轻松入门基因表达式编程 (GEP)
0 引言
基因表达式编程 GEP (Gene Expression Programming) 是一种基于生物基因结构和功能发明的一种新型自适应演化算法。GEP 是从遗传算法(geneticalgorithms ,简称 GAs)和遗传程序设计(genetic pro2gramming ,简称 GP)中发展而来,它在吸收了二者优点的同时,又克服了二者的不足之处,其显著特点就是可以利用简单编码解决复杂问题。
1. 基本概念
1.1 终点符号集
\quad\quad 终点符号集是提供给系统值的最末端结构。终点符自己提供信息,但不处理另外的信息。通常, 终点符号集包括基因表达式编程程序中的输入,常量,或者没有参数的函数。
\quad\quad 如果用树形结构来表示程序,终点符代表树的这些叶节点。当程序运行的时候,这些叶节点,要么接受外部的输入,要么自己就是一个常量,或者自己就能计算产生一个量。它们向系统提供信息,以供系统处理。
\quad\quad 本文通常用 T 或者 T G E P T_{GEP} TGEP 表示一个基因表达算法的终点符号集。用 t ∈ T t∈T t∈T 表示终点符号集中的终点符。
1.2 函数符号集
\quad\quad 函数符号集可以包括与应用有关的问题领域的运算符号,也可以包括程序设计语言中的程序构件,甚至是表示系统中间层次的一种符号。
\quad\quad 函数表示树形结构中的非叶节点。根据问题空间的描述不同,它要么接受了节点传递的信息,进行处理,要么代表一种抽象自了树的一种中间层次的结构。
\quad\quad 本文通常用 F F F 或者 F G E P F_{GEP} FGEP 表示一个基因表达算法的函函数符号集。每一个函数 f ∈ F f∈F f∈F 记为:
f ( x 1 , x 2 , ⋅ ⋅ ⋅ , x m ) f(x_1, x_2, ···, x_m) f(x1,x2,⋅⋅⋅,xm)
\quad\quad 其中参数个数记为:
λ ( f ) = m \lambda(f) = m λ(f)=m
\quad\quad 函数参数的最大个数为函数集合的参数数量,记为:
λ ( F ) = n = m a x ( λ ( f ) ∣ f ∈ F ) \lambda(F) = n = max(\lambda(f)~ |~ f \in F) λ(F)=n=max(λ(f) ∣ f∈F)
\quad\quad 后续 GEP 基因的限制条件会用到。
1.3 表达式树(表现型)
表达式的结构用树形结构来描述,叶节点为终点符号集,内部节点为函数符号集。
例如 1.2 有 G E P = ⟨ F , T ⟩ GEP = \langle F, T\rangle GEP=⟨F,T⟩,其中
F = { + , − , × , ÷ , s i n } F = \{+, -, ×, ÷, sin\} F={+,−,×,÷,sin}
T = { a , b , c , d } T = \{a, b, c, d\} T={a,b,c,d}
数值表达式为:
s i n ( ( a + b ) ( c − d ) ) (1.2) sin((a + b)(c - d)) \tag{1.2} sin((a+b)(c−d))(1.2)
的表达式树如图 3.1 所示:

1.4 K - 表达式
\quad\quad 将表达式树转化为表达式的过程称为线性化。最常见的线性化方式就是采用先序,中序或者后序遍历序列来表示表达式。因为运算符优先级和结合顺序的原因,中序遍历井不能完全如实地反映原表达式。所以,很少有进化算法将中序遍历序列作为遗传编码。而先序和后序遍历序列则能够完全如实地反映原表达式,在某些改进的遗传编程算法中,采用了先序或者后序遍历序列作为遗传编码
例 1.3 算法表达式为:
s i n ( ( a + b ) c 2 ) (1.3) sin((a + b)c^2) \tag{1.3} sin((a+b)c2)(1.3)
表达式树如图 3.2 所示。(b):树的先序遍历结果。 (c):后续遍历结果

\quad\quad K-表达式: 对于定义在 G E P = ⟨ F , T ⟩ GEP = \langle F, T\rangle GEP=⟨F,T⟩ 上的表达式树,对一棵表达式树,按照从上到下,从左到右的顺序遍历,所得到的序列,称为表达式树的 K-表达式。即上图 (d) 所示
1.5 基因型 → \to → 表现型(K-表达式 → \to → 表达式树)
例 1.4 有 K-表达式

其中位于表达式第一个位置的 Q 代表平方根函数 \sqrt{} ,S 代表 sin 函数
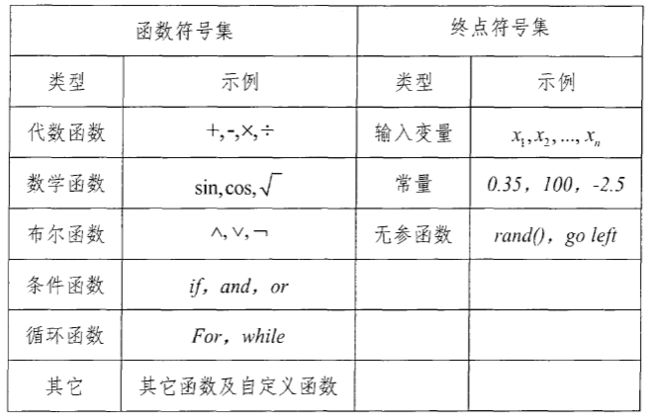
首先位置 0 的 Q 位于根节点:
由于函数 \sqrt{} 仅有一个函数,于是,节点 Q 仅有一个子节点,即K-表达式中位于位置 1 的符号 +
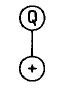
加法运算符有两个参数,于是,下一行应该放置两个节点,用位置 2,3 的两个节点 *、+ 填充:
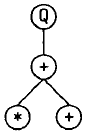
目前,最下面一行的节点有两个了,两个节点都代表函数,并且都有两个参数,用 K-表达式中的接下来 4 个符号 b、S、*、a 从左到右填充,得到:

新添加的一行出现了两个终节点 b、a,它们没有子节点,而剩余的两个节点 S、+,分别有 1,2 个参数,继续用 K-表达式的剩余部分填写:

最后,得到表达式树:
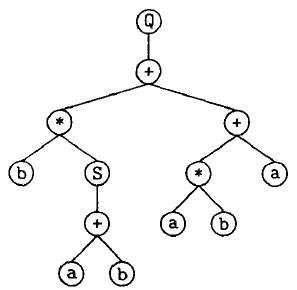
此表达式树所表达的公式为:
b ⋅ s i n ( a + b ) + ( a ⋅ b + a ) \sqrt{b·sin(a + b) + (a · b + a)} b⋅sin(a+b)+(a⋅b+a)
\quad\quad K-表达式的意义: 从K-表达式的解码过程看,无论 K-表达式是如何编码的,都一定能按照步骤一步 一步进行解码。同时,只要K-表达式的长度足够,就一定能解码完成,表示出一 棵完整的表达式树。这些特点使得K-表达式作为遗传编码具有极大的灵活性。进化过程中的各种算子不必采用特别复杂的设计。就能保证产生的新的染色体仍然能合法地解码为完整的表达式树。
1.6 基因编码(基因型)✨✨✨
\quad\quad 如果 K-表达式长度不够,或者说, K-表达式不完整,解码算法中可能没有足够的符号用于构造表达式树,构造的表达式树将是不完整的,也就不能表示一个表达式的完整意义。所以, 任意的符号串并不能当成 K-表达式作为遗传编码(基因型)。只有完整的 K-表达式才能解码为一个表达式,也才能够作为遗传编码。 如图 3.3 所示,K-表达式 S*+^ abc 并不能解码为一个合法的表达式树。
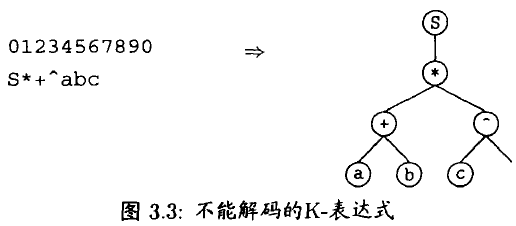
\quad\quad Candida 在其提出的 GEP 算法中对 K-表达式作为遗传编码做了一定的限 制,使得 K-表达式一定能解码为一个表达式,并此将 K-表达式作为遗传编码,如下:
定义 GEP 基因:
(1)基因总长度: l = h + t l = h + t l=h+t。
(2)有 G E P = ⟨ F , T ⟩ GEP = \langle F, T\rangle GEP=⟨F,T⟩,则 GEP 基因满足下列条件:
t = h × ( n − 1 ) + 1 (1) t=h×(n-1)+1 \tag{1} t=h×(n−1)+1(1)
(3)前 h 个符号 a 满足 a ∈ F ∪ T a \in F \cup T a∈F∪T,后 t t t 个符号 b b b 满足 b ∈ T b \in T b∈T。
\quad\quad 其中 h h h 为基因头部长度, t t t 为尾部长度, n n n 为所有函数中参数的最大数目
例 3.4 在 G E P = ⟨ { + , − , × , ÷ } , { a , b } ⟩ GEP = \langle\{+, -, ×, ÷\},\{a, b\} \rangle GEP=⟨{+,−,×,÷},{a,b}⟩ 中,令头部长度 h = 8, 又 n = λ ( F ) = 2 n = \lambda(F) = 2 n=λ(F)=2,则公式 1.4 有
t = h × ( n − 1 ) + 1 = 8 × ( 2 − 1 ) + 1 = 9 (1.4) t=h×(n-1)+1 = 8 × (2 - 1) + 1 = 9 \tag{1.4} t=h×(n−1)+1=8×(2−1)+1=9(1.4)
基因总长: l = t + h = 9 + 8 = 17 基因总长: l = t + h = 9 + 8 = 17 基因总长:l=t+h=9+8=17
按照基因头部 h h h 从 ⟨ F , T ⟩ \langle F, T\rangle ⟨F,T⟩ 中选择,而基因尾部 t t t 从 ⟨ T ⟩ \langle T\rangle ⟨T⟩ 中选择:
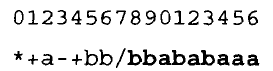
此 K-表达式是一个合法的基因表达式编程基因。它表示了如下的表达式树
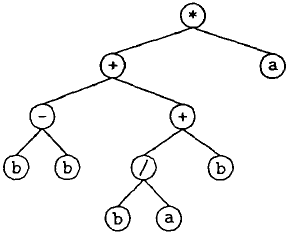
\quad\quad 实际上,仅有前面的 11 位符号出现在表达式树中,即表达式树终止于基因的第 12 位基因元素,Ferreira 将这前 11 位基因元素称为 ORF(Open Reading Frame)。本文将由 ORF 中基因元素构成的表达式,称为 ORF 表达式,可见,ORF 表达式和表达式树是一一对应的,是基因编码的有效成分。而不属于表达式的基因元素由于在转化为表现型时无效,称为基因的非编码基因元素。
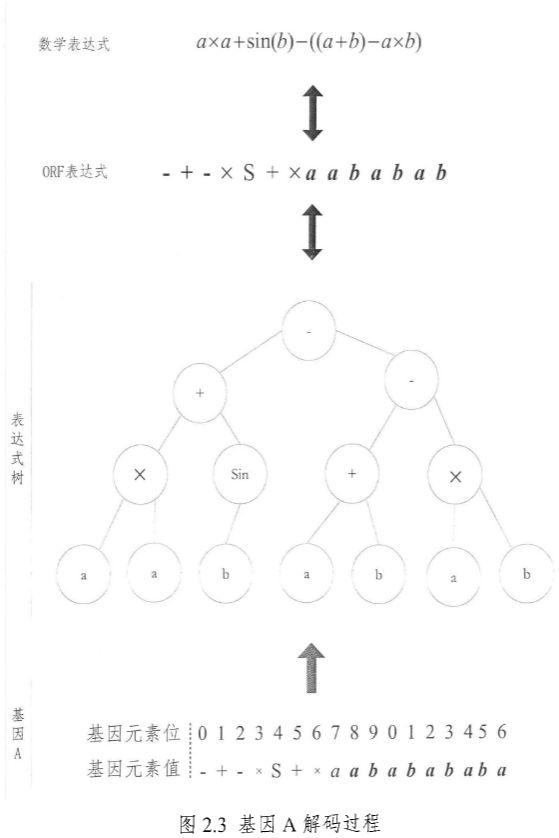
1.7 基因解码过程
图 2.3 给出了将基因解码为表达式树并转化为 ORF 表达式和数学表达式的过程
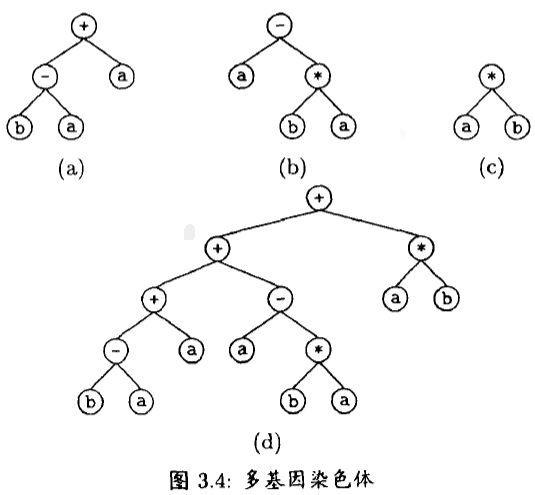
1.8 多基因(染色体)✨✨✨
\quad\quad 实践证明,如果选择一个过分长的基因编码长度,GEP 的搜索效率将很低。但是,如果基因太短,其可以表示的表达式的复杂程度就很有限。为了解决这个矛盾,Candida 模拟大自然的解决方案,引入了多基因。在一个 GEP 的 染色体中包含多个基因。然后,用一个指定称为连接函数的函数来连接这些基因解码得到的表达式树。
例如:有 G E P = ⟨ { + , − , ∗ } , { a , b } ⟩ GEP = \langle\{+, -, * \},\{a, b\} \rangle GEP=⟨{+,−,∗},{a,b}⟩,如果令基因头部长度 h = 3 h = 3 h=3,那么
t = h × ( n − 1 ) + 1 = 3 × ( 2 − 1 ) + 1 = 4 (1.5) t=h×(n-1)+1 = 3 × (2 - 1) + 1 = 4 \tag{1.5} t=h×(n−1)+1=3×(2−1)+1=4(1.5)
基因总长: l = t + h = 3 + 4 = 7 基因总长: l = t + h = 3 + 4 = 7 基因总长:l=t+h=3+4=7
每个基因都应该满足限制条件,三个基因构成的染色体表达如下:

如果指定连接函数为 “+”,则该染色体解码如图 3.4 所示。其中(a),(b),(c) 分别表示解码 3 个基因得到的表达式树 (d) 则是最终表达式树。
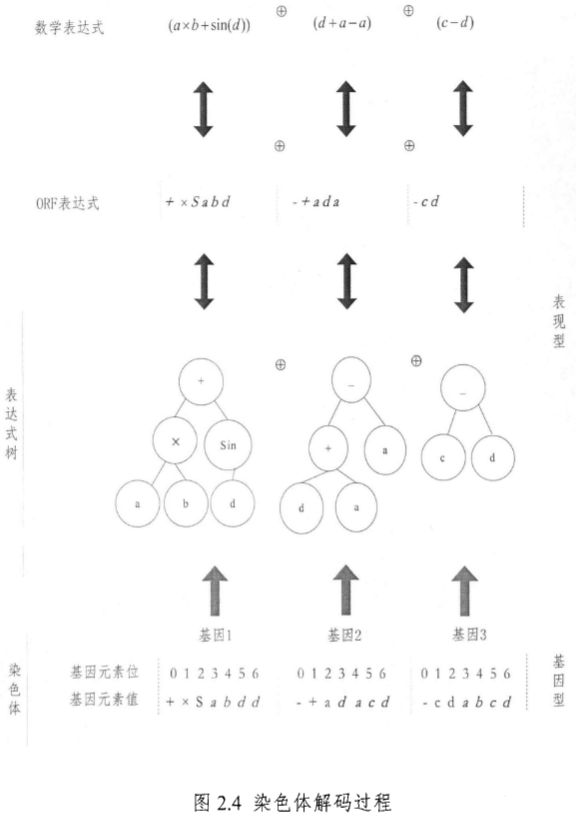
1.9 染色体解码过程
\quad\quad 由多基因可见,基本 GEP 中的染色体 (个体) 由一个以上的基因组成,基因之间用连接符 “+” 连接,连接符具体取值视情况而定,一般取 “+,-,×,÷”。
\quad\quad 图 2.4 为一个由 3 个基因组成的染色体解码为表达式树并转化为 ORF 表达式和数学表达式的过程
2.0 基本 GEP 组织结构
\quad\quad 在基本 GEP 中,种群是最高实体,且由多个等长的个体组成,个体(染色体)包含一个以上的等长基因,基因包含多个基因元素。基本 GEP 的组织结构如图 2.1 所示。其中每个染色体含有 3 个基因,基因间由虚线隔开,基因间的连接符为 “+”,基因头部长度为 3,尾部长度为 4

