Apache Kafka & SAP
最近项目关系了解到了Kafka,一下被这个神奇的物种折服,它代表着无限扩展,发布/订阅,随时在线并且连通万物。所以必须要进一步了解它,欢迎同道的朋友一起讨论学习。
Event Streaming事件流
参考:
https://kafka.apache.org/documentation.html#introduction
https://www.confluent.io/blog/microservices-apache-kafka-domain-driven-design/
https://www.confluent.io/hub/
https://www.confluent.io/apache-kafka-vs-confluent/
https://www.kai-waehner.de/blog/2019/11/22/apache-kafka-automotive-industry-industrial-iot-iiot/
https://www.jianshu.com/p/f13844f815f0
https://www.jianshu.com/p/894549cd2068
https://www.jianshu.com/p/fa307ecc1eeb
https://www.orchome.com/343
https://www.jianshu.com/p/1136f37cc419
https://blog.51cto.com/quantfabric/2499090
https://blog.csdn.net/xiaoyu_BD/article/details/81783076
https://blogs.sap.com/2021/03/16/cloud-integration-what-you-need-to-know-about-the-kafka-adapter/
https://assets.cdn.sap.com/sapcom/docs/2017/06/66673acb-c37c-0010-82c7-eda71af511fa.pdf
https://help.sap.com/docs/SAP_NETWEAVER_750/6522d0462aeb4909a79c3462b090ec51/d90da4dd2c4743948e3f018c90a235d7.html?locale=en-US&version=7.5.17
https://help.sap.com/saphelp_nwes72/helpdata/EN/4a/1415a4174f0452e10000000a421937/content.htm?no_cache=true
https://www.sap.com/products/data-intelligence.html?btp=5dbe7fa2-8f01-4b3c-bf38-e3d7788ea06b
https://blogs.sap.com/2018/11/11/sap-data-hub-2.3-hello-kafka-world/
https://blog.csdn.net/i042416/article/details/105289270/
首先要搞清楚什么是事件,然后什么是事件流?
对于关系型数据库,它的数据日志机制就是时间流,我们对数据库做的CUD操作(查询不修改状态 ),会写两个日志,一个是redo log,一个是bin log,而日志中记录的就是驱动数据库系统状态变化的事件(日志),比如把表t的id为5的记录年龄+1。
一个例子说明什么是事件流:
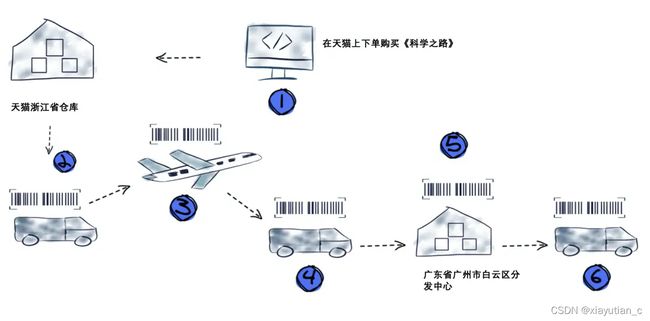

从上边购买图书的例子中,笔者特别强调这7个步骤的动作,其实每个步骤都会产生事件,而这些时间按照时间就组成了购买图书这个业务的事件流,而对于用户来讲,我只在天猫上做了下单购买的操作而已。考虑到天猫或者淘宝在国内占据统治地位的电商平台每天的订单量,你大概能测算出来每天会产生多少数量的事件,可以说是数以亿计。
事件流之后,是事件流平台
事件流平台Kafka
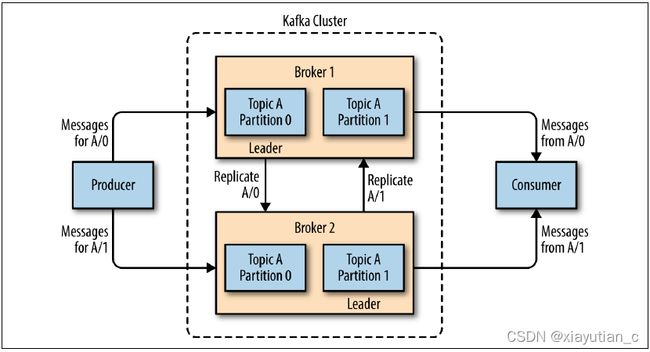
Kafka是一个事件流平台。它通常被描述为发布/订阅消息传递系统或分布式提交日志。Kafka在可以分区的主题中存储键值消息(记录)。每个分区使用增量偏移量(记录在分区中的位置)按顺序存储这些记录。记录在使用时不会被删除,但它们会一直保留,直到代理满足保留时间或保留大小。在此之前,消息可以由一个或多个(不同的)消费者一次又一次地重新处理。
为了优化效率,底层消息传递协议是基于tcp的。消息通常被分组在一起以减少网络开销,这将导致更大的网络包。
Kafka运行在一个或多个服务器(代理)的集群上,所有的主题和分区都分布(和复制)在这些代理上。这种体系结构允许您分配负载并提高容错能力。集群中的每个代理充当某些分区的leader,并充当由其他代理领导的分区的副本。

