【打卡】零基础入门推荐系统-新闻推荐
文章目录
- 赛题背景
- Task1:比赛报名与数据读取
-
- 比赛报名
- 数据读取
- 数据查看
- Task2:比赛数据分析
-
- 用户ID
- 合并点击日志和内容
- 整体分布
- 用户国家和地区分布
- 用户点击文章数
- 点击来源与文章点击次数
- 用户行为时间戳分析
- 整体分布
- 文章内容分析
- 文章嵌入向量
赛题背景
赛题地址:https://tianchi.aliyun.com/competition/entrance/531842/information
赛题以预测用户未来点击新闻文章为任务,数据集报名后可见并可下载,该数据来自某新闻APP平台的用户交互数据,包括30万用户,近300万次点击,共36万多篇不同的新闻文章,同时每篇新闻文章有对应的embedding向量表示。为了保证比赛的公平性,将会从中抽取20万用户的点击日志数据作为训练集,5万用户的点击日志数据作为测试集A,5万用户的点击日志数据作为测试集B。
Task1:比赛报名与数据读取
比赛报名

数据读取
# 原始读入时间
time_start = time.time()
articles = pd.read_csv('articles.csv')
articles_emb = pd.read_csv('articles_emb.csv')
train_click = pd.read_csv('train_click_log.csv')
test_click = pd.read_csv('testA_click_log.csv')
print('load time: ',time.time() - time_start)

由于数据量比较大,读取占用内存和时间都比较多,考虑对其进行优化。
优化代码:
# 优化内存
def reduce_mem(df):
start_mem = df.memory_usage().sum() / 1024 ** 2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
## Reference from: https://www.kaggle.com/arjanso/reducing-dataframe-memory-size-by-65
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024 ** 2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
看下优化后内存占用:
articles = reduce_mem(articles)
articles_emb = reduce_mem(articles_emb)
train_click = reduce_mem(train_click)
test_click = reduce_mem(test_click)
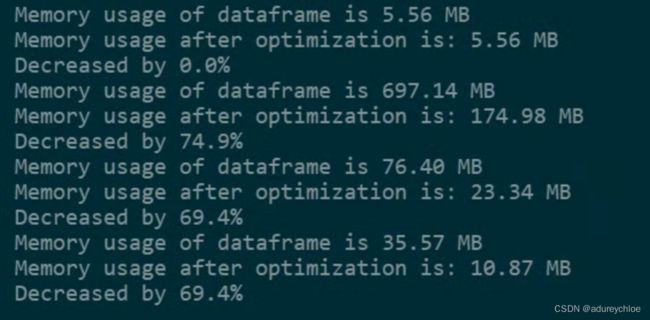
可见节省了很多内存。我们把它存储下来以便以后使用,这里使用hdf5存储。
# 保存数据以免每次都重新读取
data_store_1 = pd.HDFStore('articles.h5')
# Store object in HDFStore
data_store_1.put('preprocessed_df', articles, format='table')
