bashrc,以便每次进入bash时不用重新手动运行。
![]()

编辑bashrc,vi ~/.bashrc,在bashrc中应用这两个脚本,然后重启bash。
vi ~/.bashrc
# 在bashrc中加入以下两行并保存
source ${SDK安装路径}/set_env.sh
source ${CANN安装路径}/set_env.sh
# 保存后重启bash
bash
3.2 安装MindStudio
MindStudio的依赖项主要有CANN,若需开发MindX SDK应用,还需MindX SDK的支持。
如果准备在Linux环境使用MindStudio进行远程开发,则需要X Server支持。可以在安装好CANN和MindX SDK的Linux机器上安装MindStudio,后续通过MobaXterm等支持X11 Forwarding的终端远程连接。或者直接通过显示器连接Linux机器开发。
此处我们在Windows环境下开发。基于MindStudio的SDK应用开发环境搭建可以参考:
https://www.hiascend.com/document/detail/zh/mindstudio/50RC2/msug/msug_000086.html
4. 建立项目
4.1 新建MindX Application项目
进入到MindStudio的安装目录,选择bin目录下的MindStudio64.exe,打开MindStudio。
然后点击New Project,选择Ascend App,选择MindX SDK Project(Python),然后点击完成,项目就新建完毕了。

如果没有选中这些项目模板,则MindStudio的工具栏会默认缺少一些工具,或者工具不可用。因此新建项目请按照上述步骤。如果需要基于已有的项目,可以在打开已有项目后选择工具栏的Ascend>Convert To Ascend Project转换成MindX SDK App。


4.2 文件结构
一般的MindX SDK App应当至少包含如下文件:
main.py ---- 程序的主入口
model.om ---- om模型
model.pipeline ---- pipeline文件
本项目的具体结构如下图:
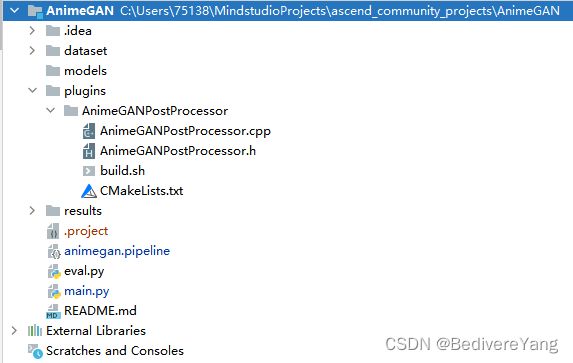
│ README.md
│ main.py # 主程序
| eval.py # 测量NPU生成图片与GPU框架生成图片的SSIM
| animegan.pipeline # pipeline文件
├─dataset
├─results
├─models
│ AnimeGAN_FD.om # 应用推理所需的om模型
├─plugins
│ ├─AnimeGANPostProcessor # AnimeGAN后处理插件
│ │ build.sh # 编译AnimeGAN后处理插件的脚本
│ │ CMakeLists.txt
│ │ AnimeGANPostProcessor.cpp
│ │ AnimeGANPostProcessor.h
5. 模型转换
5.1 准备模型文件
MindX SDK支持的模型格式是om模型,因此使用之前须进行模型转换。首先需要将Tensorflow的ckpt模型文件转换成pb文件,再使用转化工具将模型转化为om模型。
若下载我们在OBS提供的pb模型,则可以跳跃至5.4 模型转换阅读,如果使用了我们提供的om模型,则可以跳过本章, 但要注意我们的om模型支持的分辨率档位为长宽从384到1536,以128为基数递增的各种分辨率组合。
首先在https://github.com/TachibanaYoshino/AnimeGAN下载官方的源代码和ckpt模型文件。
5.2 确定输入、输出节点
为了模型转换,需要确定输入的Placeholder的name和输出节点的name。输入节点在后续步骤中,工具可以自动获取,但如果工具获取失败,还需在此步查看。
手工查看
打开官方源代码的中关于模型的代码net/generatir.py,查看Generator模型的输出节点。下例代码中的tanh节点,就是本模型的输出。节点的默认名称与其操作算子有关,比如tanh节点名称为Tanh,为了更方便定位该节点,可以给tanh节点自定义名称output,但是注意在最终使用时要加上节点的命名空间,即generator/G_MODEL/output。