Kafka是一款开源的消息处理引擎,通常我们称之为消息中间件,与之齐名的还有阿里巴巴开源的RocketMQ。汽车行业中,奥迪、宝马、保时捷和特斯拉等汽车制造商,以及优步、Lyft和Here Technologies等移动服务公司都在使用Kafka。
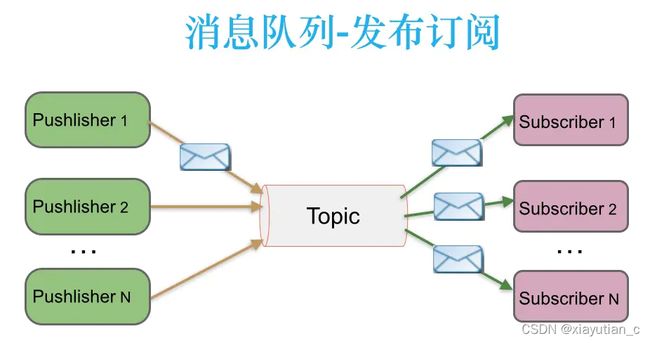
Kafka除了提供消息中间件所必须的消息发送,Borker,分区,消费者端,高可用和高可靠等机制外,还提供了事件流模式所需要的核心组件和能力。站在事件流模式的角度,我们可以把Kafka提供的能力分为三类:1,消息的发布和订阅模式;2,持久化存储机制;3,消息处理引擎。
适用场景
- 监控:主机通过Kafka发送与系统和应用程序健康相关的指标,然后这些信息会被收集和处理从而创建监控仪表盘并发送警告。
- 消息队列: 应用程度使用Kafka作为传统的消息系统实现标准的队列和消息的发布—订阅,例如搜索和内容提要(Content Feed)。比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统 一般吞吐量相对较低,但是需要更小的端到端延时,并尝尝依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMR或RabbitMQ
- 站点的用户活动追踪: 为了更好地理解用户行为,改善用户体验,将用户查看了哪个页面、点击了哪些内容等信息发送到每个数据中心的Kafka集群上,并通过Hadoop进行分析、生成日常报告。
- 流处理:保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始topic来的数据进行阶段性处理,汇总,扩充或者以其他的方式转换到新的topic下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返 还给用户。这就在一个独立的topic之外,产生了一系列的实时数据处理的流程。
- 日志聚合。使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟。
- 持久性日志:Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于Apache BookKeeper项目。
一个例子对比显示使用Kafka的效果
使用前:

使用后:

从Kafka体系结构来看,Kafka是一套分布式的系统,由客户端和服务器端组成,服务器端也叫Broker,客户端负责生产和消费事件数据。接下来我们分别介绍一下Kafka的核心组件以及事件流组件。
Kafka的核心组件以及事件流组件
【Kafka Broker】
Broker的最主要的工作就是持久化生产者客户端发送的消息数据,消息被按照key-value的格式进行存储。由于消息是以字节码的格式被保存在磁盘上,因此这些消息数据对于Broker来说就如同黑盒子,因为Broker其实也不知道消息中具体有什么内容,并且Borker也不关心。
【Schema registry】
基于消息队列通信的两个系统,消息格式非常重要,因为消息格式就如同两个做生意实体签订的合同,业务往来必须按照约定的模式进行。而Schema在消费者端和生产者端建立了这种约束。Kafka的Sechema Registry机制为生产者端和消费者端提供Schema管理,版本控制,序列化和反序列等机制,来加速基于事件流模式的应用落地实施。
【Kafka Connect】
Kafka Connect基于客户端对象模型进行了抽象,来提供Kafka数据的接入和输出的能力。Connect是和外部数据源集成的核心,并且提供了轻量级的数据转换机制。如下图所示:

【Kafka Streams】
Kafka Streams是一套原生的流数据处理框架,Streams框架基于Java语言编写。Streams组件并不是运行在Broker上,提供了事件数据的操作,包括数据转换的能力,以及数据连接和聚合操作。从这个角度看,我们的大部分工作都将会集中在Streams组件上。
【Kafka ksqlDB】
ksqlDB是一套事件流持久化数据库,并对事件流数据提供了类SQL的查询接口,从具体实现的角度来看,ksqlDB使用Kafka Streams来进行事件流数据的各种操作。ksqlDB最大的优势就是提供了一套类SQL的查询接口,让熟悉关系型数据的业务人员可以无缝切换到流数据的分析场景。
kafka的工作原理
MQ 系统都有两个比较通用的缺陷:一是当消费者出现,无法及时消费的时候,数据就会丢掉;二是可延展性问题,MQ 系统很难很好地配合数据的波峰或波谷。这些需求正好对应当时的消息队列系统不能解决的一些问题:「横向拓展、持久化、高吞吐、高性能、甚至是低成本」。因此Kafka这一流处理系统出现后,瞬间成为大数据流处理系统的事实标准。
Kafka高性能架构:
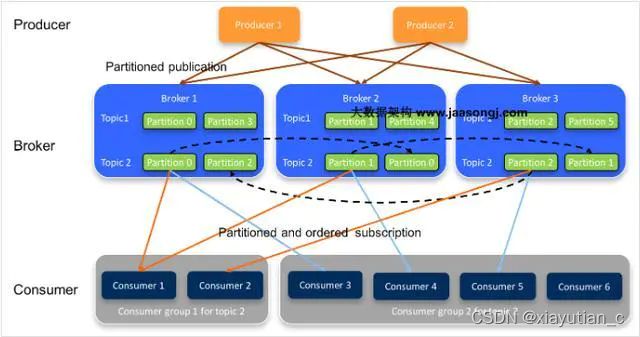
Kafka的亮点
简单讲就是上面的 横向拓展、持久化、高吞吐、高性能、甚至是低成本
Kafka使用痛点
参考 https://www.jianshu.com/p/894549cd2068
这里写的只是低版本出现的问题,高版本中可能已经不存在?
Kafka Connect
参考 https://www.jianshu.com/p/59cb3e8a93e9
Kafka Connect是到0.9版本才提供的并极大的简化了其他系统与Kafka的集成。Kafka Connect运用用户快速定义并实现各种Connector(File,Jdbc,Hdfs等),这些功能让大批量数据导入/导出Kafka很方便。
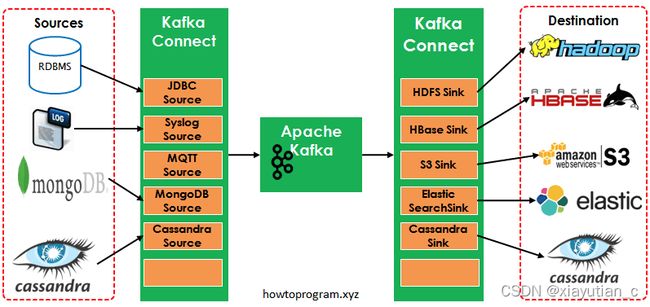
如图中所示,左侧的Sources负责从其他异构系统中读取数据并导入到Kafka中;右侧的Sinks是把Kafka中的数据写入到其他的系统中。
各种Kafka Connector
Kafka Connect 是一个可扩展、可靠的在Kafka和其他系统之间流传输的数据工具。它可以通过connectors(连接器)简单、快速的将大集合数据导入和导出kafka。Kafka Connect可以接收整个数据库或收集来自所有的应用程序的消息到Kafka Topic。使这些数据可用于低延迟流处理。导出可以把topic的数据发送到secondary storage(辅助存储也叫二级存储)也可以发送到查询系统或批处理系统做离线分析。
Kafka Connect功能包括:
Kafka连接器通用框架:Kafka Connect 规范了kafka与其他数据系统集成,简化了connector的开发、部署和管理。
分布式和单机模式 - 扩展到大型支持整个organization(公司、组织)的集中管理服务,也可缩小到开发,测试和小规模生产部署。
REST 接口 - 使用REST API来提交并管理Kafka Connect集群。
自动的offset管理 - 从connector获取少量的信息,Kafka Connect来管理offset的提交,所以connector的开发者不需要担心这个容易出错的部分。
分布式和默认扩展 - Kafka Connect建立在现有的组管理协议上。更多的工作可以添加扩展到Kafka Connect集群。
流/批量集成 - 利用kafka现有的能力,Kafka Connect是一个桥接流和批量数据系统的理想解决方案。
Kafka Connector很多,包括开源和商业版本的。如下列表中是常用的开源Connector
| Connectors | References |
|---|---|
| Jdbc | Source, Sink |
| Elastic Search | Sink1, Sink2, Sink3 |
| Cassandra | Source1, Source 2, Sink1, Sink2 |
| MongoDB | Source |
| HBase | Sink |
| Syslog | Source |
| MQTT (Source) | Source |
| Twitter (Source) | Source, Sink |
| S3 | Sink1,Sink2 |
商业版的可以通过Confluent.io获得
Confluent Kafka

2014 年的时候,Kafka 的三个主要开发人员从 LinkedIn 出来创业,开了一家叫作 Confluent 的公司。和其他大数据公司类似,Confluent 的产品叫作 Confluent Platform。这个产品的核心是 Kafka,分为三个版本:Confluent Open Source、Confluent Enterprise 和 Confluent Cloud。
Confluent的介绍是:
超过70%的财富500强使用了Apache Kafka,它已经成为动态数据的基础平台,但是自给自足的开源项目将你带到了管理底层数据基础设施的业务中。这就是现代企业选择Confluent的原因,这样他们就可以把重点放在重要的地方。以Kafka为核心,Confluent提供了一个更完整的、云原生的平台来设置你的数据,在你的数据和应用驻留的任何地方都可以使用。
可以理解为confluent是Kafda为核心,包了一些方便使用的管理功能和控件。
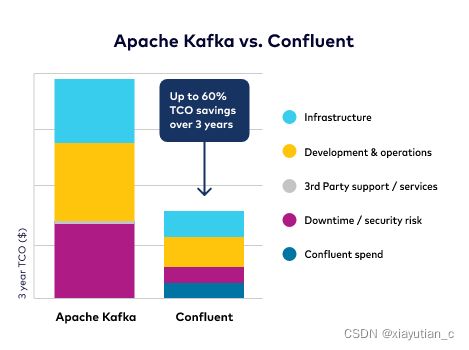
具体的对比参考Apache Kafka VS Confluent
-
Confluent Open Source 是 Confluent 公司在 Kafka 上的一个增强版本,其主要增强的地方是:增加了一个 REST 代理,以便客户端可以使用 HTTP 连接;增加了对 Java 以外的语言的支持,比如 C++、Python 和.NET;增加了对 Hadoop 文件系统、亚马逊 S3 存储、JDBC 等的连接的支持;最重要的是一个 Schema Registry,这是对 Kafka 一个比较大的增强,它使得 Kafka 的数据流必须符合注册的 Schema,从而增强了可用性。所有这些东西本身也都是开源的,这使得其他第三方在这个上面继续开发新功能成为了可能。
-
Confluent Enterprise 是 Confluent 面向企业级应用的产品,里面增加了一个叫作 Confluent Control Center 的非开源产品。Confluent Control Center 是一个对整个产品进行管理的控制中心,最主要的功能对这个 Kafka 里面各个生产者和消费者的性能监控。
-
Confluent Cloud 是 Confluent Enterprise 的云端托管服务,它增加了一个叫作云端管理控制台的组件。除此之外,按照 Confluent 的说法,其实没有什么差别。但是对于想要省心的用户来说,这个产品无疑是更好的选择。
Confluent 中有什么?
- Confluent开源版
- Confluent Kafka Connectors
Kafka Connect JDBC Connector
Kafka Connect HDFS Connector
Kafka Connect Elasticsearch Connector
Kafka Connect S3 Connector - Confluent Kafka Clients
C/C++ Client Library
Python Client Library
Go Client Library
.Net Client Library - Confluent Schema Registry
- Confluent Kafka REST Proxy
- Confluent Kafka Connectors
- Confluent 企业版中增加的功能
Automatic Data Balancing
Multi-Datacenter Replication
Confluent Control Center
JMS Client
Confluent Kafka特性
Confluent Kafka开源版特性如下:
(1)Confluent Kafka Connectors:支持Kafka Connect JDBC Connector、Kafka Connect HDFS Connector、Kafka Connect Elasticsearch Connector、Kafka Connect S3 Connector。
(2)多客户端支持:支持C/C++、Python、Go、.Net、Java客户端。
(3)Confluent Schema Registry
(4)Confluent Kafka REST Proxy
Confluent Kafka企业版特性如下:
(1)Automatic Data Balancing
(2)Multi-DataCenter Replication
(3)Confluent Control Center
(4)JMS Client
Confluent Kafka组件
1. Schema Registry
当通过网络发送数据或将数据存储在文件中时,需要对数据进行序列化。常见跨语言的序列化库如Avro、Thrift和Protocol buffer,存在两个明显的缺点:
(1)数据生产者和数据消费者间缺乏契约。如果上游生产者随意更改数据格式,很难确保下游消费者能够正确解释数据。
(2)开销和冗余。所有消息都会显示保存相同字段名和类型信息,存在大量冗余数据。
无论是使用传统的Avro API自定义序列化类和反序列化类还是使用Twitter的Bijection类库实现Avro的序列化与反序列化,都会在每条Kafka记录里都嵌入schema,会让记录的大小成倍地增加。在读取记录时需要用到整个schema,Schema Registry可以让所有记录共用一个schema。
2. Control Center
Confluent Control Center是一个对整个产品进行管理的控制中心,最主要的功能对Kafka集群的各个生产者和消费者的进行性能监控,同时可以很容易地管理Kafka的连接、创建、编辑和管理与其它系统的连接。
Confluent Control Center只在Confluent Kafk企业版提供支持