data_store_1.close()
data_store_2 = pd.HDFStore('articles_emb.h5')
# Store object in HDFStore
data_store_2.put('preprocessed_df', articles_emb, format='table')
data_store_2.close()
data_store_3 = pd.HDFStore('train_click.h5')
# Store object in HDFStore
data_store_3.put('preprocessed_df', train_click, format='table')
data_store_3.close()
data_store_4 = pd.HDFStore('test_click.h5')
# Store object in HDFStore
data_store_4.put('preprocessed_df', test_click, format='table')
data_store_4.close()
测试一下读取优化后数据的速度:
# 读取优化数据时间
time_start = time.time()
store_data = pd.HDFStore('articles.h5')
# 通过key获取数据
articles = store_data['preprocessed_df']
store_data.close()
store_data = pd.HDFStore('articles_emb.h5')
# 通过key获取数据
articles_emb = store_data['preprocessed_df']
store_data.close()
store_data = pd.HDFStore('train_click.h5')
# 通过key获取数据
train_click = store_data['preprocessed_df']
store_data.close()
store_data = pd.HDFStore('test_click.h5')
# 通过key获取数据
test_click = store_data['preprocessed_df']
store_data.close()
print('load time:',time.time() - time_start)

比原来快了很多。
数据查看
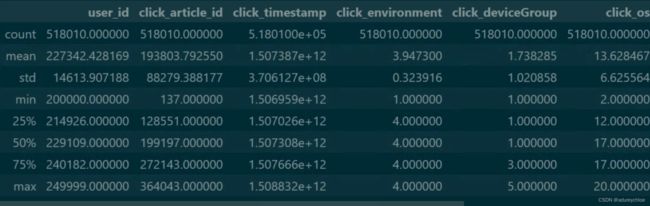
articles.describe()
articles_emb.describe()
train_click.describe()
test_click.describe()
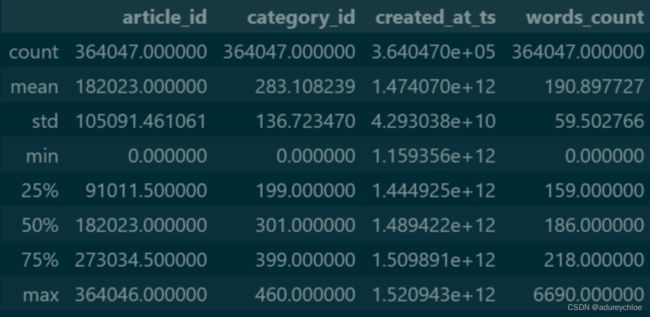
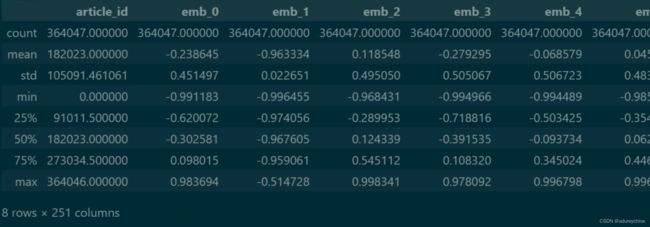
Task2:比赛数据分析
用户ID
每个用户id唯一且不重复,所以我们通过查看user_id来判断用户数量。unique()方法返回的是不重复值,nunique()方法返回不同值的个数。
# user_id
train_click['user_id'].nunique(), test_click['user_id'].nunique()
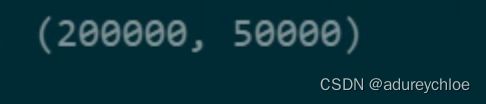
