人物交互(human object interaction)论文汇总-2020年
1. Learning Human-Object Interaction Detection using Interaction Points
1.1 总述
大多数现有的HOI检测方法都是以实例为中心的,其中基于外观特征和粗糙的空间信息来预测所有可能的人-物体之间的交互。作者认为,仅外观特征不足以捕获复杂的人与物体的相互作用。因此,在本文中,作者提出了一种新颖的全卷积方法,该方法直接检测人与物体之间的相互作用。 网络会预测交互点,这些交互点可以直接对交互进行定位和分类。与密集预测的交互向量配对,这些交互与人类和物体检测相关联以获得最终预测。
1.2 网络结构
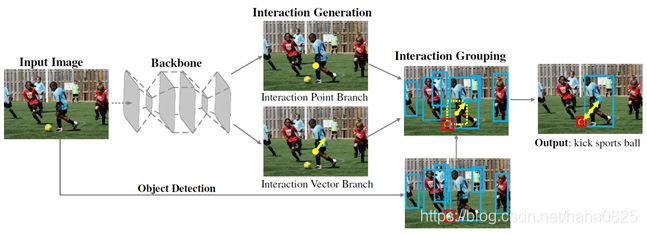
网络主要分为3个部分,特征提取部分、交互生成部分(生成交互点、交互向量)、交互分组部分(根据目标检测预测框,交互点,交互向量得到最终结果)。
Backbone网络使用的是Hourglass网络。使用Faster RCNN + ResNet50-FPN获得目标检测预测框。交互点 ( p x = ( h x + o x ) / 2 , p y = ( h y + o y ) / 2 ) (p_x=(h_x+o_x)/2,p_y=(h_y+o_y)/2) (px=(hx+ox)/2,py=(hy+oy)/2)由真实值的人和物中心点连线的中点的高斯热图监督。交互向量 ( v : p + v = h a n d p − v = o ) (v: p+v=h and p-v=o) (v:p+v=handp−v=o)分支预测指向人类中心点的交互向量,特征包括两个通道,分别是水平方向和垂直方向,推理时根据 ( x h i , y h i ) = ( p x ± ∣ v x ∣ , p y ± ∣ v y ∣ ) , i = 1 , 2 , 3 , 4 (x_h^i,y_h^i )=(p_x±|v_x |,p_y±|v_y |),i=1,2,3,4 (xhi,yhi)=(px±∣vx∣,py±∣vy∣),i=1,2,3,4生成4个人类中心的可能位置。
1.3 交互分组

总体来说,满足 h ≈ p + v a n d o ≈ p − v h≈p+v and o≈p-v h≈p+vando≈p−v的分为一组。具体来说,图中4个绿色点–人类中心的可能位置由交互向量的公式生成;紫色的4个点由人/物检测框确定;然后基于这8个点计算4个黑色向量长度 d t l , d t r , d b l , d b r d_{tl},d_{tr},d_{bl},d_{br} dtl,dtr,dbl,dbr,满足下式的为正例:
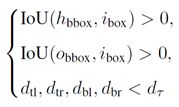
其中, d T d_T dT为过滤时的阈值。
1.4 实验
在HICO-DET数据集上mAP为19.56;在VCOCO数据集上mAP为51.0。
2. Parallel Point Detection and Matching for Real-time Human-Object Interaction Detection
2.1 总述
传统的HOI检测方法分为两个阶段,即人体目标proposal生成和proposal分类。它们的有效性和效率受到了体系结构的限制。本文提出了一种并行点检测与点匹配(PPDM)的HOI检测框架。在PPDM中,HOI被定义为一个点三元组<人的点,交互点,物体点>。人与物体点是检测box的中心,交互点是人与物体点的连线的中心点。PPDM包含两个并行分支,即点检测分支和点匹配分支。点检测分支预测三个点。同时,点匹配分支预测从交互点到对应的人和物体点的两个位移。将来自同一交互点的人体点和物体点视为匹配对。在并行体系结构中,交互点隐含地为人体和物体检测提供上下文和正则化,抑制了无意义的HOI三个的孤立的检测框,提高了HOI检测的精度。
此外,人与物体检测框之间的匹配只适用于有限数量的过滤候选交互点,这样节省了大量的计算成本。
2.2 网络结构

首先应用关键点热图预测网络,例如 Hourglass-104或DLA-34,以从图像中提取外观特征。
a)点检测分支:基于提取的视觉特征,利用三个卷积模块来预测交互点,人体中心点和物体中心点的热图。另外,要生成最终框,所以对二维尺寸w,h和局部偏移量offset进行回归。
b)点匹配分支:该分支分预测两个部分,一个是交互点到人的中心距离,一个是交互点到物的中心的距离。每个部分的特征图都是2通道的,分别表示x和y坐标。
得到预测结果进行匹配,根据检测的交互点,预测的两个距离加上交互点的坐标得到人/物中心点的坐标c1,再与检测到的人/物中心点坐标c2比较,距离c1最近且置信度较高的c2则分为一组,以生成一组交互三元组。
