基于MindX SDK的ChineseOCR文字识别教程
b站视频案例:https://www.bilibili.com/video/BV12W4y1j7Fq/
目录
基于MindX SDK的ChineseOCR文字识别教程
1. 任务介绍
1.1. 任务场景
1.2. 任务描述
1.3. 任务目标
1.4. 环境信息
2. 模型介绍
3. MindStudio介绍
4. 开发前准备
4.1. 环境准备
4.2. 安装MindStudio 3
5. 开发过程
5.1. 工程创建
5.2. 工程结构介绍
5.3. om模型文件准备
5.4. 官方模型转onnx模型
5.5. Pipeline流程编排
5.6. 主程序开发
5.6.1 代码逻辑
5.6.2 主程序实现
5.7. 数据集准备
5.8. 运行
5.9. FAQ
5.10. 推广
1 任务介绍
1.1 任务场景
MindX SDK应用开发
1.2 任务描述
本开发样例使用MindX SDK,演示中文字体识别ChineseOCR,供用户参考。 本系统基于昇腾Atlas310卡。主要为单行中文识别系统,系统将图像进行适当的仿射变化,然后送入字符识别系统中进行识别后将识别结果输出。
1.3任务目标
在Ascend 310上能使模型成功识别手写文字图片
1.4环境信息
开发环境:Windows 10 + MindStudio 5.0.RC2
昇腾设备:Atlas 200DK
昇腾芯片:Ascend 310
服务器环境依赖软件和版本如下表:
| 软件名称 |
版本 |
| mxVision |
3.0.RC2 |
| Python |
3.9.12 |
| CANN |
5.1.RC1 |
本地环境依赖软件和版本如下表:
| 软件名称 |
版本 |
| Python |
3.7.13 |
| Docker |
1.5-2 |
Python第三方库依赖如下表:
| 软件名称 |
版本 |
| protobuf |
3.19.0 |
2 模型介绍
ChineseOCR是一个主要识别中文字符的系统。系统可以实现将字符检测结果中的文字进行识别。本方案选择使用PaddleOCR作为字符识别模型。
我们也提供了已经转换好的模型以及一些测试数据集的OBS地址:
https://mindx.sdk.obs.cn-north-4.myhuaweicloud.com/mindxsdk-referenceapps%20/contrib/OCR/model/models_ocr.zip 3 MindStudio介绍
MindStudio是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,集成了工程管理、编译器、仿真器以及命令行开发工具包,提供网络模型移植、应用开发、推理运行及自定义算子开发等功能。通过MindStudio能够进行工程管理、编译、调试、运行、性能分析等全流程开发,支持仿真环境及真实芯片运行,提高开发效率。
通过MindStudio,众智团队可以基本脱离终端命令行模式,搭配昇腾AI硬件环境(实体服务器或远端环境)体验AI开发的所有功能。并通过MindStudio后端主导的独有的负载建模和专家系统,以及可视化的数据分析来更高效的完成调优等过程。
4开发前准备
4.1MindStudio环境搭建
首先安装好CANN和MindX SDK,具体可参考如下链接:
CANN安装指导: 昇腾社区-官网丨昇腾万里 让智能无所不及
MindX SDK安装指导:
昇腾社区-官网丨昇腾万里 让智能无所不及
然后开始设置环境变量,在CANN的安装目录和MindX SDK的安装目录可以分别找到set_env.sh,它们包含了MindX SDK App所需的大部分环境变量。我们可以打开它们查看内容并且运行脚本,也可以将它们加入~/.bashrc,以便每次进入bash时不用重新手动运行。
![]()
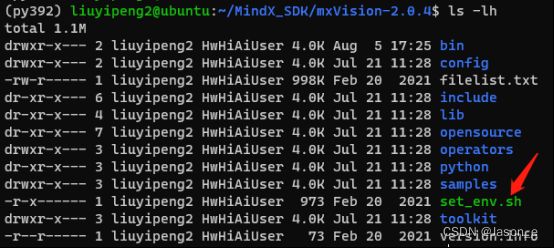
编辑bashrc,vi ~/.bashrc,在bashrc中应用这两个脚本,然后重启bash。
vi ~/.bashrc
# 在bashrc中加入以下两行并保存
source ${SDK安装路径}/set_env.sh
source ${CANN安装路径}/set_env.sh
# 保存后重启bash
bash
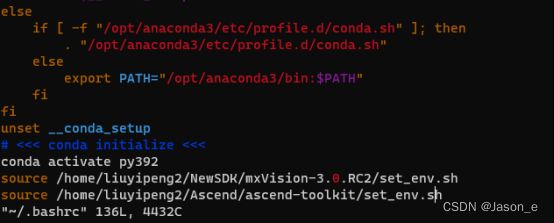
MindStudio的主要安装依赖项有CANN,若需开发MindX SDK应用,还需MindX SDK的支持。
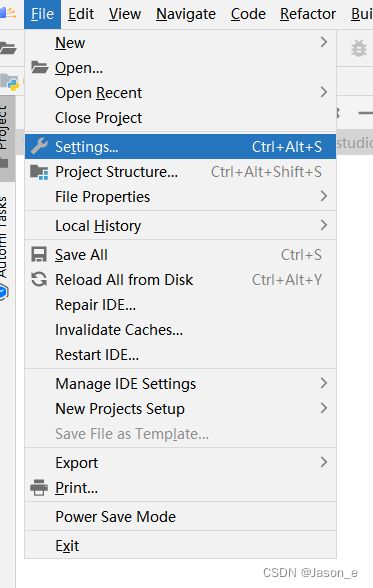
我们点开setting设置,点击install SDK进行CANN和SDK设置

如果我们在Windows环境下开发。基于MindStudio的SDK应用开发环境搭建可以参考: 昇腾社区-官网丨昇腾万里 让智能无所不及
4.2 onnx模型文件准备
步骤一:首先用户需下载大于等于1.8.0以上版本的paddle包和1.7.0以上版本的onnx,用户可以通过以下两种方式进行安装
安装方式一:
pip install paddle2onnx==0.3.1 [--user]
安装方式二:
git clone https://github.com/PaddlePaddle/paddle2onnx.git
python setup.py install
步骤二:进入下载的目录/models/paddleocr/执行以下命令

paddle2onnx --model_dir ./ch_ppocr_server_v2.0_rec_infer/ --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./ch_ppocr_server_v2.0_rec_infer.onnx --opset_version 11 --enable_onnx_checker True
如果执行成功则会生成转化成功的onnx模型,如果出现E16005错误
E16005: The model has [2] [--domain_version] fields, but only one is allowed.
则调用keep_default_domain这个接口修改onnx解决,参考链接网址为镇亮/MagicONNX
5 开发过程
5.1 工程创建
下载MindStudio压缩包解压打开后进入MindStudio的安装目录,选择bin目录下的MindStudio64.exe,打开MindStudio。

点击Ascend App,选择项目路径,然后点击下一步选择昇腾应用工程类型。
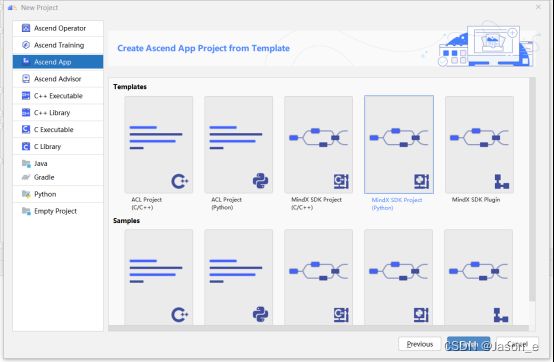
选择如图所示,选择Python框架的MindX SDK应用工程,点击Finish完成创建。
5.2 工程结构介绍
本工程结构包含如下文件:

│ README.md
│ main.py # 主程序
│ chineseocr.pipeline # pipeline文件
├─dataset #输入图片
├─output #输出图片
5.3 om模型文件准备
MindX SDK支持的模型格式是om模型,因此使用之前须进行模型转换。首先需要下载官方的paddle模型文件,再使用官方的转化工具将模型转化为onnx模型。
若下载我们提供的已经转化完成的om模型,则可以跳跃至5.4阅读。
首先在PaddleOCR下载官方的的pdparams模型文件。
5.4 onnx模型转om模型
将onnx文件上传到CANN所在服务器后,打开MindStudio,在顶部菜单栏中选择“Ascend>Model Converter”,打开图形化模型转换工具。

在Model File中选中上传至服务器的onnx模型。Model Name一栏可自行更改,其为输出的om模型名。Target Soc Version选中目标平台,这里我们选择Ascend310。Output Path为输出路径,模型转换工具会将转换后的一些文件拷贝至该位置。
更改Input Format和Input Nodes,一般情况下,选择好PB文件后,该栏会自动和模型匹配,若是因某些原因没有自动匹配,需自行选定。
旧版本的MindX SDK的已有插件中的推理插件mxpi_tensorinfer暂不支持动态分辨率模型,因此即使原模型支持动态分辨率,也需要在此步将input可能的分辨率固定下来。
若需要动态分辨率支持,可以使用mxVision 3.0.RC2及以上的版本,经实验确定推理插件mxpi_tensorinfer已经支持动态分辨率模型。
Input Nodes中的Shape为-1的一项表明该维度是动态的,因此可以根据需要将N取值为-1以实现动态Batch,或者将H,W取值 -1,以实现动态分辨率。但注意,动态分辨率和动态Batch是不能同时应用的。

最后点击Output Nodes下方的Select,会出现可视化的模型图,找到模型的最终输出节点,然后点击OK确认。
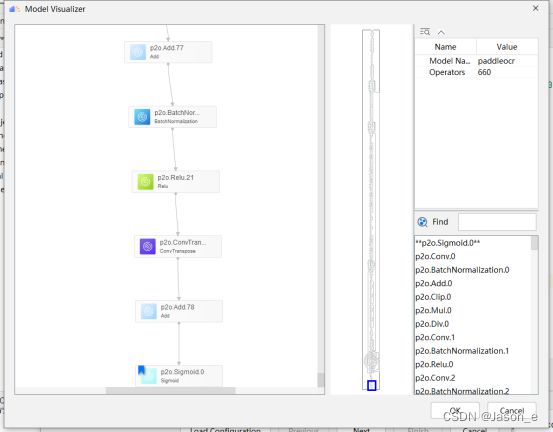
点击Next,下一步是一些数据预处理,比如转换颜色空间、裁切输入以适配模型等,可按需选择。本项目并不需要进行预处理,因此继续进行下一步。

本模型不需要设置其他参数,因此直接finish结束模型转换,转换完成。
5.5 Pipeline流程编排
MindX SDK实现功能的最小粒度是插件,每一个插件实现特定的功能,如图片解码、图片缩放等。将这些插件按照合理的顺序编排,实现相应的功能。
我们将这个配置文件叫做pipeline,以JSON格式编写,用户必须指定业务流名称、元件名称和插件名称,并根据需要,补充元件属性和下游元件名称信息。
我们在MindStudio中可以进行可视化流程编排。在顶部菜单栏中选择“Ascend>MindX SDK Pipeline”,打开空白的pipeline绘制界面,可以在左方插件库中选中所需的插件,并进行插入插件、修改参数等操作。

