【Python实例第18讲】affinity propagation聚类算法
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
在统计和数据挖掘里,affinity propagation(AP)是一种基于数据点之间的“信息传递”的聚类算法。与k-means等其它聚类算法不同的是,AP不需要在聚类前确定或估计类的个数。类似于k-medoids, AP需要寻找原型(exemplars), 即,代表类的输入集里的成员。AP算法广泛应用于计算机视觉和计算生物学领域。
算法描述
设 x 1 , x 2 , … , x n x_1, x_2, \dots, x_n x1,x2,…,xn 组成数据点集合,这里并不需要假设数据集的结构。令 s s s 是一个量化任何两点相似度的函数。对任意 x i x_i xi, s ( x i , x j ) > s ( x i , x k ) s(x_i, x_j)>s(x_i, x_k) s(xi,xj)>s(xi,xk), 当且仅当
x i x_i xi 与 x j x_j xj 更相似。在这里,使用负平方距离,即,
s ( i , j ) = − ∥ x i − x j ∥ 2 s(i, j)=-\|x_i-x_j\|^2 s(i,j)=−∥xi−xj∥2
令相似矩阵 S = ( s ( i , j ) ) S=(s(i, j)) S=(s(i,j)), 它的对角元 s ( i , i ) s(i, i) s(i,i) 尤其重要,因为它代表了输入偏好。这意味着一个输入在多大程度上可能是一个exemplar. 特别地,当所有对角元都相同时,它实际上控制了算法产生多少个类。该值越大,产生的类就越多。AP算法在两个信息传递步迭代,升级两个测度。
-
responsibility矩阵 R \mathrm{R} R, 矩阵元素 r ( i , k ) r(i, k) r(i,k) 量化 x i x_i xi 作为 x k x_k xk 的exemplar的适配程度。 -
availability矩阵 A \mathrm{A} A, 矩阵元素 a ( i , k ) a(i, k) a(i,k) 表示 x i x_i xi 选择 x k x_k xk 作为它的exemplar的适合程度。
R \mathrm{R} R, A \mathrm{A} A 初始化为零矩阵。然后,算法在下面的两步间迭代升级:
- 首先升级 R \mathrm{R} R:
r ( i , k ) ← s ( i , k ) − max k ′ ≠ k { a ( i , k ′ ) + s ( i , k ′ ) } r(i, k)\leftarrow s(i, k)-\max_{k'\ne k}\{a(i, k')+s(i, k')\} r(i,k)←s(i,k)−k′̸=kmax{a(i,k′)+s(i,k′)}
- 然后升级 A \mathrm{A} A:
a ( i , k ) ← min ⟮ 0 , r ( k , k ) + ∑ i ′ ∉ { i , k } max ( 0 , r ( i ′ , k ) ) ⟯ f o r i ≠ k a(i, k)\leftarrow \min \lgroup 0, r(k, k)+\sum_{i'\notin\{i, k\}}\max(0, r(i', k))\rgroup\,\,\, for \,\, i\ne k a(i,k)←min⟮0,r(k,k)+i′∈/{i,k}∑max(0,r(i′,k))⟯fori̸=k
a ( k , k ) ← ∑ i ′ ≠ k max ( 0 , r ( i ′ , k ) ) a(k, k)\leftarrow \sum_{i'\ne k}\max (0, r(i', k)) a(k,k)←i′̸=k∑max(0,r(i′,k))
迭代进行到达到类的边界,或者预定的迭代次数,算法停止。对于满足 r ( i , i ) + a ( i , i ) > 0 r(i, i)+a(i, i)>0 r(i,i)+a(i,i)>0 的数据点,作为类的exemplars.
Python 实例
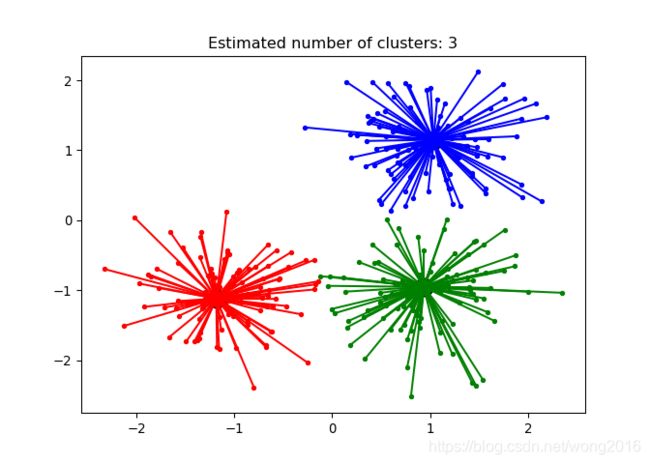
scikit-learn的方法 AffinityPropagation 实现AP聚类。下面,我们使用方法make_blobs
模拟300个样本、3个中心的isotropic高斯数据团,在这些模拟数据上进行聚类,比较聚类效果。
from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.5,
random_state=0)
# #############################################################################
# Compute Affinity Propagation
af = AffinityPropagation(preference=-50).fit(X)
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_
n_clusters_ = len(cluster_centers_indices)
print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels, metric='sqeuclidean'))
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
from itertools import cycle
plt.close('all')
plt.figure(1)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
class_members = labels == k
cluster_center = X[cluster_centers_indices[k]]
plt.plot(X[class_members, 0], X[class_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
for x in X[class_members]:
plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()

阅读更多精彩内容,请关注微信公众号:统计学习与大数据