2.3 实验
在HICO-DET数据集上mAP为21.1。
4. PaStaNet: Toward Human Activity Knowledge Engine
4.1 总述
image到activity之间的巨大gap会导致人物交互任务的表现不是很好。作者发现:人类动作是由细粒度的身体部位的状态组成的,大多数情况下,只有少数关键的某些人体部位与行为有关,而其他部分没有多少有用的信息,另外,有的身体部位相关的活动较多(手),有的较少(头)。即动作与人体的部位状态密切相关,因此,如果能很好地利用这个信息会对交互识别提供很大帮助。
基于此,本文提出首先推断人类的身体部位的状态,然后根据此部件级别语义推断出activity。为此,本文提出了一个模块—Pasta(Human Body Part States)。为了训练这个部分,还建立了一个大型知识库PastaNet以提取Pasta特征。
4.2 PastaNet
PastaNet的结构和字母与单词的结构类似,可以用较少的Pasta来描述和区分大量活动。它将人体分为10个部分(头、两个上臂、臀部、两只手、两个大腿 、两个脚),并为每个部位分配PastaState(例如:手->握住某物;头->看/吃)。因为一个人会同时执行多个动作,因此每个部位也可具有多个Pasta。
最后构建一个活动解析树,活动(动作)是根节点,Pasta是子节点,边是共识。PastaNet包括118K+张图片,285K+个人,250K+个交互物体,724K+个动作实例以及7M+个Pasta。
4.3 人物交互任务的网络结构

首先Faster R-CNN提取的人体部件特征 f p f_p fp和物体特征 f o f_o fo拼接作为输入,输入到Part Attentions中得到部件相关性(表示身体部位对于动作的重要性)a。然后将a与 f p f_p fp相乘得到 f p ∗ f_p^* fp∗,再经过最大池化和全连接层得到Pasta的视觉特征 f p a s t a V f_{pasta}^V fpastaV(最后一个FC提取的特征)。
语言先验在视觉理解中很有用,因此视觉加语义是很好的方式。将得到的Pasta的视觉特征 f p a s t a V f_{pasta}^V fpastaV送入PastaNet得到Pasta,然后送入BERT语言特征提取器来生成包含语义知识的嵌入,也就是Pasta的语言特征 f p a s t a L f_{pasta}^L fpastaL。
最后拼接Pasta的视觉特征和语言特征,就得到了每个身体部位的Pasta特征,然后就可以用于下一步的活动检测,活动转文字等任务。
本文是通过构建层次活动图来对动作建模进而提取图状态来推断动作的。

4.4 实验
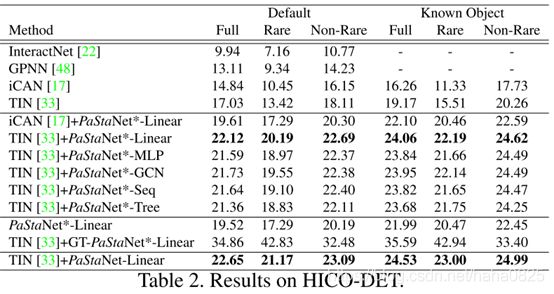
Linear、MLP、GCN、Seq、Tree这几种都是组合人体部件的方式,发现Linear方式效果最好。
PaStaNet *(38K图像):使用HICO训练集中的图像及其PaSta标签。 与传统方式相比,这里唯一的附加是使用了PaSta注释。
GT-PaStaNet *(38K图像):使用的数据与“ PaStaNet *”相同。 为了验证方法的上限,使用PaSta的真实值(二进制标签)作为Activity2Vec中的预测PaSta概率。
PaStaNet(118K张图像):除HICO测试数据外,使用所有带有PaSta标签的PaStaNet图像。
与TIN相比,TIN+PastaNet提升了将近6个点,效果还是很明显的。
5. VSGNet: Spatial Attention Network for Detecting Human Object Interactions Using Graph Convolutions
5.1 总述
物体之间的相对空间位置推理和结构连接是分析交互的基本线索,本文以此出发,提出VSGNet(Visual、Spatial、Graph)。 VSGNet从人-物对中提取视觉特征,使用人-物对的空间配置对特征进行细化,并通过图卷积利用人-物对之间的结构连接。即视觉分支分析人/物的上下文,提取特征;空间分支使用人-物对的空间配置来细化视觉特征;图卷积分支连接人-物对。
5.2 网络结构

网络主要包括三个分支:视觉分支用于提取上下文特征;空间注意力分支用于优化特征;图卷积分支提取交互特征(人、物作为结点,交互作为边)。