然后打开test.py,查看输入的Placeholder节点。下例中名为test的placeholder就是本模型的输入,其支持动态分辨率,即图片的长和宽无需提前指定。
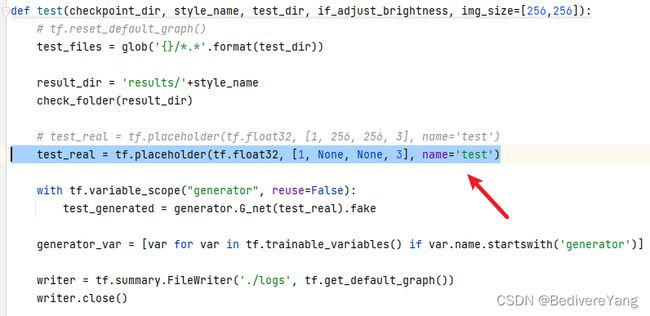
使用Tensorboard
除开直接查看源代码外,也可以使用tf.summary.FileWriter,在运行推理流程的同时保存日志,然后使用Tensorboard指定日志位置,查看网络图,确认输入和输出的节点。

将上面标蓝的代码插入到推理代码当中,然后运行一次推理流程,会将日志保存在./logs文件夹。在安装Tensorboard的环境中运行下面的命令,然后在Tensorboard提示的网页中打开,即可看到模型的网络图。
tensorboard --logdir=./logs

如上图,我们使用Tensorboard找到了名为generator/G_MODEL/output的输出节点。
5.3 PB固化
参照如下pb_frozen.py,编写PB固化脚本。
# pb_frozen.py
import tensorflow as tf
from tensorflow.python.framework import graph_util
import argparse
import os
from net import generator
def parse_args():
desc = "AnimeGAN"
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('--checkpoint_dir', type=str, default='checkpoint/'+'generator_Hayao_weight/',
help='Directory name to save the checkpoints')
return parser.parse_args()
def main():
# 解析传进来的参数,这里就只有模型路径
arg = parse_args()
checkpoint_dir = arg.checkpoint_dir
print(arg.checkpoint_dir)
# 可以按照模型推理代码,建立模型
test_real = tf.placeholder(tf.float32, [1, None, None, 3], name='test')
with tf.variable_scope("generator", reuse=False):
test_generated = generator.G_net(test_real).fake
generator_var = [var for var in tf.trainable_variables() if var.name.startswith('generator')]
saver = tf.train.Saver(generator_var)
with tf.Session() as sess:
# 读取训练好的模型
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
saver.restore(sess, os.path.join(checkpoint_dir, ckpt_name))
print(" [*] Success to read {}".format(ckpt_name))
# 如果读取成功,就开始准备固化模型
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
# 下面的文件为输出的文件名,可以自行修改
output_graph = os.path.join("AnimeGAN.pb")
# 将output_node_nmames里的名字更换成上述步骤找到的节点名
output_graph_def = graph_util.convert_variables_to_constants(
sess=sess,
input_graph_def=input_graph_def,
output_node_names=["generator/G_MODEL/output"])
# 保存pb模型
with tf.gfile.GFile(output_graph, "wb") as f:
f.write(output_graph_def.SerializeToString())
print("done")
else:
print(" [*] Failed to find a checkpoint")
return
if __name__ == '__main__':
main()
固化各类模型的代码基本一致,针对特定模型需要修改的的操作步骤主要如下:
第一步,按照原模型的初始化代码建立模型,并读取5.1 准备模型文件中获取的ckpt权重文件。
在本模型中,其对应代码为:
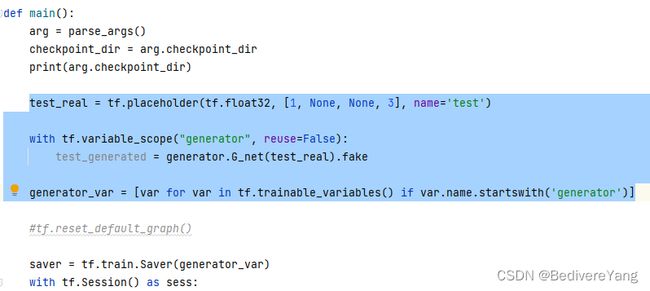
上图这段代码分别建立了模型的输入Placeholder和Generator网络。
接下来是读取预训练权重。

