hadoop之MapReduce的案例(排序、最大值)

4.0.0
com.xuan
hadoopdemo
1.0-SNAPSHOT
hadoopdemo
http://www.example.com
UTF-8
1.8
1.8
junit
junit
4.11
test
org.apache.hadoop
hadoop-common
2.5.2
org.apache.hadoop
hadoop-hdfs
2.5.2
org.apache.hadoop
hadoop-client
2.5.2
junit
junit
4.11
test
案列一:排序


package squencefile;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import java.io.IOException;
public class DisticAndSort {
/**
* 将每行读取进来,转换成输出格式<行数据,"">
*/
public static class MyMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,new Text(""));
}
}
/**
* 将行数据进行去重,输出格式<行数据,"">
*/
public static class MyReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//直接输出
context.write(key,new Text(""));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个job,也就是一个运行环境
Configuration conf=new Configuration();
//集群运行
// conf.set("fs.defaultFS","hdfs://hadoop:8088");
//本地运行
Job job=Job.getInstance(conf,"DisticAndSort");
//程序入口(打jar包)
job.setJarByClass(DisticAndSort.class);
//需要输入三个文件:输入文件
FileInputFormat.addInputPath(job,new Path("F:\\filnk_package\\hadoop-2.10.1\\data\\test2\\file1.txt"));
FileInputFormat.addInputPath(job,new Path("F:\\filnk_package\\hadoop-2.10.1\\data\\test2\\file2.txt"));
FileInputFormat.addInputPath(job,new Path("F:\\filnk_package\\hadoop-2.10.1\\data\\test2\\file3.txt"));
//编写mapper处理逻辑
job.setMapperClass(DisticAndSort.MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//shuffle流程
//编写reduce处理逻辑
job.setReducerClass(DisticAndSort.MyReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//输出文件
FileOutputFormat.setOutputPath(job,new Path("F:\\filnk_package\\hadoop-2.10.1\\data\\test2\\out"));
//运行job,需要放到Yarn上运行
boolean result =job.waitForCompletion(true);
System.out.print(result?1:0);
}
}
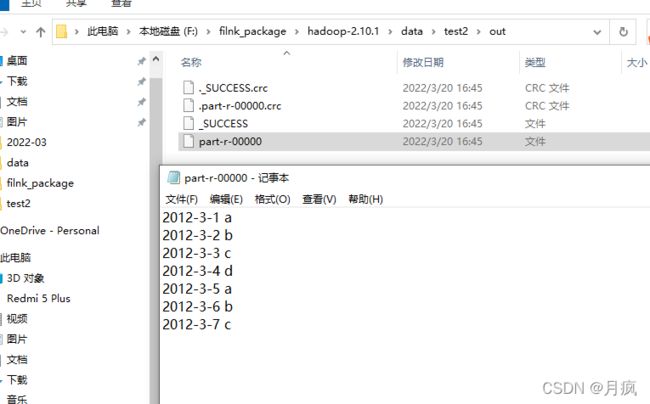
file1.txt
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c

案列二:求最高气温

temp1.txt
1990-01-01 -5
1990-06-18 35
1990-03-20 8
1989-05-11 23
1989-07-05 38
1990-07-01 36

package squencefile;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MaxTemp {
/**
* map处理逻辑
* 将输入的value进行拆分,拆分出年份,然后输出<年份,日期:温度>
*/
public static class MyMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将输入value进行拆分
String line=value.toString();
String[] lineArr=line.split(" ");
//输出年份
String year=lineArr[0].substring(0,4);
//输出格式:
context.write(new Text(year),new Text(lineArr[0]+":"+lineArr[1]));
}
}
/**
*
*/
public static class Myreducer extends Reducer{
private double maxTemp = Long.MIN_VALUE;
private String maxDay = null;
//获取每年气温最大值
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for(Text tempVal:values){
//生成数组[日期,温度]
String tempStr = tempVal.toString();
String[] tempArr=tempStr.split(":");
Long temp = Long.parseLong(tempArr[1]);
//比较,获取最大值
maxTemp = temp >maxTemp?temp:maxTemp;
//获取天数
maxDay = tempArr[0];
}
context.write(new Text(maxDay), new DoubleWritable(maxTemp));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个job,也就是一个运行环境
Configuration conf=new Configuration();
//集群运行
// conf.set("fs.defaultFS","hdfs://hadoop:8088");
//本地运行
Job job=Job.getInstance(conf,"MaxTemp");
//程序入口(打jar包)
job.setJarByClass(MaxTemp.class);
//需要输入俩个文件:输入文件
FileInputFormat.addInputPath(job,new Path("F:\\filnk_package\\hadoop-2.10.1\\data\\test3\\temp1.txt"));
FileInputFormat.addInputPath(job,new Path("F:\\filnk_package\\hadoop-2.10.1\\data\\test3\\temp2.txt"));
//编写mapper处理逻辑
job.setMapperClass(MaxTemp.MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//shuffle流程
//编写reduce处理逻辑
job.setReducerClass(MaxTemp.Myreducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//输出文件
FileOutputFormat.setOutputPath(job,new Path("F:\\filnk_package\\hadoop-2.10.1\\data\\test3\\out"));
//运行job,需要放到Yarn上运行
boolean result =job.waitForCompletion(true);
System.out.print(result?1:0);
}
}