阿里天池新人赛——二手车交易价格预测(赛题理解)
阿里天池新人赛——二手车交易价格预测-Task2 数据分析
概述
本次新人赛是Datawhale与天池联合发起的0基础入门系列赛事第一场 —— 零基础入门数据挖掘之二手车交易价格预测大赛。赛事以二手车市场为背景,要求选手预测二手汽车的交易价格。这是典型的回归问题适合小白上手。
探索性数据分析 EDA(Exploratory Data Analysis)
在对赛题有初步的了解和认识以后进行初步的分析,判断数据缺失和异常 ,数据总览,了解预测值的分布等。
目录
1.感悟
2.内容(学习教学代码复述)
1.感悟
经过小雨老师和ml老师的讲解,让我对数据探索性分析有了初步的认识和了解,也让我对数据挖掘的baseline有了初步的认识。在几天的突击学习中将python的numpy,pandas,matplotlib,sklearn等库接触并浏览了一番,依赖着这些临阵磨枪的成果,通过发的讲义上的注释,可以粗略的理解样例中的代码含义,也为我进一步的学习打下了基础。虽然老师说的一些术语我可能还不是很熟悉但是在后面的学习中可以加深印象。
后面的内容我将复述一遍代码并体会代码的含义。
复述的内容在自己的 jupyter notebook运行此处以图片形式上传
2.内容
1.先导入库,然后导入数据。
下面展示一些 内联代码片。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
car_Train_data = pd.read_csv(r'./used_car_train_20200313.csv', sep=' ')
car_Test_data = pd.read_csv(r'./used_car_testA_20200313.csv', sep=' ')
数据的含意
name - 汽车编码
regDate - 汽车注册时间
model - 车型编码
brand - 品牌
bodyType - 车身类型
fuelType - 燃油类型
gearbox - 变速箱
power - 汽车功率
kilometer - 汽车行驶公里
notRepairedDamage - 汽车有尚未修复的损坏