2.1 种群
\quad\quad 由图 2.1 可见,基本 GEP 的种群为多个个体(染色体)的集合,种群的不断进化(个体间的遗传操作)得到最优个体,而最优个体即为种群的最优解。基本 GEP 中,初始种群的染色体由解决特定问题的分别代表函数和终点的符号随机产生,因此初始种群中,基本不会出现问题的最优解个体。但是,随着初始种群的不断进化,在遗传算子的作用下,优秀个体会不断涌现,进而获得最优解。
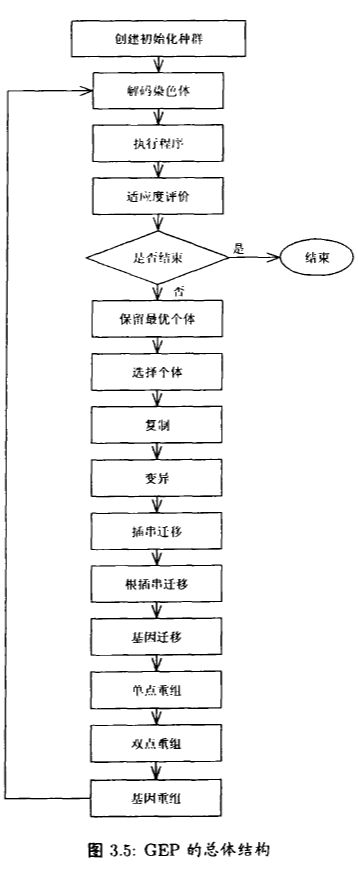
2. GEP 算法
2.1 算法框架
2.2 适应度函数
\quad\quad 适应度函数主要用来计算个体适应度,从而对表达式进行评价。基本 GEP 主要有三种适应值函数:
f i = ∑ j = 1 C t ( M − ∣ C ( i , j ) − T ( j ) ∣ ) 基于绝对误差的适应度函数 (2.1) f_i = \sum_{j = 1}^{C_t}(M - |C_{(i, j)} - T_{(j)}|) ~~~~~~~~~~~~~~~~~~~~~~~~~\text{基于绝对误差的适应度函数}\tag{2.1} fi=j=1∑Ct(M−∣C(i,j)−T(j)∣) 基于绝对误差的适应度函数(2.1)
f i = ∑ j = 1 C t ( M − ∣ ( C ( i , j ) − T ( j ) T ( j ) ∣ ) 基于相对误差的适应度函数 (2.2) f_i = \sum_{j = 1}^{C_t} (M - |\frac{(C_{(i, j)} -T_{(j)} }{T_{(j)}}|) ~~~~~~~~~~~~~~~~~~~~~~~~~\text{基于相对误差的适应度函数}\tag{2.2} fi=j=1∑Ct(M−∣T(j)(C(i,j)−T(j)∣) 基于相对误差的适应度函数(2.2)
\quad\quad 其中,M 为常量,用来决定适应值 f i f_i fi 的取值上限; C ( i , j ) C_{(i, j)} C(i,j) 表示第 i i i 个个体对于第 j j j 个样本数据的输出值; T ( j ) T_{(j)} T(j) 表示第 j 个样本的真实值; C t C_t Ct 是样本数据总数。
\quad\quad 这两种评价模型都有自身的固有缺点,用于评价两组数据符合程度的方法更多采用相关系数。在基于 GEP 的符号回归中,将适应度函数定义如下:
f i t n e s s = R 2 = 1 − S S E S S T (2.3) fitness = R^2 = 1 - \frac{SSE}{SST} \tag{2.3} fitness=R2=1−SSTSSE(2.3)
其中:
S S E = ∑ j = 1 C t ( C ( i , j ) − T ( j ) ) 2 (2.4) SSE = \sum_{j=1}^{C_t}(C_{(i, j)} - T_{(j)})^2 \tag{2.4} SSE=j=1∑Ct(C(i,j)−T(j))2(2.4)
S S T = ∑ j = 1 C t ( C ( i , j ) − T ( j ) ‾ ) 2 (2.4) SST = \sum_{j=1}^{C_t}(C_{(i, j)} - \overline{T_{(j)}})^2 \tag{2.4} SST=j=1∑Ct(C(i,j)−T(j))2(2.4)
其中, T ( j ) ‾ \overline{T_{(j)}} T(j) 为 T ( j ) T_{(j)} T(j) 的平均值,称 S S E SSE SSE 为残差平方和, S S T SST SST 为总离差平方和。
2.3 选择与复制算子
选择算子通常有轮盘赌、锦标赛、比例选择等算法。通常在遗传算法中,为了防止超级个体独霸种群,多采用锦标赛选择算子。
复制算子将被选中的个体原样复制到下一代种群
2.4 变异算子
\quad\quad 变异是 GEP 中所有具有“修饰”能力的算子中最高效的算子,是遗传多样化最重要的代理。基本 GEP 中的变异可以发生在染色体中的任何位置,对变异种类和变异次数都不作限制,但为了让染色体的组织结构保持完整,避免非法个体产生,对变异方式进行了一定的限制,如基因头部的基因元素值可以变异成任何基因元素,而基因尾部的基因元素值,只能变异成终点符号集元素,因此,GEP 的变异操作产生的新生个体都是合法的个体,这与遗传编程的变异操作会产生非法个体有明显的不同。
图 2.5 为一个含有 3 个基因的染色体的变异过程(基因头部长度为 4,基因尾部用斜黑体字符表示,变异点如虚框所示)。
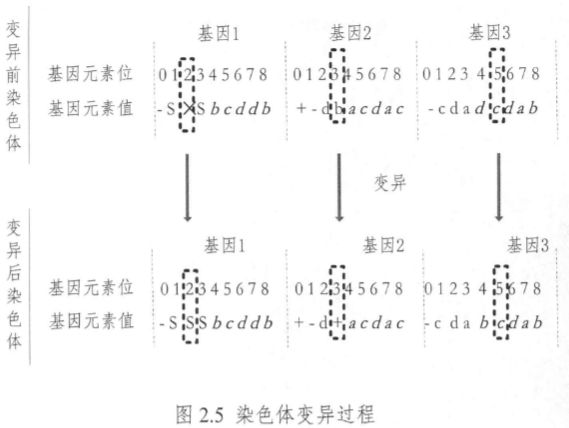
图 2.6 给出了变异前后染色体表达式树的异同(变异点如深色圆圈所示)

\quad\quad 由图 2.6 可见,假如函数符号集元素变异成了终点符号集元素或者带一个参数的函数符号集元素变异成了带两个参数的函数符号集元素(如基因 1 和基因 2),表达式树将会被彻底地修改,反之亦然;值得一提的是,假如变异发生在非编码基因元素上(如基因 3),变异将对表达式树或 ORF 表达式不产生任何改变,这种变异被称为中性变异。中性变异的积累在进化中会起到非常重要的作用,因为在其它遗传算子的作用下,这些非编码基因元素将会被激活成为基因的有效成分。
2.5 转座算子
\quad\quad 转座算子将由相邻基因元素组合起来的片段或串(转位元素),插入到染色体中其它的位置。在基本 GEP 中有三种转座算子:顺序插入转座、根转座和基因转座,下面分别介绍。
(1)顺序插入转座
\quad\quad 顺序插入转座:随机选择转位元素,将转位元素插入到基因头部除首位置的任何位置,基因头部此插入点后面的元素后移,超出基因头部长度的最后几个元素将被删除。顺序插入转座可以随机选择染色体、转位元素的开始位置、长度以及目标插入位置。图 2.7 为染色体进行顺序插入转座的过程 (基因头部长度为 7,基因尾部用斜黑体字符表示,转位元素和目标插入位置如虚框所示)。