首先获得人、物的proposal,然后输入视觉分支获得人框、物框特征以及上下文特征。此外,根据人-物框对生成的空间配置图输入空间注意力分支提取空间注意力特征以及进一步得到空间注意力分支的交互动作概率 p h o A t t p_{ho}^{Att} phoAtt。然后将这两个特征融合得到空间细化特征,根据此特征获得该交互proposal分数 i h o i_{ho} iho以及交互动作类别概率 p h o R e f p_{ho}^{Ref} phoRef。最后将人框特征、物体框特征送入图卷积网络,每个人和每个物体连接,最终得到该分支的交互动作类别概率 p h o G r a p h p_{ho}^{Graph} phoGraph。最后将这一个交互proposal分数以及3个交互类别概率进行融合得到最终的交互类别概率 p h o p_ho pho。
5.3 空间注意力分支
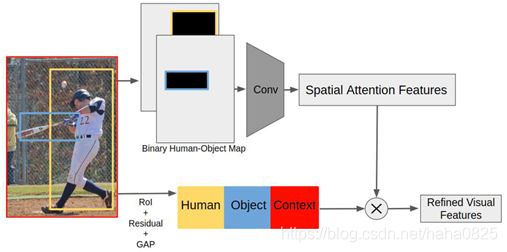
首先根据人物框构建2通道的二元图(框内为1,框外为0),将该图依次通过一个卷积,一个GAP得到空间注意力特征。该部分主要作用是完善基础特征。优化后的特征用于生成交互proposal分数和交互动作类别概率,前者size为1,指示是否交互,后者size为交互类别数量。
5.4 图卷积交互分支
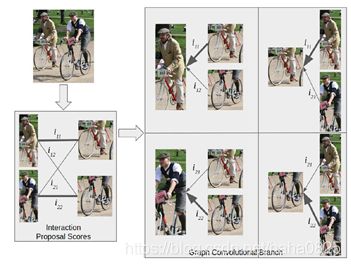
图卷积网络提取人物对结点之间的结构关系建模的特征,这是使用边缘遍历和更新图中的结点完成的。分别得到Graph Human(右图左侧)以及Graph Object(右图右侧)。本文使用交互proposal分数而不是视觉相似性作为边缘邻接(分数越大连通性越强),这允许边利用人物对之间的相互作用并生成更好的特征。
5.5 实验
在HICO-DET数据集上mAP为19.80;在VCOCO数据集上mAP为51.76。
6. Action-Guided Attention Mining and Relation Reasoning Network for Human-Object Interaction Detection
6.1 总述
现有大多数方法通过考虑多流信息甚至引入额外的知识来解决HOI问题,但存在着巨大的组合空间和非交互对控制的问题(常规的两两组合产生了大量的人物对proposal)。本文以此出发提出一种行动导向的注意力挖掘和关系推理网络。主要包括两个部分:
- 对人物对的关系推理,通过利用图注意力神经网络来增强有关的人物对,从而过滤掉非交互的人物对proposal。
- 为了更好的区分细粒度动作之间的细微差别,提出一种基于类激活图的动作感知注意力,以挖掘相关的特征来识别HOI。
6.2 网络结构
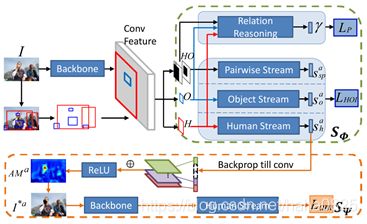
主要分为两个部分,人物交互检测流 S ∅ S_∅ S∅和注意力挖掘流 S φ S_φ Sφ。其中 S ∅ S_∅ S∅由常规的三分支再加上一个关系推理分支(图神经网络)组成; S ∅ S_∅ S∅用于从人物对proposal中滤除非交互对和推断交互类别。对应于橙色线的注意力挖掘流 S φ S_φ Sφ仅用于训练阶段,用以挖掘最具代表性的动作感知特征。
6.3 动作感知的注意力特征挖掘
作者认为应该挖掘HOI敏感的特征并更注意这些特征,iCAN是这样做的,但是它与动作无高度相关性,而动作识别对于识别交互之间的细微差别很重要。而类激活图(CAM)可以专注于类感知区域,利用它挖掘与动作有关的注意力以进行细粒度的交互检测。
类激活图(CAM)[Zhou,2016b,Learning deep features for discriminative localization]是一种有效的工具,可以通过生成粗糙的类激活图来突出显示与任务相关的区域。Grad-CAM [Selvaraju,2017b,Grad-cam: Visual explanations from deep networks via gradient-based localization]将CAM扩展到用于各种任务的可用架构,以提供模型决策的可视化解释。
[Fukui,2019,Attention branch network: Learning of attention mechanism for visual explanation]通过基于CAM生成用于视觉解释的注意力图来设计用于图像识别的注意力分支网络(ABN)。[Li,2018,Tell me where to look: Guided attention inference network]通过探索网络本身的监督来进行语义分割,提出了一种引导式注意推理模型。
受到类激活图成功应用的启发,本文基于Grad-CAM计算以人为中心的动作感知注意图并指导模型学习更多区分特征以实现细粒度的HOI识别。 与[Li et,2018]的区别在于,本文的目标是寻找最有代表性的动作感知特征,用于细粒度的交互识别,而不是更完整的类别领域。
