pandas读取excel的方式介绍、行列元素访问以及读取数据后使用matplotlib画折线图
文章目录
- 1. pandas读取excel方法介绍
-
- (1)io:文件的路径
- (2)sheet_name:读取的工作表的名称
- (3)header:指定哪几行做列名
- (4)names:自定义列名
- (5)index_col:用作索引的列
- (6)usecols:指定读取的列
- (7)squeeze:一列数据时,返回Series还是DataFrame
- (8)skiprows:跳过指定行
- (9)nrows:需要读取的行数
- (10)skipfooter:跳过末尾n行
- (11)dtype:指定元素类型
- 2. 访问Excel的行列元素
-
- (1)读取行列索引
- (2)读取行列元素
- (3)读取某个数据元素
- 3. pandas结合matplotlib使用画图
-
- (1)使用df.plot直接画图
- (2)每一列单独设置画图
pandas是基于Numpy创建的Python包,内置了大量标准函数,能够高效地解决数据分析数据处理和分析任务,pandas支持多种文件的操作,比如Excel,csv,json,txt 文件等,读取文件之后,就可以对数据进行各种清洗、分析操作了。下面我们这里介绍一下如何使用pandas读取excel文件,以及使用它结合matplotlib进行画图。
下面所有的操作都是基于下列excel表格。

1. pandas读取excel方法介绍
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None, squeeze=False,dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0,
convert_float=True, **kwds)
(1)io:文件的路径
下面的路径为相对路径,当然也可以使用绝对路径。
import pandas as pd
io = r'data/verti_list.xlsx' #相对路径
(2)sheet_name:读取的工作表的名称
- 可以是
整型数字、列表名,如果读取多个sheet,也可以是它们组成的列表。 - 整形数字是
以0为起始点
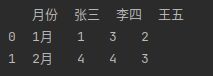
data = pd.read_excel(io, sheet_name = 0)#指定读取第一个sheet
print(data.head(2)) #读取前2行
- 读取指定列表名
data = pd.read_excel(io, sheet_name = '销量')#指定sheet_name
print(data.head(2)) #读取前2行
(3)header:指定哪几行做列名
- 默认header为0,如果设置为[0,1],则表示将前两行作为多重索引。
data = pd.read_excel(io, sheet_name = 0, header = [0,1])
print(data.head(2)) #读取前2行
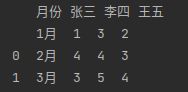
可以看到,header就有两行了。
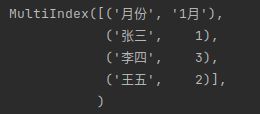
也可以使用print(data.columns)方法,查看它的索引头,如下图所示,是一个MultiIndex类型。
(4)names:自定义列名
- 如果缺少列名,可以使用
names指定列名字,会替代原来的列表头。 - 但是要注意的是,长度必须和excel的
列大小相同。
data = pd.read_excel(io, sheet_name = 0, names=['员工1','员工2','员工3','员工4'])
print(data.head(2)) #读取前2行
print(data.columns)

(5)index_col:用作索引的列
- 可以是
某列的名字,如index_col=‘月份’ - 也可以是整型数字或列表,如index_col=0或index_col=[0,1]
data = pd.read_excel(io, sheet_name = 0, index_col='月份')
print(data.head(2)) #读取前2行
(6)usecols:指定读取的列
- 列从0开始,可以是列表,如:[0,2]
- 也可以使用Excel的列名,如’A’,'B’等字母
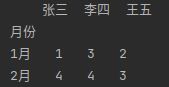
data = pd.read_excel(io, sheet_name = 0, usecols=[0,2])
print(data.head(2)) #读取前2行

使用Excel字母的读取方式:
data = pd.read_excel(io, sheet_name = 0, usecols='A,C')
print(data.head(2)) #读取前2行
(7)squeeze:一列数据时,返回Series还是DataFrame
仅当Excel只有一列的时候起作用- squeeze为True时,返回Series,反之返回DataFrame。
data = pd.read_excel(io, sheet_name = 0, squeeze=True)
print(type(data))
(8)skiprows:跳过指定行
- skiprows= n,
跳过前n行; skiprows = [a, b, c],跳过第a+1,b+1,c+1行(索引从0开始); - 使用skiprows 后,可能会
跳过行首,也就是列名。
data = pd.read_excel(io, sheet_name = 0, skiprows=3)#跳过前3行
print(data.head(2)) #读取前2行