图 2.8 给出了顺序插入转座操作前后染色体表达式树的异同转位元素如深色圆圈所示

由图 2.8 可见,基因的非编码元素在顺序插入转座算子的操作下,被激活
了
(2)根转座
\quad\quad 根转座:随机选择以函数为起始符号的转位元素,将其插入到基因头部的根位置,基因头部此插入点后面的元素后移,超出基因头部长度的最后几个元素将被删除。图 2.9 为染色体进行根转座的过程(基因头部长度为 7,基因尾部用斜黑体字符表示,转位元素和目标插入位置如虚框所示)。
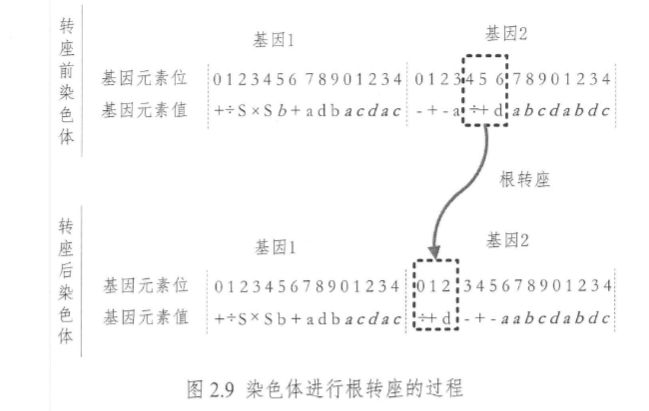
图 2.10 给出了根转座操作前后染色体表达式树的异同(转位元素如深色圆圈所示)。
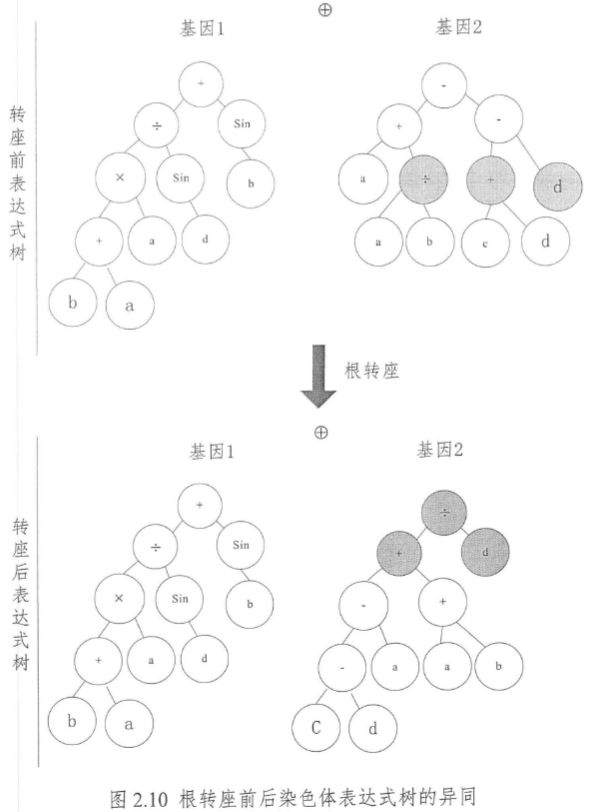
\quad\quad 可见,与顺序插入转座不同的是,根转座转位元素都是以函数为开始符号的,因此,必须在基因头部中选择。选择方法是:在基因头部中随机选择一个基因位,从这个位置向后扫描基因,直到发现函数为止,这个函数就是根转位元素的起始位置,根转位元素将被插入到基因的头部。与顺序插入转座一样,根转座可以随机选择染色体、转位元素在基因头部的开始位置、长度和目标插入位置。此外,由图 2.10 可见,由于根转座直接对基因的根部操作,其对表达式树的修改能力比顺序插入转座更强。同理,通常其转座因子取值小于等于 3。
(3)基因转座
\quad\quad 基因转座:随机选择一个基因,将其作为转位元素转移到染色体的起始位置,后续基因顺延。图 2.11 为染色体进行基因转座的过程(基因头部长度为7,基因尾部用斜黑体字符表示,转位元素和目标插入位置如虚框所示)。
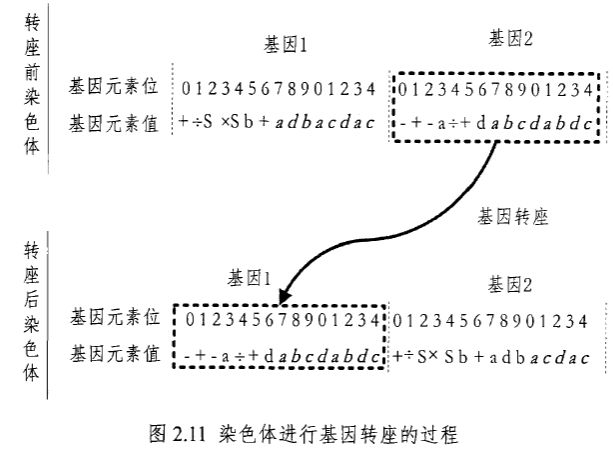
\quad\quad 图 2.12 给出了基因转座操作前后染色体表达式树的异同(转位基因如深色圆圈所示)。与其他转座方式相比较,基因转座不再保留转位元素副本,将会删除原位置的转位元素(转位基因),因此,染色体的长度仍将保持不变。此外,基因转座算子也可以随机选择染色体、转位的基因。
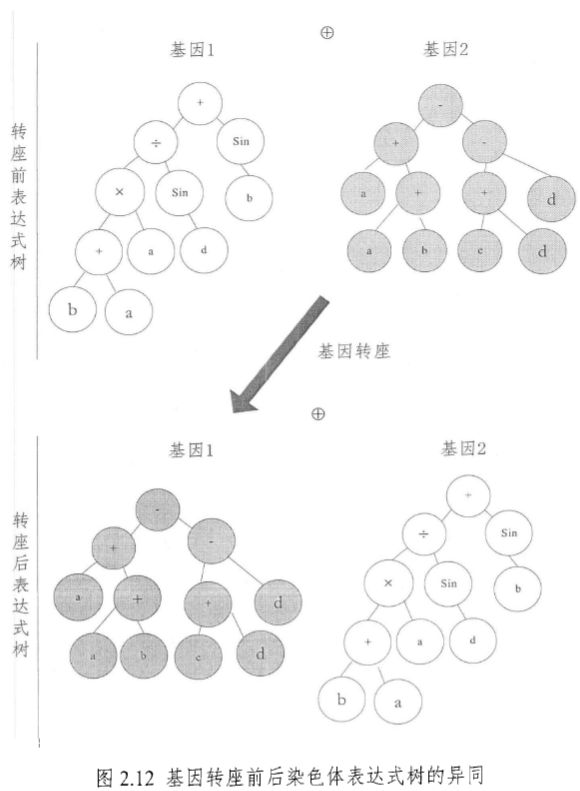
\quad\quad 综上所述,三种转座操作中,根转座引起的改变是最强烈的,顺序插入转座次之,而基因转座对连接符 “ ⊕ \oplus ⊕” 取为 “+” 的染色体则是无效的。值得注意的是,当转为元素长度为1时,转座操作变弱化为变异操作,因此,所有的转座操作均是一种宏变异操作,具有创造遗传多样性的卓越能力。
2.6 重组算子
\quad\quad GEP 中的重组是指两个随机选中的父代染色体通过相互交换部分成分,生成两个新的子代染色体的过程。基本 GEP 中有三种重组算子:单点重组、两点重组和基因重组,下面分别介绍。
(1)单点重组
\quad\quad 单点重组中,首先随机选择两个父代染色体配对,并随机产生 1 个分割点,两个父代染色体均在这个点处切开,然后相互交换切点之后的部分,形成两个子代染色体。图 2.13 为两染色体进行单点重组的过程,其中粗虚线处为切点。
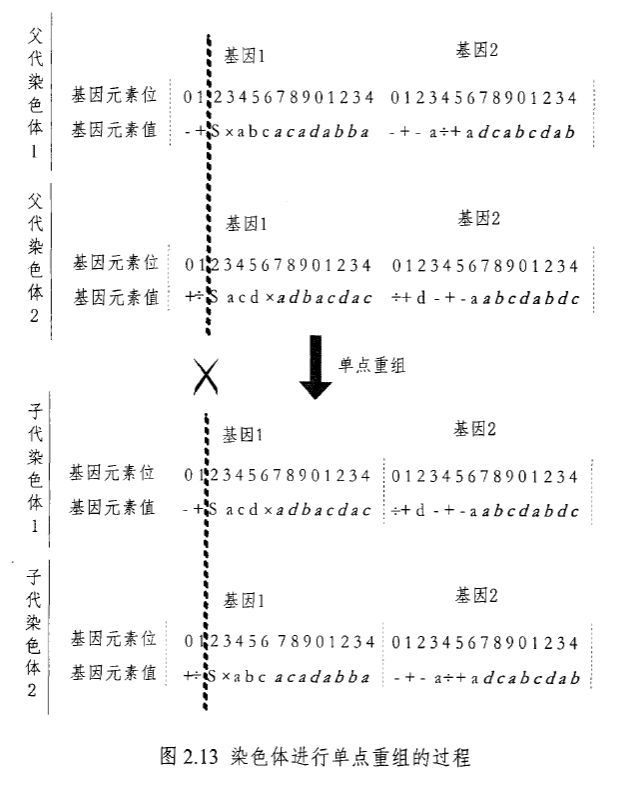
\quad\quad 图 2.14 给出基因 1 在单点重组后的表达式树变化情况,由于基因 2 在单点重组时,整个基因被完全的替换,相当于基因重组,具体见基因重组部分

(2)两点重组
\quad\quad 两点重组中,首先随机选择两个父代染色体配对,并随机产生 2 个分割点,两个父代染色体均在这 2 个点处切开,然后相互交换这两切点之间的部分,形成两个子代染色体。图 2.15 为两染色体进行两点重组的过程,其中粗虚线处为切点。
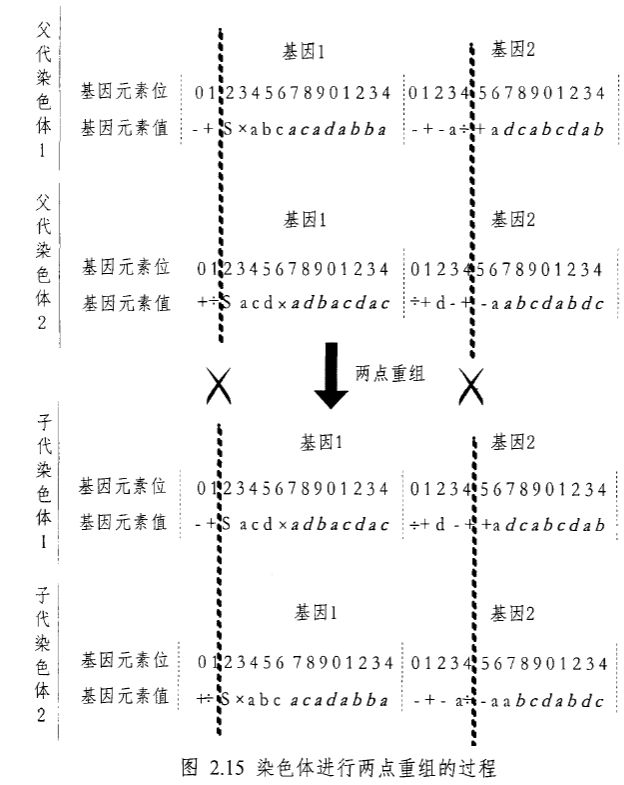
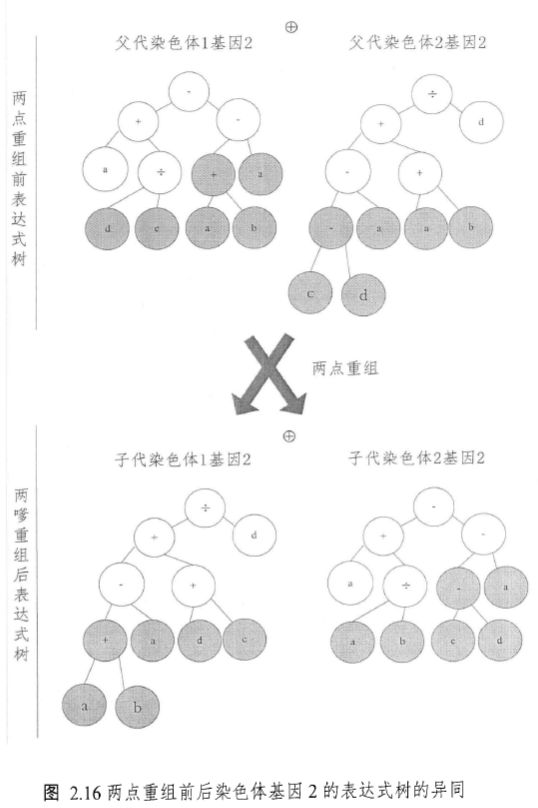
\quad\quad 此两点重组对基因 1 的表达式树的改变与单点重组类似,见图 2.14,对基因 2 的改变如图 2.16 所示。由图 2.16 可知,两点重组对基因的改造能力要比单点重组强,通常会造成多个基因的表示树改变,因此一般用于解决复杂问题。
(3)基因重组
\quad\quad 基因重组中,首先随机选择两个父代染色体配对,选择其中一个等位基因相互交换,形成两个子代染色体。图 2.17 为两染色体进行基因重组的过程,其中粗虚线处为切点。
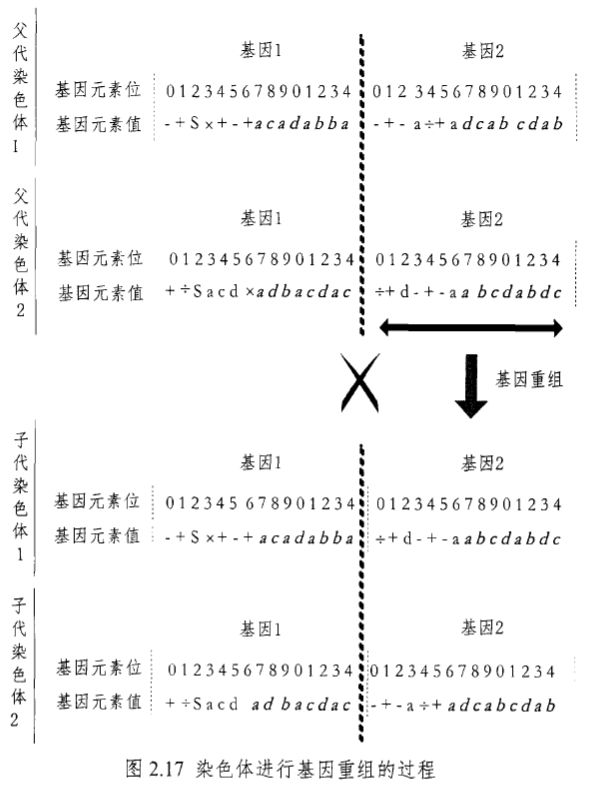
\quad\quad 综上所述,在重组操作中,由于子代染色体同时包含 2 个父代染色体中的不同基因(虽然父代有时会交换相近的部分),大多数时候将会产生新的染色体。需要强调的是,两点重组破坏性最强,因为它对遗传元素的重组最彻底,能持续破坏旧基因块,生成新基因块。而基因重组并不能产生新基因,其产生的染色体是仅仅是现存基因的不同排列和组合。
2.7 形式化定义
定义 2.1 基因(Gene)
G = ( Ω , F , T , Ω , h , f ) G = (\Omega, F, T, \Omega, h, f) G=(Ω,F,T,Ω,h,f)