可以看到训练集中有200000个用户,测试集中有50000个用户。
然后来看一下训练集和测试集中用户是否发生交叉,set()函数返回不重复元素集:
set(train_click['user_id']) & set(test_click['user_id'])
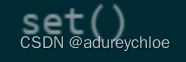
说明训练集中的用户不会在测试集中出现。
合并点击日志和内容
将用户点击日志表和文章内容表做一个合并。
train_click = pd.merge(train_click, articles,
left_on='click_article_id',how='left',
right_on='article_id')
train_click.head(3)
使train_click表中的点击文章id和articles表中的文章id一一对应。

整体分布
用户国家和地区分布
# click country
train_click['click_country'].nunique(), test_click['click_country'].nunique()
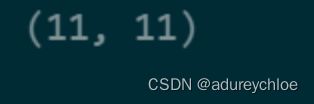
训练集和测试集的用户国家都有11个。查看具体分布:
plt.figure(figsize=(10,5), dpi=80)
plt.subplot(121)
train_click['click_country'].value_counts().sort_index().plot(kind='bar')
plt.xlabel('click_country')
plt.subplot(122)
test_click['click_country'].value_counts().sort_index().plot(kind='bar')
plt.tight_layout()
plt.xlabel('click_country')
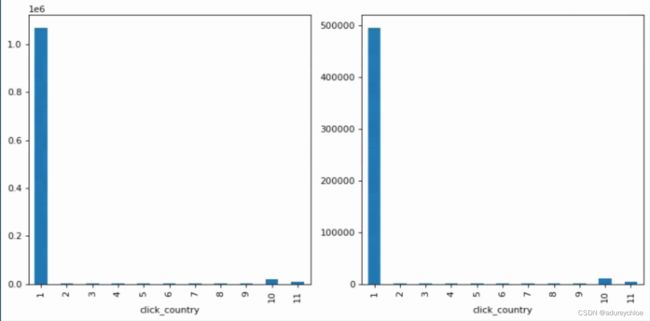
可以看到训练集和测试集的用户国家分布一致,都是1、10、11,集中在1。
# click region
train_click['click_region'].nunique(), test_click['click_region'].nunique()
训练集和测试集的用户地区都是28个,查看具体分布:
plt.figure(figsize=(10,5),dpi=100)
plt.subplot(121)
train_click['click_region'].value_counts().sort_index().plot(kind='bar')
plt.xlabel('click_region')
plt.subplot(122)
test_click['click_region'].value_counts().sort_index().plot(kind='bar')
plt.xlabel('click_region')
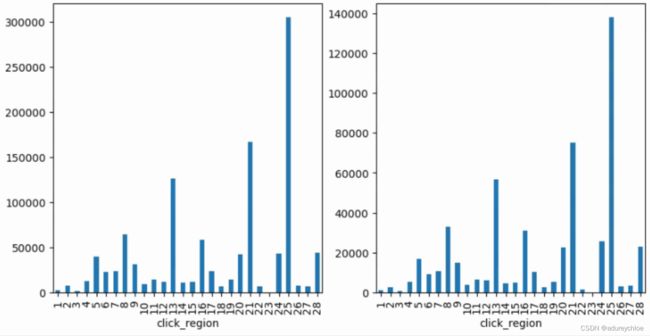
可以看到训练集和测试集的用户地区分布基本一致。
用户点击文章数
查看用户点击文章的数目,groupby函数用来对用户分组。
plt.figure(figsize=(10,5),dpi=120)
plt.subplot(121)
train_click.groupby('user_id')['click_article_id'].nunique().plot(kind='box')
plt.subplot(122)
test_click.groupby('user_id')['click_article_id'].nunique().plot(kind='box')
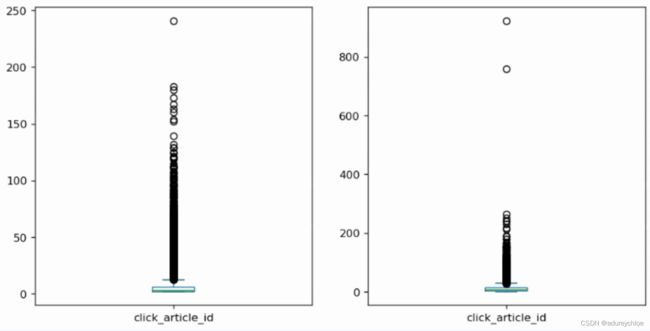
可以看到训练集和测试集分布基本一致,用户点击文章数多在100以内。
# 查看每个用户最少点击文章
train_click.groupby('user_id')['click_article_id'].count().min(), test_click.groupby('user_id')['click_article_id'].count().min()
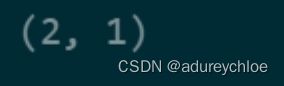
训练集中每个用户最少点击两篇文章,测试集中每个用户最少点击一篇文章。
点击来源与文章点击次数
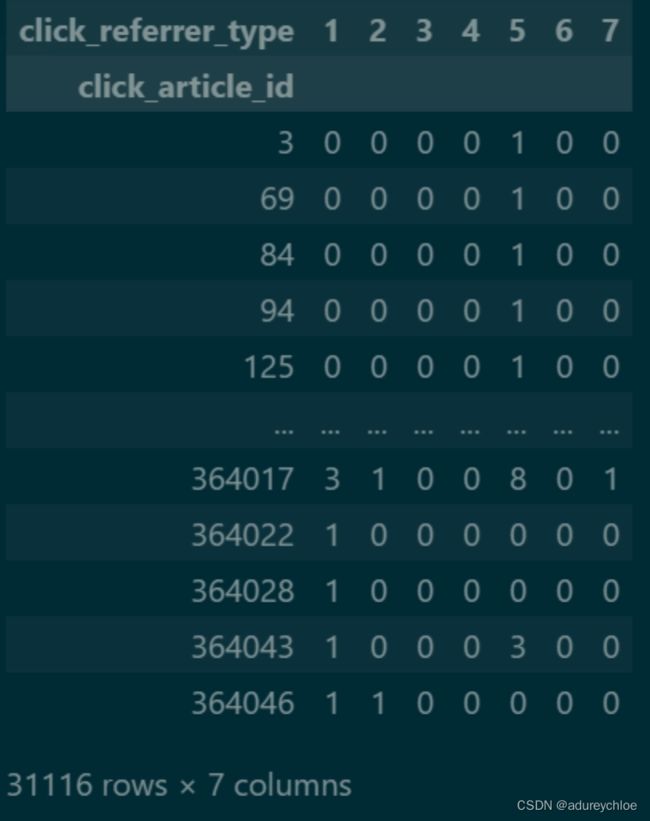
查看对每一篇文章不同来源下用户对应的点击次数。
click_referrer_type_count = pd.pivot_table(train_click,
index='click_article_id',
columns='click_referrer_type',
values='user_id',
aggfunc='nunique',
fill_value=0)
click_referrer_type_count
查看每一个来源的点击平均次数。
click_referrer_type_count.mean(0).plot(kind='bar')
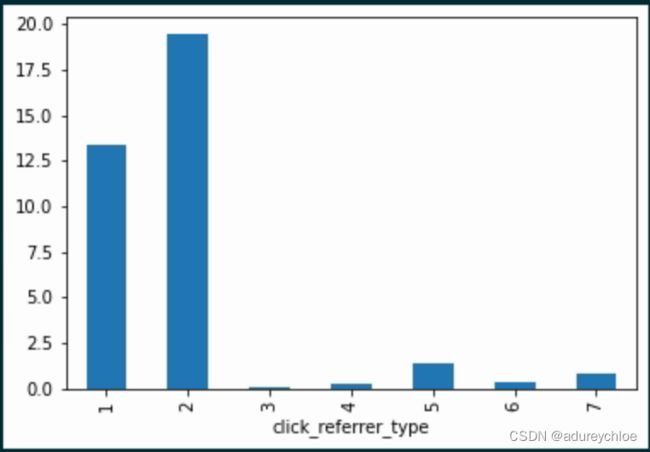
可以看到来源1、2、5的文章点击次数比较高。
查看文章来源之间的相关性:
click_referrer_type_count.corr()
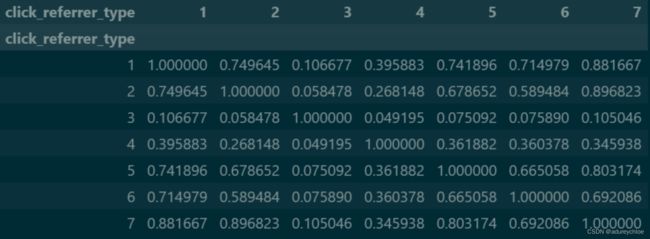
观察发现来源1和来源7,来源2和来源7都是相关性比较大的。
用户行为时间戳分析
计算用户点击rank和点击次数。
# 对每个用户点击的时间戳进行排序
train_click['rank'] = train_click.groupby('user_id')['click_timestamp'].rank(ascending=False).astype(int)
test_click['rank'] = test_click.groupby('user_id')['click_timestamp'].rank(ascending=False).astype(int)
#计算用户点击文章的次数,并添加新的一列count
train_click['click_cnts'] = train_click.groupby(['user_id'])['click_timestamp'].transform('count')
test_click['click_cnts'] = test_click.groupby(['user_id'])['click_timestamp'].transform('count')