首先通过计算人分支交互类别a的得分 S h a S_h^a Sha的梯度,然后对这些梯度执行全局平均池化获得权重 w i a w_i^a wia,然后权重与特征图进行加权后经过ReLU得到类注意力图 A M a AM^a AMa。下一步基于 A M a AM^a AMa设计一个mask(像素点的值小于某个阈值设为0,反之为1)应用在原图像上得到 I ∗ a I^{*a} I∗a,然后依次经过基础网络、人分支获得交互类别得分。
6.4 实验
在HICO-DET数据集上mAP为16.63;在VCOCO数据集上mAP为48.1。
7. Detecting Human-Object Interactions with Action Co-occurrence Priors
7.1 总述
稀有HOI类别缺少训练实例,本文旨在解决HOI的长尾分布问题。作者发现交互作用存在自然的相关性和反相关性,本文将相关性建模为动作共现(co-occurrence)矩阵,然后学习这些先验知识。
动作共现可以排除一些不兼容的HOI,如切蛋糕和吹蛋糕。与语言先验知识相比,动作共现不需要外部数据,仅从训练数据的统计信息中即可获得共现先验知识。
2种方法使用这个动作共现:
- 设计了一种具有层次结构的神经网络,其中首先针对动作组执行分类。 每个动作组由一个anchor动作定义,其中anchor动作是互斥的。然后模型将预测动作组中新的HOI类别。
- 提出一种利用知识蒸馏的技术来扩展HOI标记,以便它们可以为潜在的同时发生的动作提供更多的阳性标记。在训练过程中,根据目标确定预测值,以提高鲁棒性,尤其是对于长尾分布的类。
7.2 网络结构
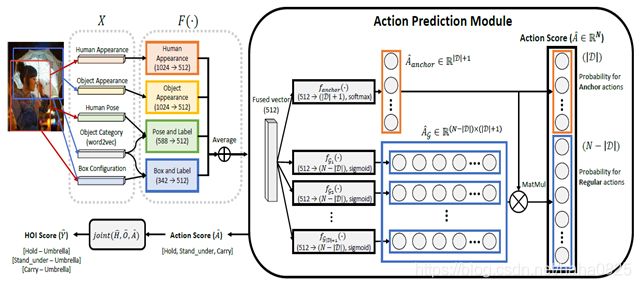
首先将各个分支的特征进行融合,传入动作预测模块。然后根据anchor动作和普通动作这两组动作分别进行预测,anchor动作使用softmax,常规动作使用sigmod。最后两者融合产生最终的动作分数:
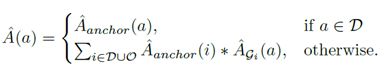
最终联合三元组得到HOI预测结果,最终的HOI预测是M个HOI类别的联合概率分布,分别根据人,物体和动作的概率H、O(目标检测分数)和A(动作分数)计算得出:
![]()
7.3 动作共现先验
HOI检测中很少考虑标签等级,受[ Deng,2014,Large-scale object classification using label relation graphs]中的使用层次Hierarchy和排除Exclusion(HEX)图对物体标签之间的可证明关系进行编码的工作的启发,本文也利用动作标签层次结构进行HOI识别。本文不同之处在于层次结构由动作共现(而不是语义或者分类法)定义的,共现基于统计确定层次结构,无需人工监督。
下图是一个共现矩阵的例子:

Y轴是给定的动作,x轴是列举条件概率,每个元素表示当一个动作i发生时另一个动作j发生的条件概率,定义为 c i j = p ( j │ i ) c_ij = p(j│i) cij=p(j│i);定义 i ′ i^{\prime} i′为动作i的互补事件(不发生动作i),则没有发生动作i时,发生动作j的条件概率 c i j = p ( j │ i ′ ) c_ij = p(j│i^{\prime}) cij=p(j│i′)。
动作关系有三种:
- 先决条件关系:条件动作发生给定动作一定发生,反之不一定
- 排除关系:给定动作与条件动作极不可能同时发生
- 重叠关系:两者一定同时发生
7.4 Non-Exclusive Action Suppression选择anchor动作
根据共现矩阵发现某些动作是接近的或通常同时发生的,另一些不是。密切相关的动作很难区分,若标注少则更难区分。作者将动作分为两组,一个是anchor动作(互斥的,倾向于区分彼此的),一个是常规动作。
在选择anchor动作时,将动作类的排他性(Exclusive)定义为计算动作i发生时其他永远不会发生的动作的数量( e i = ∑ i e_i =∑_i ei=∑i(如果 c i j = 0 c_{ij} = 0 cij=0 为1,否则为0)。 如果在执行动作i时其他动作很少发生,那么 e i e_i ei将具有较高的值。 基于排他性值,通过下图算法中所述的非排他性抑制(NES)生成anchor动作标签集D:

迭代地将最互斥的动作类设为anchor动作,并删除不与所选anchor动作互斥的其余动作类。列表中的anchor动作是永远不会在训练标签中同时出现的动作类。
7.5 知识蒸馏
最初提出了知识蒸馏[Hinton,2015,Distilling the knowledge in a neural network]来将知识从大型网络转移到较小的网络。 最近,知识蒸馏已被用于各种任务,例如终身学习(life-long learning)或多任务学习。
[Hu,2016,Harnessing deep neural networks with logic rules]扩展了这个概念,以逻辑规则的形式将先验知识提炼成深度神经网络。具体来说,他们提出了一种师生框架,将网络预测(学生)投影到规则正则化的子空间(教师)中,该过程称为蒸馏。然后更新网络,以在模拟教师的输出与预测真实标签之间取得平衡。
本文之所以是这种设置,是因为ACP可以充当提炼之前的角色。首先介绍一个ACP投影,以将动作分布映射到ACP约束。然后就可以在训练和推理时使用师生框架从ACP投影中提取知识。
7.6 实验
在HICO-DET数据集上mAP为20.59;在VCOCO数据集上mAP为52.98;针对zero-shot任务提升了6.35;针对稀有类(训练样本数量在0-9之间的交互类别)与baseline相比提升了38.24%。
8. Cascaded Human-Object Interaction Recognition
8.1 总述
现有模型局限于单阶段推理,考虑到HOI任务的复杂性,本文引入一种级联体系结构,用于多阶段,从粗糙到精细的HOI理解,总体包括实例定位网络和交互识别网络两个部分,两部分都采用级联结构,前者用于逐步完善HOI proposal,后者进行交互识别。
8.2 网络结构
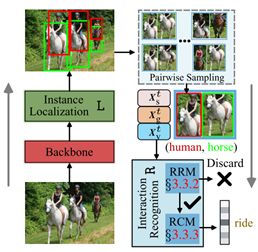
首先输入图像到backbone提取图像特征,然后特征送入实例定位网络逐步细化proposal,然后进行人物对采样,针对采样的人物对送入一个排序函数,该函数排序使带HOI标签的人物对比无标签的人物对有更高的分,然后取前64对人物对执行交互分类。
8.3 实例定位网络
与先前的级联目标检测器相似,在每个阶段,Lt都经过在IoU阈值上有一定相互作用的方式进行训练,并且对其输出进行重新采样以训练具有更高IoU阈值的下一个检测器Lt + 1。通过这种方式,逐渐提高了级联中较深阶段的训练数据的质量,从而提高了对困难负样本的选择性。在每个阶段,实例定位损失与Faster R-CNN相同。
除此之外,还朝着更细粒度的HOI理解迈出了一步,即在像素级别识别交互实体之间的关系,这种关系使我们能够探索更强大的关系表示,因为基于边界框的表示对包括了背景噪声的粗糙物体信息进行编码,而基于像素的掩模特征可以捕捉到更详细和更精确的信息。为此,为每一个实例定位网络添加一个实例分割头部,从分割mask中采样人物对,并通过逐像素ROI获取更精细的特征。
8.4 交互识别网络

在交互识别网络中,人的语义信息(Implicit Human Semantic Mining)和人脸区域(Explicit Facial Region Attending)都被挖掘以增强关系推理,因为这些线索与行为相关。具有这种以人为中心的特征,提出了一种关系排序模块(RRM)来对所有可能的人物对进行排序。只有排名靠前的高质量proposal才被送入关系分类模块(RCM)中,以进行最终交互预测。
(1) 以人为中心的特征表示
包括三个部分,语义特征X_s(捕获物体提供的关于动作的先验知识,建模为物体类别和动作类别的共现概率);几何特征X_g(编码空间关系的黑白图);视觉特征(2种特征增强方式,Implicit Human Semantic Mining用于增强人的特征,Explicit Facial Region Attending用于增强物的特征)。
a. Implicit Human Semantic Mining
不同于目前主流的依赖于人体姿势估计的方法,本文隐式地学习人体部分及其相互作用。对于人类区域(特征)H内的每个像素位置i,将其语义上下文定义为属于i的同一语义人类部位类别的像素。使用这种语义上下文来增强人类特征表示,因为它捕捉到了人体部位内部和部位之间的关系。在这里,计算一个语义相似度图来完成,最后计算的H内所有像素的语义上下文信息进行集合后,得到一个语义上下文增强特征。
b. Explicit Facial Region Attending
人脸对于理解HOI是至关重要的,因为它传达了丰富的信息,与人类潜在的注意力和意图密切相关。有许多交互直接涉及到人脸。例如,人类用眼睛看电视,用嘴吃东西,等等。此外,与人脸相关的交互通常是细粒度的,并且与交互物体上的严重遮挡相结合,例如打电话,给HOI识别带来了很大的困难。为了解决上述问题,作者提出了另一种特征增强机制,即显式面部区域参与。该机制通过两种注意机制丰富了物体特征表示:
- 一是ROI Align提取面部区域特征F,然后学习一个注意分数α∈[0,1]来解释面部区域对物体的重要性;
- 二是面部不可知注意力。人脸感知增强解决了人脸与物体之间的相关性问题。为了挖掘物体和其他人类区域之间的潜在关系,提出了一种不可知注意力。首先通过将人脸区域中的像素值设置为零,从人类区域中移除面部区域。然后从去除的人脸区域得到相应的ROI Align特征 F ˉ \bar{F} Fˉ。最后,计算了一个重要度得分 α ˉ \bar{α} αˉ∈[0,1],最终增强的物体特征为 O ˉ = O + α F + α ˉ F ˉ \bar{O}=O+αF+\bar{α}\bar{F} Oˉ=O+αF+αˉFˉ。
(2) 关系排序模型(RRM)
人类与物体进行交互并不是杂乱无章的(人物实例两两配对构造交互proposal的方式不可取),作者认为带注释的人物对比没有HOI标签的人物对相比来说更相关(排名得分更高)。所以训练一个函数,该函数使有标签的人物对比没有标签的人物对有更高的分数。
(3) 关系分类模型(RCM)
通过RRM,只有少数排名靠前的、高质量的人-物对被保存并输入到三分支关系分类模块(RCM)中,用于最终的HOI识别。对于HOI proposal(人、物),语义 X s X_s Xs、几何 X g X_g Xg和视觉 X v X_v Xv特征分别输入到RCM中的相应流中,以独立地估计HOI动作得分向量 s s 、 s g 、 s v s_s、s_g、s_v ss、sg、sv,最终的结果为 s = ( s v + s g ) ⊙ s s s=(s_v+s_g)⊙s_s s=(sv+sg)⊙ss(⊙是Hadamard product)。
8.5 实验
在ICCV 2019 PIC19 Challenge(ICCV2019 Person in Context Challenge, on both relation detection and segmentation tasks)比赛中获得第一名;在VCOCO数据集上mAP为48.9。
9. Polysemy Deciphering Network for Human-Object Interaction Detection
9.1 总述
现有模型假设同一动词在不同的HOI范畴中具有相似的视觉特征,忽略了动词的不同语义(在不同的场景下,相同的动作的视觉特征有很大差别,如下图所示,对于不同的物体,动词可以呈现实质上不同的语义和视觉特征。这种语义差异可能非常大,导致同一类型视觉特征的重要性随着感兴趣物体的变化而发生巨大变化)。

其中同一动词的(a)姿态信息重要但是对(b)来说不重要;同一动词的(c)和(d)的空间相对关系并不同。
为了解决动词的多义性问题,本文提出一种多义词解码网络PDNet,通过3种方式对动词的视觉多义进行解码以进行HOI检测。首先,PDNet利用语言先验信息增强人类的姿态和空间特征进行HOI检测,使动词分类器能够接收到减少同一动词类内变异的语言提示。其次,提出了一种新的多义注意模块(PAM),该模块可以指导PDNet根据语言优先级对更重要的特征类型进行决策。最后,将上述两种策略应用于动词识别的两种分类,即SH-VCM和SP-VCM(object-shared and object-specific verb classifiers),二者的结合进一步解决了动词多义问题。
9.2 网络结构

(1)基础部分:
给定一幅图像,使用Faster R-CNN获得人和物体的proposal。每个人类提议h和物体提议o将组合成对作为交互分类的proposal。然后提取人特征、物体特征、空间特征以及姿态信息 ( H w s 、 O w s 、 P w s 和 S w s ) (H^{ws}、O^{ws}、P^{ws}和S^{ws}) (Hws、Ows、Pws和Sws)传入后续网络。
(2)动词多义处理部分:
A w s 、 A s h 和 A s p A^{ws}、A^{sh}和A^{sp} Aws、Ash和Asp是PAM模块的块。 H w s 、 O w s 、 P w s 和 S w s H^{ws}、O^{ws}、P^{ws}和S^{ws} Hws、Ows、Pws和Sws是SH-VCM和SP-VCM共享的块(上标“ws”表示“权重共享”)。 H s h ( H s p ) 、 O s h ( O s p ) 、 P s h ( P s p ) H^{sh}(H^{sp})、O^{sh}(O^{sp})、P^{sh}(P^{sp}) Hsh(Hsp)、Osh(Osp)、Psh(Psp)和 S s h ( S s p ) S^{sh}(S^{sp}) Ssh(Ssp)是SH-VCM(SP-VCM)中的块。将 H s h ( H s p ) 、 O s h ( O s p ) 、 P s h ( P s p ) H^{sh}(H^{sp})、O^{sh}(O^{sp})、P^{sh}(P^{sp}) Hsh(Hsp)、Osh(Osp)、Psh(Psp)和 S s h ( S s p ) S^{sh}(S^{sp}) Ssh(Ssp)的二元分类分数用PAM产生的注意分数进行融合。⊗和⊕分别表示元素的乘法和加法运算。