定义 2.2 染色体(Chromosome)
染色体 C 是一个 4 元组:
C = ( G , Σ , Φ , f ) C = (G, \Sigma, \Phi, f) C=(G,Σ,Φ,f)

定义 2.3 个体(Individual)
个体 I 是一个 3 元组
I = ( C , Φ , f ) I = (C, \Phi, f) I=(C,Φ,f)

定义 2.4 种群(Population)
种群 P 是一个 3 元组:
P = ( I , f , t ) P = (I, f, t) P=(I,f,t)

定义 2.5 基因表达式编程算法(Gene Expression Programming)
GEP 算法可定义为一个 4 元组:
G E P = ( P , Φ , f , t ) GEP = (P, \Phi, f, t) GEP=(P,Φ,f,t)

3. GEP 理论分析
本章将对基因表达式编程进行系统的理论分析,主要包括以下几点:
- (1) 个体编码的合法性: 基因、染色体的编码是否都可以构建完整的表达式树? 种群进化过程中,各遗传操作是否会产生非法个体?
- (2) 模式理论: 基因表达式编程是否有效?
- (3) 基因块假设: GEP 模式是否满足基因块假设?
- (4) 收敛性: 基因表达式编程是否能收敛到最优解?
3.1 个体编码的合法性分析
\quad\quad 基因表达式编程中,初始种群和遗传操作点都是随机产生的,怎样保持个体的合法性显然是影响算法运行速度的关键问题。所谓合法个体,是指个体编码字符串可以构建一个完整的表达式树(存在一个 ORF 表达式)。
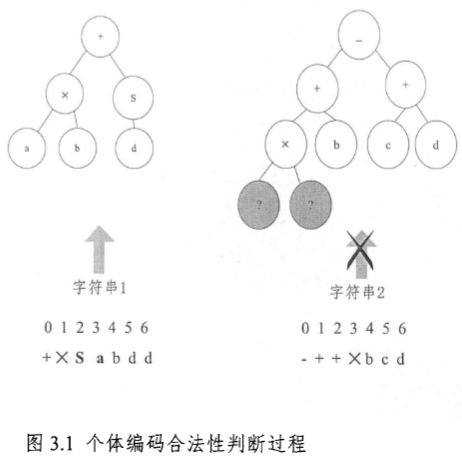
图 3.1 中字符串 1 能够构建一个表达式树,字符串 2 无法构建一个表达式树。
\quad\quad 如上章所述,在基本 GEP 中,基因包括头部和尾部两部分,基因头部的基因元素值可从函数符号集 F 和终点符号集 T 中选取,而基因尾部的基因元素值则只能从终点符号集 T 中选取。此外,对于一个基因来说,其基因头部长度 h 通常根据问题的复杂度来定义,而其尾部长度 t 需和 h 保持如式 3.1 所示关系:
t = h × ( n − 1 ) + 1 (3.1) t=h×(n-1)+1 \tag{3.1} t=h×(n−1)+1(3.1)
其中 n 是所有基因元素(函数)中参数的最大的目数。证明如下命题:



3.2 收敛性分析
\quad\quad 收敛性分析是进化计算理论分析中的重要一环。符号回归作为 GEP 的重要应用,基于 GEP 的符号回归的收敛性将能反应 GEP 在收敛性上的特点。
\quad\quad 建立基于 GEP 的符号回归模型的目的在于,利用 GEP 在问题的解空间中找到具有最高适应度的染色体,改染色体解码后得到的公式 g 最能够反应观测数据之间的内在关系。
在利用纯数学方法建模中,相关系数(Correlation Coefficient)是在建模过程中评价一个公式好坏的重要因素。于是,在基于 GEP 的符号回归中,将适应度函数设计为:
f i t n e s s = R 2 = 1 − S S E S S T (4.3) fitness = R^2 = 1 - \frac{SSE}{SST} \tag{4.3} fitness=R2=1−SSTSSE(4.3)
其中:
S S E = ∑ j = 1 C t ( C ( i , j ) − T ( j ) ) 2 (4.4) SSE = \sum_{j=1}^{C_t}(C_{(i, j)} - T_{(j)})^2 \tag{4.4} SSE=j=1∑Ct(C(i,j)−T(j))2(4.4)
S S T = ∑ j = 1 C t ( C ( i , j ) − T ( j ) ‾ ) 2 (4.5) SST = \sum_{j=1}^{C_t}(C_{(i, j)} - \overline{T_{(j)}})^2 \tag{4.5} SST=j=1∑Ct(C(i,j)−T(j))2(4.5)
其中, C ( i , j ) C_{(i, j)} C(i,j) 为变量关于函数 g 的估计值, T ( j ) ‾ \overline{T_{(j)}} T(j) 为 T ( j ) T_{(j)} T(j) 的平均值,称 S S E SSE SSE 为残差平方和, S S T SST SST 为总离差平方和。
\quad\quad 对于不同的函数 g,在式 4.3 中,SSE 的值是变化的,而 SST 则是常量。因此,基于 GEP 的符号回归问题可以转化为:搜索一个染色体,其解码得到的表达式为 g,使得 SSE 最小。这样,基于 GEP 的符号回归问题的收敛性问题,实际上就转化为探讨 SSE 向下收敛的问题。先给出一些相关概念。
\quad\quad 定义 4.1 (第 k 代最小残差平方和) 设 GEP 中用于进化的群体规模是 N,即种群中每一代染色体的个数为 N 个。第 i 个染色体记为 C i C_i Ci,其解码得到的函数表达式记为 g i g_i gi,对应的残差平方和记为 S S E i SSE_i SSEi。记 C i ( j ) C_i(j) Ci(j) 表示第 i i i 个染色体第 j j j 个节点, f i t n e s s ( i ) fitness(i) fitness(i) 为第 i i i 个染色体的适应度,并称
S S E m i n k = m i n ( S S E i ) i = 1 , 2 , ⋅ ⋅ ⋅ , N (4.6) SSE_{min}^k = min(SSE_i) ~~~~~~~~~~~~~~~~ i = 1, 2, ···, N \tag{4.6} SSEmink=min(SSEi) i=1,2,⋅⋅⋅,N(4.6)
为第 k k k 代最小残差平方和。若 k k k 代中某染色体对应的残差平方和等于 S S E m i n k SSE_{min}^k SSEmink ,即称该染色体为第 k k k 代最佳染色体。
定义 4.2(全局残差平方和最小值,全局残差平方和最小差)设 M M M 为 G E P GEP GEP 搜索的群体空间中所有的 S S E SSE SSE 值不相同的染色体个数,记
m e = m i n ( S S E i ) , i = 1 , 2 , ⋅ ⋅ ⋅ , M (4.7) me = min(SSE_i), ~~~~~~~~~~~ i = 1, 2, ···, M\tag{4.7} me=min(SSEi), i=1,2,⋅⋅⋅,M(4.7)
e = m i n ( ∣ S S E i − S S E j ∣ ) , i , j = 1 , 2 , ⋅ ⋅ ⋅ , M (4.8) e = min(|SSE_i - SSE_j|), ~~~~~~~~~~~ i, j = 1, 2, ···, M\tag{4.8} e=min(∣SSEi−SSEj∣), i,j=1,2,⋅⋅⋅,M(4.8)
称 m e me me 为全局残差平方和最小值, e e e 为全局残差平方和最小差。其中 M ≤ ( ∣ F ∣ + ∣ T ∣ ) h ⋅ ∣ T ∣ t 。 M ≤ (|F| + |T|)^h · |T|^t。 M≤(∣F∣+∣T∣)h⋅∣T∣t。 其中 ∣ F ∣ , ∣ T ∣ |F|,|T| ∣F∣,∣T∣ 分别表示集合 F,T 元素数量,即用于构造 G E P GEP GEP 染色体的函数的数量以及变量或者常量数量。
\quad\quad 若某染色体对应的残差平方和等于 m e me me,称该染色体为全局最佳染色体。显然,采用 GEP 进行符号回归时,希望每一代最佳染色体向全局最佳染色体收敛。









3.3 GEP 与 GP的比较
到底是什么原因使得 GEP 比 GP 性能更好? 本节试图做一个定性的分析。
\quad\quad 首先,GEP 采用的是符号串作为遗传编码,而 GP 采用树形结构作为遗传编码。从性能上来说,显然操纵符号串比操纵树形数据结构要快,例如,对于通常的单点变异操作,GEP只需要随机产生个变异点,然后将变异点位置的符号随机变成另外一个符号; 而 GP 则需要随机找出编码树中的个节点,然后将以该节点为根的子树删除,再从该节点开始,重新生长出一棵子树。这两个操作的性能差异是巨大的。
\quad\quad 其次,对于绝大多数实际问题, GEP 和 GP 面临的问题解空间都是无限大的。在 GP 中如果不采取相应措施,在进化过程中,树形结构将很容易变得非常巨大。非常巨大的树形结构不但降低了遗传算子的操作速度,更重要的是,使得搜索空间变得很大,效率急剧下降。这种现象称为代码膨胀问题。
\quad\quad 为了能在有效的时间内搜索出有效的解,必须对搜索范围进行一‘定的限制。在 GP 中,通常都是限定编码树的生长高度不得超过指定的值,或者编码树的节点数不得超过一定的数量。在 GEP 中。则是对 K-表达式指定了头部长度,相应的,尾部最大长度也随之固定,进而,整个遗传编码符号串就是一个定长的编码。显然,在进化过程中,GEP 是不需要随时对编码进行调整,就能够保持解树的复杂度不超过一定的值。
\quad\quad 而在 GP 中,各种遗传算子直接对解树进行操纵,极有可能使得新产生的解树超过指定的复杂度 (高度超过范围或者节点数超过范围)。这个时候,GP 需要一种机制来解决限制这些问题。通常,有两种方法:
- 淘汰法。直接将超过指定复杂度的解树进行淘汰,重新进行遗传操作产生新的子代个体。
- 罚函数法。对于超过指定复杂度的解树,在进行评价的时候增加一条罚函数,使得其适应度降低。
\quad\quad 但是,这两种方法都有很大的局限性。实践证明,当进化进行到一定代数之后,种群中的解树复杂度一般都趋于比较接近指定的上限,因为通常来说,比较复杂一点的解树更容易更精确地逼近问题的真实解,适应度也比较高一点。在这种情况下,淘汰法的进化效率将急剧下降,因为、新产生的子代个体其复杂度很容易就超过了指定的上限。而对于罚函数法,则会在大量的子代个体中引入罚函数,这使得个体的适应度在很大程度上偏离问题求解的本意,导致搜索效率也急剧下降。
\quad\quad 而在 GEP 中,由于定长的遗传编码,无论遗传算子怎么操作,都能保让产生的子代个体都是满足复杂度要求的。虽然,这比较硬性地限定了搜索的解空间,但只要指定足够的遗传编码长度,GEP的搜索性能总是能找到相对较优的解的。
Reference
[1] 张克俊. 基因表达式编程理论及其监督机器学习模型研究[D].浙江大学,2010.
[2] 左劼. 基因表达式编程核心技术研究[D].四川大学,2004.