hadoop基础-Yarn的基本配置-详细过程
一、预备知识:
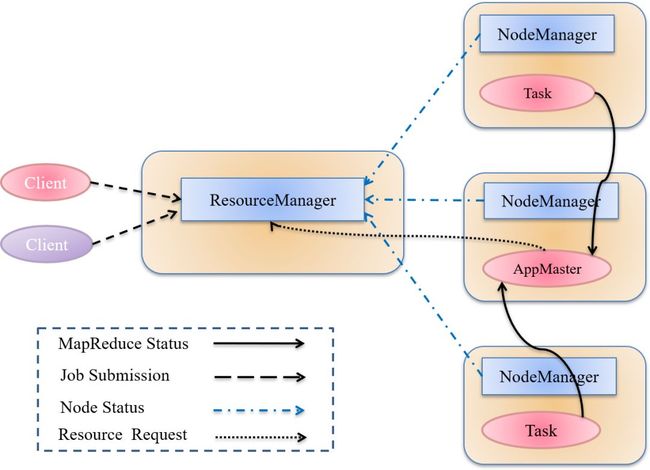
1、yarn的角色及其在系统栈中的位置

2、角色和交互
1. Client 向ResourceManager(RM)提交作业,RM为该作业启动 AppMaster。在作业执行过程中,Client也可以通过RM结束作业。
2. AppMaster(ApplicationMaster)向ResourceManager申请作业需要的计算资源(一组容器),计算任务结束后向RM登记释放容器的资源。
3. NodeManager向ResourceManager汇报节点状态,领取待执行的任务。
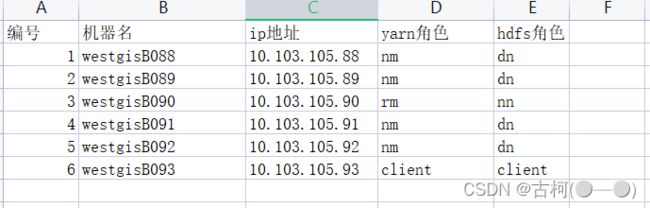
3、集群的节点配置:
二、yarn的基本配置:
1、在配置yarn时需要先配置好hdfs
这是本博主的hdfs的安装配置
(14条消息) hadoop基础hdfs集群的安装配置_古柯(●—●)的博客-CSDN博客
2、和HDFS的安装配置一样,先配置好主节点,然后将配置文件远程拷贝到每个从节点。此处重点关注两个配置文件。
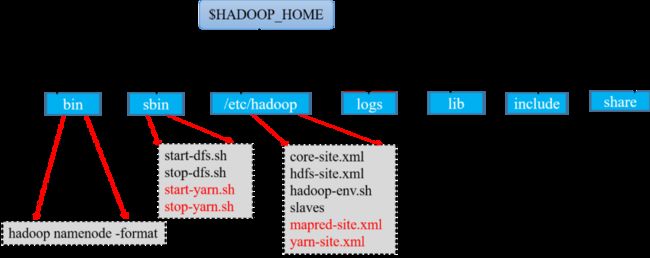
图1-3Yarn相关配置文件和脚本
图1-3中红色部分代表与Yarn相关的配置文件和执行脚本。与资源管理和分配相关的参数在yarn-site.xml中配置,与MapReduce编程模型相关的参数配置在mapred-site.xml中。start-yarn.sh和stop-yarn.sh分别代表启动和停止Yarn。
3、 配置mapred-site.xml
mapreduce.framework.name
yarn
/*该配置项表示使用Yarn框架来管理MapReduce程序*/
4、配置yarn-site.xml
关于Yarn的基本配置项有六个参数,表1-1描述了这些参数的名字和对应的物理意义。
表1-1基本参数配置项及其意义
| 序号 |
参数名 |
物理意义 |
| 1 |
yarn.nodemanager.aux-services |
NodeManager上运行的附属服务,配置成mapreduce_shuffle才可以跑MapReduce程序 |
| 2 |
yarn.resourcemanager.address |
RM暴露给客户端的地址,用于提交进程、结束进程 |
| 3 |
yarn.resourcemanager.scheduler.address |
RM暴露给AppMaster的地址,用于申请、释放资源 |
| 4 |
yarn.resourcemanager.resource-tracker.address |
RM暴露给NodeManager的地址,汇报心跳、领取任务 |
| 5 |
yarn.nodemanager.memory-mb |
NodeManager所在节点(可分配给Yarn的)最大可使用内存 |
| 6 |
yarn.nodemanager.cpu-vcores |
NodeManager所在节点(可分配给Yarn的)最大可使用CPU核心数 |
-----yarn-site.xml 具体配置内容如下----
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
westgisB090:8032
yarn.resourcemanager.scheduler.address
westgisB090:8030
yarn.resourcemanager.resource-tracker.address
westgisB090:8031
yarn.resourcemanager.resource-tracker.address
westgisB090:8031
yarn.nodemanager.memory-mb
8GB
yarn.nodemanager.cpu-vcores
4
---yarn-site.xml 具体配置内容------
/*此处westgis101为ResourceManager所在节点的机器名*/
/*最后两个配置参数要考虑其它守护进程也需要CPU和内存,不能100%都给Yarn*/
5、集群的操作和查看
5.1、启动集群
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
5.2、查看集群
HDFS
http://10.103.105.90:50070
/*westgis101为NameNode所在节点的机器名*/
YARN
http://10.103.105.90:8088
/*westgis101为ResourceManager所在节点的机器名*/
5.3、 停止集群
$HADOOP_HOME/sbin/stop-yarn.sh
$HADOOP_HOME/sbin/stop-dfs.sh