Mediapipe关键点实现人脸特效
目录
- 为人脸添加特效的思路
- 1. 获得人脸关键点
- 2. 调整特效尺寸
- 3. ROI区域
- 4. 消除特效图像中白色背景
-
- 第一种方法:像素值替换
- 第二种方法:图像运算
-
- 二进制“与”运算
- 处理彩色特效
- 添加特效完整代码
为人脸添加特效的思路
- 检测图像/视频中人脸的关键点
- 调整特效图像的尺寸,让其匹配人脸
- 确定人脸图像中的感兴趣区域(Region of Interest, ROI区域)
- 消除特效图像中白色背景
- 将特效图像置换到ROI区域上,实现特效添加效果
# 导入所需库
import cv2
import mediapipe as mp
import math
import matplotlib.pyplot as plt
import time
1. 获得人脸关键点
使用mediapipe的FaceMesh模块检测人脸关键点,该模块的调用方法可参考该文章: mediapipe人脸关键点检测
需要注意的是该模块返回的人脸关键点位置x和y,是通过图像宽度和高度归一化为[0.0,1.0],需要利用图像的宽度和高度进行还原。
# 获取人脸关键点
def get_landmarks(image, face_mesh):
"""
:param image: ndarray图像
:param face_mesh: 人脸检测模型
:return:人脸关键点列表,如[{0:(x,y),1:{x,y},...},{0:(x,y),1:(x,y)}]
"""
landmarks = []
height, width = image.shape[0:2]
# 人脸关键点检测
results = face_mesh.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# 解释检测结果
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
i = 0
points = {}
# 根据图像的高度和宽度还原关键点位置
for landmark in face_landmarks.landmark:
x = math.floor(landmark.x * width)
y = math.floor(landmark.y * height)
points[i] = (x, y)
i += 1
landmarks.append(points)
return landmarks
math.floor()函数用来返回向下取整的数字,如下所示。
# math.floor()的作用
print(math.floor(0.8)) # 输出0
print(math.floor(4.7)) # 输出4
调用get_landmarks()函数检测人脸关键点
# 模型配置
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(static_image_mode=False,
max_num_faces=3,
refine_landmarks=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5)
# 读取图像
image = cv2.imread("images/img1.jpg")
# 获取关键点
face_landmarks = get_landmarks(image, face_mesh)
# 输出第1个人脸,序号为3的关键点位置
print(face_landmarks[0][3])
2. 调整特效尺寸
原始的特效图像尺寸不一,若将原始特效图像叠加在人脸上会出现特效图像过大/小的情况,不能匹配人脸的大小,如下图所示:

因此,需要根据人脸比例来调整特效的尺寸,
如加胡子特效时,以132号特征点到361号特征点的宽度(即人脸的宽度)调整特效图像的宽度,以5号特征点到到0号特征点的长度调整特效的长度,这样可以保证特效能匹配人脸的大小。
本实验中共设计了3种特效,分别是胡子、眼镜和脸部面具,根据三种特效图像选定关键点,确定特效大小
def process_effects(landmarks,icon_path, icon_name):
"""
:param landmarks: 检测到的人脸关键点列表
:param icon_path: 特效图像地址
:param icon_name: 特效名称
:return:处理好的特效图像、特效宽、特效高
"""
# 特效关键点,用于调整特效的尺寸
effect_landmarks = {"beard": ((landmarks[132][0], landmarks[5][1]), (landmarks[361][0], landmarks[0][1])),
"eyeglass": ((landmarks[127][0], landmarks[151][1]), (landmarks[356][0], landmarks[195][1])),
"halfmask": ((landmarks[162][0]-50, landmarks[10][1]-50), (landmarks[389][0]+50, landmarks[195][1]+50))}
# 读取特效图像
icon = cv2.imread(icon_path)
# 选择特效关键点
pt1, pt2 = effect_landmarks[icon_name]
x, y, x_w, y_h = pt1[0], pt1[1], pt2[0], pt2[1]
# 调整特效的尺寸
w, h = x_w - x, y_h - y
effect = cv2.resize(icon, (w, h))
return effect, w, h
3. ROI区域
感兴趣区域(Region of Interest, ROI):在图像处理过程中,会对图像的某一个特定区域进行整体操作,这个区域就是感兴趣区域(ROI)。
在为人脸添加特效时,我们可以选择一个人脸区域作为ROI,将调整好尺寸的特效图像替换整个人脸ROI。
确定ROI的方法
本项目中将选择一个合适关键点,以该关键点为中心,选择一个与特效尺寸一致的区域。
- 选择该方法确定ROI区域,可以让特效随着中心点移动,在视频显示时效果更好。
- 同时需要注意的是ROI的尺寸与特效的尺寸要一致,才能进行替换,如果不一致,会出现报错。
如下图所示以164号关键点为中心,以胡子特效的高和宽确定了一个ROI区域:
landmarks[p][1] - int(h / 2) + h - (landmarks[p][1] - int(h / 2))就是特效图像的高h;
landmarks[p][0] - int(w / 2) + w - (landmarks[p][0] - int(w / 2))就是特效图像的宽w。
p = 164 # 第164号关键点为中心
# ROI区域,w,h为特效的宽与高
roi = image[landmarks[p][1] - int(h / 2):landmarks[p][1] - int(h / 2) + h,
landmarks[p][0] - int(w / 2):landmarks[p][0] - int(w / 2) + w]
需要注意的是,不能将landmarks[p][1] - int(h / 2) + h写成landmarks[p][1] + int(h / 2)。因为在python运算过程中int(h / 2) + int( h / 2) 的结果不等于h。因为int(数字),会计算向下取整后的值。
h = 373
print(int(h / 2)+int(h / 2)) # 该输出结果为372
特效图像替换ROI区域
image_copy = image.copy()
icon_name = "beard"
p = 164
for landmarks in face_landmarks:
# 调整特效尺寸
effect, w, h = process_effects(landmarks, "icons/"+icon_name+".png", icon_name)
# 以164号关键点为中心点,确定ROI区域
roi = image_copy[landmarks[p][1] - int(h / 2):landmarks[p][1] - int(h / 2) + h,
landmarks[p][0] - int(w / 2):landmarks[p][0] - int(w / 2) + w]
if roi.shape[0:2] == effect.shape[0:2]:
# 特效图像替换ROI区域
image_copy[landmarks[p][1] - int(h / 2):landmarks[p][1] - int(h / 2) + h,
landmarks[p][0] - int(w / 2):landmarks[p][0] - int(w / 2) + w] = effect
# 利用matplotlib展示
plt.figure(figsize=(10, 5))
plt.imshow(image_copy[:, :, ::-1])
输出图像

可以发现,特效可以直接“贴”在人脸的ROI上,但是图像还存在白色区域,现在就需要考虑如何去掉特效中的白色区域。
4. 消除特效图像中白色背景
观察特效可以看出,特效图像的背景都是白色的;在图像中越接近白色的点,该点的像素值就越接近255,当像素值(RGB)为(255,255,255)时,该点为白色。
第一种方法:像素值替换
消除白色区域的第一种方法:给定一个像素阈值,当特效图像中某个点的像素大于该阈值时,用ROI中的对应点替换特效图像中的点

如图中所示,特效图像中位于(100,100)的像素点,其像素值是[255,255,255],可用ROI对应位置(100,100)的点进行替换,将其像素值变为[199,205,228]。
# 循环特效图像中每一个像素点,替换大于阈值的像素值
def swap_non_effcet1(effect,roi,threshold=240):
"""
:param effect: 特效图像
:param roi: ROI区域
:param threshold: 阈值
"""
for h in range(effect.shape[0]):
for w in range(effect.shape[1]):
for k in range(3):
if effect[h][w][k] > threshold:
effect[h][w][k] = roi[h][w][k]
如何选择阈值:
在这个方法中,阈值并不是越接近255越好,虽然白色背景的像素值都是255,但是需要考虑特效区域与背景边界部位的像素值,可根据所需的特效效果选择合适的阈值。

如图所示,当阈值为254时,能去除白色背景,但是边界部分未去除;当阈值为100时,能将白色背景与边界部分都去除干净。
第一种方法在去除背景时要求依次循环读取每个像素点,每个像素点又有3个像素值,导致添加特效的时间比较长,可以研究一种改进方法。
第二种方法:图像运算
二进制“与”运算
图像的二进制“与”运算:
“与”运算的规则:1&1=1,1&0=0,0&1=0,0&0=0。
可以得出
- 任何数据与0的二进制“与运算”都是0;
- 任何数据与1的二进制“与运算”都能保留原数据信息。
如:
- 199的二进制是11000111
- 0的二进制是00000000
- 则 199 & 0 = 11000111 & 00000000 = 00000000。
- 255的二进制是11111111
- 则 199 & 255 = 11000111 & 11111111 = 11000111
观察胡子特效图像可以发现,特效图像的背景是白色的,像素值为255,转换为二进制为11111111;特效图像的胡子区域是黑色的,像素值为0,转换为二进制为00000000。
将特效图像的像素点与ROI的像素点做二进制“与运算”,ROI就会替换特效图像背景,保留胡子区域,如下图所示

opencv中实现二进制与运算的方法为cv2.bitwise_and()
# 将特效图像(effect)与ROI做二进制“与运算”
effect = cv2.bitwise_and(effect, roi)
该方法虽然能加快添加特效速度,但该方法对彩色特效图像的处理效果一般,如将黑色胡子特效换为彩色胡子特效,就会出现如下所示效果,胡子部分颜色发生了变化,这是因为胡子区域的像素值不再是0,与ROI进行“与”运算时就会发生变化。

如在(200,200)像素点处,特效图像的RGB值为[0,149,210],ROI的RGB值为[208,215,235],经过二进制“与”运算后,该点的像素值就会变为[0,149,194]。
因此对于彩色特效,需要将其先转换为黑色特效,去除背景后再做叠加。
处理彩色特效
第一步:首先利用灰度化和二值化去除特效图像的彩色信息,将彩色图像变为黑白图像
image_copy = image.copy()
# 获取特效图像和ROI区域
p = 164
effect, w, h = process_effects(landmarks, "icons/beard_color.png", icon_name)
# 以164号关键点为中心点,确定ROI区域
roi = image_copy[landmarks[p][1] - int(h / 2):landmarks[p][1] - int(h / 2) + h,
landmarks[p][0] - int(w / 2):landmarks[p][0] - int(w / 2) + w]
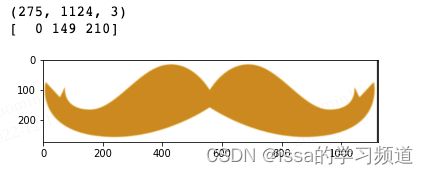
plt.imshow(effect[:, :, ::-1])
print(effect.shape) # 获得图像尺寸
print(effect[200,200]) # (200,200)位置的像素值
输出结果
cv2.cvtColor(img,cv2.COLOR_BGR2GRA)可以将彩色图像图像转换为灰度图像。
# 图像灰度化
effect2gray = cv2.cvtColor(effect, cv2.COLOR_BGR2GRAY)
plt.imshow(effect2gray,'gray')
print(effect2gray.shape) # 获得图像尺寸
print(effect2gray[200,200]) # (200,200)位置的像素值
输出结果
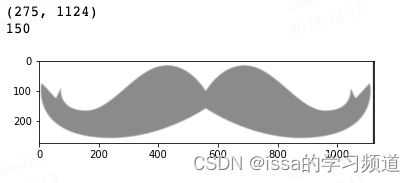
经过灰度处理后,每个图像由原来的3个颜色通道(RGB),变为1个颜色通道(gray),它有256个灰度等级,255代表全白,0表示全黑。可对比图像颜色、图像尺寸和(200,200)位置的像素值。
二值化是将灰度图像中的灰度值转换为0或者255两个值。cv2.threshold()可以将灰度图像中的灰度值二值化。
cv2.threshold(img, thresh, maxval, type)参数说明:
- img:原始灰度图像
- thresh:阈值
- maxval:最大值,如255.
- type:阈值类型,定义了如何处理数据与阈值的关系,如当type = cv2.THRESH_BINARY时,原始图像中灰度值如果大于阈值,将该灰度值转换为最大值,否则转换为0
- 返回值:阈值和二值化后的图像。
# 图像二值化(阈值为180)
ret, effect2wb = cv2.threshold(effect2gray, 180, 255, cv2.THRESH_BINARY)
plt.imshow(effect2wb,'gray')
print(effect2wb.shape) # 获得图像尺寸
print(effect2wb[100,100]) # (100,100)位置的像素值
输出结果
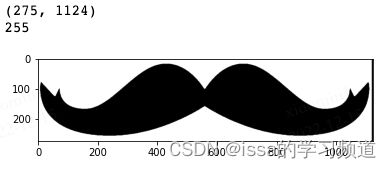
经过二值化处理后的图像,将彩色特效图像变为了黑白特效图像,如图中胡子区域变为了黑色,其像素值都是0,背景区域为白色,其像素值为255.
第二步:需要将ROI与二值化后的黑白特效图像进行二进制”与“运算
这个时候不能直接进行cv2.bitwise_and(roi,effect)的操作,因为cv2.bitwise_and()在进行“与”运算时,需要两张图像的大小和通道数一致,但经过二值化后的黑白图像只有一个颜色通道(gray)。
解决方法
为了解决图像通道数的差异问题,可以在cv2.bitwise_and(src1,src2,mask)方法中加入mask参数,也称作图像掩膜或图像遮罩,为单通道的灰度图像。输出图像像素只有mask对应位置元素不为0的部分才输出,否则该位置像素的所有通道都设置为0。
dst(I)=src1(I) & src2(I) if mask(I)≠0 dst为输出图像。
即mask中等于0的区域会保留在输出图像中,如黑色胡子区域的像素值为0,将二值化的黑白胡子图像作为mask,就会被完整保留在输出图像中。
effectwb = cv2.bitwise_and(roi,roi,mask = effect2wb)
plt.imshow(effectwb[:, :, ::-1])
输出结果

第三步:需要将彩色信息添加到特效中,这个过程中需要保证特效图像背景不发生变化。
opencv中提供了“叠加”的方法cv2.add(src1,src2),任何像素值与0相加都能获得像素值本身(如230 + 0 = 230)。叠加时,需要保证“相加”的两个图像有相同的尺寸和通道数。
目前黑白特效图像(effectwb)中的特效区域像素值均为0,与彩色特效图像(effect)做add操作,就能还原出彩色信息。
但彩色特效图像的背景是白色(像素值为255),任何像素值与255相加都只能获得255(像素的最大值为255),无法保留需要的特效背景。
如下所示,直接“相加”并不能获得想要的结果
a = cv2.add(effectwb,effect)
plt.imshow(a[:, :, ::-1])
输出结果

因此,需要对彩色特效图像做一些处理,将彩色特效图像的背景也变为黑色,保留特效区域的颜色。
# 首先反转二值化后的特效
effect2wb_ne = cv2.bitwise_not(effect2wb)
plt.imshow(effect2wb_ne,'gray')
输出结果

# 然后与运算处理彩色特效
effectcolor = cv2.bitwise_and(effect, effect, mask=effect2wb_ne)
plt.imshow(effectcolor[:, :, ::-1])
输出结果

# 最后将处理后的彩色特效与黑色特效进行叠加
effect_final = cv2.add(effectcolor,effectwb)
plt.imshow(effect_final[:, :, ::-1])
输出结果

总结
整个处理彩色特效的方法如下方函数所示
def swap_non_effcet2(effect, roi, threshold=240):
"""
:param effect: 特效图像
:param roi: ROI区域
:param threshold: 阈值
:return: 消除背景后的特效图像
"""
# (1)特效图像灰度化
effect2gray = cv2.cvtColor(effect, cv2.COLOR_BGR2GRAY)
# (2)特效图像二值化
ret, effect2wb = cv2.threshold(effect2gray, threshold, 255, cv2.THRESH_BINARY)
# (3)消除特效的白色背景
effectwb = cv2.bitwise_and(roi, roi, mask=effect2wb)
# (4)反转二值化后的特效
effect2wb_ne = cv2.bitwise_not(effect2wb)
# (5)处理彩色特效
effectcolor = cv2.bitwise_and(effect, effect, mask=effect2wb_ne)
# (6) 组合彩色特效与黑色特效
effect_final = cv2.add(effectcolor, effectwb)
return effect_final
经过测试发现,第二种消除特效背景的方法比第一种更快,在视频中显示效果更好
添加特效完整代码
# 模型配置
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(static_image_mode=False, # 静态图片设置为False,视频设置为True
max_num_faces=3, # 能检测的最大人脸数
refine_landmarks=True, # 是否需要对嘴唇、眼睛、瞳孔的关键点进行定位,
min_detection_confidence=0.5, # 人脸检测的置信度
min_tracking_confidence=0.5) # 人脸追踪的置信度(检测图像时可以忽略)
# 读取图像
image = cv2.imread("images/img2.jpg")
# 获取关键点
face_landmarks = get_landmarks(image, face_mesh)
# ROI区域中心关键点
center = {"beard": 164, "eyeglass": 168, "halfmask": 9}
# 处理特效
icon_name = "beard"
for landmarks in face_landmarks:
effect, w, h = process_effects(landmarks, "icons/"+icon_name+".png", icon_name)
# 确定ROI
p = center[icon_name]
roi = image[landmarks[p][1] - int(h / 2):landmarks[p][1] - int(h / 2) + h,
landmarks[p][0] - int(w / 2):landmarks[p][0] - int(w / 2) + w]
if effect.shape[:2] == roi.shape[:2]:
# 消除特效图像中的白色背景区域
s = time.time()
# 第一种方法
# swap_non_effcet1(effect,roi,240)
# 第二种方法
effect = swap_non_effcet2(effect, roi,240)
print(time.time()-s) # 计算处理时间
# 将处理好的特效添加到人脸图像上
image[landmarks[p][1] - int(h / 2):landmarks[p][1] - int(h / 2) + h,
landmarks[p][0] - int(w / 2):landmarks[p][0] - int(w / 2) + w] = effect
# 利用matplotlib展示
plt.figure(figsize=(30, 10))
plt.imshow(image[:, :, ::-1])