PD-Net首先为每个proposal对生成一组动词分类分数。然后将多标签交互分类问题转化为一组二元分类问题(动词-名词两两组合)。然后依次通过语言先验增强(LPA)、多义注意模块(PAM)、物体共享动词分类模块(SH-VCM)和特定于物体的动词分类模块(SP-VCM)来执行HOI检测。SH-VCM和SP-VCM分别包含一组共享物体二元分类器和特定物体二元分类器。
9.3 LPA
首先动词-名词进行组合,然后在语言先验的指导下,将忽略无意义的HOI类别,从而减少重复的动词-名词对的数量,例如舍弃和。
此外,还在姿态特征以及空间特征上添加了词向量以增强这两部分的特征。具体来说,将空间特征与两个单词的600维词嵌入相连接。一个单词表示待识别的动词,另一个单词表示检测到的物体。词嵌入是使用word2vec工具生成的。使用相同的策略在姿态特征上。
9.4 PAM
动词多义问题带来的一个主要挑战是,四个特征流中的每一个对于识别同一个动词的相对重要性可能会随着物体的变化而发生显著变化。因此PAM产生注意力分数,不同的场景下每个特征流有着不同的权重,从而动态的融合4个特征流。
PAM包含三个块: A w s 、 A s h 和 A s p 。 A w s A^{ws}、A^{sh}和A^{sp}。A^{ws} Aws、Ash和Asp。Aws块由SH-VCM和SP-VCM共享,以减少参数数量,它由两个600维FC层组成。 A s h A^{sh} Ash仅用于SH-VCM,仅包括一个四维FC层。 A s p A^{sp} Asp仅适用于SP-VCM,包括两个FC层,其尺寸分别为600和4。利用sigmoid激活函数对两个四维FC层的输出分别作为SH-VCM和SP-VCM的注意分数。这样,就突出了重要特征相对于语言先验的作用,而不太有用的特征的作用被抑制。
9.5 SH-VCM和SP-VCM
由于动词多义问题本质上是由物体的变化引起的,因此引入SP-VCM为每个有意义的HOI类别构造一个二元分类器。
SH-VCM和SP-VCM的输入特征相同。利用PAM产生的注意分数对SP-VCM中每个二元分类器的四个特征流进行融合。理论上,只要每个HOI类别都有足够的训练数据,SP-VCM比SH-VCM就能很好地解决多义问题;但由于类别不平衡问题,许多HOI类别的训练数据有限。因此将SH-VCM和SP-VCM结合起来进行动词分类。
此外,它们之间共享它们的某些层,即 H w s 、 O w s 、 P w s 和 S w s H^{ws}、O^{ws}、P^{ws}和S^{ws} Hws、Ows、Pws和Sws,以降低SP-VCM在检测训练数据有限的HOI类别时的过拟合风险(实验也证明了在没有这种参数共享的情况下,SH-VCM和SP-VCM的组合在检测训练数据有限的HOI类别时性能较差)。
9.6 Clustering-based SP-VCM
动词-名词对组合数量巨大,即使使用语言先验去除了无意义的HOI类别,还是会留下很多,因此使用聚类解决这个问题。
这一步的主要动机是同一个动词的一些HOI范畴在语义上是相似的,因此,它们可以共享相同的Object specific Classification。具体来说,首先获得每个动词的所有有意义和常见的HOI类别。包含动词v的有意义的HOI类别的数量由 O v O_v Ov表示。其次,利用K-means方法,根据物体词嵌入之间的余弦距离,将同一动词v的HOI类别聚类为 C v C_v Cv簇。然后根据经验将每个动词的 C v C_v Cv设为 O v O_v Ov平方根的四舍五入数。这种聚类策略也能处理SP-VCM的few-shot和zero-shot学习问题。
9.7 实验
在HICO-DET上mAP为19.99,在VCOCO上mAP为51.6。
10. DRG: Dual Relation Graph for Human-Object Interaction Detection
10.1 总述
现有的方法要么孤立地识别每个人-物对的交互作用,要么基于复杂的外观特征进行联合推理,这样缺少上下文的推理是不明确的。本文以此出发,利用抽象的空间语义表示来描述每个人-物对,并通过一个双重关系图(一个以人为中心,一个以物体为中心)来聚合场景的上下文信息。双重关系图能有效地捕捉场景中的区分性线索,以解决HOI局部预测中的模糊性问题。
此外,现有的方法依赖于复杂的基于外观的特征来编码人-物关系(例如从两个框的联合框提取的深层特征),而不利用信息丰富的空间线索。所以本文使用空间语义表示来描述每个人-物对。具体来说,空间语义表示编码(1)人与物体之间的相对空间布局,(2)物体范畴的语义词嵌入。
10.2 网络结构

网络由三个分支(人、物体和空间语义)组成。人和物体分支利用外观特征 f H 和 f O f_H和f_O fH和fO。空间语义分支由抽象的空间语义特征x进行预测,并将双重关系图(DRG)应用于该分支。三个分支预测分数融合形成最终预测。