然后更改脚本中output_node_names为5.2 确定输入、输出节点中确定的输出节点的name。

output_graph里的文件名是最后得到的PB文件名,可自行更改。

最后运行PB固化脚本,若成功,应当会在当前目录下生成pb文件。
5.4 模型转换
转换pb模型到om模型的操作步骤如下:
将PB文件上传到CANN所在服务器后,打开MindStudio,在顶部菜单栏中选择“Ascend>Model Convertor”,打开图形化模型转换工具。
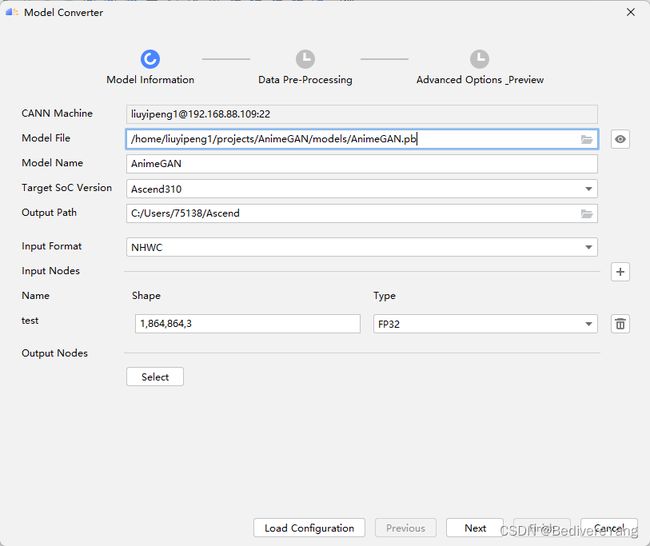
在Model File中选中刚才上传的PB模型。Model Name一栏可自行更改,其为输出的om模型名。Target Soc Version选中目标平台,这里我们选择Ascend310。Output Path为输出路径,模型转换工具会将转换后的一些文件拷贝至该位置。
更改Input Format和Input Nodes,一般情况下,选择好PB文件后,该栏会自动和模型匹配,若是因某些原因没有自动匹配,需自行选定,按照5.2 确定输入、输出节点中得到的输入的name选择节点。
旧版本的MindX SDK的已有插件中的推理插件mxpi_tensorinfer暂不支持动态分辨率模型,因此即使原模型支持动态分辨率,也需要在此步将input的分辨率固定下来。另外,如果用户设置的分辨率数值过大,也可能会导致模型转换失败,即使模型转换成功,后续的推理也可能失败,因此请酌情修改。
若需要动态分辨率支持,可以使用mxVision 3.0.RC2及以上的版本,经实验确定推理插件mxpi_tensorinfer已经支持动态分辨率模型。
Input Nodes中的Shape为-1的一项表明该维度是动态的,因此可以根据需要将N留-1以实现动态Batch,或者将H,W留为-1,-1以实现动态分辨率。但注意,动态分辨率和动态Batch是不能同时应用的。如果使用动态分辨率,要求提前给定可能出现的分辨率组合,也就是在Dynamic Image Size一栏中给出,最少给定2档,最多支持100档。
下图中,我们使用了动态分辨率,并给定了长宽从384到1536,以128为基数递增的各种分辨率组合:

点击Output Nodes下方的Select,会出现可视化的模型图,从中找到5.2 确定输入、输出节点中确定的输出节点,一般是在模型图的最下方,右击该节点并选中Select,然后点击OK确认。

点击Next,下一步是一些数据预处理,比如转换颜色空间、裁切输入以适配模型等,可按需选择。本项目并不需要进行预处理,因此继续进行下一步。
在Advanced Options中,可以设置环境变量和一些高级参数。比如,因为本模型有精度需求,而模型转换默认会将同时支持Float32和Float16的算子精度降低为Float16,因此需要禁止其降低精度,可以加上–precision_mode=force_fp32,其他高级参数可参见ATC官方文档:
https://support.huaweicloud.com/atctool-cann330alpha2infer/atlasatc_16_0081.html

最后得到的OM模型文件默认会保存在远端服务器~/modelzoo里,将其拷贝至项目文件夹内,模型转换一步就完成了。
6. 设计Pipeline
MindX SDK实现功能的最小粒度是插件,每一个插件实现特定的功能,如图片解码、图片缩放等。将这些插件按照合理的顺序编排,实现相应的功能。
我们将这个配置文件叫做pipeline,以JSON格式编写,用户必须指定业务流名称、元件名称和插件名称,并根据需要,补充元件属性和下游元件名称信息。
我们在MindStudio中可以进行可视化流程编排。在顶部菜单栏中选择“Ascend>MindX SDK Pipeline”,打开空白的pipeline绘制界面,可以在左方插件库中选中所需的插件,并进行插入插件、修改参数等操作。


本模型使用的插件和工作流程如下:
| 序号 | 子系统 | 功能描述 |
|---|---|---|
| 1 | 图片输入 | 调用appsrc输入图片 |
| 2 | 图像解码 | 调用mxpi_imagedecoder对图像解码 |
| 3 | 归一化 | 调用mxpi_imagenormalize将图像归一化到[-1,1] |
| 4 | 模型推理 | 调用mxpi_tensorinfer推理图像 |
| 5 | 结果输出 | 从流中获取处理结果,进行后处理并保存至文件夹中 |
本项目Pipeline的文本格式如下:
{
"animegan": {
"stream_config": {
"deviceId": "3"
},
"appsrc0": {
"props": {
"blocksize": "409600"
},
"factory": "appsrc",
"next": "mxpi_imagedecoder0"
},
"mxpi_imagedecoder0": {
"props": {
"cvProcessor": "opencv",
"dataType": "float32",
"outputDataFormat": "RGB"
},
"factory": "mxpi_imagedecoder",
"next": "mxpi_imagenormalize0"
},
"mxpi_imagenormalize0": {
"props": {
"alpha": "127.5,127.5,127.5",
"beta": "127.5,127.5,127.5",
"dataType": "FLOAT32"
},
"factory": "mxpi_imagenormalize",
"next": "mxpi_tensorinfer0"
},
"mxpi_tensorinfer0": {
"props": {
"dataSource": "mxpi_imagenormalize0",
"modelPath": "models/AnimeGAN_FD.om",
"waitingTime": "8000"
},
"factory": "mxpi_tensorinfer",
"next": "animeganpostprocessor0"
},
"animeganpostprocessor0": {
"props": {
"dataSource": "mxpi_tensorinfer0",
"outputPath": "results/npu"
},
"factory": "animeganpostprocessor",
"next": "appsink0"
},
"appsink0": {
"props": {
"blocksize": "409600"
},
"factory": "appsink"
}
}
}
其中animeganpostprocessor0并不是官方插件库中的一员,而是接下来我们要自定义编写的插件,用于结果后处理和保存。
元件的名称,例如"mxpi_tensorinfer0",是可以自行修改的,只需要确认其和其他元件的连接即可,一般按照插件基类名+序号命名。
插件名称factory,例如"factory": “mxpi_tensorinfer”,则指定了该元件的功能,需要从已有插件中查询。
元件的属性props可以参考已有插件介绍:
https://support.huawei.com/enterprise/zh/doc/EDOC1100234263/26583ebd
next和dataSouce则指定了元件的连接关系。
本模型的pipeline需要重点关注的参数就是mxpi_tensorinfer0的modelPath,修改为5.4 模型转换中转换好的OM模型路径,以及animeganpostprocessor0的outputPath,该路径指定了推理结果的保存路径。
注意,不论属性值的数据类型是否为字符串,属性值都以字符串填写。
7. 应用开发
7.1 主程序逻辑
接下来就是应用主程序的编写。本项目主程序的逻辑如下:
- 初始化流管理。
- 加载图像,对图像进行预处理以符合动态分辨率模型的档位
- 向流发送图像数据,进行推理。
- 获取pipeline各插件输出结果,其中animeganpostprocessor会自动保存结果。
- 销毁流
7.2 主程序实现
下图是本程序的需要的依赖库,其中StreamManagerApi是MindX SDK自带的,如果在Windows本地进行编辑代码,需要使用MindStudio的同步MindX SDK的功能将这些库文件下载到本地,才可以有代码补全提示等,并消去MindStudio对于没有找到对应库的提示。当然,这些错误提示也是可以忽略的,因为真正运行程序是在安装了CANN和MindX SDK的昇腾设备上进行的。
另外,如果在昇腾设备上运行程序时报找不到OpenCV等第三方库的错误提示,可以使用pip或者conda安装,但如果是报找不到StreamManagerApi等MindX SDK自带的库的错误提示,则不能使用pip或conda安装了。此时要确认环境变量是否配置正确,${PYTHONPATH}这个环境变量用于在导入模块的时候搜索路径,配置正确会给程序指明MindX SDK自带模块的位置。配置环境变量请看3.1 环境准备一节。

