四、One-hot和损失函数的应用
文章目录
- 前言
- 一、One-hot是什么?
- 二、应用场景
- 三、One-hot创建方法(3种)
-
- 1.for 循环生成
- 2.arange遍历方法
- 3.scatter_方法
- 四、总结
前言
今天闲来无事,因为学习人工智能的道路上遇到了很多问题,纠结从那个问题开始解决?但是不要紧,我已经有答案了。所以,我决定总结一下最近学习知识要点,以缓解紧张的学习气氛。哈哈哈~~,来吧,进入正题。
/font>
提示:讲一下数据预处理之One-Hot。以下是本篇文章正文内容,下面案例可供参考
一、One-hot是什么?
示例:对于这个问题,之前谷歌了一下,还涉及寄存器了(one-hot编码是N位状态寄存器为N个状态进行编码的方式)。。真的无语。这里不说那些很底层的,我们只需要了解one-hot编码是将类别变量转换为机器学习算法中容易处理的一种形式!
概念太抽象了,对太抽了,那么从实际例子来说明。
如下我们有两个特征:

我们看到有两个特证名为:animal与food,解释一下两列值意思,第一列代表的是动物的名字,第二列是食物的个数,比如第一行cat 2 描述为猫吃了两个食物,这里是测试数据,主要是想通过,这些数据给予直观的认识及实际操作。
而对上述数据做one-hot编码后得结果为:
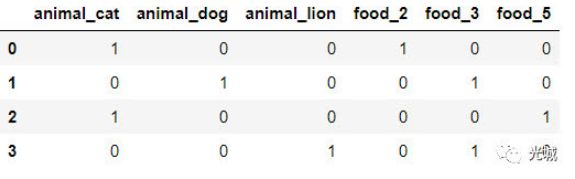
animal列数据类型是字符串,而第二列是数值型,如果我们能将这些特征值用0/1表示,是不是在机器学习中,对这些非连续值非常有帮助。综上,我们推论出,如果你在处理的数据中,通过特征工程这一步操作,能够将特征的类型判别出来,哪些是连续的,哪些是非连续的,那么我们就可以对它进行特殊处理,比如此处的one-hot编码!
二、应用场景
在模型训练中,常常会根据损失函数的大小作为训练效果的好坏。通常会使用:
- 平均绝对误差(MAEloss),
- 均方误差(MSEloss),需要做one-hot以及加入softmax输出函数。
- 二分类交叉熵(BCELoss),需要做one-hot以及加入softmax输出函数。
- 二分类交叉熵(BCEWithLogitsLoss,对输入值自动做sigmoid,但需要做one-hot。
- 多分类交叉熵(CrossEntropyLoss),自动对输入数据做one-hot和softmax。
三、One-hot创建方法(3种)
1.for 循环生成
代码如下(示例):
def one_hot(w,h,arr):
zero_arr = np.zeros([w,h])#w行,h列
for i in range(w):
j = int(arr[i])
zero_arr[i][j]=1
return zero_arr
arr = np.array([5, 2, 8, 6])
one_hot(len(arr),max(arr)+1,arr)2.arange遍历方法
该方法前提是:arr = np.array([5, 2, 8, 6])是这样的类型,即数组类型。
代码如下(示例):
#法1
arr = np.array([5, 2, 8, 6])
zero_arr = torch.zeros(len(arr),max(arr)+1)
zero_arr[torch.arange(len(arr)),arr]=1 #arange非常类似range函数
#或者一步到位
#法2
torch.zeros(len(arr), max(arr) + 1)[torch.arange(len(arr)),arr]=1# 一级标题
3.scatter_方法
该方法前提是:arr = torch.tensor([5, 2, 8, 6])是这样的类型,即张量(tensor)类型。
代码如下(示例):
arr = torch.tensor([5, 2, 8, 6])
torch_out =torch.zeros(len(arr),max(arr)+1).scatter_(1,arr.reshape(-1,1),1)
'''scatter_(input, dim, index, src)可以理解成放置元素或者修改元素
dim:沿着哪个维度进行索引. 一般为1或-1
index:用来 scatter 的元素索引
src:用什么内容来修改交换,可以是一个标量或一个张量'''
'''reshape(-1,1)转换成1列:
reshape(1,-1)转化成1行:for
reshape(2,-1)转换成两行:
reshape(-1,2)转化成两列''';四、总结
提示:这里对文章进行总结:
1.多分类交叉熵CrossEntropyLoss(),不需要做ong-hot,自动做onehot和softmax。
2.均方差MSELoss,需要做onehot和输出函数。
3.二分类交叉熵BCELoss(),需要做onehot和输出函数。
4.二分类交叉熵BCEWithLogitsLoss,onehot,但不用做输出函数。