10.3 DRG
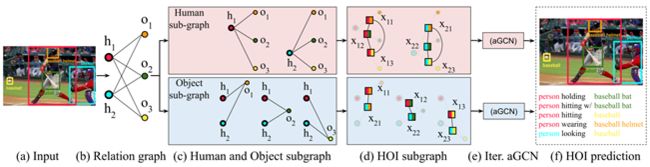
(a)模型的输入是给定图像中检测到的目标。将H表示为人检测的集合,而O表示为物体检测的集合。
(b)从H和O集合构造一个关系图。
(c)对于H中的每个人类节点H,构建了一个以人为中心的子图,其中O中的所有节点都与H相连。同样,为O中的每个物体节点O构造一个以物体为中心的子图(“人”也是一个物体类别,为了简单起见,不在图中显示它)。
(d)显式地预测HOI图。以人子图为例,在人节点h和物体节点o之间插入一个HOI节点x,连接所有的HOI节点,得到以人为中心的HOI子图和以物体为中心的HOI子图。
(e)通过一个可训练的注意图卷积网络迭代更新HOI节点特征。这有助于聚合上下文信息。
(f)融合两个子图的得分,并做出最终的HOI预测。
10.4 实验
在HICO-DET上mAP最高为24.53(COCO上预训练,HICO-DET上微调),在VCOCO上mAP为51.0。
11. Visual Compositional Learning for Human-Object Interaction Detection
11.1 总述
本文主要针对长尾分布问题,提出Visual Compositional Learning (VCL) 框架。VCL首先将HOI表示分解为特定于物体和动词的特征,然后通过拼接这些特征在特征空间中合成新的交互样本。分解与合成的结合使得VCL能够在不同的HOI样本和图像之间共享物体和动词特征,生成新的交互样本和新类型的HOI,从而大大缓解了长尾分布问题,有利于low-shot 或 zero-shot的HOI检测。
11.2 网络结构
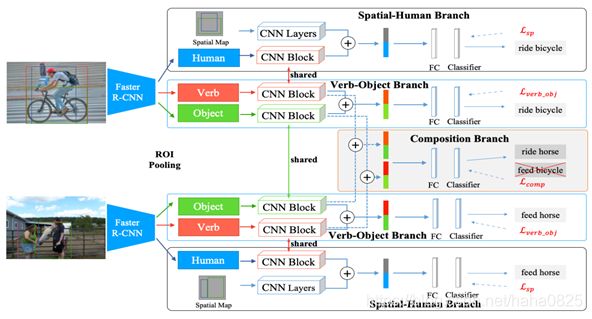
视觉合成学习(VCL)框架如图所示。给出两幅图像,我们首先用Faster RCNN来检测人和物体。接下来,利用ROI池化和以及CNN块,提取人的特征、动词的特征(即人与物的联合框)和物体特征。然后将这些特征分为以下几个分支:空间-人分支、动-宾分支和复合分支。最后,由一个共享的FC分类器对来自动-宾分支和复合分支的HOI表示进行分类,而来自空间-人分支的HOI表示则由单独的FC分类器进行分类。所有参数都是跨图像共享的,如果图像包含多个HOI,则新合成的HOI实例可以来自单个图像。
动宾-分支:每个图像中的动-宾分支包括一个动词流和一个宾词流。动词分支从人类框和物体框的联合框中提取出一个动词表征。同时将空间-人分支中的人流与动-宾分支中的联合框中的动词流进行权重分配。动词表征更具区分性,在人与物的联合框中包含了更多有用的语义信息。
11.3. Composing Interactions
VCL框架的核心思想是在图像内部和图像之间构建新的交互样本。这个合成过程鼓励网络通过合成大量不同的HOI样本来学习HOI的共享宾语和动词特征。
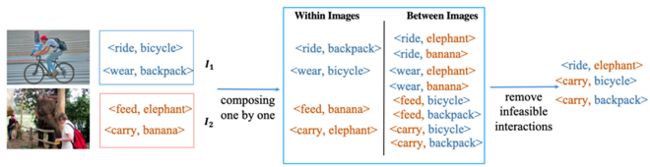
新交互的形成过程如图。在给定两幅图像I1和I2的情况下,首先考虑所有可能的动-宾语对,然后消除不可行的交互,在单个图像中和两个图像之间构造新的交互样本。
现有的HOI标签主要包含一个宾语和至少一个动词,这使得HOI检测成为一个多标签问题。为了避免频繁检查动宾对,设计了一种高效的合成和删除策略。首先,将HOI标签空间分解为动词HOI矩阵 A v ∈ R ( N v × C ) A_v∈R^(N_v×C) Av∈R(Nv×C)和宾语HOI矩阵 A o ∈ R ( N o × C ) A_o∈R^(N_o×C) Ao∈R(No×C),其中 N c 、 N o 和 C N_c、N_o和C Nc、No和C分别表示动词、宾语和HOI类别的个数。 A v ( A o ) A_v(A_o) Av(Ao)可以看作是动词(宾语)与HOI的共现矩阵。然后,给出二元HOI标记向量 y ∈ R ( N × C ) y∈R^(N×C) y∈R(N×C),其中N,C分别表示相互作用数和HOI类别。然后可以得到宾语标签向量和动词标签向量:
![]()
然后生成新的交互:
![]()
其中&表示“与”逻辑运算。给定标签空间中不存在的不可行HOI标签在逻辑运算后都是零向量。然后就可以过滤掉那些不可行的HOI。在实现中通过ROI池化从两幅图像中获取动词和宾语,并将它们在图像内部和图像之间进行相同的处理。因此,在组合HOI时,不会对两个层次的构图进行不同的处理。
在测试阶段,去除合成操作,使用空间-人分支和动-宾分支来识别输入图像的交互作用(即人-物对)。
11.4 实验
在HICO-DET上mAP最高为23.63(COCO上预训练,HICO-DET上微调),在VCOCO上mAP为48.3。