对图片进行前处理,将各种大小的图片预先Resize成设置的动态分辨率档位之中,并且将原本OpenCV的Ndarray数据类型转换成字节表示,以便发送至流中。

在程序开始前,应先检查pipeline文件、数据集等是否存在。

然后需要进行的是初始化流管理器,接下来和流、昇腾设备等相关的都是通过调用该接口进行完成的。

读取pipeline文件,然后根据pipeline创建流。

发送数据时需要将数据赋给dataInput,然后指定流名,指定输入插件的插件名称,调用SendData发送。
其中发送数据和接收数据这一套业务流数据对接接口共有4套,但有些接口是可以不用成套使用的。比如本程序中的SendData是和GetResult配对的,但是本程序使用的获取结果的接口是GetProtobuf,这些根据实际情况使用即可。详细的使用说明可以查看官方文档
https://www.hiascend.com/document/detail/zh/mind-sdk/30rc2/vision/mxvisionug/mxvisionug_0045.html

发送数据后的处理是对用户透明的,用户只需要确认数据发送成功后,就可以尝试获取结果。在GetProtobuf这个接口中,我们需要指定流名称、对应的输入接口的编号,以及要获取结果的插件的插件名。

完成处理后,应当回收并销毁所创建的流。

8. 后处理插件的编写和编译
8.1 创建后处理插件项目
一般的后处理插件开发,可以根据任务类型,选择SDK已经支持的后处理基类去派生一个新的子类,这些后处理基类分别为目标检测,分类任务,语义分割,文本生成。但因为SDK现有支持的后处理插件的基类并不包含GAN,因此需要新增后处理基类继承PostProcessBase,并写入新的数据结构。详细请查看
https://www.hiascend.com/document/detail/zh/mind-sdk/30rc2/vision/mxvisionug/mxvisionug_0057.html
或者基于普通插件的开发步骤,自行实现后处理的功能。详细请查看
https://www.hiascend.com/document/detail/zh/mind-sdk/30rc2/vision/mxvisionug/mxvisionug_0048.html
接下来,我们就基于普通插件的开发步骤,来实现本项目所需的后处理插件。
MindStudio支持创建MindX SDK插件的模板,它会提供一个继承MxPluginBase的空类,但会提供一些函数声明。基于这些模板,进行后续开发会更简洁和方便。
右击项目,点击New MindX SDK Plugin。

填写插件名称,选中想要放置插件项目文件的位置,点击OK。
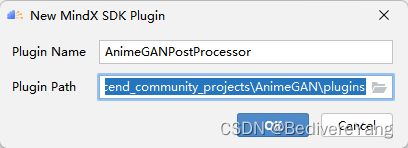
就会在选中的位置生成如下模板文件:

其中CMakeLists.txt一般保持原状即可,若有需要链接的库,再自定义添加。
8.2 自定义属性
我们的插件都是继承自MxPluginBase类的,该父类自带一些成员属性,譬如dataSource等,并不需要我们进行修改。如果需要自定义一些插件的属性,则可进行如下步骤:
在AnimeGANPostProcessor.h中给AnimeGANPostProcessor类添加成员变量。
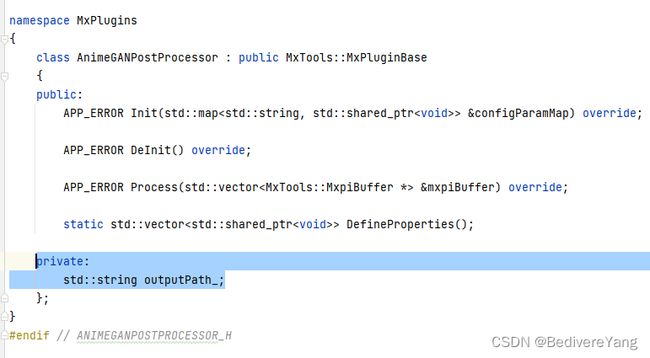
在AnimeGANPostProcessor.cpp中实现AnimeGANPostProcessor::DefineProperties函数,更详细的内容可以查看
https://www.hiascend.com/document/detail/zh/mind-sdk/30rc2/vision/mxvisionug/mxvisionug_0048.html

在插件初始化中获取该属性,实现AnimeGANPostProcessor::Init。对于outputPath这种指定保存文件夹位置的属性,还可以在初始化时检查文件夹是否存在以及进行创建等动作。

8.3 处理
本项目的后处理的主要工作有:将插件之间传输的Metadata格式转换成可以保存的OpenCV的Mat格式;将该图片映射回[0,255];以RGB格式保存图片。
因此需要重写AnimeGANPostProcessor::Process函数。
- 获取上流插件输出的Metadata
Metadata使用的是Google的Protobuf格式。先根据上游插件的key,此处即dataSource,获取上游插件发送的结果数据。

- 将Metadata转换成特定的格式
因为本插件后接于mxpi_tensorinfer,模型输出的结果是MxpiTensorPackageList,因此其对应格式是MxpiTensorPackageList。如果后接于mxpi_objectpostprocessor等插件,则对应格式就会变为MxpiObjectList,具体的输入输出数据类型可以查看对应的插件介绍。

- 从MxpiTensorPackageList中获取data
MxpiTensorPackageList是MxpiTensorPackage的嵌套列表,而MxpiTensorPackage是MxpiTensor的组合数据,具体的定义可以查看Metadata介绍:
https://www.hiascend.com/document/detail/zh/mind-sdk/30rc2/vision/mxvisionug/mxvisionug_0557.html
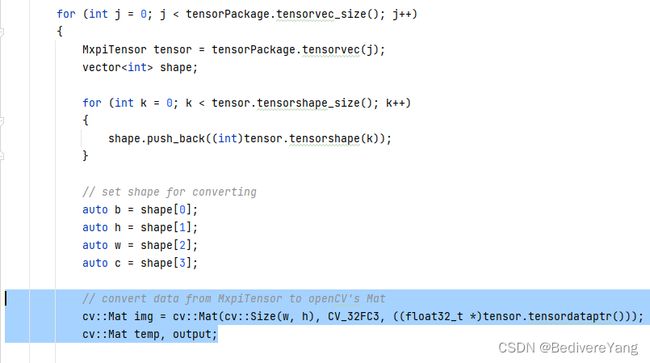
用如下函数调用可以得到位于tensorPackageList[i][j]的tensor。

- 转换成OpenCV的Mat格式
上一步骤中得到的tensor有tensorStr的成员变量,照理应当可以仿照buffer的使用从中得到数据,但我在这一步是失败了的。但是tensor还有tensordataptr数据指针,因此也可以使用指针获得数据,其结果是等价的。使用指针获取数据需要指定其形状,因此可以使用tensor.tensorshape()获取tensor的形状。
- 将数据映射回[0,255]并转换成RGB格式保存
因为本模型在图像的标准化上是标准化为[-1,1],因此在结果处理时给alpha和beta分别赋127.5,使用OpenCV的converTo函数映射回[0,255]。