3. KSQL
KSQL是面向Apache Kafka的一种流式SQL引擎,为使用Kafka处理数据提供了一种简单的、完全交互的SQL界面,支持众多功能强大的数据流处理操作,包括聚合、连接、加窗(windowing)和sessionization(捕获单一访问者的网站会话时间范围内所有的点击流事件)等等。
KSQL目前还无法执行查询,KSQL提供的是对Kafka中的数据流执行连续查询,即随着新数据不断流入,转换在连续进行。
4. Confluent Replicator
Confluent Platform可以轻松地在多个数据中心内维护多个Kafka群集。Confluent Replicator提供了管理数据中心之间的数据复制和topic配置的功能,应用场景如下:
(1)ative-active地理定位部署:允许用户访问最近(附近)的数据中心,以优化其架构,实现低延迟和高性能。
(2)集中分析:将来自多个Kafka集群的数据聚合到一个地方,以进行组织范围的分析。
(3)云迁移:可以使用Kafka完成本地应用与云之间的数据迁移。
5. Confluent Auto Data Balancer
随着集群的增长,topic和partition以不同的速度增长,随着时间的推移,添加和删除会导致跨数据中心资源的工作负载不平衡(数据倾斜)。Confluent Auto Data Balancer会监控集群中的Broker数量、partition大小、partition数量,允许转移数据以在整个群集中创建均匀的工作负载,同时限制重新平衡流量,以最大限度地减少重新平衡时对生产工作负载的影响。
6. Kafka Connect
Kafka Connect是Kafka的一个开源组件,是用来将Kafka与数据库、key-value存储系统、搜索系统、文件系统等外部系统连接起来的基础框架。
通过使用Kafka Connect框架以及现有的Connector可以实现从源数据读入消息到Kafka,再从Kafka读出消息到目的地的功能。
Confluent在Kafka Connect基础上提供了对多种常用系统的支持:
具体以官网为准
7. MQTT Proxy333
MQTT Proxy提供了允许MQTT客户端以Kafka原生方式直接向Kafka发送消息的可伸缩的轻量级接口。
MQTT Proxy用于把基于物联网(IoT)的应用程序和Kafka 集成,可以用于联网汽车、制造业生产线和预测性维护应用程序中。
MQTT Proxy使用传输层安全(TLS)加密和基本身份验证,支持 MQTT 3.1.1 协议,可以发布所有三个MQTT服务质量级别的消息,服务级别包括把消息发送给消费者:1)最多一次(即发即弃);2)至少一次(需要确认);3)恰好一次
Kafka和SAP的集成
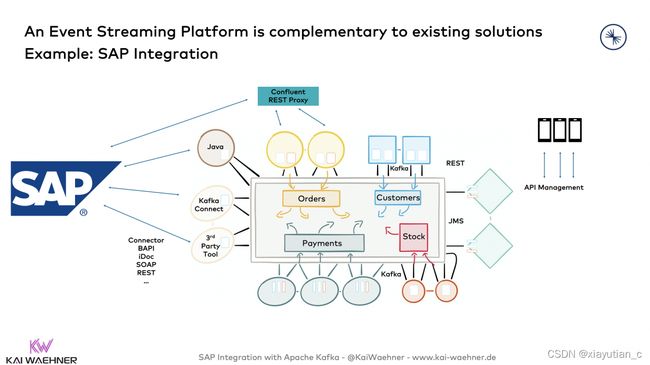
CPI 与Kafka的集成
CPI中有Kafka适配器。 既有Sender Adapter也有Receiver Adapter。
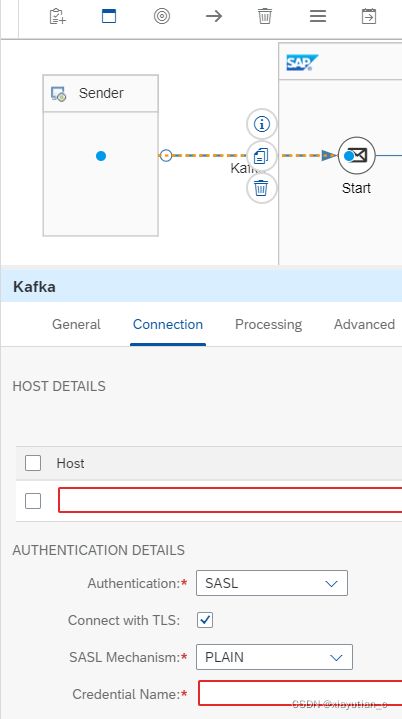
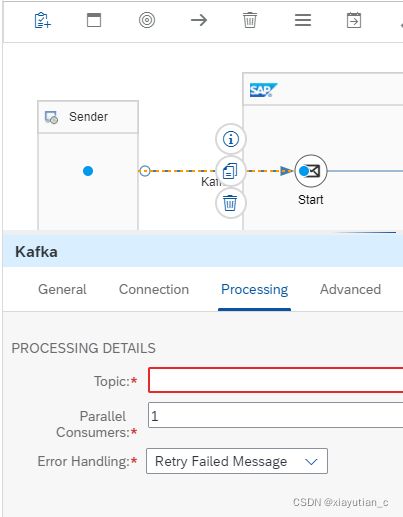
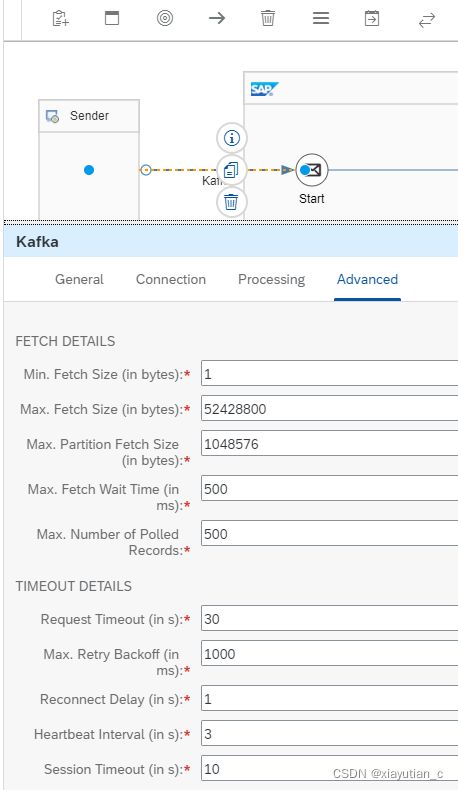
Kafka Sender Adapter
Kafka发送器适配器从一个或多个主题中批量获取Kafka记录。配置
下面几个配置截图方便理解
Kafka Receiver Adapter
Kafka接收适配器发送Kafka记录(或批)到一个主题(或分区)。配置


SAP SDK与Kafka的集成
下图是所有可用的SDK:
太旧的就不需要关注了,主要有:
- SAP ABAP TCP Push Channel: 不想用Confluent REST Proxy 这个HTTP 协议而想用 TCP协议的选择;
- JMS Adapter: 如果使用了PI,可以选择JMS适配器;
- SAP Cloud SDK: 使用Java或是JS开发应用与SAP做集成时除了CPI之外可以使用SAP Cloud SDK来集成,比如与SAP S4 HANA Cloud集成 ,与SAP SuccessFactors集成 。与On-premise产品集成也是可以的。
- SAP Cloud Platform Enterprise Messaging: S4/Hana提供异步消息传递接口(运行在CloudFoundry上的Solace上)。它支持不同的消息传递标准,包括AMQP 1.0和JMS(取决于您查看的具体产品)。一些示例演示了如何使用JMS API通过Java client进行连接。
- SAP ODP (Operational Data Provisioning): 用于操作分析和数据提取+复制的技术基础设施。针对一些产品(SAP BW, SAP BW/4HANA, SAP Data Services, and SAP HANA Smart Data Integration)有开箱即用的CDC (Change Data Capture) 功能。ODP不仅用于SAP接口,还集成了第三方技术(通过自定义连接器,而不是开箱即用),如HDFS或Kafka。(下面有ODP的具体内容)
用于SAP集成的SOAP / REST Web服务
web服务用于构建面向服务的体系结构(SOA)来集成应用程序,web服务通常使用SOAP或REST / HTTP作为技术。大多数中间件工具都对构建HTTP服务提供了适当的支持。SAP一些产品并不提供HTTP开放接口,但可以用一些工具来实现,比如PI, PO ,CPI,SAP Cloud Integration。
对于与Kafka的直接HTTP(S)通信,**Confluent Rest Proxy**是一个很好的选择,可以从任何Kafka客户端(包括自定义的SAP应用程序)生产、消费和管理。例如,SAP云平台集成(CPI)可以使用这种集成模式在SAP和Kafka之间进行集成。
Kafka的特定于sap的第三方工具
除了SAP自己做的集成工具之外,很多第三方也在做SAP的集成工具,比如:
- SAP本身的各种集成工具,尽管许多工具已经被弃用。使用SAP解决方案的一个示例是SAP OpenHub Service。它允许将数据从BW系统分发到非sap数据集市、分析应用程序和其他应用程序。SAP Data Hub(更名为SAP Data Intelligence Cloud)也可以连接到Kafka,就像本例使用Data-Hub连接Kafka中演示的那样,使用ODP。SAP Data Hub的限制包括:您必须操作一个有许可的BI系统,必须为每个场景在BW中实现专用的OpenHub组件,发生一个相当面向批处理的、基于请求的处理,以及这是一个经典的点对点场景。此外,还必须考虑到额外的许可证费用。
- ASAPIO:他们的云集成器是为SAP ERP和SAP S/4HANA设计的。它能够基于SAP NetWeaver技术在系统环境之间复制所需的数据。比如有专门的Ariba和SAP ERP或S4HANA 的集成工具。
- Advantco: Kafka适配器与SAP适配器框架完全集成,例子,这意味着Kafka连接可以使用标准的SAP PI/PO和CPI工具进行配置、管理和监控。包括对Confluent Schema Registry (+ Avro / Protobuf)的支持。
- workato:该公司提供了SAP的OData集成到Kafka和各种预构建的配方模板。
- INIT Software:INIT Software实现了一个名为i-OhJa的Kafka Connect ODP连接器。kafka原生特性提供了诸如高性能、高可伸缩性和单次语义等好处。
- Kate:KaTe Kafka适配器双向连接SAP PO与Kafka。
Kafka-native 使用 Kafka Connect与SAP集成
Kafka Connect是Apache Kafka的一个开源组件,是一个框架,用于连接Kafka和外部系统,如数据库、键值存储、搜索索引和文件系统。
Kafka Connect连接器适用于SAP ERP数据库:
- S4 HANA数据库用Confluent Hana connector或是SAP Hana connector 。
- Oracle / IBM DB2 / MS SQL Server数据库用Confluent JDBC connector for R/3 / ECC集成。
这只是几个例子。还有许多用于与不同的SAP产品和接口进行内部集成、云计算和混合集成。
这种类型的连接器有以下优点:
- Kafka-native:Kafka的底层,以高的可伸缩性和可靠性为大容量数据提供实时处理。
- Simplicity:只有一个基础架构用于消息和数据集成,比使用不同的框架或产品(例如,用于消息传递的Kafka加上用于数据集成的ESB)更容易开发、测试、操作、扩展和授权。
- Real Decoupling: 可以做到真正的解耦。Kafka的架构在设计上使用了智能端点和哑管道,这是微服务的关键设计原则之一。不仅针对应用程序,也针对集成组件。为你的Kafka-native中间件利用域驱动架构( Domain-Driven Design )的所有好处。
- Custom connectors: Kafka Connect提供了一个开放模板。如果没有可用的连接器,您(或者您喜欢的系统集成商或kafka供应商)可以构建一个特定于sap的连接器,并且可以在任何地方使用它。
缺点是:
- Only database connectors: 目前除了本地JDBC数据库集成之外,还没有其他可用的连接器。
- Anti-pattern of direct database access:在大多数情况下,您希望或需要与功能或服务集成,而不是与数据对象集成。在大多数情况下,您甚至无法从数据库管理员那里直接访问。
- Efforts:构建你自己的sap原生(即,非jdbc)连接器或询问(并支付)你最喜欢的SI或Kafka供应商。
2021年1月后,Kafka-native集成可以与INIT的ODP连接器一起使用。它消除了上述缺点,对于某些用例来说,它可能是一个很棒的第三方选择。
Kafka Connect是一个很棒的框架,在大多数Kafka架构中都有使用。对于SAP集成,情况有所不同,因为没有可用的连接器(除了直接数据库访问)。第三方供应商花了很多年的时间来实现RFC/BAPI/iDoc与他们的工具的集成。这样的实现可能不会在Kafka中再次发生,因为它非常复杂,而且这些专有的遗留接口无论如何都会消亡。对于现代的SAP接口,情况是不同的:一些第三方供应商在他们的产品中使用Kafka Connect。例如,INIT Software的Kafka Connect ODP连接器。
使用Java客户端为SAP云平台企业消息传递提供Kafka Connect连接器将是一个可行且最佳的选择。我认为我们迟早会在市场上看到这样的连接器。
在SAP产品中嵌入的Kafka
上面我们已经看到了SAP和Kafka之间的各种集成选项。不幸的是,所有这些都是基于“静止数据”的原则,而不是Kafka处理的“动态数据”。在此之前,最合适的集成方式是通过SAP云平台企业消息传递进行集成,因为您至少可以利用异步消息传递API。
当Kafka不仅用于实时消息传递,还用于事件流时,真正的附加值就来了。Kafka使用它的分布式存储基础设施提供了消息、数据集成、数据处理和真正的解耦的组合。
在SAP产品中使用Kafka原生事件流
SAP收购的产品中有的也使用的kafka,比如财务报销软件SAP Concur和体验管理平台SAP Qualtrics。
显然,人们也在等待kafka原生的SAP S4/Hana接口,这样他们就可以利用实时事件来处理动态数据,并将实时数据和历史数据关联在一起。Kafka与SAP S4/Hana的本地集成应该是SAP的下一步!HERE Technologies提供了一个很好的例子来说明如何为他们的产品提供一个Kafka-native接口(以及一个可选的REST选项)。
目前原生接口方面,除了上面提到直接访问数据库的接口外没有太好的原生连接器,未来一定会有,现在有的供应商会提出两步走的策略:首先为外部提供一个kafka本地接口(在SAP术语中,就是在bapi之上提供一个kafka接口)。然后等技术成熟后,再重新设计内部架构,将不可伸缩的技术转移到Kafka(在SAP术语中,你可以用一个更可伸缩的Kafka原生版本替换RFC / BAPI函数——即使使用相同的API接口和消息结构)。
产品、部门和公司之间的本地流复制
存在多个流产品时,往往采用的是流复制,而不是用API集成的方式。

想想看:如果你在不同的应用基础设施中使用Kafka,但接口只是一个web服务或数据库,那么所有的好处可能会消失,因为可伸缩性和/或实时数据相关性消失了。这里我理解是如果有同的产品之间,比如SAP ERP和SAP CRM之间如果是用的API或是SOAP接口集成,那就没什么优势了,即使其中一个产品用了可伸缩的Kafka,也体现不出优势了。不需要数字化转型和工业4.0的需求了。
因此,越来越多的公司不仅在内部使用Kafka,而且在部门之间甚至不同的公司之间使用。通过MirrorMaker 2.0或Confluent Replicator等工具,可以实现公司之间的流复制。或者你可以使用来自Confluent的更简单的集群链接,它可以使用Kafka协议在混合、多云或第三方集成之间进行集成。
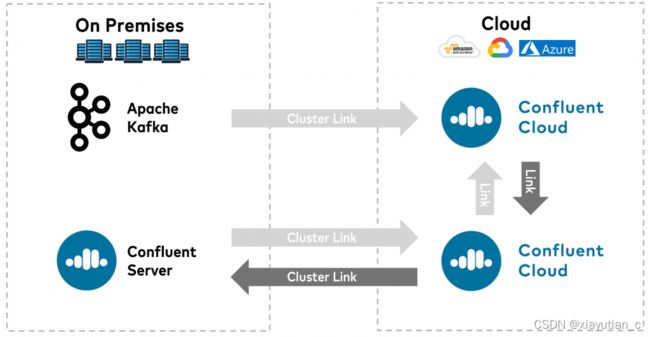
SAP + Apache Kafka
在全球范围内,将SAP应用程序与Apache Kafka集成在一起以实现实时消息、数据集成和大规模数据处理的需求是巨大的。SAP ERP (ECC和S4/Hana)的需求是真实的,SAP众多产品组合中的大多数其他产品也是如此。
下面重点研究了Confulent的连接器,和INIT的连接器
Confluent connector 与SAP
connector分三类:

-
开源、社区、合作伙伴(也就是free),SAP相关的3个连接器属于partner类别的。

-
商业性的连接器(试用30天),其中可以找到FTPS和SFTP等。

-
专业版的连接器Confluent Premium Connectors(试用30天)

其中,搜索SAP发现有三个,属于partner级别的
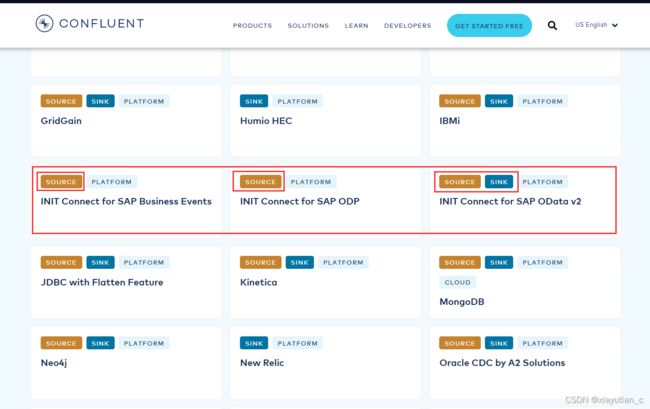
分别是:
- INIT Connect for SAP Business Events Source
- INIT Connect for SAP OData v2
- INIT Connect for SAP ODP Source
这三个都可以做为source的connector,最后一个可以做为sink也就是消费端的连接器。
JDBC Connector
除此之外JDBC Connector可以做为通用的连接器,JDBC源和接收连接器允许你在关系数据库和Kafka之间交换数据。JDBC源连接器允许你用JDBC驱动从任何关系数据库导入数据到Kafka主题。

INIT Connect for SAP Business Events Source
INIT Connect for SAP OData v2
INIT Connect for SAP ODP Source
ODP Source Connector连接器用于将数据从支持增量的SAP运营数据供应数据源中获取到Apache Kafka中。它实现了SAP ODP API v2,它为以完全模式和增量模式从各种SAP产品和模块中提取和复制业务数据提供了技术基础设施
ODP(Operational Data Provisioning)
什么是ODP?
Operational Data Provisioning提供了一个技术基础设施,主要用在支持两个应用程序场景。第一个是 操作性分析,用于业务流程中的决策制定。另一种是 数据提取和复制。
- 操作性分析
您可以使用Operational Analytics在应用程序系统本地对应用程序数据执行OLAP分析。对于Operational Analytics,您只需要在应用程序系统中执行最小的BW配置,而不需要设置数据仓库。不需要将数据复制到BW系统。应用程序数据可以直接访问。分析性能可以通过SAP HANA或SAP BW Accelerator进行提升。 - 数据提取和复制
除了SAP HANA或SAP BW Accelerator中的索引数据外,还可以使用ODP为其他外部消费者(如SAP BusinessObjects data Services)提供数据。ODP支持针对各种目标应用程序的提取和复制场景,并支持这些场景中的delta机制。对于增量过程,使用更新进程将来自源(所谓的ODP Provider)的数据自动写入增量队列,或者使用提取器接口将数据传递到增量队列。目标应用程序(称为ODQ“订阅者”或更常用的“ODP消费者”)从增量队列检索数据并继续处理数据。除了SAP BW/4HANA、SAP BW外,ODP还可以为SAP Data service、SAP HANA Smart Data Integration等其他SAP产品提供数据。
来自应用程序的数据源在联合建模环境中建模,以便使用搜索和Operational Analytics的概念进行搜索分析,并相互链接。搜索和分析模型是为此目的而定义的。在搜索和分析模型中,分析所需的属性是通过定义操作数据提供者(ODP)来设置的。ODP是复制和OLAP分析的基础。InfoProvider由一个ODP及其关联的ODP衍生而来。您可以为这些“TransientProviders”定义和运行分析查询。数据源特别适合作为分析的数据源,但是应用程序中的其他数据源也可以用于操作数据提供。Operational Data Provisioning支持事务数据和主数据(属性、文本、层次结构)的搜索和分析模型。SAP提供了搜索和分析模型,为各种业务应用程序提供了广泛的业务内容。增强概念允许对基于数据源的模型进行特定于客户的增强。对于特定于客户的数据源,可以创建特定于客户的odp以及搜索和分析模型。
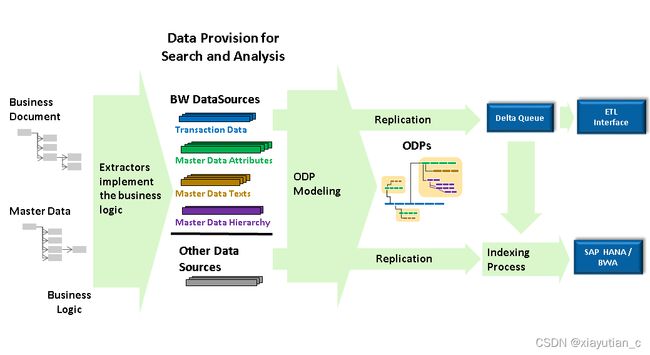
ODP框架的优点是什么?
- 使用ODP,可以直接把数据load到BW inforproviders,通过使用DTP(Data Transfer Processes )可以绕过PSA(Persistent Staging Area)层。
- ODP基础设施(使用delta队列)接管重要的服务,比如监控数据请求。
- 数据以压缩状态存储在增量队列中。增量请求将数据记录从队列传输到订阅者(目标系统)。
- 多个订阅者(目标系统)也可以请求对队列的数据更改。
- 数据将在delta队列中保留一段指定的时间,以便进行恢复。


什么时候可以用ODP?
以下是最常见的ODP集成场景的概述(不常见的场景是灰色的——Operational Analytics用例没在这个文档里,忽略)
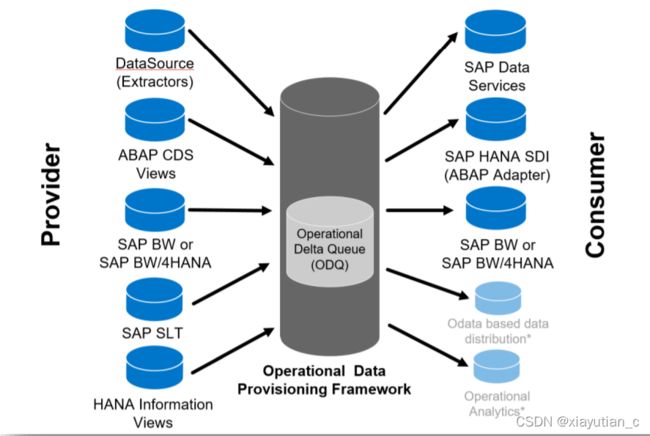
其它
2.8 版本以后,可以在没有 ZooKeeper 的情况下运行 Kafka,前后对比:
**SAP Open Hub Service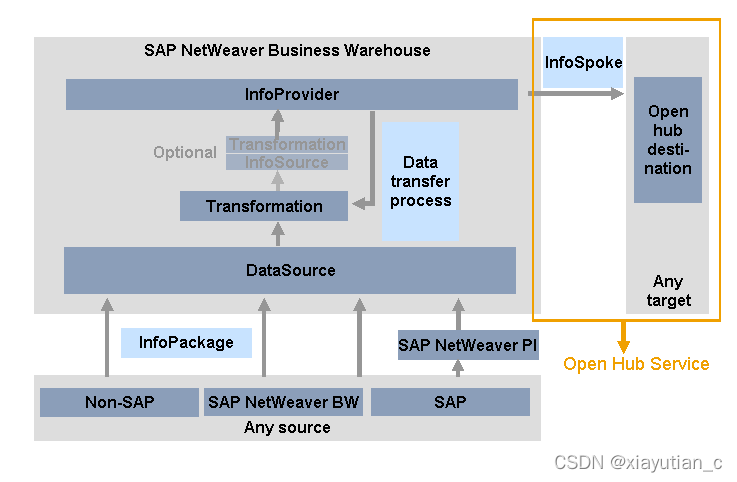
**