regionCode - 看车地区编码
seller - 销售方
offerType - 报价类型
creatDate - 广告发布时间
price - 汽车价格
v_0’, ‘v_1’, ‘v_2’, ‘v_3’, ‘v_4’, ‘v_5’, ‘v_6’, ‘v_7’, ‘v_8’, ‘v_9’, ‘v_10’, ‘v_11’, ‘v_12’, ‘v_13’,‘v_14’(根据汽车的评 论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】
导入数据后要对数据进行初步的查看包括异常值检测等
下面展示一些 内联代码片。
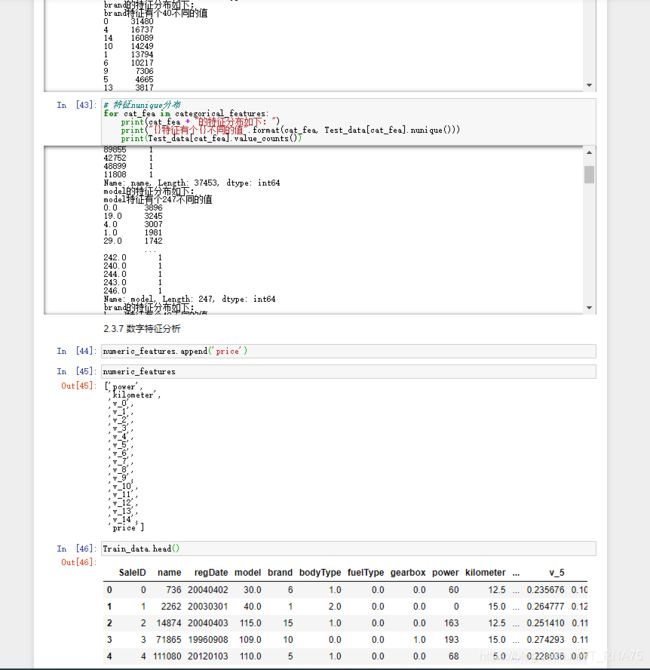
car_Train_data.shape
##(150000, 31)
car_Train_data.head()
car_Train_data.describe().T
car_Train_data.dtypes
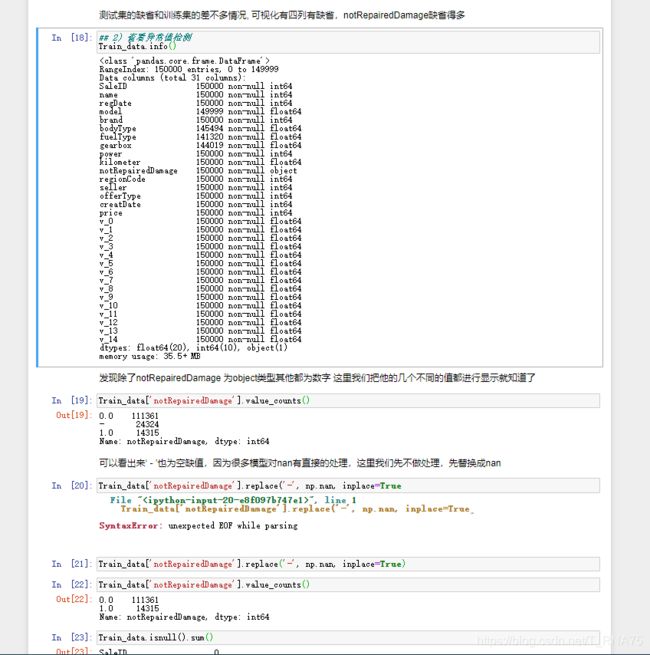
car_Train_data.info()
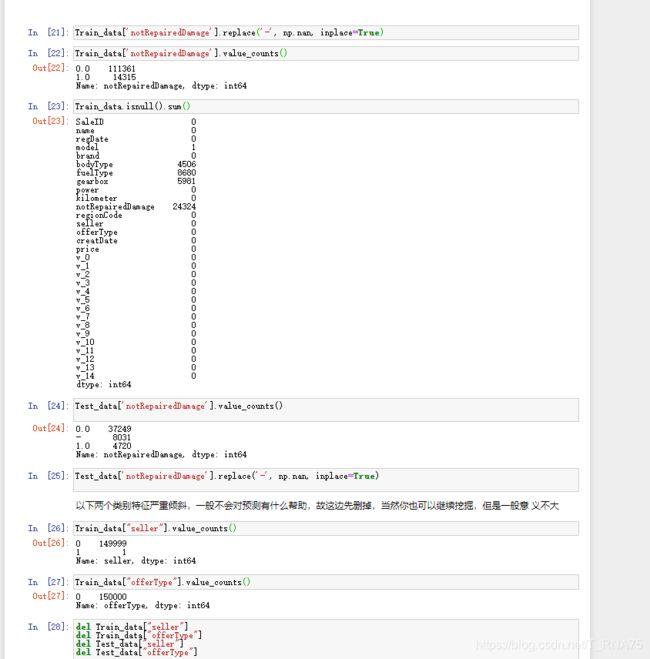
car_Train_data.isnull().sum()
上述代码的结果截图
在这里插入图片描述
进行数据的可视化分析
# nan可视化
missing = car_Train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
##
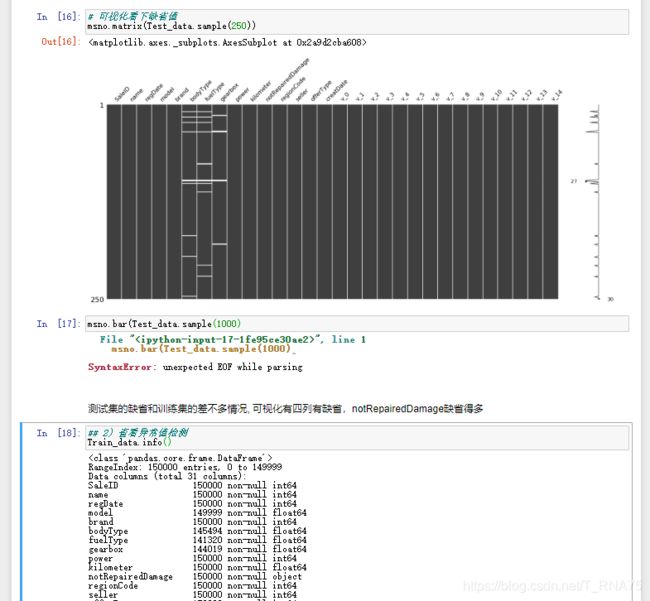
通过以上两句可以很直观的了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于 nan存在的个数是 否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果nan存在的 过多、可以考虑删掉。
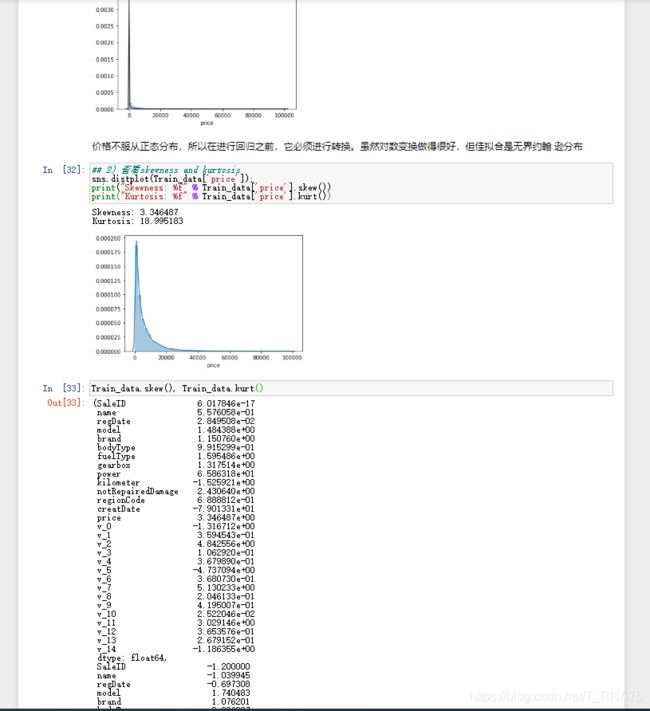
进行相关性分析