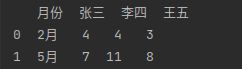
- 跳过指定的行
data = pd.read_excel(io, sheet_name = 0, skiprows=[1,3,4])#跳过指定的行
print(data.head(2)) #读取前2行
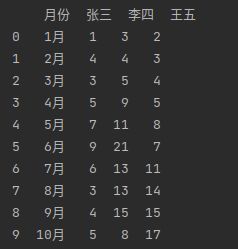
(9)nrows:需要读取的行数
- nrows表示只读取excel的
前nrows行,包括表头。
data = pd.read_excel(io, sheet_name = 0, nrows=10)#读取前10行
print(data)
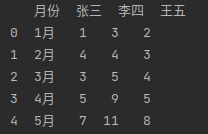
(10)skipfooter:跳过末尾n行
data = pd.read_excel(io, sheet_name = 0, skipfooter=7)#跳过末尾7行
print(data)
(11)dtype:指定元素类型
指定元素的类型
- 未指定时,也就是默认情况,数字为整型或浮点类型
df = pd.read_excel(io, sheet_name = 0)
df['张三'] = df['张三']*3
print(df.head(2))

- 指定元素类型
指定'张三'这一列为str类型,df['张三'] = df['张三']*3,这时候表示重复三次。
df = pd.read_excel(io, sheet_name = 0,dtype={"张三": str})
df['张三'] = df['张三']*3
print(df.head(2))
2. 访问Excel的行列元素
(1)读取行列索引
- 使用
index和columns分别访问行和列的索引。
import pandas as pd
io = r'data/verti_list.xlsx' #相对路径
df = pd.read_excel(io, sheet_name = 0)
print(list(df.index)) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
print(list(df.columns)) #['月份', '张三', '李四', '王五']
- 使用index和columns访问指定的索引
import pandas as pd
io = r'data/verti_list.xlsx' #相对路径
df = pd.read_excel(io, sheet_name = 0)
print(list(df.index[1:3]))#[1, 2]
print(df.columns[1]) #张三
print(list(df.columns[1:3])) #['张三', '李四']
(2)读取行列元素
- 读取列元素
iloc不能通过[:, [1:3]]取连续数据,取连续数据只能通过 df[df.columns[1:4]],先获取列索引,再取数据。
import pandas as pd
io = r'data/verti_list.xlsx' #相对路径
df = pd.read_excel(io, sheet_name = 0)
print(df['张三']) #按列名取列
print(df.张三) #按列名取列
print(df[['张三', '王五']]) #按列名取不连续列数据
print(df[df.columns[1:4]]) #按列索引取连续列数据
print(df.iloc[:, 1]) #按位置取列,第1列,从0列开始数
print(df.iloc[:, [1, 3]]) #按位置取不连续列数据
- 读取行数据
- iloc方法
import pandas as pd
io = r'data/verti_list.xlsx' #相对路径
df = pd.read_excel(io, sheet_name = 0)
print(df[1:3]) #按行取数据,列索引不算一行
print(df[df.张三>4]) #按行有条件的取数据,取张三销量大于4的行
print(df.iloc[1]) #按行取行数据
print(df.iloc[1:3]) #按行取连续数据
print(df.iloc[[1, 3]]) #按行取不连续数据