8.4 编译
检查完CMakeLists.txt无误后,点击顶部菜单栏的Build>Edit Build Configuration,新建一个构建配置。
在Build Configuration界面,点击+号新建一个默认配置,如果成功连接服务器,ToolChain一般会自动检测到服务器的编译工具链。
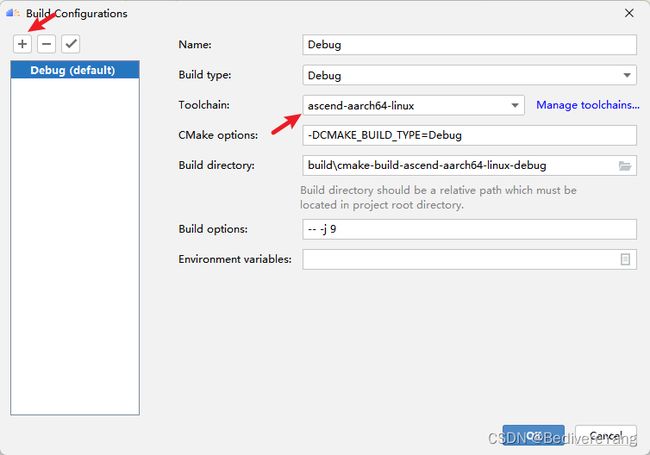
点击OK保存配置,然后点击Build>Build Project,开始构建编译插件。

构建过程是在远程服务器上完成的,构建成功后,MindStudio会将远程服务器端生成的插件同步到本地。

我们编译生成的插件一般是so文件,将插件文件上传至服务器端,并将该so文件的权限改为640,否则在运行时权限检查会报错。然后将其拷贝至服务器端的${MX_SDK_HOME}的lib/plugins下。
chmod 640 ${插件文件名}
cp ${插件文件名} ${MX_SDK_HOME}/lib/plugins
9 运行
在3.2 安装MindStudio中,按照给出的教程连接,我们已经将本地Windows的MindStudio与远程服务器连接。
首先准备好数据集,并修改main.py里的DATA_PATH为数据集路径。
接下来,点击顶部菜单栏的Tools>Deployment>Upload,将项目与远程服务器同步。

当然,也可以勾选Automatic Upload,这会让MindStudio在文件更改后就会上传到远程服务器。
然后点击编辑运行配置,选中main.py为Excutable文件。然后保存配置,点击运行。

这是运行成功的控制台输出:
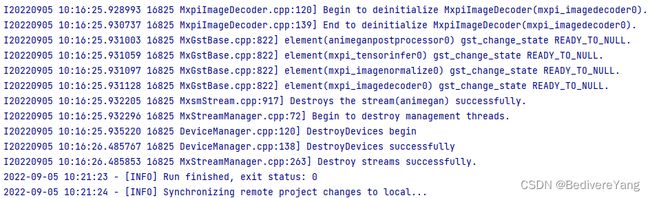
等待运行成功后,MindStudio会自动同步远程项目,但是若是自动同步失败或者没有运行,可以点击菜单栏中的Tools>Deployment>Download,下载服务器里的项目,应当包含模型的输出。
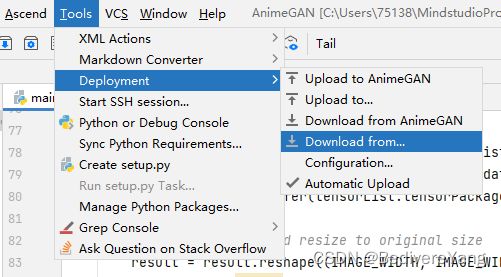
然后点击results文件夹,查看模型的输出。


10. FAQ
10.1 后处理库权限问题
问题描述:
提示Check Owner permission failed: Current permission is 7, but required no greater than 6.
解决方案:
后处理库so文件权限太高,需要降低权限至640,参见8.4 编译一节有关编译的内容。
chmod 640 ${插件文件名}
10.2 MindStudio可视化编排问题
问题描述:
使用可视化流程编排时,控制台输出“……\AllPluginsInfo.json (系统找不到指定的文件。) ”
解决方案:
这是因为使用可视化流程编排时,MindStudio需要在MindX SDK中搜集插件信息并下载。
可以尝试手动进入${MindX SDK安装目录}/bin执行InspectAllPlugins,该程序会在当前目录生成AllPluginsInfo.json,手动下载并放置于项目根目录中。

如果还不行,可以尝试在~/log/mindxsdk中检查是否有deployment.log,若没有,手动新建一个空白的deployment.log,再次运行InspectAllPlugins,然后再在MindSutdio重新打开pipeline文件进行同步。