对每一个用户点击的时间戳前后做一个差值,相同的舍弃:
clicks_ts_diff = train_click.groupby('user_id')['click_timestamp'].diff(1).dropna()
clicks_ts_diff
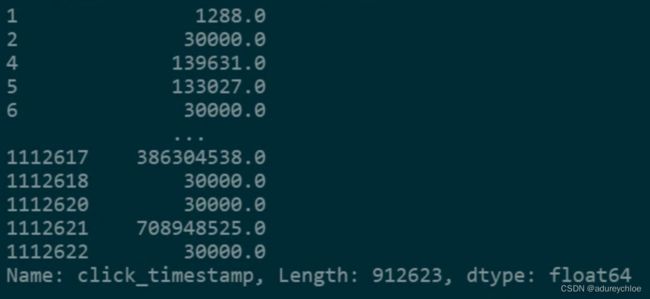
对差值做一个统计:
clicks_ts_diff.describe().astype(int)
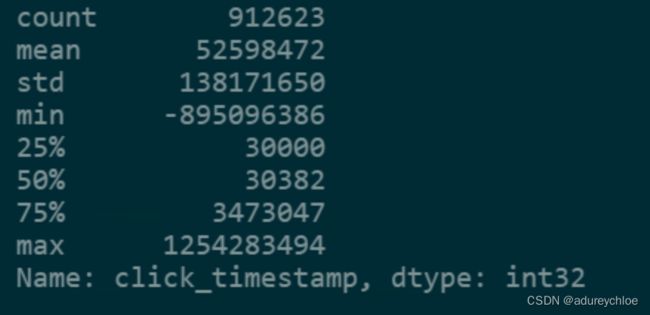
从平均值看出大部分点击时间差都在一小时以内。
筛选user_id为199999的用户信息:
train_click[train_click['user_id']==199999]
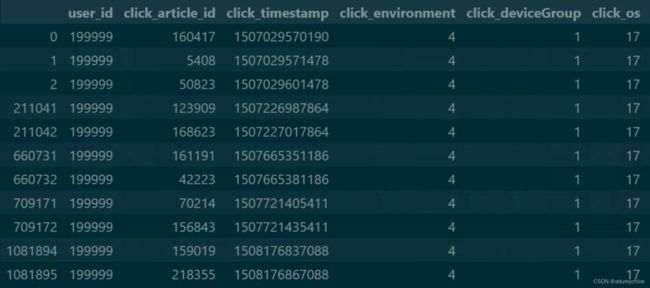
发现文章id为161191和42223的时间戳间隔很近,应该有某种关系。看一下它们的信息:
articles[articles['article_id'].isin([161191, 42223])]
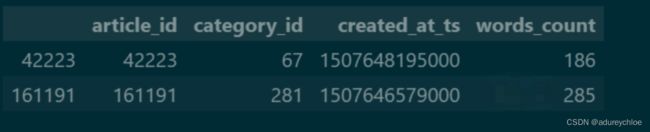
可以看到这两篇文章的创建时间也是很接近的。
具体而言,它们相隔时间在一小时以内。
(1507646579000 - 1507648195000) /1000 /3600

整体分布
文章内容分析
统计文章点击人数和文章单词数是否存在关系:
plt.scatter(
train_click.groupby(['click_article_id'])['user_id'].nunique(),
train_click.groupby(['click_article_id'])['words_count'].mean()
)
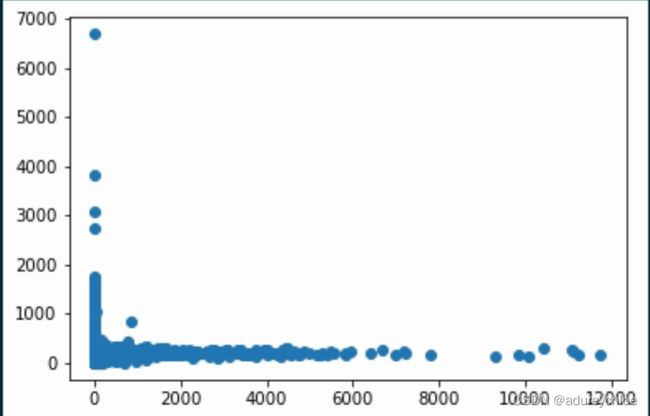
大部分点击人数比较多的文章单词数都在2000以下。
对文章的点击时间和创建时间做一个差值,统计差值与点击人数的关系:
train_click['click_ts2created'] = train_click['click_timestamp'] - train_click['created_at_ts']
plt.scatter(
train_click.groupby('click_article_id')['user_id'].nunique(),
train_click.groupby('click_article_id')['click_ts2created'].mean()
)
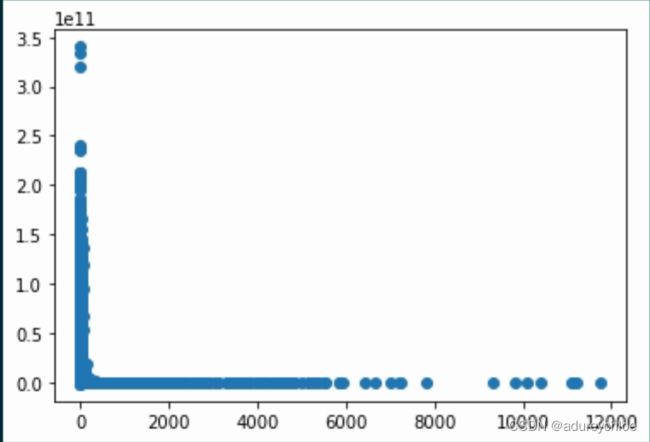
可以发现文章创建的时间越短,被点击的概率越大。
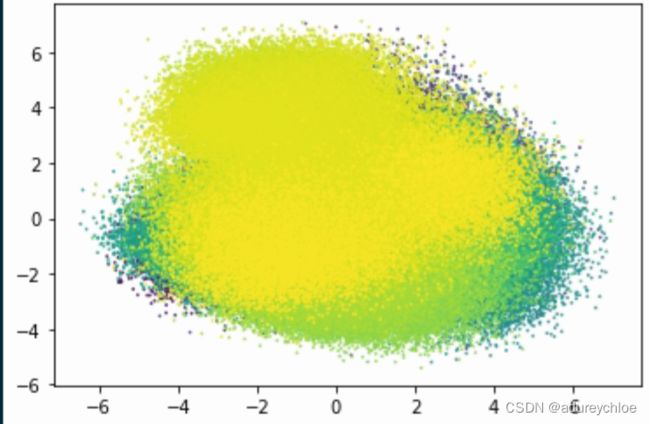
文章嵌入向量
将文章嵌入向量进行降维可视化。
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
articles_emb_2d = pca.fit_transform(articles_emb.values[:, 1:])
plt.scatter(articles_emb_2d[:,0], articles_emb_2d[:, 1],
s = 1, c=articles['category_id'].iloc[:], alpha=0.7)