点击MindX SDK Pipeline新建pipeline
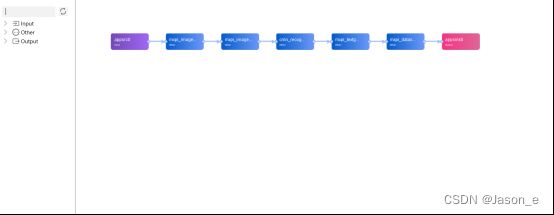
本模型使用的插件和工作流程如下表所示
| 序号 |
子系统 |
功能描述 |
| 1 |
图片输入 |
调用appsrc接口输入图片 |
| 2 |
图像解码 |
调用mxpi-imagedecoder接口对图像解码 |
| 3 |
模型推理 |
调用mxpi-tensorinfer接口对图像进行推理 |
| 4 |
模型后处理 |
将图像推理后结果进行最后的处理输出结果 |
| 5 |
数据序列化 |
用mxpi_dataserialize插件对数据进行序列化输出结果 |
本项目Pipeline的文本格式如下:
{
"chineseocr": {
"stream_config": {
"deviceId": "0"
},
"appsrc0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsrc",
"next": "mxpi_imagedecoder0"
},
"mxpi_imagedecoder0": {
"props": {
"dataSource": "appsrc0",
"deviceId": "0",
"cvProcessor": "opencv",
"dataType": "uint8",
"outputDataFormat": "RGB"
},
"factory": "mxpi_imagedecoder",
"next": "mxpi_imageresize0"
},
"mxpi_imageresize0": {
"props": {
"dataSource": "mxpi_imagedecoder0",
"resizeType": "Resizer_Stretch",
"cvProcessor": "opencv",
"resizeHeight": "32",
"resizeWidth": "320"
},
"factory": "mxpi_imageresize",
"next": "crnn_recognition"
},
"crnn_recognition": {
"props": {
"dataSource": "mxpi_imageresize0",
"modelPath": "./model/ch_ppocr_server_v2.0_rec_infer_bs1.om"
},
"factory": "mxpi_tensorinfer",
"next": "mxpi_textgenerationpostprocessor0"
},
"mxpi_textgenerationpostprocessor0": {
"props": {
"dataSource": "crnn_recognition",
"postProcessConfigPath": "./cfg/crnn.cfg",
"labelPath": "./cfg/ppocr_keys_v1.txt",
"postProcessLibPath": "./cfg/libcrnnpostprocess.so"
},
"factory": "mxpi_textgenerationpostprocessor",
"next": "mxpi_dataserialize0"
},
"mxpi_dataserialize0": {
"props": {
"outputDataKeys": "mxpi_textgenerationpostprocessor0",
"deviceId": "0"
},
"factory": "mxpi_dataserialize",
"next": "appsink0"
},
"appsink0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsink"
}
}
}
next和dataSouce制定了各个元件之间的连接关系,om模型地址需要放在推理插件里面,推理插件输出结果不一定可以可视化,所以需要后处理元件对推理插件进行处理输出。
5.6 主程序开发
5.6.1代码逻辑
接下来就是应用主程序的编写。本项目主程序的逻辑如下:
- 初始化流管理。
- 加载图像,对图像进行预处理以符合动态分辨率模型的档位。
- 向流发送图像数据,进行推理。
- 获取pipeline各插件输出结果,将结果写入文件。
- 销毁流。
5.6.2 主程序实现
下图是本程序的需要的依赖库,其中StreamManagerApi是MindX SDK自带的,如果在Windows本地进行编辑代码,需要同步MindX SDK,将这些库文件下载到本地,才可以有代码补全提示等,并消去MindStudio对于没有找到对应库的提示。由于运行程序是在远端安装了CANN和MindX SDK的昇腾设备上进行的,因此这些错误提示可以忽略。
另外,如果在昇腾设备上运行程序时报找不到OpenCV等第三方库的错误提示,可以使用pip或者conda安装,但如果是报找不到StreamManagerApi等MindX SDK自带的库的错误提示,此时要确认环境变量是否配置正确,${PYTHONPATH}这个环境变量用于在导入模块的时候搜索路径,配置正确会给程序指明MindX SDK自带模块的位置。配置环境变量请看第4节。
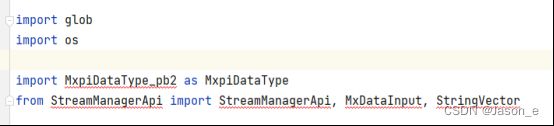
预先设置需要的全局变量以便后面使用

在程序开始前,应先检查pipeline文件是否存在且可以运行。
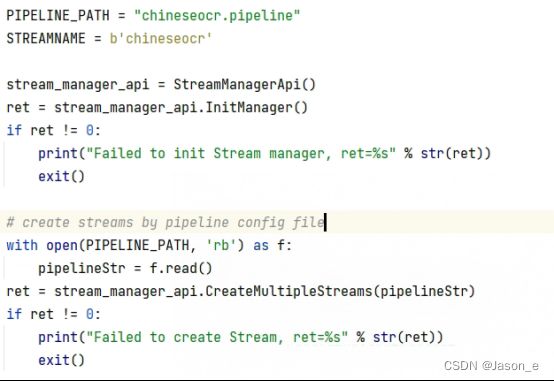
设置好文件输出路径,使图片识别结果的保存到txt文档中,以便后续与标签的比对。

设置好输入路径的图片和标签:

发送数据时需要将数据赋给dataInput,然后指定流名,指定输入插件的插件名称,调用SendData发送。推理结果在终端输出打印台同时显示:
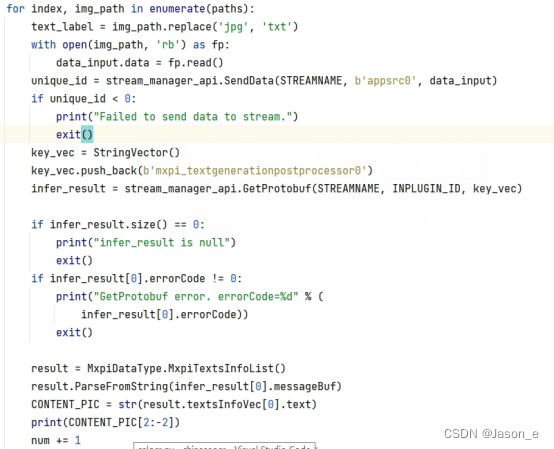
将打印结果写入文档,并与标签进行文字比对,输出识别结果的相似度:
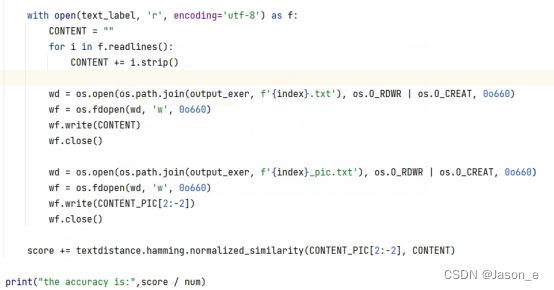
数据完成输出后后,应当回收并销毁所创建的流:

其中发送数据和接收数据这一套业务流数据对接接口共有4套,但有些接口是可以不用成套使用的。比如本程序中的SendData是和GetResult配对的,但是本程序使用的获取结果的接口是GetProtobuf,这些根据实际情况使用即可。详细的使用说明可以查看官方文档:昇腾社区-官网丨昇腾万里 让智能无所不及。
发送数据后的处理是对用户透明的,用户只需要确认数据发送成功后,就可以尝试获取结果。在GetProtobuf这个接口中,我们需要指定流名称、对应的输入接口的编号,以及要获取结果的插件的插件名。
5.7 数据集准备
数据集为GitHub - chineseocr/chineseocr: yolo3+ocr官方提供的OCR手写数据集,直接下载到本地即可
5.8 运行
在3.2中,按照给出的教程连接,我们已经将本地Windows的MindStudio与远程服务器连接。
准备好数据集后,修改main.py里的DATA_PATH为自己放置数据集的路径。

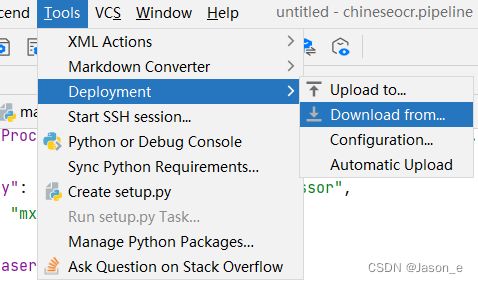
接下来,点击顶部菜单栏的Tools>Deployment>Upload,将项目与远程服务器同步。

当然,也可以勾选Automatic Upload,这会让MindStudio在文件更改后就会上传到远程服务器。
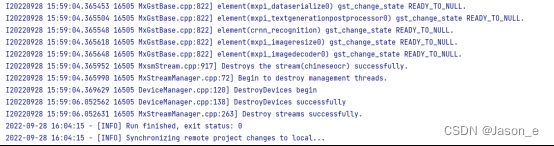
然后点击编辑运行配置,选中main.py为Excutable文件。然后保存配置,点击运行。

这是运行成功的控制台输出:
等待运行成功后,MindStudio会自动同步远程项目,但是若是自动同步失败或者没有运行,可以点击菜单栏中的Tools>Deployment>Download,下载服务器里的项目,应当包含模型的输出。
测试图片输入(放置在dataset文件夹内):
![]()
测试图片输出(控制台的打印输出)
![]()
因为本项目要测试识别文字的精度,因此需要额外将识别结果写入文件,保存后与标签文件进行相似度计算。
5.9 FAQ
输入图片大小与模型不匹配问题
问题描述:
运行失败,错误提示:E20220826 10:05:45.466817 19546 MxpiTensorInfer.cpp:750] [crnn recognition][1001][General Failed] The shape of concat inputTensors[0] does not match model inputTensors[0]
解决方案:
在imagedecode插件,设定解码方式的参数为opencv,选择模型格式为RGB,然后再imageresize插件里面设定o解码方式为opencv
5.10 推广
昇腾(Ascend)开发者论坛面向开发者提供的AI计算平台,包含计算资源、运行框架以及相关配套工具等,这里有昇腾专家在线答疑,欢迎开发者来昇腾论坛学习和交流。
链接地址:华为云论坛_云计算论坛_开发者论坛_技术论坛-华为云 (huaweicloud.com)