print(df.iloc[[1,2,3], [2,4]]) #取部分行部分列数据
- loc方法
import pandas as pd
io = r'data/verti_list.xlsx' #相对路径
df = pd.read_excel(io, sheet_name = 0)
print(df.loc[4])#取行,4是行索引,也可以是str类型,下同
print(df.loc[4,'张三'])#取某个元素
print(df.loc[0:4])#取连续的行
print(df.loc[[0, 3]])#取某几行
print(df.loc[df.index[1:3]]) #按行索引取行
print(df.loc[[0, 3], ['张三', '王五']])#取行和列的交集
(3)读取某个数据元素
print(df.iloc[1, 3]) #按坐标取
print(df.iloc[[1], [3]]) #按坐标取
print(df.loc[[0, 3], ['张三', '王五']])#取行和列的交集
3. pandas结合matplotlib使用画图
(1)使用df.plot直接画图
pandas可以很好的使用matplotlib进行画图,甚至可以直接使用pandas调用plot方法进行画图。
import pandas as pd
import matplotlib.pyplot as plt
io = r'data/verti_list.xlsx' #相对路径
df = pd.read_excel(io, sheet_name = 0)
df.plot()
plt.show()
画图效果如下:
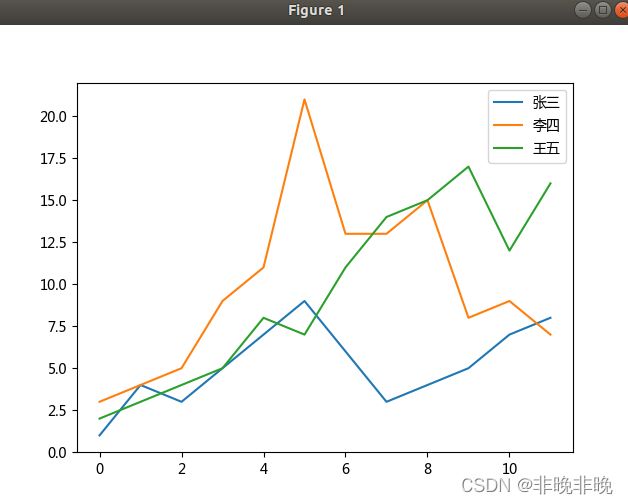
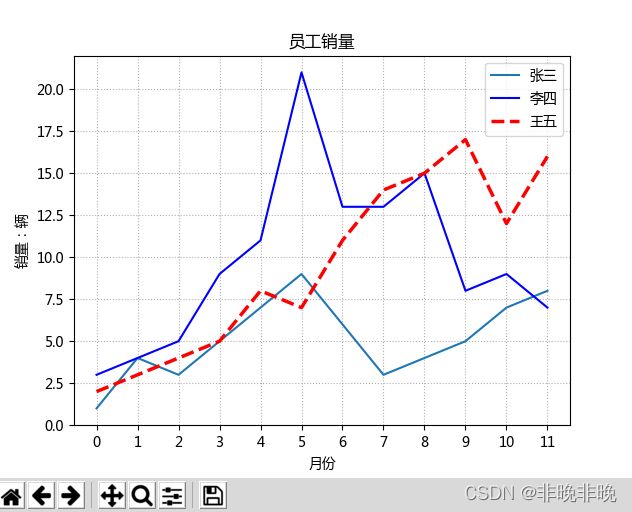
(2)每一列单独设置画图
如果对画图要求比较高,比如需要设置每条折线图的粗细、线条类型、颜色等等,那就要单独设置了,下面是代码举例和注释。
import pandas as pd
import matplotlib.pyplot as plt
io = r'data/verti_list.xlsx' #相对路径
df = pd.read_excel(io, sheet_name = 0)
x_row = df.index.to_numpy() #转numpy,用做横坐标
# 好像不能直接用df['月份'].to_numpy(),画图会乱
y_col_1 = df['张三'].to_numpy()
y_col_2 = df['李四'].to_numpy()
y_col_3 = df['王五'].to_numpy()
fig, ax = plt.subplots()
xticks = list(range(12)) #自定义刻度
ax.set_xticks(xticks)
plt.title("员工销量", fontsize=12) #标题,并设置字体大小
plt.ylabel("销量:辆") #纵坐标名字
plt.xlabel("月份") #横坐标名字
plt.grid(True,linestyle=':') #设置网格
#plt.xlim((0,13)) # 坐标轴的取值范围
#plt.tick_params(axis='both',which='major',labelsize=14)
l1, = plt.plot(x_row, y_col_1)# 默认折线、实线
l2, = plt.plot(x_row, y_col_2, color="blue", linewidth=1.5, linestyle="-") # 蓝色,1.5宽,线段
l3, = plt.plot(x_row, y_col_3,'r',linewidth = 2.5,linestyle ='--')# 红色,2.5宽,虚线
#l4, = plt.plot(x, y_col_1,'c',linestyle ='-.')# 线段类型-.
#l5, = plt.plot(x, y_col_1,linestyle =':')# 虚点
ls = [l1,l2, l3]
labels = ['张三','李四','王五']
plt.legend(handles=ls,labels=labels,loc='best')
plt.show()
效果如下: