mmdetection项目实现Faster RCNN(4)
环境 ubantu16.04+cudnn7.0+cuda_9.0.176
Pytorch1.0+python3.6.5+ anaconda3
一、数据准备
①mmdetection 支持VOC风格数据类型
②下载预训练权重(没有下载,训练的时候自动下载restnet50)
二、编译:
下载工程:
https://github.com/open-mmlab/mmdetection
./compile.sh
python setup.py develop
三、修改文件
faster_rcnn_r50_fpn_1x_voc0712.py放到新建文件夹experiment里
1、config文件
# model settings
model = dict(
type='FasterRCNN',
pretrained='modelzoo://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_scales=[8],
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[4, 8, 16, 32, 64],
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0],
use_sigmoid_cls=True),
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='SharedFCBBoxHead',
num_fcs=2,
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=3, #修改成自己要训练的类别+1
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2],
reg_class_agnostic=False))
# model training and testing settings
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=0,
pos_weight=-1,
smoothl1_beta=1 / 9.0,
debug=False),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False))
test_cfg = dict(
rpn=dict(
nms_across_levels=False,
nms_pre=2000,
nms_post=2000,
max_num=2000,
nms_thr=0.7,
min_bbox_size=0),
rcnn=dict(
score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100)
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_thr=0.5, min_score=0.05)
)
# dataset settings
dataset_type = 'VOCDataset' #修改数据类型
data_root = 'data/VOCdevkit/'#数据所在根目录
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
data = dict(
imgs_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset', # to avoid reloading datasets frequently
times=3,
dataset=dict(
type=dataset_type,
ann_file= [
data_root + 'VOC2007/ImageSets/Main/trainval.txt', #训练验证数据路径
#data_root + 'VOC2012/ImageSets/Main/trainval.txt'
],
img_prefix= [data_root + 'VOC2007/'],# 相关数据文件夹
img_scale=(1000, 600),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0.5,
with_mask=False,
with_crowd=True,
with_label=True)),
val=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',#验证数据路径
img_prefix=data_root + 'VOC2007/',#相关数据文件路径
img_scale=(1000, 600),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=True,
with_label=True),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',#测试数据路径
img_prefix=data_root + 'VOC2007/',#相关数据文件路径
img_scale=(1000, 600),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_label=False,
test_mode=True))
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(policy='step', step=[3]) # actual epoch = 3 * 3 = 9
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
# runtime settings
total_epochs = 4 # actual epoch = 4 * 3 = 12
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = './experiment/faster_rcnn_r50_fpn_1x_voc0712'#训练时生成文件的路径
load_from = None
resume_from = None
workflow = [('train', 1)]
2、修改mmdetection/mmdet/datasets/voc.py
CLASSES种类改成自己要识别的类别
3、修改mmdet/core/evaluation/class_names.py
将其中返回的return类别修改为自己要识别的类别
四、训练
在终端运行命令:
$ python tools/train.py experiment/faster_rcnn_r50_fpn_1x_voc0712.py --gpus 1 --work_dir experiment/faster_rcnn_r50_fpn_1x_voc0712

训练完成之后会在mmdetection/experiment/faster_rcnn_r50_fpn_1x_voc0712文件夹中生成一系列pth文件。

2、验证
运行命令:
$ python tools/test.py experiment/faster_rcnn_r50_fpn_1x_voc0712.py experiment/
faster_rcnn_r50_fpn_1x_voc0712/latest.pth --out=experiment/eval/result.pkl
生成result.pkl文件后,验证测试集
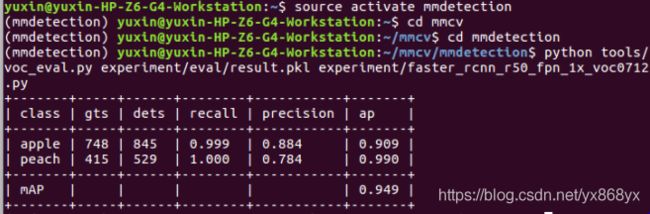
运行命令:
$ python tools/voc_eval.py experiment/eval/result.pkl experiment
/faster_rcnn_r50_fpn_1x_voc0712.py
运行下面命令可以看测试验证集的过程:
$ python tools/test.py experiment/faster_rcnn_r50_fpn_1x_voc0712.py experiment
/faster_rcnn_r50_fpn_1x_voc0712/latest.pth --show
五、测试
1测试文件:
import mmcv
import torch
from mmcv.runner import load_checkpoint
from mmdet.models import build_detector
from mmdet.apis import inference_detector, show_result
import ipdb
def roialign_forward(module,input,output):
print('\n\ninput:')
print(input[0].shape,'\n',input[1].shape)
if __name__ == '__main__':
params=[]
def hook(module,input):
# print('breakpoint')
params.append(input)
# print(input[0].shape)
# data=input
cfg = mmcv.Config.fromfile('experiment/faster_rcnn_r50_fpn_1x_voc0712.py')
cfg.model.pretrained = None
# ipdb.set_trace()
# construct the model and load checkpoint
model = build_detector(cfg.model, test_cfg=cfg.test_cfg)
print(model)
handle=model.backbone.conv1.register_forward_pre_hook(hook)
# model.bbox_roi_extractor.roi_layers[0].register_forward_hook(roialign_forward)
_ = load_checkpoint(model, 'experiment/faster_rcnn_r50_fpn_1x_voc0712/latest.pth')
'''
# test a single image
img= mmcv.imread('test1.jpeg')
result = inference_detector(model, img, cfg)
#print(params)
show_result(img, result)
handle.remove()
'''
imgs = ['test1.jpeg','test2.jpg','test2.jpeg']
for i, result in enumerate(inference_detector(model, imgs, cfg, device='cuda')):
print(i, imgs[i])
#show_result(imgs[i], result,
out_file='/home/yuxin/mmcv/mmdetection/demo/{}'.format(imgs[i]))#输出保存路径
show_result(imgs[i],result)#不输出保存路径
2、修改mmdetection/mmdet/apis/inference.py中的show_result函数,把coco改成voc
import mmcv
import numpy as np
import pycocotools.mask as maskUtils
import torch
from mmdet.core import get_classes
from mmdet.datasets import to_tensor
from mmdet.datasets.transforms import ImageTransform
def _prepare_data(img, img_transform, cfg, device):
ori_shape = img.shape
img, img_shape, pad_shape, scale_factor = img_transform(
img,
scale=cfg.data.test.img_scale,
keep_ratio=cfg.data.test.get('resize_keep_ratio', True))
img = to_tensor(img).to(device).unsqueeze(0)
img_meta = [
dict(
ori_shape=ori_shape,
img_shape=img_shape,
pad_shape=pad_shape,
scale_factor=scale_factor,
flip=False)
]
return dict(img=[img], img_meta=[img_meta])
def _inference_single(model, img, img_transform, cfg, device):
img = mmcv.imread(img)
data = _prepare_data(img, img_transform, cfg, device)
with torch.no_grad():
result = model(return_loss=False, rescale=True, **data)
return result
def _inference_generator(model, imgs, img_transform, cfg, device):
for img in imgs:
yield _inference_single(model, img, img_transform, cfg, device)
def inference_detector(model, imgs, cfg, device='cuda:0'):
img_transform = ImageTransform(
size_divisor=cfg.data.test.size_divisor, **cfg.img_norm_cfg)
model = model.to(device)
model.eval()
if not isinstance(imgs, list):
return _inference_single(model, imgs, img_transform, cfg, device)
else:
return _inference_generator(model, imgs, img_transform, cfg, device)
def show_result(img, result, dataset='voc', score_thr=0.3, out_file=None): #coco--voc
img = mmcv.imread(img)
class_names = get_classes(dataset)
if isinstance(result, tuple):
bbox_result, segm_result = result
else:
bbox_result, segm_result = result, None
bboxes = np.vstack(bbox_result)
# draw segmentation masks
if segm_result is not None:
segms = mmcv.concat_list(segm_result)
inds = np.where(bboxes[:, -1] > score_thr)[0]
for i in inds:
color_mask = np.random.randint(
0, 256, (1, 3), dtype=np.uint8)
mask = maskUtils.decode(segms[i]).astype(np.bool)
img[mask] = img[mask] * 0.5 + color_mask * 0.5
# draw bounding boxes
labels = [
np.full(bbox.shape[0], i, dtype=np.int32)
for i, bbox in enumerate(bbox_result)
]
labels = np.concatenate(labels)
mmcv.imshow_det_bboxes(
img.copy(),
bboxes,
labels,
class_names=class_names,
score_thr=score_thr,
show=out_file is None,
out_file=out_file) #更新过
